




大数相乘
大数相乘要比大数相加难实现一点,关键是模拟乘法
实现一个哈希表(采用链式冲突)
这个题目一般就是vector加list的结构实现,一般不需要手写复杂的Hash函数
2.问我MVC模式你是怎么理解的
M:model,V:view, C:控制器
3.tomcat和spring你是如何理解并区分的
4.http header中keepalive字段的了解
当一个客户端向服务器发送http请求时,两者之间会建立一个tcp连接,然后服务器发回响应信息同时关闭连接。如果请求的的页面中含有别的资源连接,比如图片、flsah等,就会再次创建连接。KeepAlive的作用就是在第一次创建连接时,服务器会把这个tcp连接保持一段时间(服务器端会有一个keepaliveTime的最大时间,超过时间就断开连接)。这样就不会频繁的去建立tcp连接,同一次请求中的信息传递都可以使用同一个tcp连接。
5.代码题
判断是否是回文链表
快慢指针,反转后一半链表
打印出根节点到叶子节点的最长路径。
介绍一下网络的七层协议,TCP/UDP,IP分别在七层协议的哪一层
TCP/UDP 在传输层, IP在网络层
TCP如何实现可靠连接
1. 序列号,ACK信号:发送方按照顺序给要发送的数据包的每个字节都标上编号。接收方接收到发送方的数据包之后,回传一个ACK信号,标识下一个需求的数据包初始字节编号。
2. 超时重发:在等待接收方回传的ACK信号超时后,发送方重发数据包。一旦开始重传,下一次等待的时间间隔指数增长,重发一定次数后还是收不到ACK信号,将强制终止连接。
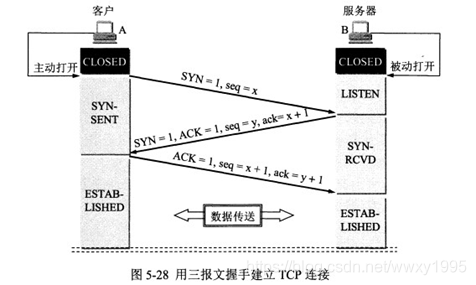
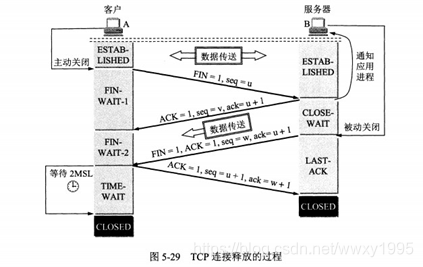
3. TCP的连接管理:建立连接的三次握手和断开连接的四次挥手。
4. 以段为单位发送数据包:在建立TCP连接的同时,两端协商发送数据包的单位,称为“最大消息长度”:MSS。 【TCP数据(MSS字节)】【TCP首部(20字节)】【IP首部(20字节)】
5. 滑动窗口:以段为单位发送数据包,每发送一个数据包需要等待一个ACK信号,当数据包往返时间越长效率越低。滑动窗口中窗口前端为已发送但为收到ACK的数据,后端为待发送数据。发送端一次发送多个数据,接收端回传收到的连续数据的ACK信号,缓存缺失数据之后的数据包(保持顺序)。发送端当收到ACK信号时,窗口向前依次移动,直到遇到有数据未确认时停止。一段时间后启动超时重传,接收端若收到缺失数据,则和缓存数据一起发送ACK信号,否则,抛弃缓存数据。
6. 流量控制:TCP首部有一个字段来通知窗口的大小,接收端通过设置来主动控制传输流量。
7. 拥塞控制:发送端通过拥塞窗口主动控制传输流量。慢启动:防止双方通信刚开始就传送大量数据包,发送端拥塞窗口初始设置为1MSS,每接受一个ACK信号,窗口扩大为两倍。发送数据时,取拥塞窗口和滑动窗口的较小值。同时设定一个慢启动阈值,当拥塞窗口大小超过阈值时,改为线性增长,直到网络拥塞。拥塞时将慢启动阈值设置为当前窗口的的一半,并将拥塞窗口的值设置为1,然后再次重复操作。
超时重传的机制是什么,怎样实现的;
在等待接收方回传的ACK信号超时后,发送方重发数据包。一旦开始重传,下一次等待的时间间隔指数增长,重发一定次数后还是收不到ACK信号,将强制终止连接。
对于数据存储时的大小端,面试官给一个16进制数,请我从高地址到低地址给出小端表示;
int、float、bool如何与0进行比较,写出比较方式;
这个题目比较基础
宏定义返回两个参数最大值
#define MAX(A,B) ( (A) > (B) ? (A) : (B) )
算法题:链表反转,分别用遍历与递归实现。
1.键值对这种数据结构的实现方式
HashMap, pair
2.多线程安全的键值对数据结构实现方式
加锁
3.归并排序
4.说说数据存储和处理的历史演变
5.hadoop实现数据冗余备份的难点
6.hive了解不
7.说说大数据的理解
8.TCP连接三次握手、四次挥手
9.两个都含有50亿url文件2G内存求交集(不用Bloom Filter)。
MapReduce
说一下多线程,Java是怎么做到线程安全的
线程和进程有什么区别
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
在开销方面:每个进程都有独立的代码和数据空间(程序上下文),程序之间的切换会有较大的开销;线程可以看做轻量级的进程,同一类线程共享代码和数据空间,每个线程都有自己独立的运行栈和程序计数器(PC),线程之间切换的开销小。
所处环境:在操作系统中能同时运行多个进程(程序);而在同一个进程(程序)中有多个线程同时执行(通过CPU调度,在每个时间片中只有一个线程执行)
内存分配方面:系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了CPU外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源。
包含关系:没有线程的进程可以看做是单线程的,如果一个进程内有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的;线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程
进程之间通信的方式
1.管道:速度慢,容量有限,只有父子进程能通讯
2.FIFO:任何进程间都能通讯,但速度慢
3.消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题
4.信号量:不能传递复杂消息,只能用来同步
5.共享内存区:能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了同一进程内的一块内存
输入一个url之后都发生了什么事
DNS,TCP,HTTP请求,HTTP响应
为什么要四次挥手
TCP全双工通信
介绍一下乐观锁和悲观锁
悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
乐观锁
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁适用于多读的应用类型,这样可以提高吞吐量,像数据库提供的类似于write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的。
数据库中有哪些隔离级别
索引是用什么实现的
B+树
RR解决了什么问题,还有什么问题是没有解决的
怎么解决幻读
1、自我介绍
2、项目及具体的实现细节
3、指针和引用的区别(猿辅导特别喜欢问这个,面猿辅导一定要准备一下这个)
指针可以修改,引用不能修改
4、TCP如何保证可靠性
5、在TCP连接中,如果突然有多个连接,服务端会发生什么(我说的SYN Flood,应该会缓冲池慢了而暂时阻塞,但是面试官否认了,我当时有点懵)
6、应用层对应的协议
HTTP,HTTPS
7、C++虚函数
8、手撕了两道代码,都很常规
第一题是BST找第K大值,第二题是行和列都是有序的二维矩阵找一个target值
1.list和set的区别
2.list的底层实现
set和list都是集合接口
简要说明
set --其中的值不允许重复,无序的数据结构
list --其中的值允许重复,因为其为有序的数据结构
List的功能方法
实际上有两种List: 一种是基本的ArrayList,其优点在于随机访问元素,另一种是更强大的LinkedList,它并不是为快速随机访问设计的,而是具有一套更通用的方法。
List : 次序是List最重要的特点:它保证维护元素特定的顺序。List为Collection添加了许多方法,使得能够向List中间插入与移除元素(这只推荐LinkedList使用。)一个List可以生成ListIterator,使用它可以从两个方向遍历List,也可以从List中间插入和移除元素。
ArrayList : 由数组实现的List。允许对元素进行快速随机访问,但是向List中间插入与移除元素的速度很慢。ListIterator只应该用来由后向前遍历ArrayList,而不是用来插入和移除元素。因为那比LinkedList开销要大很多。
LinkedList : 对顺序访问进行了优化,向List中间插入与删除的开销并不大。随机访问则相对较慢。(使用ArrayList代替。)还具有下列方法:addFirst(), addLast(), getFirst(), getLast(), removeFirst() 和removeLast(), 这些方法 (没有在任何接口或基类中定义过)使得LinkedList可以当作堆栈、队列和双向队列使用。
3. hashmap的底层数据结构,什么时候链表转为红黑树
1、 HashMap的原理,内部数据结构?
底层使用哈希表(数组+链表) , 当链表过长时会将链表转成红黑树以实现O(logn)时间复杂度内查询
2、 讲一下HashMap中put方法过程?
①.对Key求hash值,然后计算其存储在数组的下标值
②,如果没有碰撞,直接放入数组中,如果碰撞了,以链表方式链接到后面
③.如果链表长度超过阈值(TREEIFY_THRESHOLD== 8), 就把链表转成红黑树
④.如果节点已经存在则替换旧值(key重复时覆盖旧值)
⑤,如果数组满了(容器 * 加载因子),即达到扩容条件,就需要执行resize()方法对数组扩容
stringbuild和stringbuffer的区别,线程安全的实现方法,lock的实现方法,sleep.wait的区别
String 字符串常量
StringBuffer 字符串变量(线程安全)
StringBuilder 字符串变量(非线程安全)
简要的说, String 类型和 StringBuffer 类型的主要性能区别其实在于 String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象
区别
1、StringBuffer 与 StringBuilder 中的方法和功能完全是等价的,
2、只是StringBuffer 中的方法大都采用了 synchronized 关键字进行修饰,因此是线程安全的,
而 StringBuilder 没有这个修饰,可以被认为是线程不安全的。
3、在单线程程序下,StringBuilder效率更快,因为它不需要加锁,不具备多线程安全
而StringBuffer则每次都需要判断锁,效率相对更低


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









