




 文章探讨了在PyTorch中,特别是在小批量训练时,梯度累积对模型权重更新的影响。它指出,对于简单的模型如ExampleLinear,梯度累积可能得到理想结果,但在复杂模型如BERT中,累积策略可能导致BatchNormalization失效,推荐使用GroupNormalization。
文章探讨了在PyTorch中,特别是在小批量训练时,梯度累积对模型权重更新的影响。它指出,对于简单的模型如ExampleLinear,梯度累积可能得到理想结果,但在复杂模型如BERT中,累积策略可能导致BatchNormalization失效,推荐使用GroupNormalization。
https://stackoverflow.com/questions/62067400/understanding-accumulated-gradients-in-pytorch
有一个小的计算图,两次前向梯度累积的结果,可以看到梯度是严格相等的。
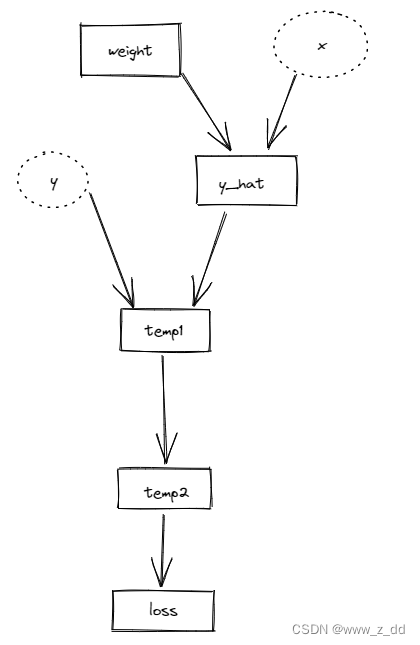

代码:
import numpy as np
import torch
class ExampleLinear(torch.nn.Module):
def __init__(self):
super().__init__()
# Initialize the weight at 1
self.weight = torch.nn.Parameter(torch.Tensor([1]).float(),
requires_grad=True)
def forward(self, x):
return self.weight * x
model = ExampleLinear()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
def calculate_loss(x: torch.Tensor) -> torch.Tensor:
y = 2 * x
y_hat = model(x)
temp1 = (y - y_hat)
temp2 = temp1**2
return temp2
# With mulitple batches of 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4644
4644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









