




部署方式:docker
部署命令:
sudo docker run -it --rm \
--name vllm \
--gpus all \
-p 8000:8000 \
-v ./local_qwen_model:/root/.cache/huggingface/hub \
vllm/vllm-openai:latest \
--model cpatonn/Qwen3-30B-A3B-Instruct-2507-AWQ-4bit \
--quantization compressed-tensors \ # 改为模型默认的量化方式
--port 8000 \
--host 0.0.0.0
测试方式:
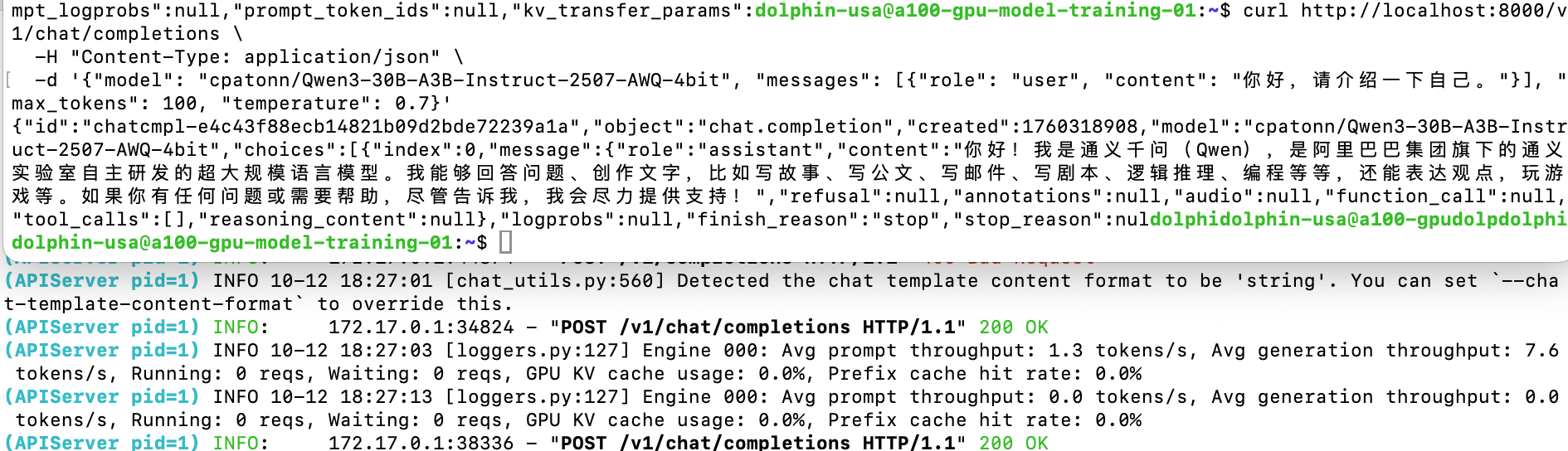
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model": "cpatonn/Qwen3-30B-A3B-Instruct-2507-AWQ-4bit", "messages": [{"role": "user", "content": "你好,请介绍一下自己。"}], "max_tokens": 100, "temperature": 0.7}'
测试结果:7.6 tokens/s,是否有点失望?还没有M2 Max快(50+ tokens/s)。
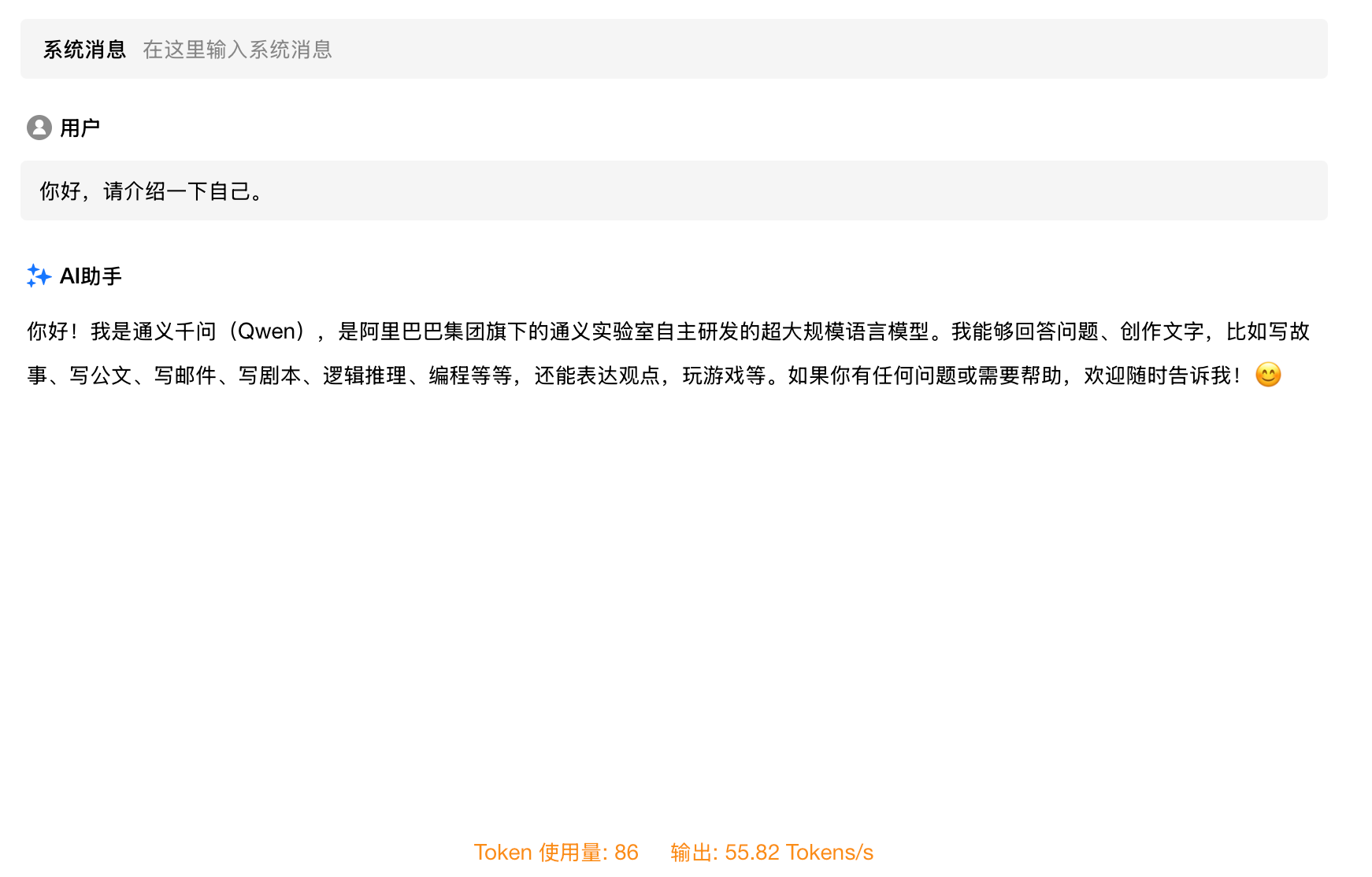
M2 Max上运行的结果:
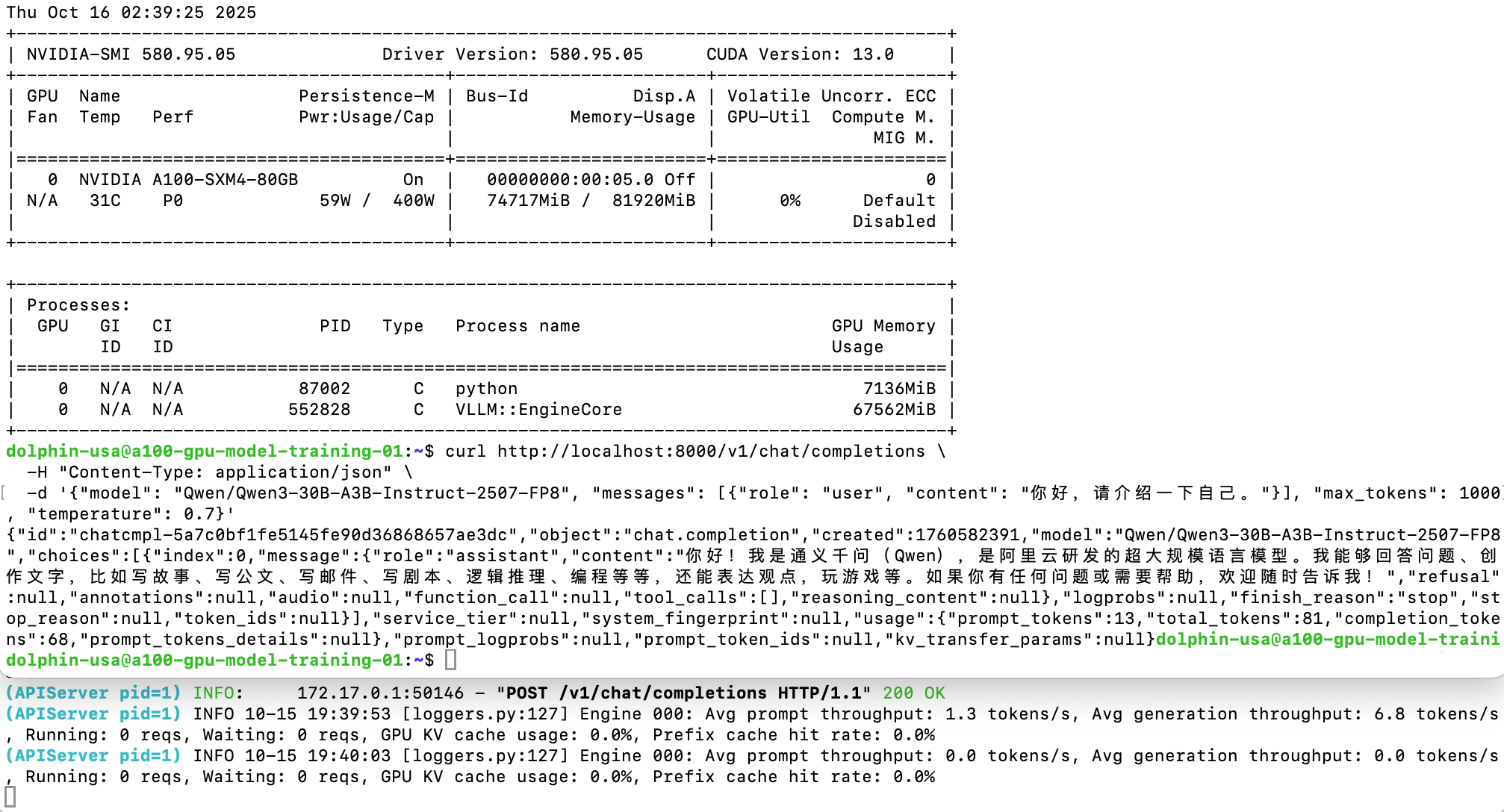
运行量化FP8也只有6.8 tokens/s,怀疑A100 不支持量化FP8。




















 3192
3192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











