




 本文介绍MyBatis中的动态SQL技术,包括if、choose、trim、set、foreach等元素的应用,并深入探讨了一级缓存和二级缓存的工作原理及配置方法。
本文介绍MyBatis中的动态SQL技术,包括if、choose、trim、set、foreach等元素的应用,并深入探讨了一级缓存和二级缓存的工作原理及配置方法。
文章目录
12.动态SQL
动态SQL就是根据不同的条件生成不同的SQL
所谓的动态SQL,本质还是SQL语句, 只是我们可以在SQL层面去执行一些逻辑代码
如果你之前用过 JSTL 或任何基于类 XML 语言的文本处理器,你对动态 SQL 元素可能会感觉似曾相识。在 MyBatis 之前的版本中,需要花时间了解大量的元素。借助功能强大的基于 OGNL 的表达式,MyBatis 3 替换了之前的大部分元素,大大精简了元素种类,现在要学习的元素种类比原来的一半还要少。
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
环境搭建
SQL
CREATE TABLE `blog`(
`id` VARCHAR(50) NOT NULL COMMENT '博客id',
`title` VARCHAR(100) NOT NULL COMMENT '博客标题',
`author` VARCHAR(30) NOT NULL COMMENT '博客作者',
`create_time` DATETIME NOT NULL COMMENT '创建时间',
`views` INT(30) NOT NULL COMMENT '浏览量'
)ENGINE=INNODB DEFAULT CHARSET=utf8;
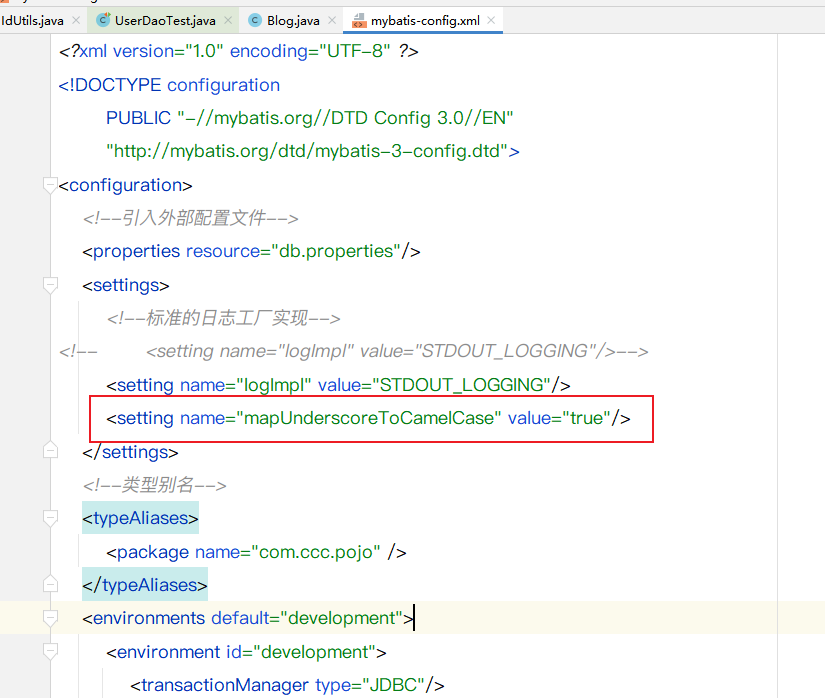
核心配置文件
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--引入外部配置文件-->
<properties resource="db.properties"/>
<settings>
<!--标准的日志工厂实现-->
<!-- <setting name="logImpl" value="STDOUT_LOGGING"/>-->
<setting name="logImpl" value="STDOUT_LOGGING"/>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<!--类型别名-->
<typeAliases>
<package name="com.ccc.pojo" />
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper class="com.ccc.dao.BlogMapper"/>
</mappers>
</configuration>
实体类
import java.util.Date;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Blog {
private String id;
private String title;
private String author;
private Date createTime; //属性名和字段名不一致 数据库是--create_time
private int views;
}
工具类-获取UUID
public class IdUtils {
public static String getID(){
//replaceAll("-","") 把-换成空
return UUID.randomUUID().toString().replaceAll("-","");
}
}

接口
public interface BlogMapper {
//插入数据
int addBlog(Blog blog);
}
mapper
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ccc.dao.BlogMapper">
<insert id="addBlog" parameterType="blog">
insert into blog (id, title, author, create_time, views)
values (#{id}, #{title}, #{author}, #{createTime}, #{views});
</insert>
</mapper>
测试类添加数据
import com.ccc.dao.BlogMapper;
import com.ccc.pojo.Blog;
import com.ccc.utils.IdUtils;
import com.ccc.utils.MybatisUtil;
import org.apache.ibatis.session.SqlSession;
import org.apache.log4j.Logger;
import org.junit.Test;
import java.util.Date;
import java.util.List;
public class BlogTest {
@Test
public void test(){
System.out.println(IdUtils.getID());
}
@Test
public void addBolg(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
Blog blog ;
blog = new Blog(IdUtils.getID(),"Mybatis哈哈","张三",new Date(),9999);
mapper.addBlog(blog);
blog = new Blog(IdUtils.getID(),"java哈哈","李四",new Date(),9999);
mapper.addBlog(blog);
blog = new Blog(IdUtils.getID(),"spring哈哈","网二",new Date(),9999);
mapper.addBlog(blog);
blog = new Blog(IdUtils.getID(),"mysql哈哈","麻子",new Date(),9999);
mapper.addBlog(blog);
sqlSession.close();
}
}
IF
使用动态 SQL 最常见情景是根据条件包含 where 子句的一部分。比如:
<select id="queryBlog" parameterType="map" resultType="blog">
select * from blog where 1=1
<if test="title != null">
and title like "%"#{title}"%"
</if>
<if test="author != null">
and author = #{author}
</if>
<if test="views != null">
and views = #{views}
</if>
</select>
测试
@Test
public void queryBlog(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap<Object, Object> map = new HashMap<>();
map.put("title","哈哈");
List<Blog> blogs = mapper.queryBlog(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
sqlSession.close();
}
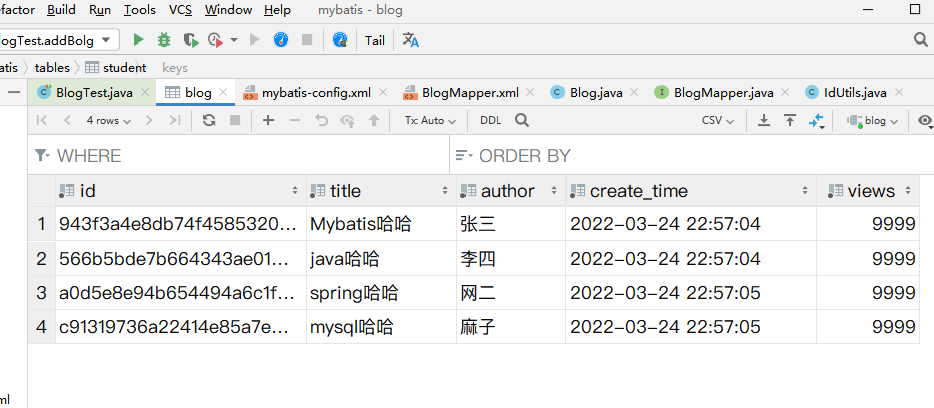
Blog(id=943f3a4e8db74f4585320f2514106417, title=Mybatis哈哈, author=张三, createTime=Thu Mar 24 22:57:04 CST 2022, views=9999)
Blog(id=566b5bde7b664343ae015c005b71a810, title=java哈哈, author=李四, createTime=Thu Mar 24 22:57:04 CST 2022, views=9999)
Blog(id=a0d5e8e94b654494a6c1fc1d804b258e, title=spring哈哈, author=网二, createTime=Thu Mar 24 22:57:05 CST 2022, views=9999)
Blog(id=c91319736a22414e85a7ebe15f002037, title=mysql哈哈, author=麻子, createTime=Thu Mar 24 22:57:05 CST 2022, views=9999)
trim、where、
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
<where>
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</where>
</select>
where 元素只会在子元素返回任何内容的情况下才插入 “WHERE” 子句。而且,若子句的开头为 “AND” 或 “OR”,where 元素也会将它们去除。
set
set 元素会动态地在行首插入 SET 关键字,并会删掉额外的逗号(这些逗号是在使用条件语句给列赋值时引入的)。
<update id="updateBlog" parameterType="map">
update blog
<set>
<if test="title != null">
title = #{title}
</if>
<if test="author != null">
author = #{author}
</if>
<if test="views != null">
views = #{views}
</if>
</set>
where id = #{id};
</update>
choose (when, otherwise)
有时候,我们不想使用所有的条件,而只是想从多个条件中选择一个使用。针对这种情况,MyBatis 提供了 choose 元素,它有点像 Java 中的 switch 语句。
还是上面的例子,但是策略变为:传入了 “title” 就按 “title” 查找,传入了 “author” 就按 “author” 查找的情形。若两者都没有传入,就返回标记为 featured 的 BLOG(这可能是管理员认为,与其返回大量的无意义随机 Blog,还不如返回一些由管理员挑选的 Blog)。
- 只有一个条件会成立, 如果三个属性都有, 进入第一个就不会进下面了
<select id="queryBlogChoose" parameterType="map" resultType="blog">
select * from blog
<where>
<choose>
<when test="title != null">
title like "%"#{title}"%"
</when>
<when test="author != null">
and author = #{author}
</when>
<otherwise>
views = #{views}
</otherwise>
</choose>
</where>
</select>
SQL片段
- 可以把公用的地方抽出来, 方便复用
- 需要使用的地方使用
include导入即可
<sql id="if-t-a-v">
<if test="title != null">
title like "%"#{title}"%"
</if>
<if test="author != null">
and author = #{author}
</if>
<if test="views != null">
and views = #{views}
</if>
</sql>
<select id="queryBlogChoose" parameterType="map" resultType="blog">
select * from blog
<where>
<include refid="if-t-a-v"/>
</where>
</select>
注意事项:
- 最好基于单标来定义SQL片段
- 最好不要存在where和set标签
ForEach
动态 SQL 的另一个常见使用场景是对集合进行遍历(尤其是在构建 IN 条件语句的时候)
foreach 元素的功能非常强大,它允许你指定一个集合,声明可以在元素体内使用的集合项(item)和索引(index)变量。它也允许你指定开头与结尾的字符串以及集合项迭代之间的分隔符。这个元素也不会错误地添加多余的分隔符,看它多智能!
提示 你可以将任何可迭代对象(如 List、Set 等)、Map 对象或者数组对象作为集合参数传递给 foreach。当使用可迭代对象或者数组时,index 是当前迭代的序号,item 的值是本次迭代获取到的元素。当使用 Map 对象(或者 Map.Entry 对象的集合)时,index 是键,item 是值。
<!--
select * from blog where (id=1 or id=2 or id=3)
传入的参数是map, map中可以放一个集合
collection 集合是什么
item 参数
open 由什么开始 close 由什么结束
separator 从什么地方分割
-->
<select id="queryBlogForeach" resultType="blog" parameterType="map">
select * from blog
<where>
<foreach collection="ids" item="id" open="(" close=")" separator="or">
id = #{id}
</foreach>
</where>
</select>
测试
@Test
public void queryBlogForeach(){
SqlSession sqlSession = MybatisUtil.getSqlSession();
BlogMapper mapper = sqlSession.getMapper(BlogMapper.class);
HashMap<Object, Object> map = new HashMap<>();
ArrayList<Object> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
map.put("ids",list);
List<Blog> blogs = mapper.queryBlogForeach(map);
for (Blog blog : blogs) {
System.out.println(blog);
}
sqlSession.close();
}
13.缓存
- 1.什么是缓存[Cache ]?
- 存在内存中的临时数据。
- 将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查
询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。
- 2.为什么使用缓存?
- 减少和数据库的交互次数,减少系统开销,提高系统效率。
- 3.什么样的数据能使用缓存?
- 经常查询并且不经常改变的数据。【可以使用缓存】
13.2, Mybatis缓存
- MyBatis包含一个非常强大的查询缓存特性,|它可以非常方便地定制和配置缓存。缓存可以极大的提升查询效率。
- MyBatis系统中默认定义了两级缓存:一级缓存和二级缓存
- 默认情况下,只有一级缓存开启。(SqlSession级别的缓存,也称为本地缓存)
- 二级缓存需要手动开启和配置,他是基于namespace级别的缓存。
- 为了提高扩展性, MyBatis定义了缓存接口Cache。我们可以通过实现Cache接口来自定义二级缓存
可用的清除策略有:
LRU– 最近最少使用:移除最长时间不被使用的对象。FIFO– 先进先出:按对象进入缓存的顺序来移除它们。SOFT– 软引用:基于垃圾回收器状态和软引用规则移除对象。WEAK– 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
默认的清除策略是 LRU。
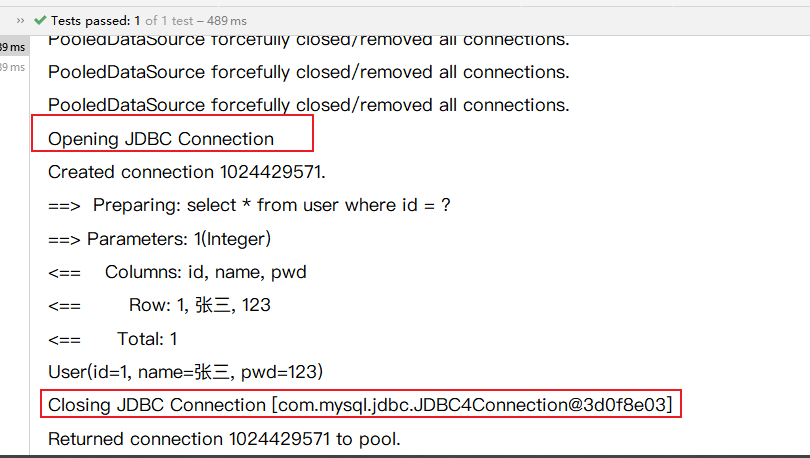
13.3.一级缓存
- 一级缓存也叫本地缓存: SqISession
- 与数据库同一次会话期间查询到的数据会放在本地缓存中。
- 以后如果需要获取相同的数据,直接从缓存中拿,没必须再去查询数据库;
缓存失效了
缓存失效的情况
- 1增删该操作, 可能改变了原来的数据
- 2查询不同的mapper
- 3手动清理缓存
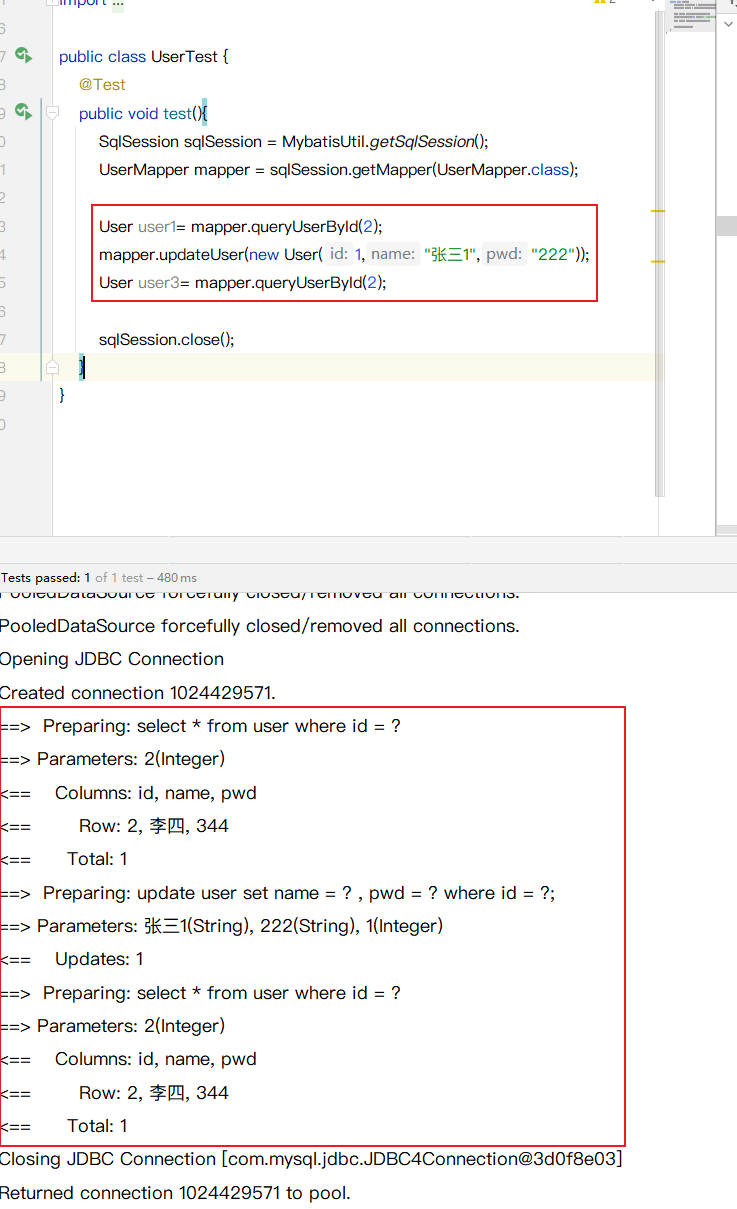
1增删该操作, 可能改变了原来的数据
查询了2次 2 只走了一次SQL
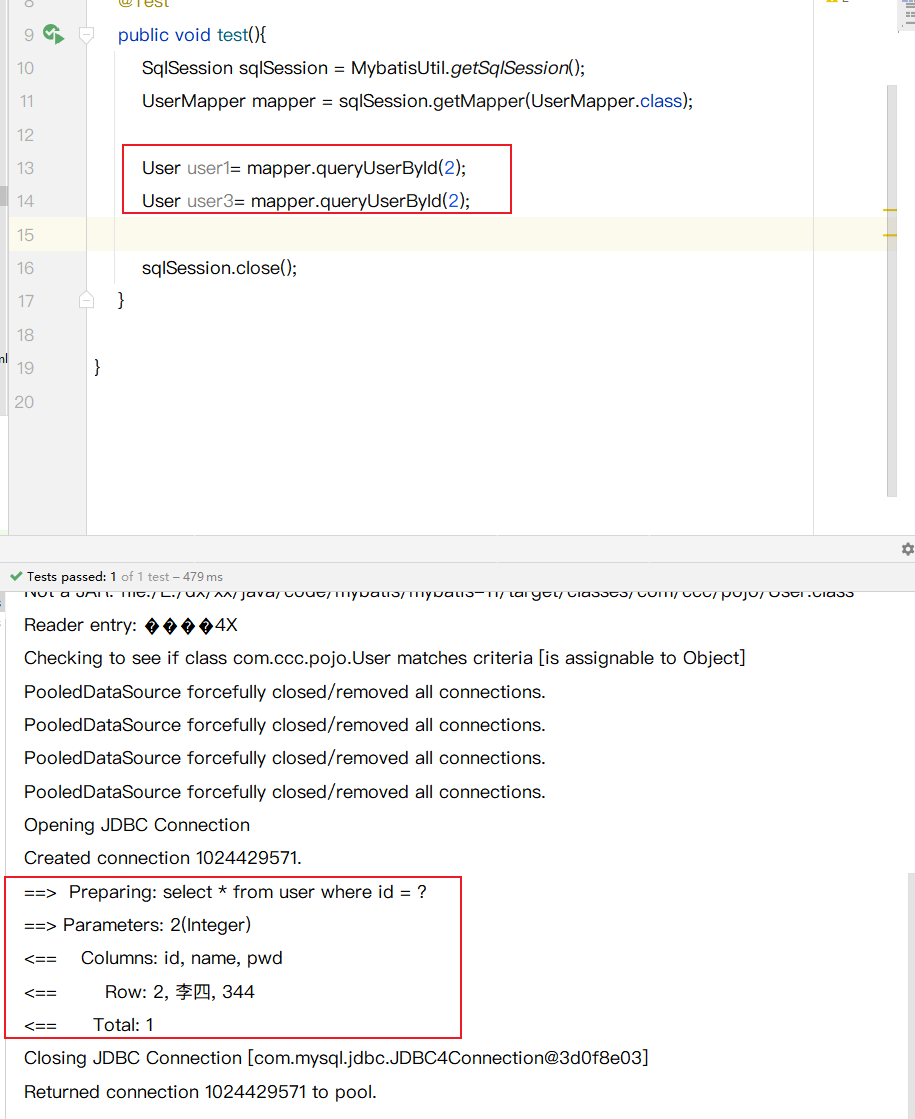
中间添加一个修改操作, 就刷新了缓存
3手动清理缓存
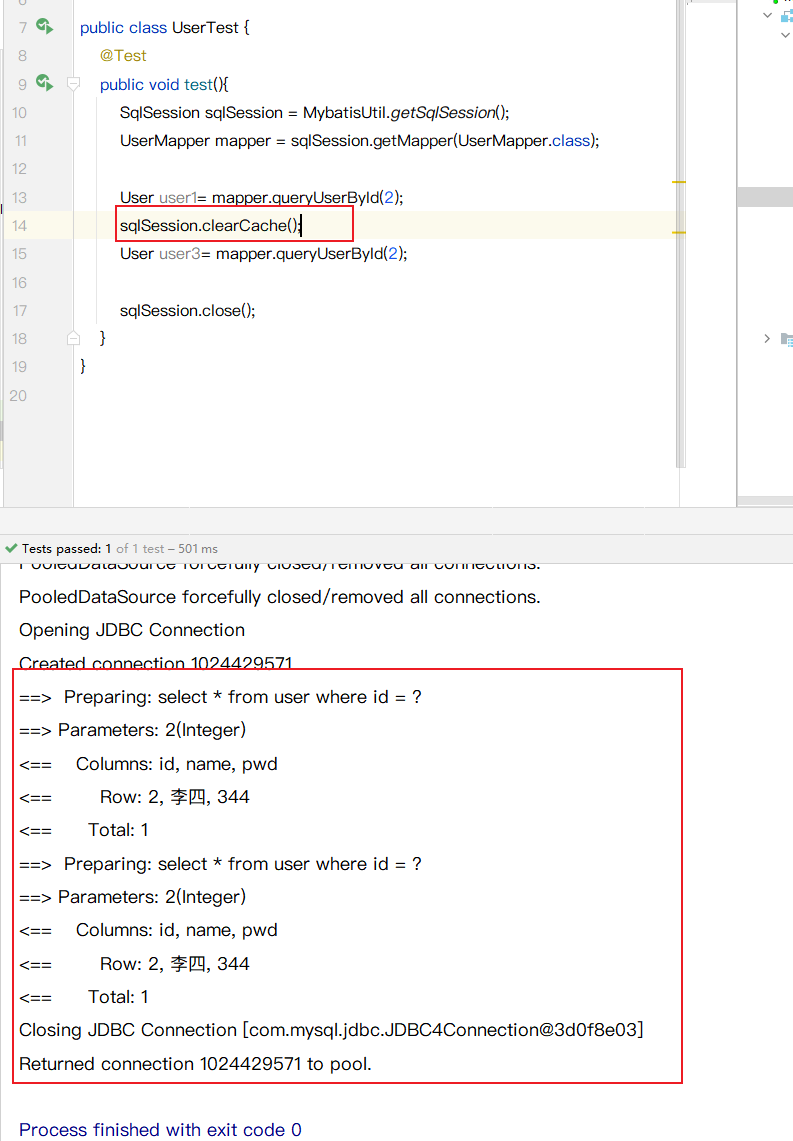
一级缓存小结
- 一级缓存是默认开启的
- 只在一次sqlsession中有用
- 拿到连接到关闭连接这个时间段
13.4.二级缓存
-
二级缓存也叫全局缓存,一级缓存作用域太低了,所以诞生了二级缓存
-
基于namespace级别的缓存,一个名称空间,对应一个二级缓存;
-
工作机制
-
一个会话查询一条数据,这个数据就会被放在当前会话的一级缓存中;
-
如果当前会话关闭了,这个会话对应的一级缓存就没了;但是我们想要的是,会话关闭了,一级缓存中的
-
数据被保存到二级缓存中;
-
新的会话查询信息,就可以从二级缓存中获取内容;
-
不同的mapper查出的数据会放在自己对应的缓存(map)中;
-
步骤
1开启全局缓存
<setting name="cacheEnabled" value="true"/>
| 设置名 | 描述 | 有效值 | 默认值 |
|---|---|---|---|
| cacheEnabled | 全局性地开启或关闭所有映射器配置文件中已配置的任何缓存。 | true |
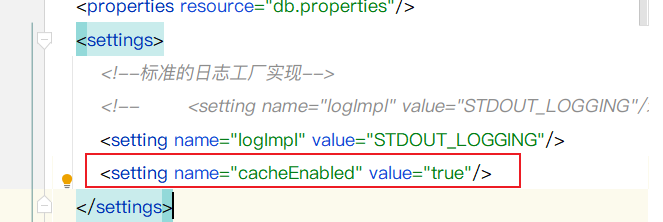
2.Mapper中添加cache标签
<cache/>
这些属性可以通过 cache 元素的属性来修改。比如:
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
3.测试
没加缓存之前
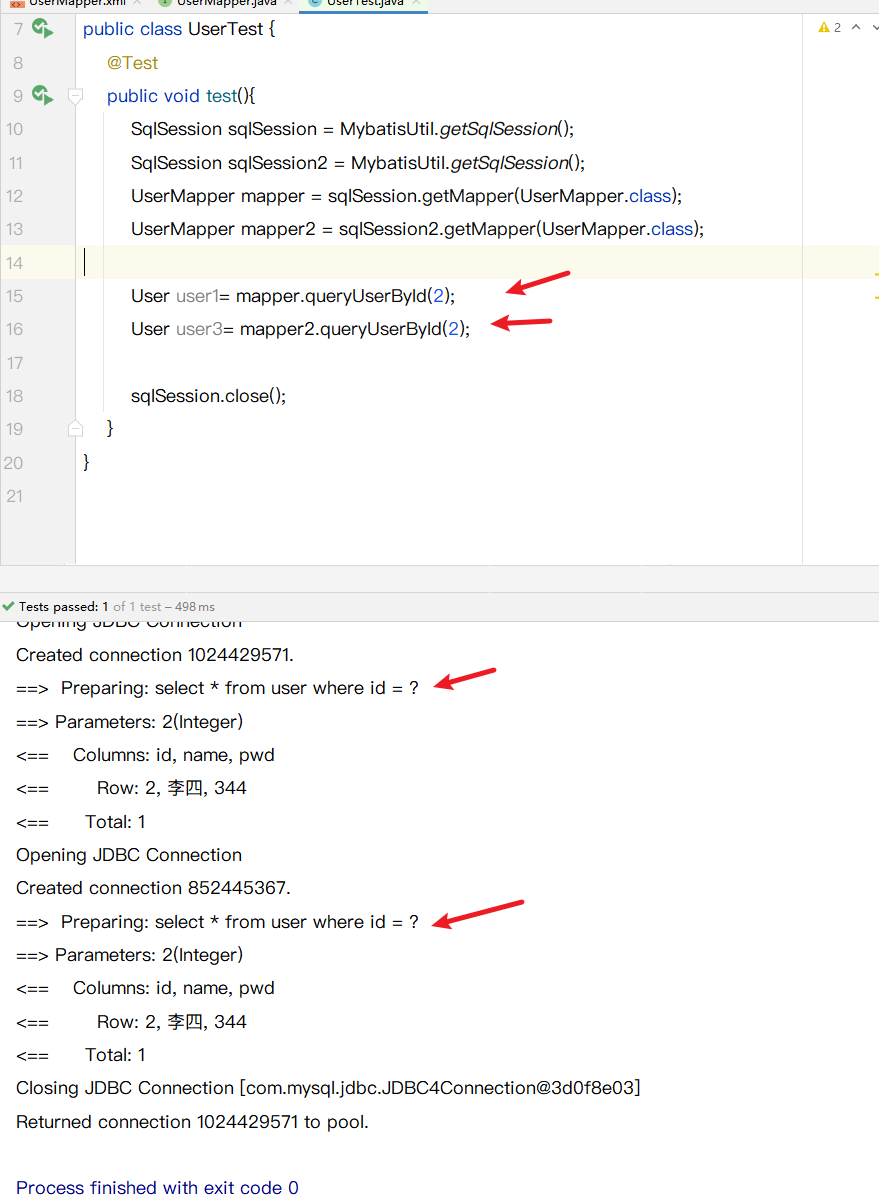
添加缓存之后
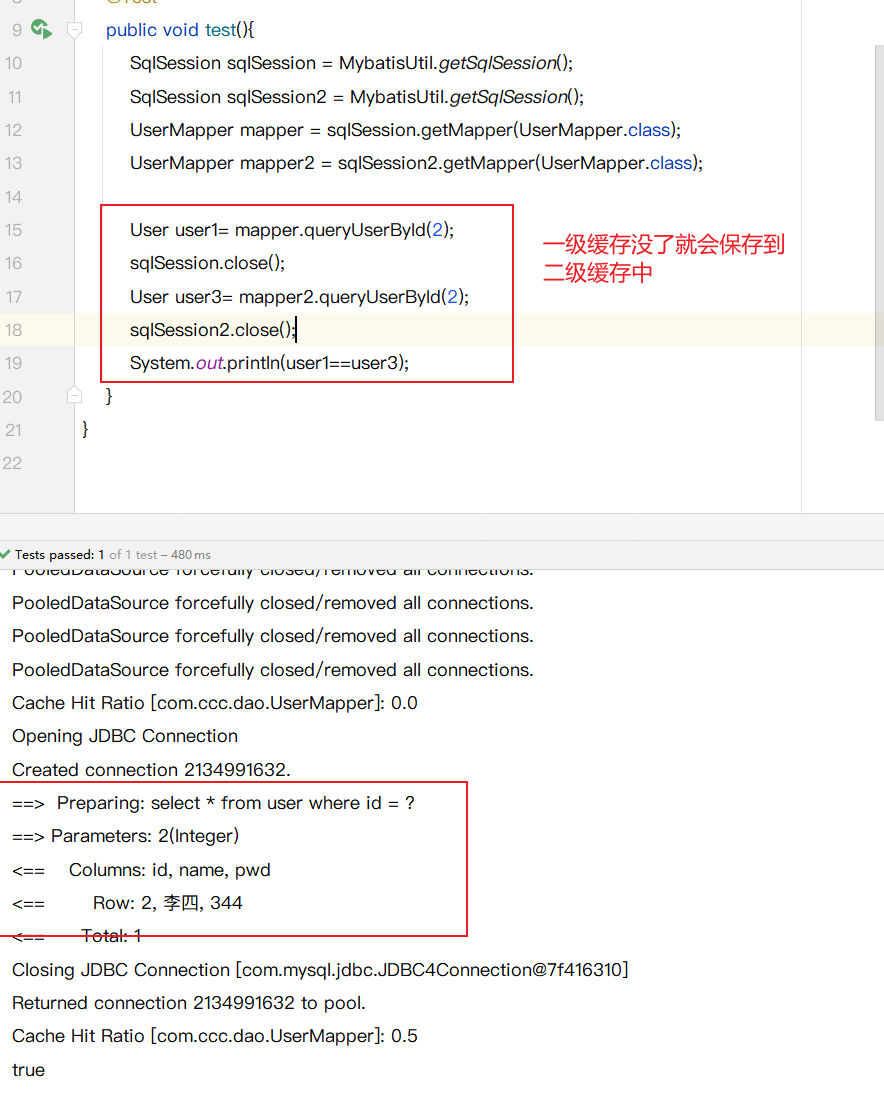
二级缓存小结
- 只要开启了二级缓存, 在同一个Mapper下就有效
- 所有数据都会先放在一级缓存中
- 只有当会话提交, 或者关闭的时候,才会保存到二级缓存中
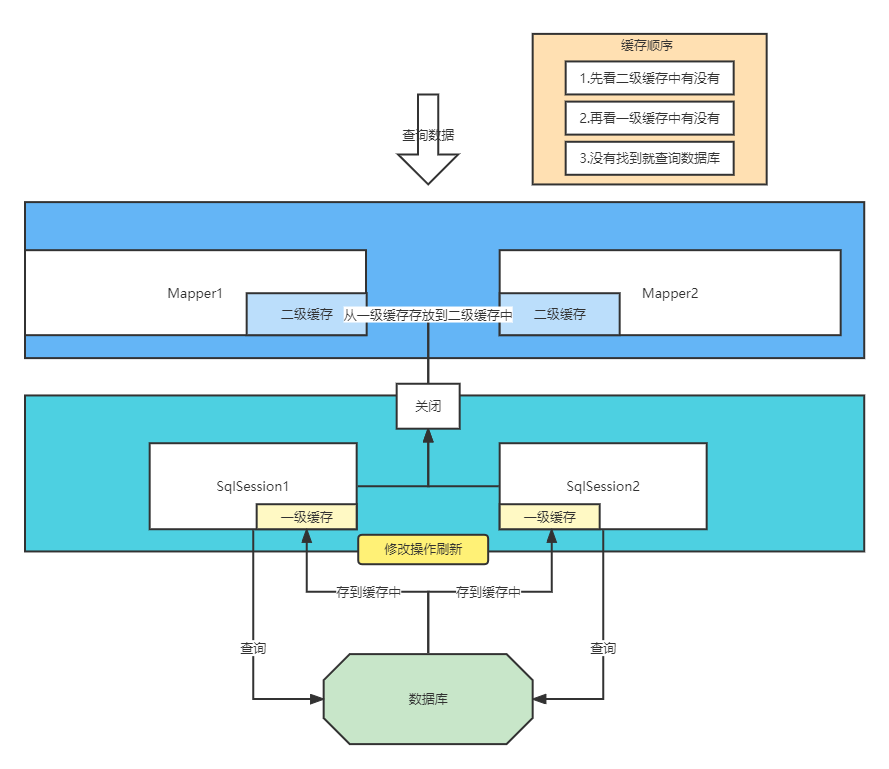
13.5.缓存原理
- 1,先看二级缓存有没有数据(一个Mapper中)
- 2,没有再查看一级缓存有没有(一个SqlSession中)
- 3,都没有就到数据库查询

















 1770
1770

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









