




TRL+Unsloth 高效微调大模型
——基于企业知识库的低资源精准记忆训练实践
一、项目背景与目标
1.1 项目背景
在企业知识库问答场景中,传统大模型普遍存在 “知识遗忘”“回答跑偏” 等问题,而全量微调方案面临显存占用高、训练周期长、资源消耗大等痛点。为解决上述问题,本项目采用 TRL(Transformer Reinforcement Learning)框架与 Unsloth 高效微调工具深度融合的技术路线,构建低资源环境下的大模型精准记忆训练系统,实现模型对企业知识库(Dify 数据集)的快速吸收与准确应答,平衡训练效率、资源成本与业务效果。
1.2 核心目标
-
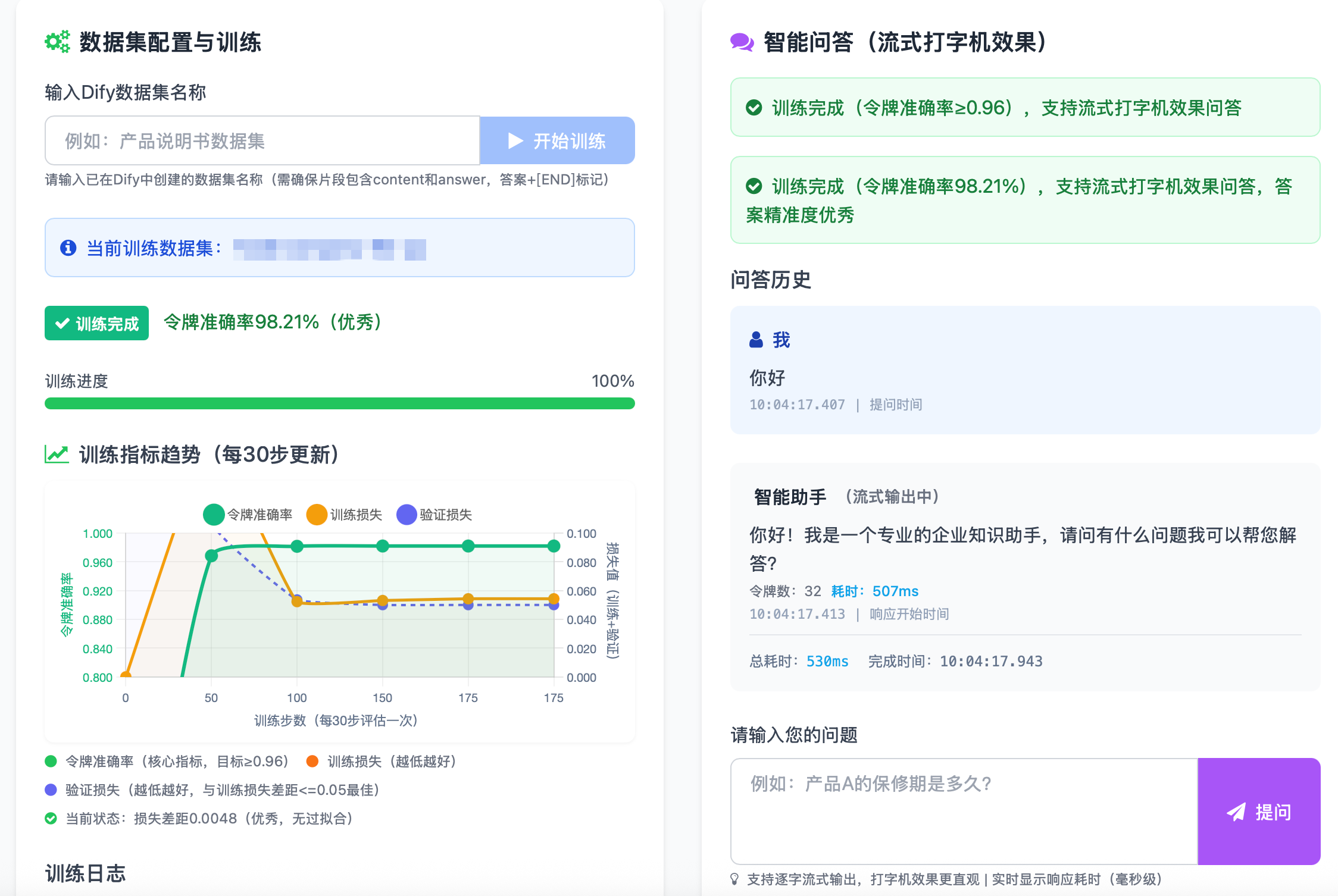
基于 Dify 数据集实现模型定向微调,确保模型精准记忆知识库关键内容,令牌准确率≥96%;
-
依托指定依赖版本(torch 2.7.1+cu128、trl 0.23.0 等)优化训练流程,在单卡环境下完成高效训练,控制显存峰值占用≤8GB;
-
构建训练过程可视化监控与 WebSocket 流式问答交互系统,支持业务直接落地;
-
保障系统在指定依赖环境下的稳定性与兼容性,实现训练过程可复现、可扩展;
-
优化模型存储与加载策略,平衡部署灵活性与推理效率。
二、技术选型与架构设计
2.1 核心技术栈(严格遵循指定依赖版本)
| 技术类别 | 选型方案 | 版本号(指定) | 选型依据 |
|---|---|---|---|
| 深度学习框架 | PyTorch | 2.7.1+cu128 | 支持 CUDA 12.8 硬件加速,优化张量计算与内存管理,适配低资源训练场景 |
| 微调框架 | TRL | 0.23.0 | 提供 SFTTrainer 核心组件,支持监督微调与评估一体化,兼容高版本 transformers |
| 高效微调工具 | Unsloth | 2025.11.3 | 优化 Transformer 层并行计算,训练速度提升 5 倍以上,强化 4bit/8bit 量化稳定性 |
| 模型仓库 | Unsloth Zoo | 2025.11.4 | 配套 Qwen3-4B 等模型权重与配置,与 Unsloth 2025 版本深度兼容,简化模型加载流程 |
| 低资源训练 | LoRA(PEFT) | 0.15.2 | 实现参数高效微调,仅训练低秩矩阵参数,降低显存占用与计算成本 |
| 数据处理 | Hugging Face Datasets | 兼容 transformers 4.57.1 | 支持批量数据处理、格式转换与内存优化,适配知识库数据特性 |
| 模型工具链 | Transformers | 4.57.1 | 提供 Tokenizer、模型生成、流式交互等核心功能,优化长文本处理逻辑 |
| 评估工具 | Evaluate | 0.4.6 | 稳定支持令牌级准确率计算,兼容 PyTorch 2.7 + 张量操作,量化模型记忆效果 |
| 部署框架 | FastAPI + Uvicorn | 兼容指定依赖 | 轻量高效,支持 WebSocket 实时交互,适配高并发问答场景 |
| 其他依赖 | requests、numpy、python-multipart 等 | 兼容指定版本 | 支撑数据获取、格式转换、接口交互等全流程功能 |
2.2 系统架构图
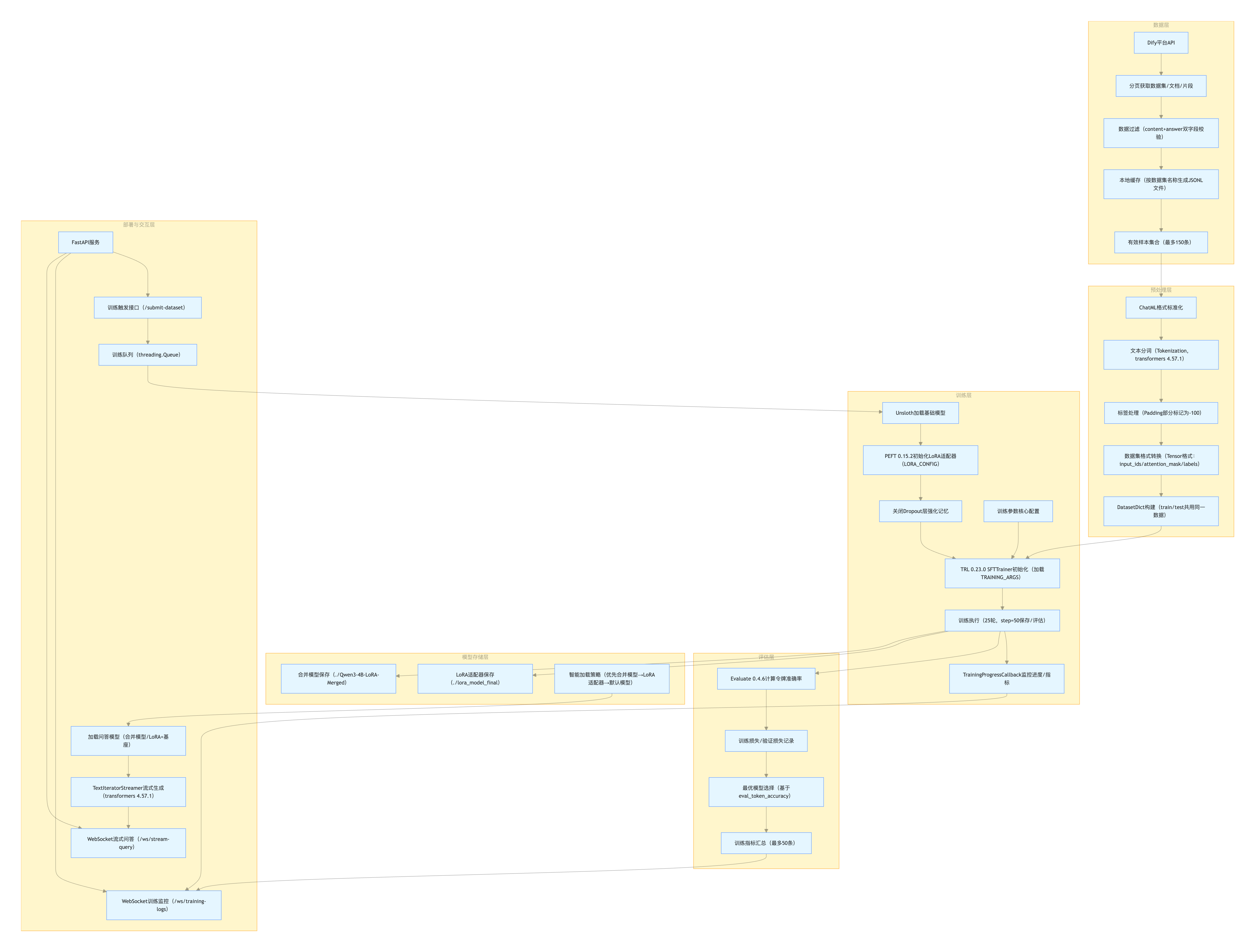
2.3 架构说明
-
层级化设计:采用 “数据层→预处理层→训练层→评估层→模型存储层→部署与交互层” 的六层级架构,流程清晰、职责明确,确保全链路可追溯;
-
依赖深度融合:各层级均基于指定依赖版本设计(如 Unsloth 2025.11.3 模型加载、torch 2.7.1+cu128 训练加速),充分发挥版本特性优势;
-
低资源适配:训练层通过 4bit 量化、LoRA 低秩适配、梯度检查点等技术,实现单卡 16GB 显存高效训练;
-
交互友好性:部署层整合 FastAPI 与 WebSocket,支持训练实时监控与流式问答,降低业务落地门槛。
三、核心技术实现(基于指定依赖版本)
3.1 依赖环境配置
3.1.1 依赖安装命令
\# 安装CUDA 12.8版本PyTorch(指定版本)
pip3 install to 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











