




c语言中的宽字符
使用ASCII编码:
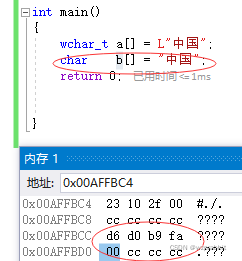
可以看到是以一个00结尾,所以”中国“占5个字节
使用unicode编码:
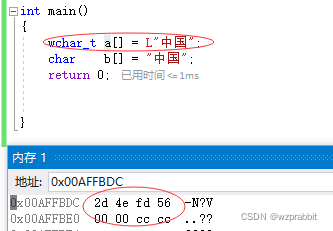
可以看到是两个00结尾,因为UTF-16的基本单位就是两个字节。所以“中国“占6个字节
char wchar_t //多字节字符类型 宽字符类型 printf wprintf //打印到控制台函数 strlen wcslen //获取长度 strcpy wcscpy //字符串复制 strcat wcscat //字符串拼接 strcmp wcscmp //字符串比较
 C语言与Unicode编码:宽字符与字符串处理
C语言与Unicode编码:宽字符与字符串处理
 本文探讨了C语言中宽字符的概念,通过ASCII和Unicode编码的对比展示了'中国'在不同编码下所占字节数。同时介绍了C语言中处理宽字符的类型如wchar_t,以及对应的字符串处理函数,如wprintf、wcslen等。理解宽字符在内存中的存储和处理对于进行多语言编程至关重要。
本文探讨了C语言中宽字符的概念,通过ASCII和Unicode编码的对比展示了'中国'在不同编码下所占字节数。同时介绍了C语言中处理宽字符的类型如wchar_t,以及对应的字符串处理函数,如wprintf、wcslen等。理解宽字符在内存中的存储和处理对于进行多语言编程至关重要。
c语言中的宽字符
使用ASCII编码:
可以看到是以一个00结尾,所以”中国“占5个字节
使用unicode编码:
可以看到是两个00结尾,因为UTF-16的基本单位就是两个字节。所以“中国“占6个字节
char wchar_t //多字节字符类型 宽字符类型 printf wprintf //打印到控制台函数 strlen wcslen //获取长度 strcpy wcscpy //字符串复制 strcat wcscat //字符串拼接 strcmp wcscmp //字符串比较
 943
943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





























