




 本文详细介绍了如何在Elasticsearch中配置索引模板、设置及映射,并提供了Java代码示例。深入探讨了analyzer与filter的区别,以及如何通过配置实现高效搜索。
本文详细介绍了如何在Elasticsearch中配置索引模板、设置及映射,并提供了Java代码示例。深入探讨了analyzer与filter的区别,以及如何通过配置实现高效搜索。
创建索引模板
以下参数配置定义官网都有介绍,这块就直接记录官网的地址,方便查阅。
索引模板的具体参数参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/indices-templates-v1.html
索引setting具体参数参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/index-modules.html#index-modules-settings
索引mapping具体参数参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/mapping.html
由于参数定义很多,就不在复制到文中。
一般创建索引要么在kibana中创建,要么代码创建,
java代码创建:
CreateIndexRequest request = new CreateIndexRequest(index);
request.settings("配置json");
request.mapping("配置json");
try {
CreateIndexResponse indexResponse = restHighLevelClient.indices().create(request);
if (indexResponse.isAcknowledged()) {
log.info("创建索引成功");
} else {
log.info("创建索引失败");
}
return indexResponse.isAcknowledged();
} catch (Exception e) {
e.printStackTrace();
}配置json代码参考:
{
"template": "*",
"order": 0,
"version": 60001,
"settings": {
"index": {
"refresh_interval": "5s",
"analysis": {
"filter": {
"edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},
"pinyin_simple_filter": {
"type": "pinyin",
"keep_first_letter": true,
"keep_separate_first_letter": false,
"keep_full_pinyin": false,
"keep_original": false,
"limit_first_letter_length": 50,
"lowercase": true
},
"pinyin_full_filter": {
"type": "pinyin",
"keep_first_letter": false,
"keep_separate_first_letter": false,
"keep_full_pinyin": true,
"none_chinese_pinyin_tokenize": true,
"keep_original": false,
"limit_first_letter_length": 50,
"lowercase": true
}
},
"analyzer": {
"ngramIndexAnalyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": [
"edge_ngram_filter",
"lowercase"
]
},
"ngramSearchAnalyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": [
"lowercase"
]
},
"ikIndexAnalyzer": {
"type": "custom",
"tokenizer": "ik_smart"
},
"ikSearchAnalyzer": {
"type": "custom",
"tokenizer": "ik_smart"
},
"pinyiSimpleIndexAnalyzer": {
"tokenizer": "keyword",
"filter": [
"pinyin_simple_filter",
"edge_ngram_filter",
"lowercase"
]
},
"pinyiSimpleSearchAnalyzer": {
"tokenizer": "keyword",
"filter": [
"pinyin_simple_filter",
"lowercase"
]
},
"pinyiFullIndexAnalyzer": {
"tokenizer": "keyword",
"filter": [
"pinyin_full_filter",
"lowercase"
]
},
"pinyiFullSearchAnalyzer": {
"tokenizer": "keyword",
"filter": [
"pinyin_full_filter",
"lowercase"
]
}
}
}
}
},
"mappings": {
"doc": {
"properties": {
"simplePyTitle": {
"type": "text",
"norms": false,
"analyzer": "ngramIndexAnalyzer",
"search_analyzer": "ngramSearchAnalyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}
}上边的配置文件中只配置了一个索引字段simplePyTitle。具体每个字段的含义参考官网。
这里边要知道analyzer和search_analyzer的区别:
分析器主要有两种情况会被使用:
第一种是插入文档时,将text类型的字段做分词然后插入倒排索引,
第二种就是在查询时,先对要查询的text类型的输入做分词,再去倒排索引搜索
如果想要让 索引 和 查询 时使用不同的分词器,ElasticSearch也是能支持的,只需要在字段上加上search_analyzer参数
在索引时,只会去看字段有没有定义analyzer,有定义的话就用定义的,没定义就用ES预设的
在查询时,会先去看字段有没有定义search_analyzer,如果没有定义,就去看有没有analyzer,再没有定义,才会去使用ES预设的
filter和analyzer的区别。
简单说,Document中的数据是如何转变成倒排索引的,以及查询语句是如何转换成一个个词(Term)使高效率文本搜索变得可行,这种转换数据的过程就称为文本分析(analysis)。
analysis 基本概念 === elasticsearch全文搜索引擎会用某种算法(Tokenizer)对要建索引的文档进行分析, 从文档中提取出若干Token(词元), 这些算法称为Tokenizer(分词器), 这些Token会被进一步处理, 比如转成小写等, 这些进一步的处理算法被称为Filter(过滤器), 被处理后的结果被称为Term(词), 文档中包含了几个这样的Term被称为Frequency(词频)。 引擎会建立Term和原文档的Inverted Index(倒排索引), 这样就能根据Term很快到找到源文档了。
文本分析(analysis)工作由analyzer(分析器)组件负责。analyzer由一个分词器(tokenizer)和0个或者多个过滤器(filter)组成,也可能会有0个或者多个字符映射器(character mappers)组成。
tokenizer用来把文本拆分成一个个的Token。Token包含了比较多的信息,比如Term在文本的中的位置及Term原始文本,以及Term的长度。文本经过tokenizer处理后的结果称为token stream。token stream其实就是一个个Token的顺序排列。token stream将等待着filter来处理。
filter链将用来处理Token Stream中的每一个token。这些处理方式包括删除Token,改变Token,甚至添加新的Token。比如变小写,去掉里面的HTML标记, 这些处理的算法被称为Character Filter(字符过滤器),Elasticsearch中内置了许多filter,读者也可以轻松地自己实现一个filter。
参考文章:https://blog.youkuaiyun.com/weixin_43197795/article/details/108209111
使用profile查看es执行细节
在操作es时,它的内部是如何执行的呢?可以设置profile:true来查看操作细节:
GET /my-index-000001/_search
{
"profile": true,
"query" : {
"match" : { "message" : "GET /search" }
}
}返回结果如下:
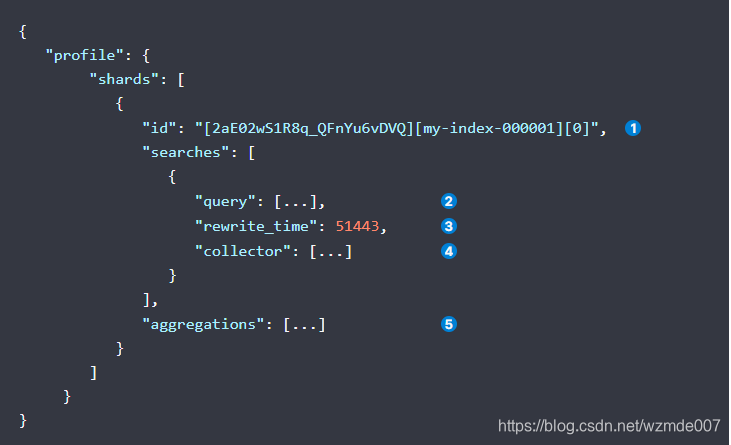
1、代表在es的某个分片上的信息
2、查询的详细信息
3、累计重写时间
4、Lucene收集器信息
5、聚合操作的信息
更多详细内容参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/search-profile.html
索引字段解释
就拿上边配置的索引字段simplePyTitle举例,解释下各个参数的作用:
"simplePyTitle": {
"type": "text",
"norms": false,
"analyzer": "ngramIndexAnalyzer",
"search_analyzer": "ngramSearchAnalyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
}type:字段类型,一般文本都是用text
norms:是否计算分值,false关闭,true会打开,开启后会增加存储等开销。一般不需要对比分值的字段建议关闭
analyzer:分词器名称,名称对应setting中配置的分词器名称。ngramIndexAnalyzer配置如下:
"ngramIndexAnalyzer": {
"type": "custom",
"tokenizer": "keyword",
"filter": [
"edge_ngram_filter",
"lowercase"
]
},type:分词器类型,es有多种分词器类型,custom代表自定义的分词器。默认为stardard。custom分词器更多介绍参考官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/analysis-custom-analyzer.html
tokenizer:分词器名称keyword,keyword类型会将字段的整体内容加入到倒排索引,不会再分词。比如存储的字段simplePyTitle内容为“你好周杰伦”,那么存入倒排索引的内容就是“你好周杰伦”不会分为“你好”,“周杰伦”等内容。
filter:该字段是将分词器分完后的结果做filter处理,处理后再放入到倒排索引中,该配置中的"edge_ngram_filter"参考上边关于它的配置:
"edge_ngram_filter": {
"type": "edge_ngram",
"min_gram": 1,
"max_gram": 50
},配置中的1,50代表会将插入到倒排索引前的数据做处理,处理为2个字段,分别为从头数的第一个字符和从头数1到50长的字符。
比如要存储的字符为abcd...........z....x,假如z为第50个字符,那么会被分为a和abcd.......z连个数据存入到倒排索引。
filter中的lowercase就是将有大写的转为小写。很好理解。
fields:当索引中的某个字段,即要满足全文检索的需要,又有排序聚合搜索等功能时,就需要fields的设置,比如上边的配置,text适合全文检索,而fields中定义的keyword更适合排序和聚合就需要配置成这样。参考官网文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/multi-fields.html
检索方式
首先要知道索引查询term,match,match_phase,query_string之间的区别,
参考文章:https://blog.youkuaiyun.com/feinifi/article/details/100512058
构建各混合查询,bool query、boosting query、constant_score query、dis_max query、function_score query
对于混合查询,官网写的很nice了:https://www.elastic.co/guide/en/elasticsearch/reference/7.9/compound-queries.html
分词器无法识别的分词
一些词汇,分词器可能无法识别,就需要自定义分词字典库,es会看字典库是符合的分词。
后续还会补充。。

















 1889
1889

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









