




1、核心概念
a、数据库分类: 关系型数据库(RDBMS)、非关系型数据库(NoSQL);
b、数据的分类:
1、结构化:数据结构字段含义确定,清晰,典型的如数据库中的表结构;
2、非结构化:杂乱无章的数据,很难按照一个概念去进行抽取的,无规律性。
3、半结构化:具有一定结构,但语义不确定,典型的如HTML网页,有些字段是确定的(title),
有些不确定(table);
c、HBase是一个分布式,用来存储半结果和结构化的松散数据的NoSQL的数据库;
优点:可扩展,分布式,高吞吐,多版本....
d、HBase的以来组建:
1、HDFS用来做底层数据文件的存储支撑;
2、MapReduce用来做HBase表中的统计分析需求的查询支撑;
3、HBase本身架构上的单点故障问题的解决方案支撑:Zookeeper;
e、HBase正常使用启动顺序:
1、启动zk
2、启动Hadoop (如果需要做统计分析的需求查询,那么必须要启动YARN,编写MR程序去计算)
3、启动hbase
f、Hbase的数据库的特点:
1、它介于Nosql和RDBMS之间,仅能通过主键(rowkey)和主键range来检索数据
2、HBase查询数据功能很简单,不支持json等复杂操作
3、不支持复杂的事务,只支持行级事务(可通过hive支持来实现多表join等复杂操作)
4、HBase中支持的数据类型:byte[] (底层所有数据的存储都是字节数组)
5、主要用来存储结构化和半结构化的松散数据
与Hadoop一样,HBase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
e、表的特点:
1、大:一个表可以有上十亿行,上百万列;
2、面向列:面向列(簇)的存储和权限控制,列(簇)独立检索;
3、稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏;
4、无模式:每行都有一个可排序的主键和任意多的列,列可以根据需求动态的增加,同一张表中不同的行可以有截然不同的列
h、数据存储系统的模式问题:
1、读模式,hive,在读取数据的时候才会做模式校验。
2、写模式,mysql,在写入数据的时候,做模式校验。
HBase无严格模式:
1、无模式:插入的key-value可以放置在任何的列簇当中;
2、有模式:插入的key-value必须在创建表的时候指定的列簇当中;
g、HBase表的结构:
1、表: 和普通的mysql中的表的概念是一样的。
2、rowkey: 所有的数据,在进行查询的时候,一般来说都是根据rowkey,但是也可以使用过滤器,去扫描整张表的数据。
查询方式:直接根据rowkey;根据rowkey的范围range;全表扫描;
rowk的长度限制:不能超过64kb,最好在10-100byte之间,最好16,最好是8的倍数。
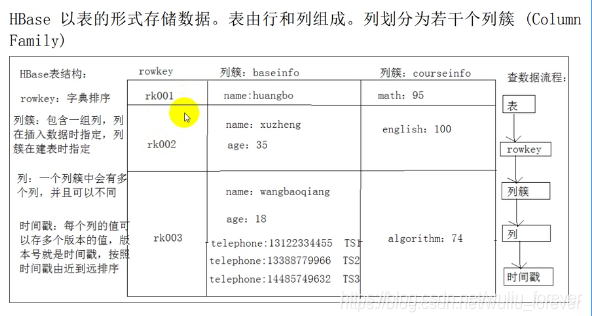
3、列簇
一组key组成一个列簇:具有相同io特性。
查询其中一个key1的时候一般来说,都会查询另外一个key2,所有说key1和key2具有相同的io特性。
经验推荐:虽然说在部分场景中,有可能存储的数据,有具有多个不同的io特性,应该要存储成为多个不同的列簇,
但是根据经验来判断,最好使用一个列簇。
6个圆圈中的一个圆圈: store。
4、列
真正的key-value中的key就是列,插入的key-value到底应该存储在哪个列簇中,是在插入的时候,一定要指定的。
5、时间戳
作用: 就相当于一个key-value中 的value的多个版本号
两种管理方式:1、保存最近的最新的N个版本;2、保存一定时间范围内的所有数据,如果某个版本数据超过时限要求,那么会被HBase的服务器自动。
h、HBase的架构
集群有三种角色:
1、client
2、server主从架构: HMaster(主键点)、HRegionServer(从节点)
HBase依赖于:
1、hdfs做数据存储
2、zookeeper做协调(解决SPOF,存储寻址入口)
hmaster没有参与真正数据的查询和插入的处理(主要用来管理hregionserver的状态,和所有的region的负载均衡)。
HBase的主从架构就决定。HBase还是有单点故障的问题,但是不迫切
表示:HBase的主节点,可以在宕机的了以后,整个HBase集群依然可以对外提供服务。
当前HBase中的每个region都会增长。增长到10G大小的时候就进行分裂。
分裂的标准: 在HBase1.x以前,是256M
在HBase1.2以后,是10G
分裂出来的两个region一般来说,hregionserver会回报给hmaster,hmaster一般来说,都会寻找一个新的
hregionserver来进行存储分裂出来的两个region当中的一个。
原始数据表raw:所有HBase表都会有多个region.
.meta. 所有的这些region的映射信息都存储在第二级表中,如果这些映射信息过多,都会造成第二级表也会进行分裂,形成多个region。
-root-:第二级多个表的region也被映射起来,存储在第一级表-root-中。
最终的核心要点:-root-这个表中的数据量不管多大,都不会进行分裂。
其实根据跳表这种数据结构的特点,如果能寻找到-root-这个表的那个唯一region在哪里,就能得到用户要寻找的数据是哪里region。
-root-这张表的所有数据就是一个region,这个region也是存储在hregionserver中,但是会经常有迁移操作
zookeeper给HBase存储寻找入口:
其实就是存储 -root-表的唯一region在哪个hregionserver中。
hbas寻址机制:
region就是一张HBase表的逻辑抽象单位,一个region并不是一个单独的文件,在hdfs上的目录树种体现为一个文件夹。
regiserver:
1、一个regionserver中的所有region都是来自于一个表么?不是
2、一个regionserver中的....
所有表的所有region是进行负载均衡的处理之后存储在整个HBase集群。
region:是HBase中对表进行切割的单元,由regionserver负责管理。
Hmaster:HBase的主节点,负责整个集群的状态感知,负载分配、负责用户表的元数据管理(可以配置多个用来实现HA),hmaster负载压力相当于hdfs的namenode会小很多。
regionserver:HBase中真正负责管理region的服务器,也就是负责为客户端进行表数据读写的服务器每一台regionserver会管理很多的region,同一个regionserver上面管理的所有的region不属于同一张表。
zookeeper:整个HBase中的主从节点协调,主节点之间的选举,集群节点之间的上下线感知...都是通过zookeeper来实现的。
HDFS:用来存储HBase的系统文件或者表的region。
2、表设计
表(region(负载均衡和分布式存储的最小单元,但是不是物理存储的最小单元,物理存储的最小单元是HFile)、store(一个master + 0到多个storefile)、HFile、data、keyvalue(rowkey、cf、qualifier、value))
a、列簇设计
1、在没有特别必要的情况下,不要设置过多的列簇(具有相同IO特性的列全部放在一起成为一个列簇);
2、如果需要做全表扫描的话。那么设置过多的列簇会导致hbase的regionserver需要扫描的文件就很多;
b、rowkey设计
三个原则:
1、长度(最好16个字节不要超过100个字节)
2、散列(数据热点、数据倾斜、负载均衡);
散列:hash散列,为了让hbase集群中的所有regionserver都能均摊服务器压力
3、唯一
c、布隆过滤器bloomfilter
1、缺点:不能从布隆过滤器中删除元素;
3、协处理器
a、起源:最常用的关于数据库的操作都没法高效的实现:
1、权限控制,没法建立二级索引,难以执行sum、max、min、avg、count、distinct等操作,在旧版本中,统计数据表的总行数,需要使用counter方法,执行一次MapReduce job才能得到。虽然HBase在数据存储层中集成了MapReduce,能够有效用于数据表的分布式计算。然而在很多情况下,做一些简单的相加或者聚合计算的时候,如果直接将计算过程防放置在server端,能够减少通讯开销,从而获得很好的性能提升。在0.92之后引入了协处理器,实现了一些新特性:能够轻易的建立二次索引、复杂的过滤器(谓词(行为操作)下推:本来放在客户端做,结果客户端把执行这个谓词这个行为分发到最底层服务器上去做,提高效率)以及访问控制等。
2、协处理器的设计思想:减轻hbase数据库系统在做一些简单统计分析的负担;
3、举例: 微博 一张表 a用户关注了b用户 10E
电商 一张表 某用户收藏了某商品 10E
分布式Nosql: HBase 一张表 : billions row + millions column BigTable
理论上来说:分布式存储系统是没有存储上限的
Hbase:user_goods
user1:a1、b2、c3....
user2:b2、c3,d4....
user3:f5
等同于在Hbase中安装rowkey去查value。
如果需要根据商品来查询到底被那些用户收藏了?
建立二级索引。
goods_user
a1:user1
b2:user1、user2
c3:user1、user2
d4:user2
f5:user3
往上面的表中插入一条数据记录也要往下面的表中插入一条记录,RDBMS中的触发器(触发器的概念:如果你做一个操作,那么会触发另外一个操作的执行。)
Mysql:
user:存储的就是weibo这个产品的所有使用户信息。
如果需要统计user表中到底有多少条记录?
提供一张新表:就是用来存储user表的总记录数counter
1、当往user表中插入一条记。counter表中,就会统计出user个数变成1
2、如果往user表中再次插入一条记录,再次出发counter表中进行user的值+1..
3、需要查询user表中的总用户数。直接查询counter表中,字段为user的value值即可。
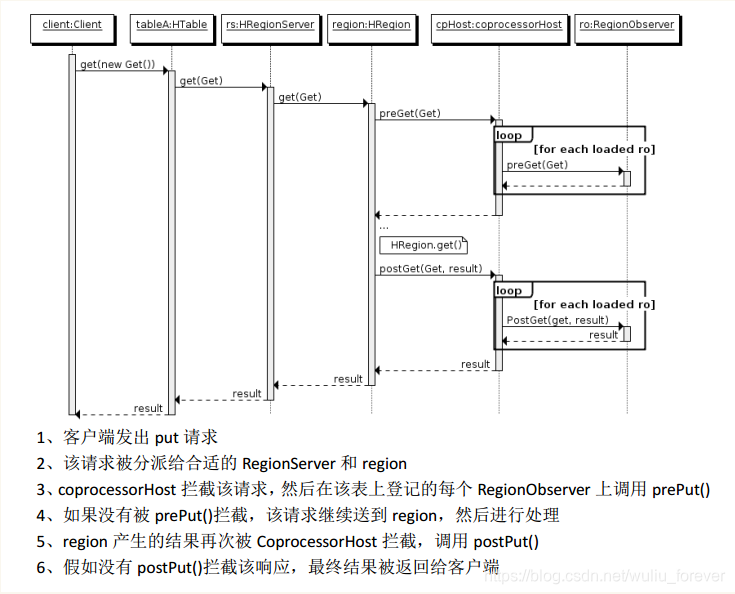
b、协处理器(coprocessor)分为两类:observer和endpoint --拦截器
1、observer:相当于mysql中的触发器主要在服务端工作。允许集群在正常的客户端操作过程中可以有不同的行为表现。可以实现权限管理、优先级设置、监控、ddl控制、二级索引等功能。
2、endpoint终端:相当于mysql中的存储过程主要在服务端工作。允许扩展集群的能力,对客户端应用开放新的运算命令。可以实现min、max、avg、sum、distinct、group by等功能。
举例:linux中一个hadoop集群的安装,可以编写一个脚本,把之前安装hadoop集群的各种命令组合到一起,最终直接调用这个脚本运行,自动按照代码的编写顺序。
f、协处理器的加载方式有两种
1、静态加载(全局加载): 在配置文件(hbase-site.xml)中进行配置,对整个hbase的所有表生效。
<!-- 启动全局aggregation,能过操纵所有的表上的数据-->
<property>
<key>hbase.coprocessor.user.region.classes</key>
<value>
org.apache.hadoop.hbase.coprocessor.AggregateImplementation</value>
</property>
为所有表,加载一个cp class,可以用","分割加载多个class
2、动态加载(局部加载/表协处理器),仅仅只是对某个表进行协处理器的加载,只对添加的表有效。 启用表aggregation,只对特定的表生效。通过hbase shell来实现。
a、disable 'table_name'
b、alter 'table_name',METHOD => 'table_att','coprocessor' => '|org.apache.hadoop.hbase.coprocessor.AggregateImplementation||' ; 修改某个表,添加一个属性->协处理器,协处理器的值分为四段,四段以"|"分割开,四个属性(第一个参数:协处理器放在hdfs上的路径(通常会把协处理打成jar包,把jar放在hdfs的某个目录);第二个参数:当前这个目录要用哪个处理器;第三个参数:加载优先级;第四个参数:当前协处理器是否接收一些参数,可以在这个域里面添加一些参数(key-value形式);)
c、enable 'table_name'
3、卸载协处理器(三步操作即可)
disable 'table_name'
alter 'table_name',METHOD=>'table_att_unset',NAME=>'coprocessor$1'
enable 'table_name'
c、二级索引
1、关注表
key value
a b
a c
a d
b d
e f
2、粉丝表
key value
b a
c a
d a
d b
f e
准备表结构和插入数据的命令:
准备: guanzhu,fensi。如果说往guanzhu表中插入一条记录,结果要自动往fensi表插入一条记录。
create 'guanzhu','cf'
create 'fensi','cf'
1、编写一个协处理器,导出jar(取名叫cp.jar)上传到hdfs的/hbasecp目录下
2、停用guanzhu(disable 'guanzhu'),添加协处理器:
alter 'guanzhu' ,METHOD=>'table_att','coprocessor'=>'hdfs://10.18.6.107:9000/hbasecp /cp.jar|com.sirius.hbase.cp.TestCoprocessor|1001|'
put 'guanzhu','user1','cf:from','a'
3、启动guanzhu(enable 'guanzhu')
put 'guanzhu','user1','cf:from','abcd'
scan 'guanzhu'
scan 'fensi'
d、三种观察者接口
以HBase0.92版本为例,0.96版本又新增了一个RegionServerObserver。
1、RegionObserver:提供客户端的数据操纵事件钩子:get、put、Delete、Scan等
2、WALObserver:提供WAL相关操作钩子
3、MasterObserver:提供DDL类型的操作钩子,如创建、删除、修改数据库表等
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









