




1、hadoop前世今生
1.1、搜索引擎:网络爬虫 + 索引服务器(生成索引+检索)
1.2、Doung Cutting 写了Lucene包(生成索引+检索)
1.3、Nutch:网络爬虫 + 索引服务器(Lucene封装)
1.3.1、分布式存储
1.3.2、分布式计算
1.4、2002年开源GFS论文,Doung Cutting写了HDFS模块
1.5、2004年谷歌开源了MapReduce论文,Doung Cutting写了MapReduce模块
1.6、Nutch0.9版本后将MapReduce模块拆分出来,形成了一个大数据处理框架Hadoop
2、Hadoop概述
2.1、Hadoop0.X 1.X(common(RPC网络通信模块)、HDFS分布式存储、MapReduce分布式计算)
Hadpoop2.X(common(网络通信RPC)、HDFS分布式文件存储、YARN任务管理和资源调度(分布式计算框架MapReduce、Hive、Storm、Spark、Flink))
2.2、四大模块
common(RPC网络通信模块,为其他Hadoop模块提供基础设施)、HDFS分布式存储(一个高可靠、高吞吐量的分布式文件系统)、MapReduce分布式计算(一个分布式离线并行计算框架)、yarn任务管理和资源调度
2.3、HDFS(Hadoop distributed file system)分布式文件系统
a、文件系统:(文件管理+Block快管理)
windows:FAT16、FAT32、NTFS; Linux: ext2/3/4、VFS
b、分布式文件系统
多个服务器存储文件
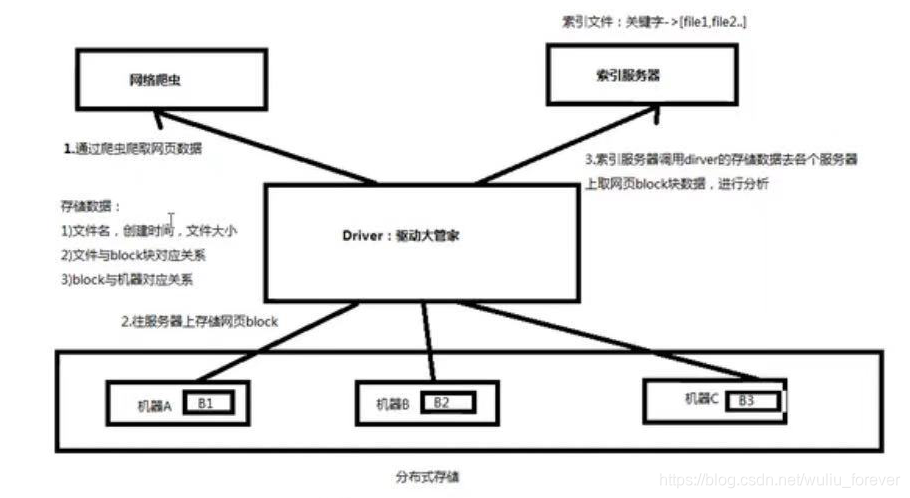
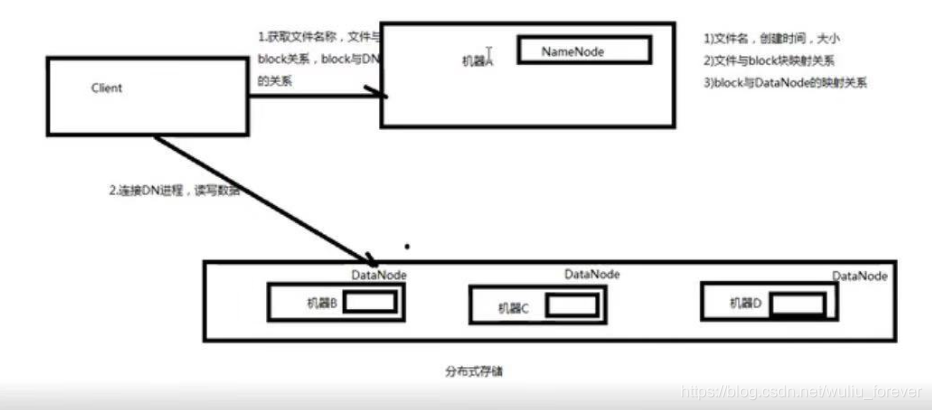
c:HDFS组件
1、NameNode是主节点,存储文件的元数据如文件名、文件目录、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。1)、元数据:文件名、目录名、属性(生成时间、权限、副本);2)、文件名与block列表映射关系;3)、block与DataNode列表映射关系;
2、DataNode在本地文件系统存储文件块数据,以及块数据的检验。
a、作用(存储真实的数据信息);b、数据存储目录dfs.datanode.data.dir;c、block块:默认128M(dfs.blocksize设置);d、副本策略(1、默认三个dfs.replication设置;2、存放形式:如果客户端在集群中,第一个副本放到客户端机器上;否则第一个副本随机挑选一个不忙的机器;第二个副本放到和第一个副本不同的机架上的一个服务器上;第三个副本放到和第二个副本相同机架不同服务器上;如果还有更多副本随机存放)
3、SecondaryNameNode是用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照。分担NameNode压力,合并编辑日志edit和镜像文件fsimage(因为合并操作需要占用很大资源,影响客户端请求),合并后将最终的镜像文件fsimage返回给NameNode进行处理。
2.4、yarn:资源调度和任务管理
1、四大组件
ResourceManager(RM):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
NodeManager(NM):单节点上的资源管理、处理来自 ResourceManager的命令、处理来自ApplicationMaster的命令;
ApplicationMaster(AM):程序切分、为应用程序申请资源、并分配任务、任务监控与容错;
Container:对任务运行环境的抽象,封装了CPU、内存等多维度资源以及环境变量、启动命令等任务运行相关的信息;
2、执行流程
2.1、Client连接RM提交作业,RM给Client一个JobId(注:ApplicationsManager和ResourceScheduler)
2.2、RM中的ApplicationsManager连接一个NM,让NM创建一个AM处理客户端作用请求。
2.3、AM连接RM中ApplicationsManager申请NodeManager
2.4、AM去ResourceScheduler给Client的作业申请资源(cpu、内存、磁盘、网络)
2.5、AM连接NM,发送client job作业程序和申请资源
2.6、NM启动Container进程运行job的不同任务
2.7、Container进程运行状态实时反馈给AM
2.8、AM反馈任务状态信息给RM中的ApplicationsManager
2.9、client端可以在连接RM或AM查询job的执行情况
注:NM启动后去RM上进行注册,会不断发送心跳,说明处于存活状态
2.5、MapReduce
2.5.1、各项指标
a、Cluster Metrics
集群指标:app(提交、排队、运行、完成)、Container个数、资源(内存、cpu)
b、Cluster Nodes Metrics
机器状态:Active、Decommissioning、Decommissioned、Lost、Unhealthy、Rebooted、Shutdown
c、作业指标

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









