 程序员吐槽前人代码现象探讨
程序员吐槽前人代码现象探讨




 本文围绕程序员对前人代码的看法展开。提到职场论坛上刚入职百度一周的新员工抱怨前人代码烂,网友评论也多有共鸣。还分析了这种现象,有人认为代码垃圾不易被裁等,最后呼吁程序员不必相互指责,还介绍了知识星球及获取进阶资源的方式。
本文围绕程序员对前人代码的看法展开。提到职场论坛上刚入职百度一周的新员工抱怨前人代码烂,网友评论也多有共鸣。还分析了这种现象,有人认为代码垃圾不易被裁等,最后呼吁程序员不必相互指责,还介绍了知识星球及获取进阶资源的方式。
热文导读| 点击标题阅读
裸辞两个月,海投一个月,从 Android 转战 Web 前端的求职之路
今天在浏览某职场论坛时,发现了如下的帖子。这个帖子一下子吸引了我的眼球。
这名刚入职百度才一周的新员工发帖抱怨说:看前人代码不忍直视,那代码写的跟一坨屎一样。完全颠覆了他之前的认知和对所谓大厂的憧憬。
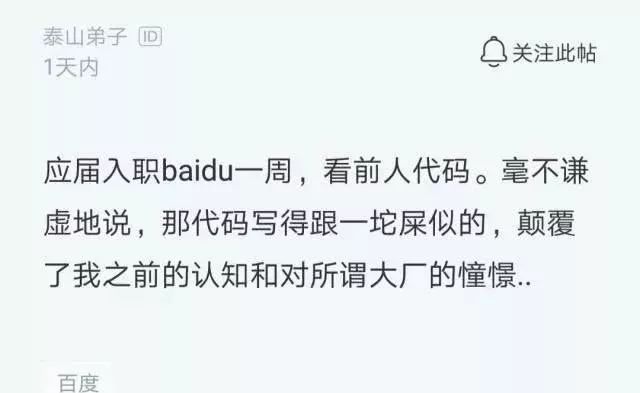
大家是不是觉得说出了大家的心声,是不是你也觉得前人的代码想一坨屎?是不是也有似曾相似的感觉?
“卧槽,这是谁写的代码?真烂”,曾经,当你看别人代码的时候,是不是心底不由自主的发出这一句。
看帖子下面的评论就知道了,很多网友发出了这样的感叹,表示彼此彼此。作为程序员的我们都会有这种感受:确实,有很多屎一样的老项目,但等你去其他厂,你可能会发现这坨屎居然有点香。
还有网友评论说等你准备重构这代码的时候,你会发现这屎冲了厕所就塌了;新人总觉得别人是屎;当你离职时回顾自己的遗产,发现也是一坨屎;果然大家都是一样的,没人交接的项目满满的就变成屎山了。
是不是评论的也很有道理。
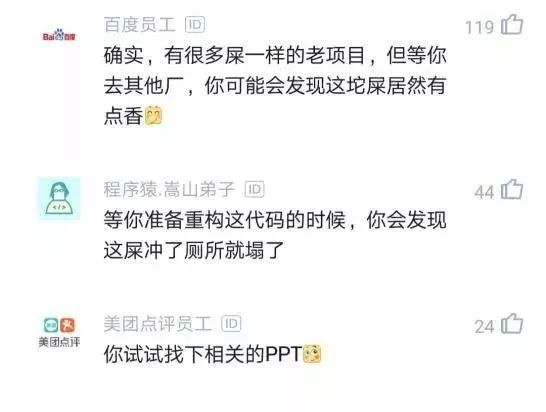
看评论就知道了,网友观点一边到,不过,有些网友也很冷静。自己虽然也会觉得前人的代码写的烂,但当自己离职了,后来接手者也会有同样的感受。
比如另外一些网友的评论:新人都觉得别人代码烂,自己写连屎都不如;取其精华,去其糟粕就好啦;大厂就像围城,里面的不想出来,外面的人进不去;过一年看你自己的代码,也是屎一样;程序员都是这样,看谁的代码都要喷,连自己以前写的也不放过;软件开发不是永远能先理想的设计,很多是历史迭代再迭代的原因,不过新人嘛,到哪都自己最牛,别人都是屎,正常;
不过,还有人给这种现象找出了另一种解释:代码越垃圾越不容易被裁;前人晋升后留下的,后人做好了也没产出,就这么传下去了。当然,对于这种解释,我是不认同的,你们觉得呢?
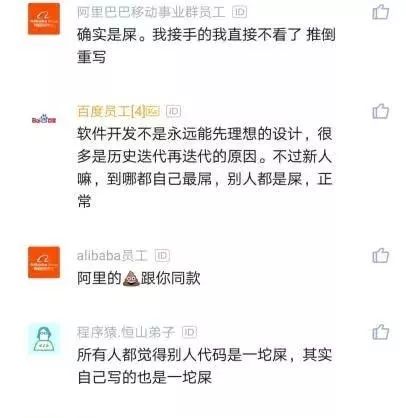
所以,最后我想说一句:前人复又前人,“冤冤相报何时了”,程序员996已经够惨了,何必相煎太急呢?
大家如何觉得呢?请说说你们的看法。更多学习和讨论,欢迎加入我们的知识星球,这里有1000+小伙伴,让你的学习不寂寞~·
看完本文有收获?请转发分享给更多人
我们的知识星球第三期开期了,已达到1100人了,能连续做三期已很不容易了,有很多老用户续期,目前续期率达到50%,说明了大家对我们的知识星球还是很认可的,欢迎大家加入尽早我们的知识星球,更多星球信息参见:
说两件事

微信扫描或者点击上方二维码领取的Android \ Python的\ AI \的Java等高级进阶资源
更多学习资料点击下面的“阅读原文 ”获取

谢谢老板,点个好看↓

















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









