




% OFDM 数字基带系统
clc; clear; close all;
%% 参数设置
M = 16; % 16-QAM
N = 64; % IFFT 点数
CP = 16; % 循环前缀长度(25%)
num_frames = 100; % 帧数
bits_per_frame = 96; % 每帧原始比特数
total_bits = bits_per_frame * num_frames;
%% 1. 随机数据 + 卷积编码
data = randi([0 1], total_bits, 1); % 9600 比特
trellis = poly2trellis(7, [171 133]);
coded = convenc(data, trellis); % 编码后变长
%% 2. 交织
% 交织行列尺寸:25x24,可扩展为更大尺寸提高抗突发干扰能力
reshaped=reshape(coded, [], 600);
reshaped=reshaped';
interleaved = matintrlv(reshaped, 25, 24);
interleaved = interleaved';
interleaved = interleaved(:);
%% 3. 16-QAM 调制
symbols = qammod(bi2de(reshape(interleaved, 4, [])', 'left-msb'), M);
%% 4. 分帧插入导频(每帧48个数据子载波 + 4个导频 → 64点)
num_symbols = length(symbols);
symbols_per_frame = 48;
num_ofdm_frames = num_symbols / symbols_per_frame;
pilot = 3 + 3j;
ofdm_symbols = zeros(N, num_ofdm_frames); % 64行,100列(每帧)
k = 1;
for i = 1:num_ofdm_frames
temp = zeros(1, 64);
% 插入导频(固定位置)
temp([8, 22, 44, 58]) = pilot;
% 插入数据
data_idx = setdiff(1:64, [8, 22, 44, 58]);
temp(data_idx(1:48)) = symbols(k:k+47);
k = k + 48;
ofdm_symbols(:, i) = temp.'; % 存储成列向量(方便后面 IFFT)
end
%% 5. IFFT + 加循环前缀
ifft_out = ifft(ofdm_symbols, N, 1);
ifft_cp = [ifft_out(end-CP+1:end, :); ifft_out]; % 80×100
%% 6. 加 AWGN + 接收处理
snr_range = 0:2:64;
MaxIter = 100 ; %设置迭代次数,如果运行时间过长,可以减少数值
total_bit_errors_zf=0;
total_bit_errors_mmse=0;
total_bits_all = length(data) * MaxIter; % 每次发送相同 data,迭代 MaxIter 次
BER_zf = zeros(1, length(snr_range));
BER_mmse = zeros(1, length(snr_range));
for snr_idx = 1:length(snr_range)
snr = snr_range(snr_idx);
% 初始化每个SNR下的误码计数
bit_errors=0;
bit_errors_zf = 0;
bit_errors_mmse = 0;
for iter = 1:MaxIter
%% 发射端
tx_signal = ifft_cp(:); % 原始OFDM时域信号
rx = awgn(tx_signal, snr, 'measured'); % 加AWGN
%% 接收端:处理为帧结构
rx = reshape(rx, N + CP, []); % 每帧80点
rx_no_cp = rx(CP+1:end, :); % 去循环前缀
fft_out = fft(rx_no_cp, N, 1); % FFT 变换
% 初始化当前帧的解调数据
rx_data = [];
rx_data_zf = [];
rx_data_mmse = [];
for i = 1:num_ofdm_frames
frame = fft_out(:, i);
pilot_idx = [8, 22, 44, 58];
data_idx = setdiff(1:64, pilot_idx);
%不做估计和均衡
rx_data = [rx_data; frame(data_idx(1:48))];
% LS 信道估计
received_pilots = frame(pilot_idx);
h_est_pilot = received_pilots ./ pilot;
h_est_full = interp1(pilot_idx, h_est_pilot, 1:64, 'linear', 'extrap')';
% ZF均衡
equalized_frame_zf = frame ./ h_est_full;
rx_data_zf = [rx_data_zf; equalized_frame_zf(data_idx(1:48))];
% MMSE均衡
snr_linear = 10^(snr / 10);
mmse_weights = conj(h_est_full) ./ (abs(h_est_full).^2 + 1/snr_linear);
equalized_frame_mmse = frame .* mmse_weights;
rx_data_mmse = [rx_data_mmse; equalized_frame_mmse(data_idx(1:48))];
end
%% 未做估计和均衡
demod = qamdemod(rx_data, M);
bin = de2bi(demod, 4, 'left-msb')';
bin = bin(:);
deintlvd = matdeintrlv(reshape(bin, [], 600)', 25, 24)';
deintlvd = deintlvd(:);
decoded = vitdec(deintlvd, trellis, 35, 'trunc', 'hard');
[num_err, ~] = biterr(data, decoded);
bit_errors = bit_errors + num_err;
%% ZF 解调链路
demod_zf = qamdemod(rx_data_zf, M);
bin_zf = de2bi(demod_zf, 4, 'left-msb')';
bin_zf = bin_zf(:);
deintlvd_zf = matdeintrlv(reshape(bin_zf, [], 600)', 25, 24)';
deintlvd_zf = deintlvd_zf(:);
decoded_zf = vitdec(deintlvd_zf, trellis, 35, 'trunc', 'hard');
[num_err_zf, ~] = biterr(data, decoded_zf);
bit_errors_zf = bit_errors_zf + num_err_zf;
%% MMSE 解调链路
demod_mmse = qamdemod(rx_data_mmse, M);
bin_mmse = de2bi(demod_mmse, 4, 'left-msb')';
bin_mmse = bin_mmse(:);
deintlvd_mmse = matdeintrlv(reshape(bin_mmse, [], 600)', 25, 24)';
deintlvd_mmse = deintlvd_mmse(:);
decoded_mmse = vitdec(deintlvd_mmse, trellis, 35, 'trunc', 'hard');
[num_err_mmse, ~] = biterr(data, decoded_mmse);
bit_errors_mmse = bit_errors_mmse + num_err_mmse;
end
% BER 计算(每个 SNR 单独计数)
BER(snr_idx) = bit_errors / (length(data) * MaxIter);
BER_zf(snr_idx) = bit_errors_zf / (length(data) * MaxIter);
BER_mmse(snr_idx) = bit_errors_mmse / (length(data) * MaxIter);
end
%% 绘图(同时显示 ZF 和 MMSE)
figure;
semilogy(snr_range, BER, 'b-o', 'LineWidth', 1.5); hold on;
semilogy(snr_range, BER_zf, 'g-o', 'LineWidth', 1.5); hold on;
semilogy(snr_range, BER_mmse, 'r-s', 'LineWidth', 1.5);
xlabel('SNR (dB)');
ylabel('BER');
title('性能对比');
legend('不做估计均衡','ZF', 'MMSE', 'Location', 'best');
grid on;
hold off;
发送端处理流程:
随机比特生成:生成原始二进制数据;
卷积编码:采用约束长度为7的卷积编码提高可靠性;
交织:防止突发错误影响译码性能;
16-QAM 调制:将编码后的比特映射为复数符号;
导频插入 + OFDM帧结构构建:每帧包含48个数据子载波 + 4个导频子载波;
IFFT + 加循环前缀:实现OFDM调制的核心过程;
串化发送。
信道建模:
使用 awgn模拟加性高斯白噪声信道。
接收端处理:
去除循环前缀并进行FFT;
提取导频并基于 LS(最小二乘)方法进行信道估计;
分别使用 ZF 与 MMSE 均衡器进行等化;
QAM 解调、反交织、Viterbi 解码,恢复原始数据;
统计各均衡方式下的误码率(BER)。
性能评估与绘图:
对比不同 SNR 下“无均衡”、“ZF均衡”、“MMSE均衡”的误码率;
仿真结果:
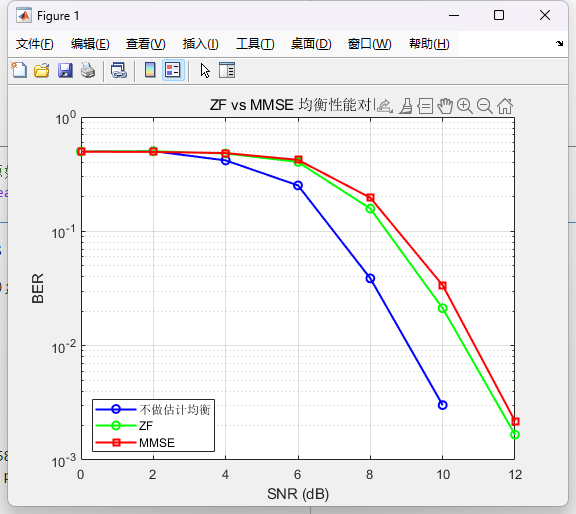
可以看到仿真结果是脱离预计的,理论上的结果应该是MMSE >ZF>不做均衡,是结果正好相反,以下是本人的一些猜想:
1.因为本次仿真仅仅用到AWGN信道进行模拟,在信道过于简单的情况下进行估计和插值反而得到了反效果,从而导致进行估计和均衡后的效果不如不做估计和均衡
2.理论上MMSE均衡在低信噪比的情况下效果不如ZF均衡,可能情况是MMSE公式中1/SNR 项在低信噪比情况下变大,导致 MMSE 把权重压得太小,为抑噪削弱了信号,ZF 反而保留信号更多。但是上面也提到信道太过于简单,信噪比加到12以后,误码率为0,体现不出MMSE的优势
3.如果加入时变瑞利信道或真实水声信道,可能会看到更明显的性能反转
该代码仿真为本人一次小小的尝试,若有不足欢迎指出

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









