




数据形式如下

需要得到如下结果:
例如:hello这个单词在a.txt中出现4次,b.txt中出现4次,c.txt中出现三次
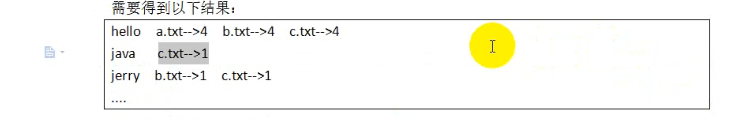
即统计出每一个单词在每一篇文档中出现的次数。
思路:maptask在运行前就已经被分配好要处理哪一个分片,要处理的哪一个切片就包含在map(key,value,context)的context中,所以只需要改写响应的context方法就行。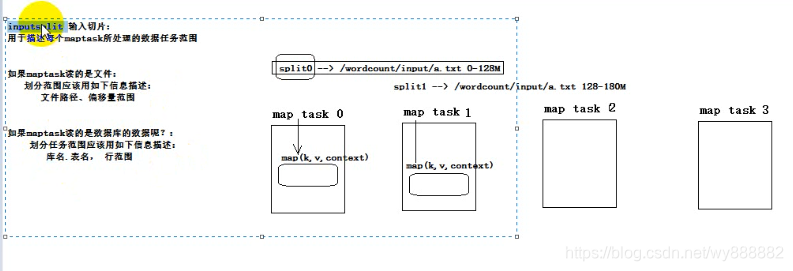
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
public class IndexStepOne {
public static class IndexStepOneMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
// 产生 <hello-文件名,1>
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 从输入切片信息中获取当前正在处理的一行数据所属的文件
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String fileName = inputSplit.getPath().getName();
String[] words = value.toString().split(" ");
for (String w : words) {
// 将"单词-文件名"作为key,1作为value,输出
context.write(new Text(w + "-" + fileName), new IntWritable(1));
}
}
}
public static class IndexStepOneReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
经过以上mapreduce处理得到一个中间文件,文件结果如下:

我们还需对中间结果进行下一步处理;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import cn.edu360.mr.flow.FlowBean;
import cn.edu360.mr.flow.ProvincePartitioner;
public class IndexStepTwo {
public static class IndexStepTwoMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("-");
context.write(new Text(split[0]), new Text(split[1].replaceAll("\t", "-->")));
}
}
public static class IndexStepTwoReducer extends Reducer<Text, Text, Text, Text> {
// 一组数据: <hello,a.txt-->4> <hello,b.txt-->4> <hello,c.txt-->4>
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
// stringbuffer是线程安全的,stringbuilder是非线程安全的,在不涉及线程安全的场景下,stringbuilder更快
StringBuilder sb = new StringBuilder();
for (Text value : values) {
sb.append(value.toString()).append("\t");
}
context.write(key, new Text(sb.toString()));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration(); // 默认只加载core-default.xml core-site.xml
Job job = Job.getInstance(conf);
job.setJarByClass(IndexStepTwo.class);
job.setMapperClass(IndexStepTwoMapper.class);
job.setReducerClass(IndexStepTwoReducer.class);
job.setNumReduceTasks(1);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("F:\\mrdata\\index\\out1"));
FileOutputFormat.setOutputPath(job, new Path("F:\\mrdata\\index\\out2"));
job.waitForCompletion(true);
}
}


















 1831
1831

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









