




 本文介绍了一种名为Lift-Splat-Shoot(LSS)的方法,该方法通过对多摄像头数据进行处理,在鸟瞰(BEV)视角下直接完成车辆分割、可行驶区域和车道线分割等任务。LSS包含Lift、Splat和Shoot三个关键步骤,能够确保模型具备平移等变性、排列不变性和自我参照等距等变性的优点,同时实现了端到端的训练。
本文介绍了一种名为Lift-Splat-Shoot(LSS)的方法,该方法通过对多摄像头数据进行处理,在鸟瞰(BEV)视角下直接完成车辆分割、可行驶区域和车道线分割等任务。LSS包含Lift、Splat和Shoot三个关键步骤,能够确保模型具备平移等变性、排列不变性和自我参照等距等变性的优点,同时实现了端到端的训练。
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D 论文阅读笔记
论文链接:https://arxiv.org/abs/2008.05711
代码链接:https://github.com/nv-tlabs/lift-splat-shoot
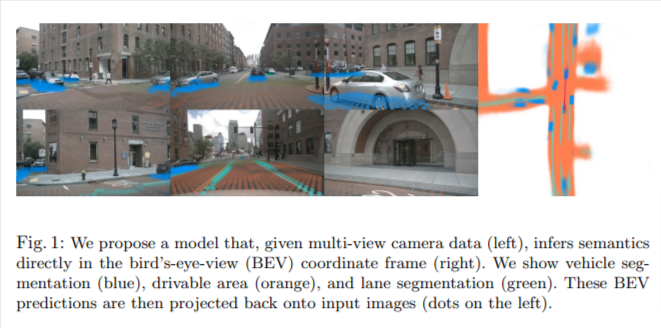
一、 Problem Statement
single-image到multi-view的范式:对于 n n n个相机的数据,通常是使用一个single-image的检测器对所有的输入图像分别做检测,然后再通过内外参的后处理,汇总到车体坐标系上。这样的范式有以下三个优点:
- Translation equivariance
- Permutation invariance
- Ego-frame isometry equivariance
然而,上述的范式也有缺点,即使用来自单个图像检测器的后处理检测阻止了从基于车体本身做的预测到输入图像的反向梯度(我认为并不是好的端到端检测)。
二、 Direction
本文探索的是通过多路摄像头数据,直接在BEV下完成vehicle segmentation. drivable area, 和lane segmentation任务。提出 "Lift-Splat"模块,保证了上述三个优点的同时,也能够端到端的训练。也提出了一个Shooting模块(有关路径规划的,本文就不细讲了)。
- Lift: 这个操作就是通过生成一个视锥形的点云把图像升维到3D。
- Splat: 这个操作就是将所有视锥转换到一个参考平面。
- Shooting: 这个操作就是将预测出的路径转换到参考平面上,做一个端到端的路径规划。
三、 Method
给定了 n n n张图像, { X k ∈ R 3 × H × W } n \{X_k \in \R^{3 \times H \times W}\}_n { Xk∈R3×H×W}n,还有其对应的外参矩阵 E k ∈ R 3 × 4 E_k \in \R^{3 \times 4} Ek∈R3×4,内参矩阵 I k ∈ R 3 × 3 I_k \in \R^{3 \times 3}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1261
1261




 到【灌水乐园】发言
到【灌水乐园】发言







