






 本文深入探讨了Kubernetes中无状态和有状态工作负载的更新与回滚策略,包括Deployment的RollingUpdate和StatefulSet的有序更新。同时,详细介绍了应用健康检查机制,如livenessProbe和readinessProbe,以及容器的HTTPGET、TCPSocket和Exec探针。此外,还讲解了应用弹性伸缩,包括HPA的水平自动伸缩和CA的节点自动伸缩,以及如何实现工作负载和节点的联动弹性伸缩。
本文深入探讨了Kubernetes中无状态和有状态工作负载的更新与回滚策略,包括Deployment的RollingUpdate和StatefulSet的有序更新。同时,详细介绍了应用健康检查机制,如livenessProbe和readinessProbe,以及容器的HTTPGET、TCPSocket和Exec探针。此外,还讲解了应用弹性伸缩,包括HPA的水平自动伸缩和CA的节点自动伸缩,以及如何实现工作负载和节点的联动弹性伸缩。
点击上方“程序猿技术大咖”,关注并选择“设为星标”
回复“加群”获取入群讨论资格!
本篇文章来自《华为云云原生王者之路训练营》钻石系列课程第8课,由华为云容器洞察引擎CIE团队高级工程师 Roc主讲,带大家深入理解应用在K8s生产环境的最佳实践,包括应用更新与回滚,应用健康检查,弹性伸缩等特性。
01
工作负载更新和回滚机制
无状态工作负载(deployment)更新
在我们的生产环境中,deployment是一种很常见的无状态工作负载类型。
Deployment可以设置不同的更新策略,有如下两种:
Recreate: 停止所有旧版本然后部署新版本(最好只在开发环境使用)
RollingUpdate:滚动升级,即逐步创建新Pod再删除旧Pod,为默认策略。
Deployment可以通过maxSurge和maxUnavailable两个参数控制升级过程中重新创建Pod的比例:
maxSurge:与Deployment中spec.replicas相比,可以有多少个Pod存在,默认值是25%,比如spec.replicas为 4,那升级过程中就不能超过5个Pod存在,即按1个的步伐升级。
maxUnavailable:与Deployment中spec.replicas相比,可以有多少个Pod失效,也就是删除的比例,默认值是25%,比如spec.replicas为4,那升级过程中就至少有3个Pod存在,即删除Pod的步伐是1。
spec:
replicas: 2
template:
spec:
containers:
- name: container-0
image: 'nginx:1.16.0-alpine‘
...
...
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 0注意:仅当 Deployment Pod 模板(即 .spec.template)发生改变时,例如模板的标签或容器镜像被更新,才会触发 Deployment 升级。
无状态工作负载(deployment)回滚
在更新出问题之后,可能需要对应用进行回滚。k8s支持根据deployment的历史版本进行回滚
查看deployment升级历史:
$ kubectl rollout history deployment/nginx
deployment.apps/nginx
REVISION CHANGE-CAUSE
1 <none>
2 <none>回滚到上一个版本:
$ kubectl rollout undo deployment/nginx回滚到指定版本:
$ kubectl rollout undo deployment/nginx --to-revision=2有状态工作负载(StatefulSet)更新
StatefulSet可以设置不同的更新策略,有如下两种:
1) OnDelete: 用户必须手动删除 Pod 以便让控制器创建新的 Pod
2) RollingUpdate: 滚动更新过程也跟Deployment大致相同,区别在于:
滚动更新的过程是有序的(逆序),index从N-1到0逐个依次进行,并且下一个Pod创建必须是前一个Pod Ready为前提,下一个Pod删除必须是前一个Pod shutdown并完全删除为前提。
支持部分实例滚动更新,部分不更新,通过 .spec.updateStrategy.rollingUpdate.partition来指定一个index分界点。所有id大于等于partition指定的值的Pods将会进行滚动更新;所有id小于partition指定的值得Pods将保持不变。
有状态工作负载(StatefulSet)回滚
statefulset 和 deployment 一样也支持回滚操作,statefulset 也保存了历史版本,和 deployment 一样利用 .spec.revisionHistoryLimit 字段设置保存多少个历史版本。
查看StatefulSet升级历史:
kind: StatefulSet
spec:
replicas: 4
template:
spec:
containers:
- name: container-0
image: 'nginx:1.16.0-alpine‘
...
...
updateStrategy:
type: RollingUpdate
rollingUpdate:
partition: 2回滚到指定版本:
$ kubectl rollout undo statefulset nginx-ss --to-revision=3 -n monitoring
statefulset.apps/nginx-ss rolled back提示:因为 statefulset 的使用对象是有状态服务,大部分有状态副本集都会用到持久存储,statefulset 下的每个 pod 正常情况下都会关联一个 pv 对象,对 statefulset 对象回滚非常容易,但其使用的 pv 中保存的数据无法回滚,所以在生产环境中进行回滚时需要谨慎操作。
02
应用探针健康检查机制详解
容器健康检查
在生产环境中,一个应用的健康状态,对我们的业务非常重要,如果一个流量进入到一个不健康的Pod中,会导致业务受损。K8s为了应对这种情况,引入了探针机制,包含两种:
liveness probe(工作负载存活探针):指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其重启策略进行重启。如果容器不提供存活探针, 则默认状态为 Success。
readiness probe(工作负载业务探针):用于检查**用户业务是否就绪,如果未就绪,则不转发流量到当前实例。一些程序的启动时间可能很长,比如要加载磁盘数据或者要依赖外部的某个模块启动完成才能提供服务。这时候程序进程在,但是并不能对外提供服务。这种场景下该检查方式就非常有用。如果容器的就绪检查失败,集群会屏蔽请求访问该容器;若检查成功,则会开放对该容器的访问。
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:探针检查机制
Kubernetes支持如下三种探测机制:
HTTP GET:向容器发送HTTP GET请求,如果Probe收到2xx或3xx,说明容器是健康的。
TCP Socket:尝试与容器指定端口建立TCP连接,如果连接成功建立,说明容器是健康的。
Exec:Probe执行容器中的命令并检查命令退出的状态码,如果状态码为0则说明容器是健康的。
还有两个公用的参数:
延时时间( initialDelaySeconds ): 延迟检查时间,单位为秒,此设置与业务程序正常启动时间相关。例如,设置为30,表明容器启动后30秒才开始健康检查,该时间是预留给业务程序启动的时间。
超时时间( periodSeconds ): 例如,设置为10,表明执行健康检查的超时等待时间为10秒,如果超过这个时间,本次健康检查就被视为失败。若设置为0或不设置,默认超时等待时间为1秒。
03
应用弹性伸缩原理
弹性伸缩概述
弹性伸缩是根据业务需求和策略,经济地自动调整弹性计算资源的管理服务。
弹性伸缩能力分为如下两个维度:
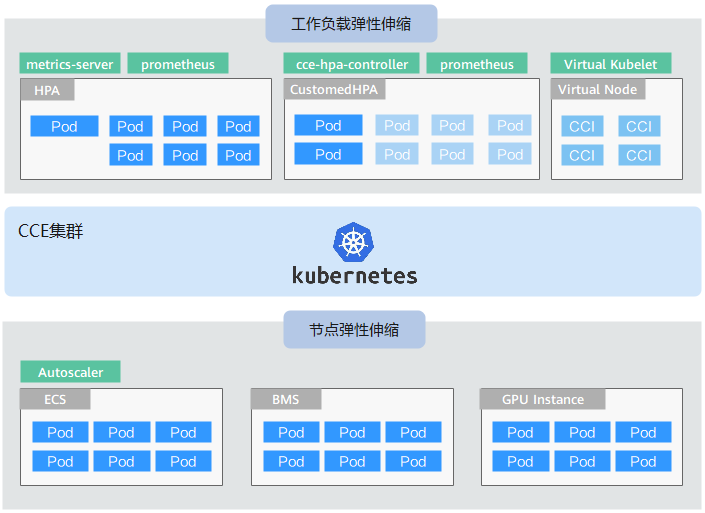
工作负载弹性伸缩:即调度层弹性,主要是负责修改负载的调度容量变化。例如,HPA是典型的调度层弹性组件,通过HPA可以调整应用的副本数,调整的副本数会改变当前负载占用的调度容量,从而实现调度层的伸缩。
节点弹性伸缩:即资源层弹性,主要是集群的容量规划不能满足集群调度容量时,会通过弹出ECS或CCI等资源的方式进行调度容量的补充。CCE容器实例弹性到CCI服务的方法请参见CCE容器实例弹性伸缩到CCI服务。
两个维度的弹性组件与能力可以分开使用,也可以结合在一起使用。
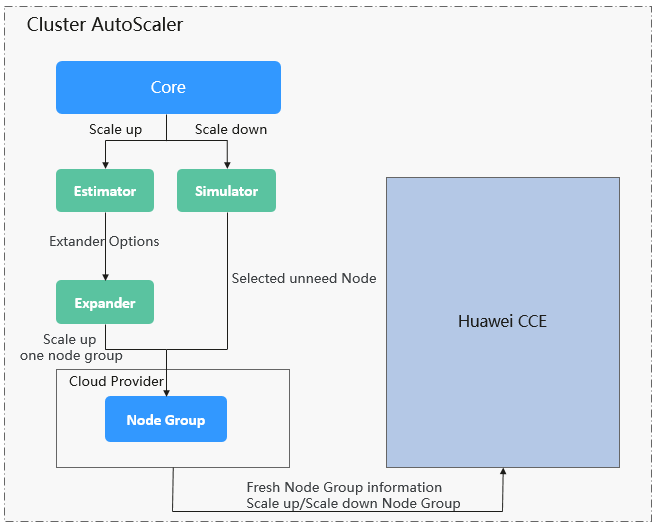
AutoScaler节点伸缩原理解析
Autoscaler是Kubernetes提供的集群节点弹性伸缩组件,根据Pod调度状态及资源使用情况对集群的节点进行自动扩容缩容。
Autoscaler(简称CA)的主要流程包括两部分:
ScaleUp流程:CA会每隔15s检查一次所有不可调度的Pod,根据用户设置的策略,选择出一个符合要求的节点组进行扩容。
ScaleDown流程:CA每隔10s会扫描一次所有的Node,如果该Node上所有的Pod Requests少于用户定义的缩容百分比时,CA会模拟将该节点上的Pod是否能迁移到其他节点,如果可以的话,当满足不被需要的时间窗以后,该节点就会被移除。
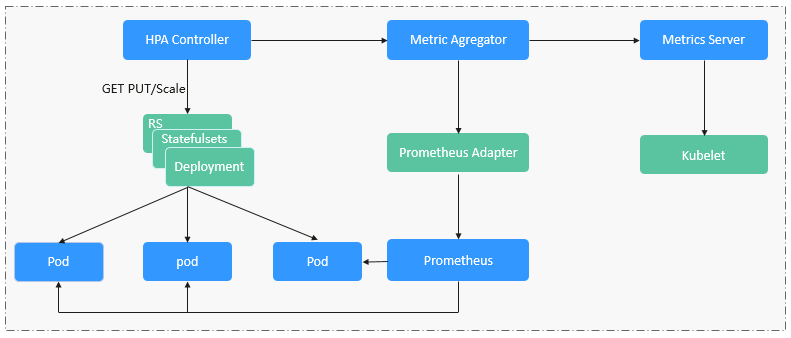
HPA工作负载伸缩原理解析
HPA(Horizontal Pod Autoscaler)是用来控制Pod水平伸缩的控制器,HPA周期性检查Pod的度量数据,计算满足HPA资源所配置的目标数值所需的副本数量,进而调整目标资源(如Deployment)的replicas字段。想要做到自动弹性伸缩,先决条件就是能感知到各种运行数据,例如集群节点、Pod、容器的CPU、内存使用率等等。而这些数据的监控能力Kubernetes也没有自己实现,而是通过其他项目来扩展Kubernetes的能力,CCE提供如下两个插件来实现该能力:
Prometheus是一套开源的系统监控报警框架,能够采集丰富的Metrics(度量数据),目前已经基本是Kubernetes的标准监控方案。
Metrics Server是Kubernetes集群范围资源使用数据的聚合器。Metrics Server从kubelet公开的Summary API中采集度量数据,能够收集包括了Pod、Node、容器、Service等主要Kubernetes核心资源的度量数据,且对外提供一套标准的API。
使用HPA(Horizontal Pod Autoscaler)配合Metrics Server可以实现基于CPU和内存的自动弹性伸缩,再配合Prometheus还可以实现自定义监控指标的自动弹性伸缩。
使用HPA+CA实现工作负载和节点联动弹性伸缩
弹性伸缩最主要的就是使用HPA(Horizontal Pod Autoscaling)和CA(Cluster AutoScaling)两种弹性伸缩策略,HPA负责工作负载弹性伸缩,也就是应用层面的弹性伸缩,CA负责节点弹性伸缩,也就是资源层面的弹性伸缩。
通常情况下,两者需要配合使用,因为HPA需要集群有足够的资源才能扩容成功,当集群资源不够时需要CA扩容节点,使得集群有足够资源;而当HPA缩容后集群会有大量空余资源,这时需要CA缩容节点释放资源,才不至于造成浪费。

创建HPA示例
创建一个HPA,期望CPU的利用率为70%,副本数的范围是1-10
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: scale
namespace: default
spec:
maxReplicas: 10 # 目标资源的最大副本数量
minReplicas: 1 # 目标资源的最小副本数量
metrics: # 度量指标,期望CPU的利用率为70%
- resource:
name: cpu
targetAverageUtilization: 70
type: Resource
scaleTargetRef: # 目标资源
apiVersion: apps/v1
kind: Deployment
name: nginx查看HPA
创建后查看HPA
$ kubectl create -f hpa.yaml
horizontalpodautoscaler.autoscaling/celue created
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
scale Deployment/nginx-deployment 0%/70% 1 10 4 18s可以看到,TARGETS的期望值是70%,而实际是0%,这就意味着HPA会做出缩容动作,期望副本数量=(0+0+0+0)/70=0,但是由于最小副本数为1,所以Pod数量会调整为1。等待一段时间,可以看到Pod数量变为1
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deployment-7cc6fd654c-5xzlt 1/1 Running 0 7m41s查看HPA详情,可以在Events里面看到这样一条记录。这表示HPA在21秒前成功的执行了缩容动作,新的Pod数量为1,原因是所有度量数量都比目标值低。
$ kubectl describe hpa scale
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulRescale 21s horizontal-pod-autoscaler New size: 1; reason: All metrics below target感谢您的阅读,也欢迎您发表关于这篇文章的任何建议,关注我,技术不迷茫!


喜欢就点个"在看"呗,留言、转发朋友圈


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









