



 本文详细介绍了深度学习网络的训练过程,包括基本的运算步骤、mini-batch梯度下降、带动量的梯度下降、自适应学习率优化方法如Adam,以及目标函数和网络参数初始化的重要性。此外,还探讨了迁移学习的应用和处理样本不均衡问题的策略。
本文详细介绍了深度学习网络的训练过程,包括基本的运算步骤、mini-batch梯度下降、带动量的梯度下降、自适应学习率优化方法如Adam,以及目标函数和网络参数初始化的重要性。此外,还探讨了迁移学习的应用和处理样本不均衡问题的策略。
网络训练
1.1 网络运算的基本过程
神经网络的参数更新方法是基于一阶导数的梯度下降方法,网络的运算包含两个交替进行的步骤:数据的前向运算和误差的反向传播。在前向运算中,输入数据经过网络逐层变换,形成神经网络的预测值。网络的预测值和数据的真值(称为标签)进行比对,通过损失函数来刻画预测值与真值的误差。在后向运算中,损失函数对网络参数求梯度并逐层反传,各层连接权依靠反传梯度进行更新。
1.2 mini-batch梯度下降

1.3 带有动量的梯度下降
当参数点落入“山谷” ,即在某一方向比另外方向更加陡峭时,梯度下降法往往不能有效进行。参数会沿着地势更加陡峭的方向反复震荡,而在地势相对平缓的区域下降缓慢。这种情况常常出现在接近局部最优点的情况下。图2-16通过等高线展示了参数点在遇到山谷地形时的优化特点,可以看到,参数点震荡的方向几乎正交于局部最优的方向,这样的迭代无疑是非常低效的。 为了改善这种

1.4 自适应学习率的梯度下降
梯度下降的另一个主要问题是学习率的调整问题。学习率控制了梯度下降时每一步更新的步长,过大的学习率会导致收敛效果较差,参数点在最优点附近来回震荡。而过小的学习率会带来训练缓慢,容易陷入局部最优点的问题。通常,我们希望在训练一开始能够使用较大的学习率,促进网络快速收敛。而在训练的中后期使用较小的学习率,保证收敛效果。同时,我们希望对参数集θ中的不同参数,能够提供自适应的学习率。常见的自适应学习率梯度下降方法包括Adagrad [27] ,Adadelta [68] ,RMSprop À ,Adam [28] 等。其中,Adagrad对不同的参数设置不同的学习率,参数更新约频繁,其学习率越小,因此特别适合于稀疏数据。Adadelta、RMSprop和Adam均是对Adagrad的扩展,主要解决了Adagrad中学习率随训练的进行逐步减少,不可逆转的缺点.
1.5 目标函数

目标函数通常还会增加额外的正则项以对网络参数进行正则,这点在后面将会介绍。
1.6 网络参数初始化
适当的初始化策略能够帮助网络训练的更快、更深。尽管BatchNormalization的出现大大降低了网络对初始参数的敏感度,但适当的初始化策略对网络训练仍然极有帮助。权重的初始化的基本准则是,不能把所有的权重设为同样的值,因为如果权重值全部相同,则一层中所有神经元都会产生相同的输出,并获得相同的梯度,不管经过多少次训练,最后所得到的权重值仍然会相同。典型的初始化方法包括从均匀分布中生成初始参数,从正态分布中生成参数等。
简单的随机初始化往往效果较差,事实上,可以通过理论分析为不同的激活函数推导出适当的初始化方法。在假设网络内部只有线性变换的条件下(尽管该条件并不满足),通过假设网络前向产生的各层输出与后向运算产生的各层反传梯度方差均保持不变,推导出了权重应服从的均匀分布的上下边界,这种推导基于的是0均值激活函数Tanh。感兴趣的可以了解适合ReLU和PReLU激活函数的初始化方案。
1.7 迁移学习
迁移学习的基本原理根植于深度学习分层特征抽取的特点上。以图像处理为例,卷积神经网络的底层通常被认为用以提取如边缘、角点等底层特征,而高层用于提取更抽象更具有语义信息的特征。需要提取的高层特征根据具体任务的不同而有所不同,但底层和中层特征却具有较好的通用性。迁移学习的基本思想是进行网络权重的复用,通过将一个已经成熟训练的网络的一部分进行截断和微调,达到复用成熟网络以适应新问题的目的。通常迁移学习包含三个主要步骤,第一步是截取适当网络,截取的层数根据当前任务与模型原始任务的差异而确定,二者任务越相似,则可以保留越多的网络层。第二步是在截断网络后补充若干层适应于当前任务的网络,形成整体模型。第三步是进行微调,首先冻结截取到的网络的权重,仅仅更新新加入的网络层的权重,当训练到一定程度后,解封所有权重进行模型整体微调。迁移学习的一般过程示意图展示如图2-17,图中绿色矩形所代表的网络层是得到训练的层,而橙色矩形代表的网络层是权重被冻结的层。有时我们也可以略去第二步,直接对全模型进行微调。深度学习是一门工程性很强的学科,网络的训练和调参,尤其是在大型数据集上的训练,十分考验研究人员的工程能力,因此性能
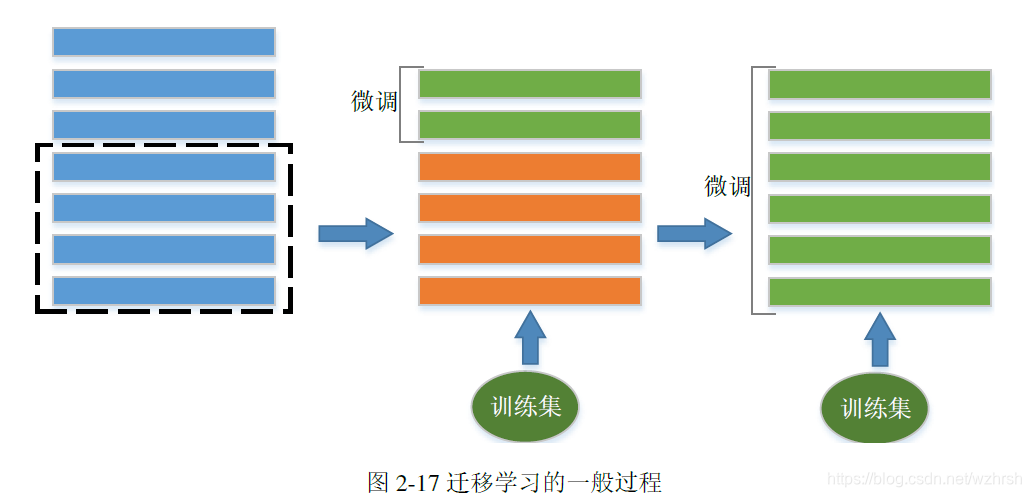
出色的模型往往是学界和工业界的宝贵资源。迁移学习的出现大大加强了对预训练权重的利用能力。
1.8 处理样本不均衡问题
样本分布不均衡问题指的是在分类等问题中,各个类别的样本数目相差较大。不均衡的训练集对模型的学习有负面影响,模型将偏向于样本数量占优的类别。在极端情况下,少数样本的类别可能会被当作数据的离群点而被忽略。处理样本不均衡的主要手段包括对多数样本进行欠采样,对少数样本进行重采样,配置类别权重,或生成少数样本等多种手段。


















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









