



引子:那一天,半个互联网“心跳骤停”
2025年11月18日,UTC时间11:48 分左右,全球互联网用户经历了一场突如其来的“数字寂静”。从热门的聊天应用Discord,到电商巨头Shopify,再到无数依赖API服务的初创公司,纷纷陷入无法访问的瘫痪状态。恐慌情绪迅速蔓延,无数运维工程师的手机被警报信息淹没。
所有线索都指向了同一个名字——Cloudflare。
这家被誉为互联网“安全守护神”的公司,其遍布全球的网络节点,在此刻成为了一个巨大的“黑洞”,吞噬着本应川流不息的数据。问题是,能让如此庞大和成熟的系统瞬间崩溃的,究竟是毁天灭地的超级攻击,还是某个微不足道的内部失误?
数小时后,Cloudflare官方发布了初步调查报告,原因令人震惊:一次旨在提高网络韧性的常规配置变更,意外地变成了一场席卷全球的灾难。
这并非简单的“草台班子”失误,而是一次深刻暴露了现代互联网基础设施脆弱性的典型事件。今天,让我们像解剖精密仪器一样,层层剥开这次事故的表象,直抵其技术内核,看看我们能从中汲取哪些宝贵的经验与教训。
第一部分:Cloudflare的“王座”——它究竟是什么?
在深入故障之前,我们必须先理解Cloudflare在互联网世界中的核心地位。简单来说,它扮演着两个关键角色:“快递加速员”和“御前带刀侍卫”。
1. 快递加速员:Anycast + CDN
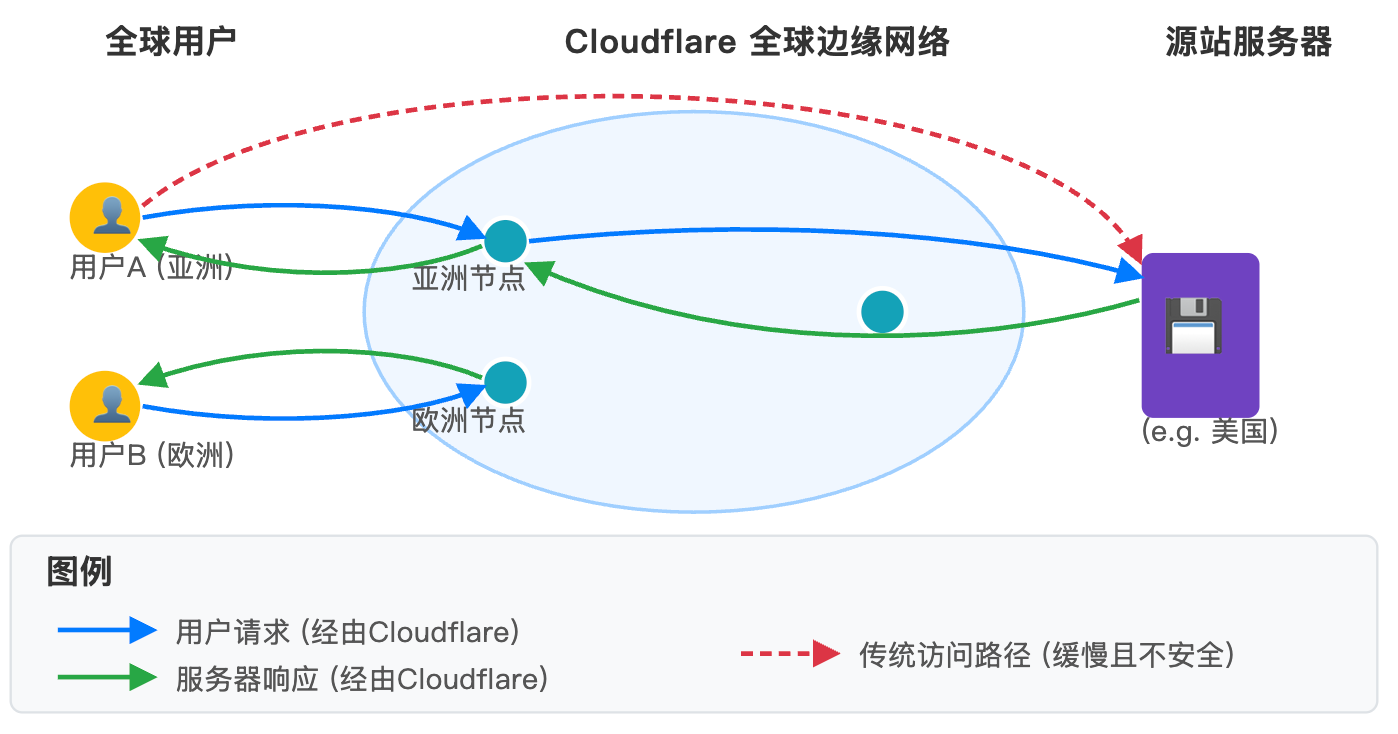
想象一下,你的网站服务器在美国(源站),当一个中国用户访问时,数据需要跨越太平洋,延迟极高。Cloudflare的解决方案是在全球,比如在中国香港、新加坡等地,部署大量的边缘服务器(Edge Server)。
它通过一种名为 Anycast(任播) 的网络技术,让用户的访问请求自动被路由到物理距离最近的服务器节点上。如果这个节点已经缓存了你网站的内容(这就是CDN,内容分发网络),用户就能就近秒速获取,体验如丝般顺滑。
Cloudflare 工作原理示意图(描述: 一张图,左侧是“全球用户”,中间是Cloudgard的“全球边缘网络(Anycast)”云图,右侧是“源站服务器”。用户的请求被智能地导向最近的边缘节点,而不是直接访问遥远的源站。)
2. 御前带刀侍卫:WAF & Anti-DDoS
除了加速,Cloudflare更核心的价值在于安全。它像一个置于你网站之前的巨大过滤器和盾牌。
-
WAF (Web应用防火墙):能识别并拦截SQL注入、跨站脚本(XSS)等恶意网络攻击。
-
Anti-DDoS:当你的网站遭遇DDoS(分布式拒绝服务)攻击,即海量垃圾流量涌入时,Cloudflare的庞大网络带宽可以像海绵一样吸收掉这些攻击流量,确保你的源站安然无恙。
正是因为Cloudflare在全球互联网流量中扮演了如此关键的“咽喉”角色,它的任何一次“咳嗽”,都会让整个互联网世界为之“感冒”。
那么,这个身经百战的巨人,究竟是如何被一行配置绊倒的呢?
我会用最通俗的语言,结合图解,为你深度剖析这次事故的根源——BGP协议,以及一个微小的配置错误是如何引发全球性雪崩的。
第二部分:致命的“回车”——BGP风暴是如何掀起的?
很多技术文章在分析这类事故时,会用“一个意外的bug”、“系统配置失误”等词语一笔带过。但今天,我们要挖得更深。Cloudflare的这次全球宕机,其“病灶”在于互联网的基石协议之一——BGP(边界网关协议)。
1. BGP:互联网的“全球卫星导航系统”
要理解这次事故,你不需要成为网络专家,只需要明白一个比喻:BGP 就是整个互联网的 GPS 导航系统。
-
自治系统 (AS): 互联网是由成千上万个独立管理的网络(比如中国电信、谷歌、Cloudflare等)组成的,每一个都叫一个“自治系统”(Autonomous System, AS)。你可以把每个AS想象成一个独立的“国家”。
-
IP地址块 (Prefix): 每个“国家”(AS)都拥有一系列“门牌号码”,也就是IP地址段。这在BGP里被称为“前缀”(Prefix)。
-
BGP的工作: BGP协议的核心任务,就是让这些“国家”互相广播:“嘿,想到达我这里的某个‘门牌号’(IP Prefix),请走这条路!”。所有AS的路由器会根据收到的这些“路况”信息,构建出到达全球任意角落的最佳路径图。
这个系统高效、稳定地运行了几十年,但它建立在一个脆弱的基础之上:信任。它默认每个AS广播出来的路径信息都是真实、准确的。一旦有人广播了错误的信息,就像GPS系统里出现了一个错误的信号源,全球的“交通”都可能陷入混乱。
2. 事故复盘:三步走向“深渊”
根据Cloudflare官方的事故报告,整个过程如同一部精密的悲剧,环环相扣。
第一步:善良的初衷 (The Goal)
为了进一步提升网络可靠性,Cloudflare的工程师团队计划对其网络主干(Backbone)进行一项优化。他们希望改变某些BGP路由的宣告策略,以便在某个物理位置(如一个城市的数据中心集群)出现问题时,能更灵活地将流量重新路由到其他地方。这是一个非常常规且善意的维护操作。
第二步:致命的变更 (The Change)
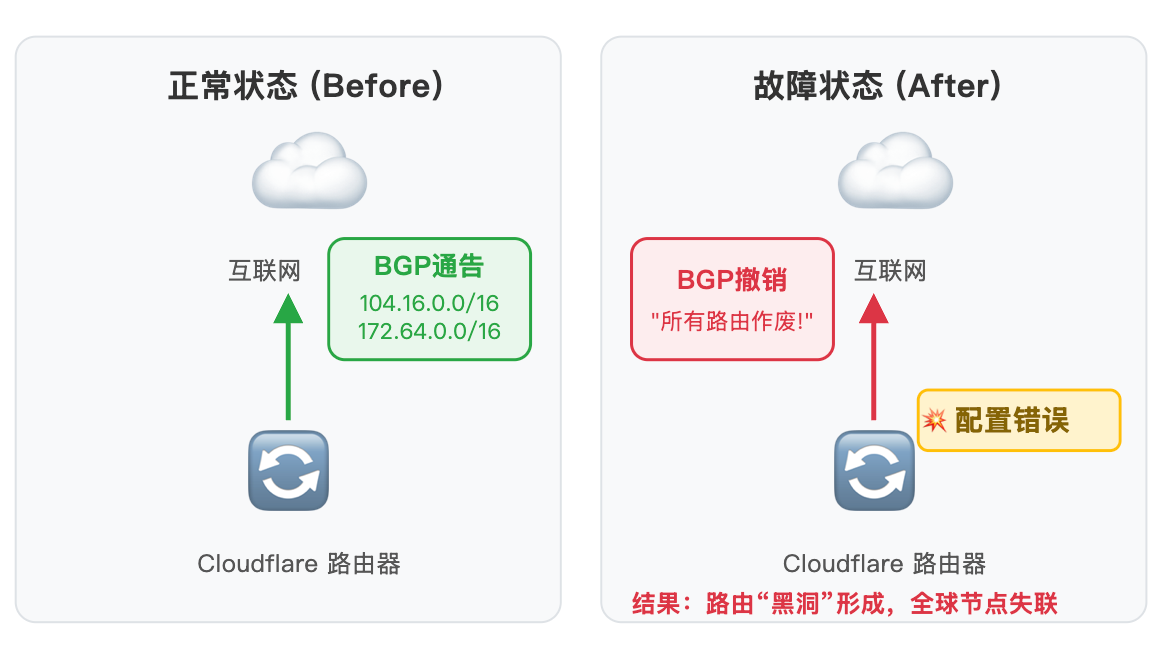
工程师们在一个位于弗吉尼亚州阿什本(Ashburn)的路由器上,部署了一项新的路由策略。这个策略的本意是:“对于某些特定的、我们想调整的路由,请撤回它们的BGP通告”。
然而,策略的匹配条件写得过于宽泛了。本应只匹配一小部分特定路由的规则,错误地匹配了所有的BGP路由。
第三步:灾难的扩散 (The Cascade)
当工程师按下回车,部署这个错误策略后,灾难性的连锁反应开始了:
-
路由撤销: 该路由器立即开始向其所有对等路由器(Peers)发送BGP
UPDATE消息,内容是:“我之前告诉你们可以通往我这里的那些‘门牌号’,现在全部作废!” -
“毒”信息传播: Cloudflare的内部网络高度互联。收到这条撤销消息的路由器,会立刻更新自己的路由表,并忠实地将这个“坏消息”继续传播给与之相连的其他路由器。
-
全球瘫痪: 这个过程像病毒一样,在短短几十秒内传遍了Cloudflare的全球骨干网络。最终,负责通告Cloudflare核心IP地址段的19个数据中心(包括阿姆斯特丹、亚特兰大、法兰克福、伦敦、纽约等关键枢纽)的BGP路由全部被撤销。
从外部互联网看来,这19个数据中心就好像突然从地球上“蒸发”了。所有指向这些数据中心的流量都找不到路径,导致全球范围内大量依赖Cloudflare服务的网站和应用瞬间离线。
BGP路由通告撤销示意图 (描述: 一张分为“之前”和“之后”的对比图。之前,Cloudflare路由器向互联网正确广播其IP地址段。之后,由于配置错误,路由器向互联网发送了“撤销”消息,导致其IP地址段在互联网上变得不可达。)
3. 从事故中学到的两个“刺骨”教训
这次事件远非一个工程师的“手滑”那么简单,它暴露了大型分布式系统运维中两个深刻的难题:
-
“爆炸半径”(Blast Radius) 失控: 在SRE(网站可靠性工程)领域,一个核心原则是控制变更的“爆炸半径”,即任何一次变更可能影响的范围。理想情况下,这样的变更应该先在单个路由器、单个数据中心进行“金丝雀发布”,验证无误后再逐步推向全球。而这次事故中,一个节点的变更瞬间污染了全球网络,说明其变更管理和部署流程未能有效隔离风险。
-
对基础协议的“过度自信”: 我们每天都在使用HTTP、DNS、BGP这些协议,但往往忽略了它们底层的脆弱性。这次事故提醒我们,越是基础和核心的组件,其变更越需要“敬畏之心”。对BGP这类协议的任何操作,都需要更加精细化的策略验证、模拟推演和自动化的安全检查机制,而不是仅仅依赖于人的审查。
Cloudflare在这次事故中摔的这一跤,代价是惨痛的,但也为整个行业提供了宝贵的“错题集”。那么,面向未来,我们该如何构建一个更具韧性的互联网呢?
第三部分:未来畅想——如何为互联网构建“不死之身”?
Cloudflare的这次“心跳骤停”事件,如同一次压力巨大的全球性“消防演习”,它迫使我们重新思考:当系统复杂到一定程度,我们还能否依赖传统的测试和人为审查来保证其稳定性?答案显然是否定的。
未来的互联网安全与稳定,必须建立在一套全新的设计哲学和技术体系之上。这不仅仅是Cloudflare一家的功课,而是整个行业需要共同探索的方向。
1. 架构演进:从“防错”到“容错”的哲学转变
传统的系统设计理念是“预防故障”(Fault Prevention),我们试图通过详尽的测试、严格的代码审查来杜绝一切错误的发生。但在Cloudflare这个级别的系统中,组件数以百万计,交互关系错综复杂,彻底“防错”已无可能。
未来的架构设计必须全面拥抱 “容错设计” (Design for Failure)。这意味着,我们在设计之初就要接受一个残酷的现实:故障一定会发生。我们的目标不是阻止故障,而是在故障发生时,系统依然能够优雅地降级,并将影响控制在最小范围之内。
具体实现路径包括:
-
单元化/多活架构 (Cell-based Architecture): 将庞大的系统切分成多个独立的、自给自足的“单元”(Cell)。每个单元内部高度自治,拥有自己的数据、计算和网络资源。单元之间通过明确的API进行通信。这样,即便一个单元(甚至是一个大区)完全崩溃,其他单元也能独立运行,服务不会全面中断。这正是“爆炸半径”控制在架构层面的终极体现。
-
解耦与异步化: 系统各模块间应尽可能减少同步强依赖。大量采用消息队列(Message Queue)等异步通信机制。比如,一个请求的不同处理环节可以解耦,即使某个下游服务暂时不可用,请求也不会立即失败,而是可以被暂存,等待服务恢复后继续处理。
2. 混沌工程 (Chaos Engineering):主动拥抱混乱的“疫苗”
如果说“容错设计”是构建强壮的“身体”,那么 混沌工程 就是为这个身体定期接种“疫苗”,以提升其免疫力。
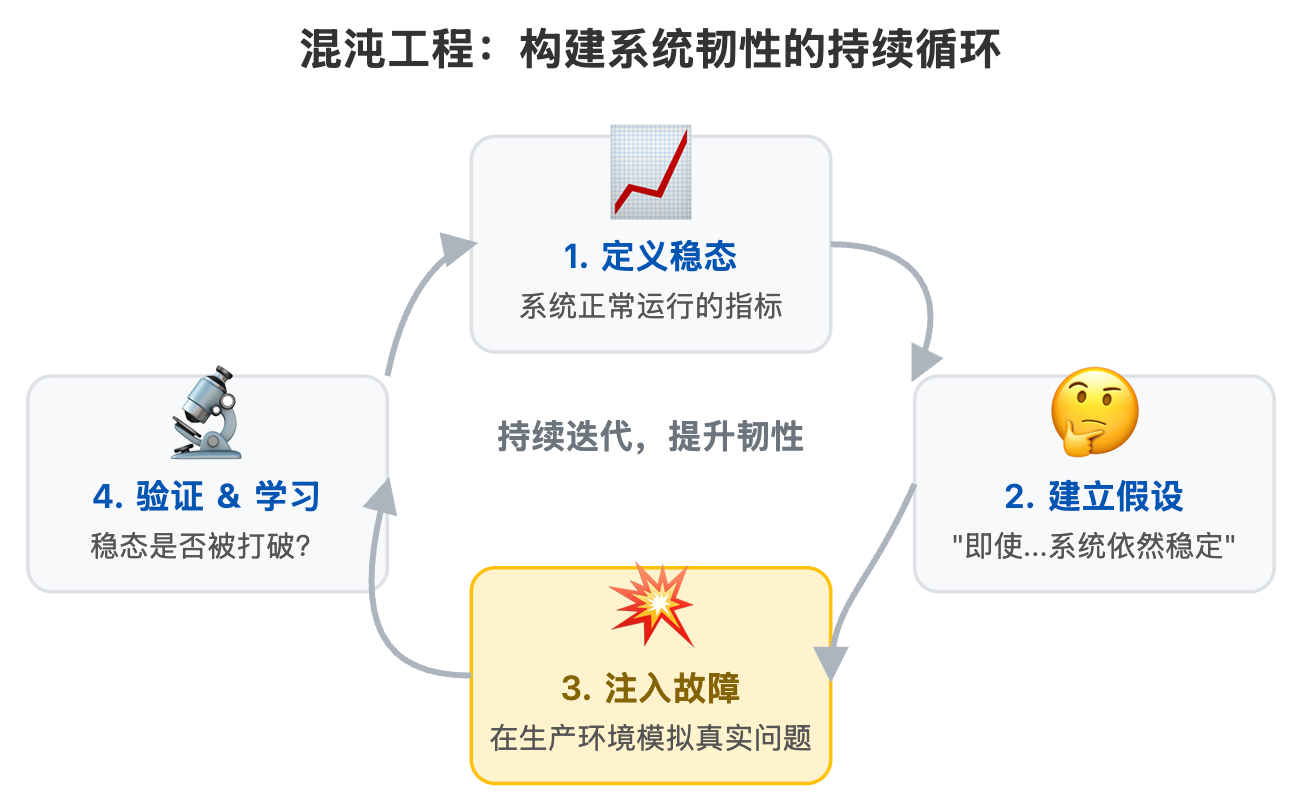
混沌工程不是简单的随机测试。它是一门在生产环境中主动注入可控故障,以验证系统韧性的学科。Netflix是这一领域的先驱,其著名的“Chaos Monkey”工具会随机关闭生产环境中的虚拟机实例,以此来检验服务是否具备自动恢复的能力。
对于Cloudflare这样的网络基础设施,混沌工程可以有更高级的玩法:
-
BGP路由抖动注入: 模拟BGP路由的不稳定,观察流量是否能自动切换到备用路径。
-
数据中心隔离演练: 在不通知业务团队的情况下,通过防火墙规则,模拟某个数据中心与外界的“失联”,检验多活切换和灾备预案是否如预期般生效。
-
延迟与丢包注入: 在核心网络路径上模拟网络质量下降,测试上层应用在弱网环境下的表现和降级策略。
通过常态化的混沌工程演练,我们可以在可控的时间和范围内,提前暴露那些在设计和测试阶段难以发现的“深水区”问题,而不是等到真正的灾难来临时才手忙脚乱。
混沌工程原理示意图 (描述: 一张图展示混沌工程的闭环流程。从“定义稳态”开始,到“提出假设”,然后通过“注入故障”(如关停服务器、模拟网络延迟)来“验证假设”,最后从“发现的脆弱点”中学习并“改进系统”,形成一个持续提升的循环。)
3. 智能化运维 (AIOps):让机器自己守护机器
人的反应速度和处理能力终究是有限的。面对全球网络的瞬息万变,未来运维的终极形态必然是AIOps (AI for IT Operations)。
-
智能变更审查: 在代码或配置提交时,AI模型可以自动分析其潜在风险。比如,通过学习历史上所有引发过故障的BGP配置变更,AI可以在工程师按下“回车”前,就发出高风险警告:“你这次的变更与2022年那次全球宕机事件的模式高度相似,请三思!”
-
异常检测与根因分析: 基于机器学习算法,AIOps系统可以实时监控数百万个系统指标(Metrics),在人类难以察觉的微小波动中,发现异常的前兆。当故障发生时,它能快速关联日志、追踪和指标数据,在几秒钟内定位出可能的故障根源,大大缩短MTTR(平均修复时间)。
-
自动化愈合: 更进一步,当检测到特定类型的故障时,系统可以触发预设的自动化预案(Playbook)进行自我修复,例如自动隔离故障节点、执行回滚操作、切换流量等,实现无人干预的“自愈”能力。
虽然完全的AIOps 遥远,但其核心思想——用数据和算法来增强乃至替代人的决策——无疑是提升大型系统稳定性的必由之路。
第四部分:结语——废墟之上,重建信任
2025年11月18日的这次事件,无疑是Cloudflare乃至整个互联网基础设施领域一次深刻的“疤痕”。但正如医学上的疤痕会让皮肤变得更坚韧一样,技术世界的每一次重大故障,只要被认真对待、深度复盘,都将成为推动行业进步的基石。
从一行错误的BGP配置,到半个互联网的短暂瘫痪,这个故事告诉我们:
-
复杂性是根本的敌人: 在现代超大规模系统中,任何试图依靠“人不出错”来保障安全的想法都是天真的。我们的核心任务,是构建一个即便在有人犯错、有组件失灵时,依然能保持基本可用的系统。
-
基础不牢,地动山摇: 我们往往惊叹于上层应用的日新月异,却忽视了支撑这一切的BGP、DNS等底层协议的脆弱性。对这些“看不见”的基础设施保持敬畏和持续投入,是整个数字世界的责任。
-
透明是重建信任的唯一途径: Cloudflare在事故后数小时内发布详尽的技术分析报告,公开承认错误并阐述改进措施。这种坦诚和透明的态度,虽然短期内承受了舆论压力,但长期看,却是维护用户信任、引领行业共同进步的最佳方式。
这次故障不是第一次,也绝不会是最后一次。人类构建的任何系统都有其边界和弱点。关键在于,我们能否从每一次“坠落”中,学到如何飞得更高、更稳。对每一位技术从业者而言,这不仅仅是一个“瓜”,更是一份沉甸甸的教材,值得我们反复品读、警钟长鸣。

关注我们,看见未来
嘿,我是三味。
在技术的浪潮中,我们既是冲浪者,也是修船人。如果你和我一样,对技术背后的原理充满好奇,对构建更美好的数字世界怀有热忱,那么你来对地方了。
关注公众号【爱三味】,这里没有浮光掠影的快讯,只有深入骨髓的思考。每周,我都会为你带来这样一篇深度解析,陪你一起成长,洞见未来。
想和更多技术同好交流? 👇👇👇 💬 QQ交流群:949793437 在这里,你可以随时抛出你的疑问,分享你的见解,和一群志同道合的朋友探讨从代码哲学到宇宙尽头的一切。

觉得这篇文章有价值? 一个简单的动作,就是对我最大的支持!
🔄 点击“在看”,分享到朋友圈 让这篇文章飞向更远的地方,帮助更多人理解我们所处的技术世界。每一次分享,都是在为构建一个更健壮、更开放的互联网贡献一份力量。
期待与你,下次再见!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











