




模块划分
基于版本5.1.1
- SPI:可插拔架构设计,SPI机制
- SQL Parser:SQL语法、方言解析
- ANTLR
- Mode:分布式治理设计
- Memory
- Standlone
- Cluster:etcd,zk
- Infra:基础组件
- Binder:SQL语法树和SQL表结构绑定和识别
- Route:SQL路由
- Rewrite:SQL改写,加密或者分片改写
- Executor:执行器,AP or TP
- Merge:结果集合并
- Federation:跨库SQL
- Kernel:内核功能
- Authority:权限
- Pipeline:数据管道
- Schedule:调度
- Traffic
- Transaction:事务
- XA
- BASE
- Feature:功能模块
- Sharding:分库分表
- Read-Write Split:读写分离
- DB discovery:数据库发现、HA
- Encrypt:数据库加密
- Shadow:影子库、压测
- 功能生态扩展中…
- Proxy
- 网络通信、netty
- 数据库协议
- jdbc
- jdbc接口
- spring命名空间
- Agent
- 探针、可观察性
- Test
- Example
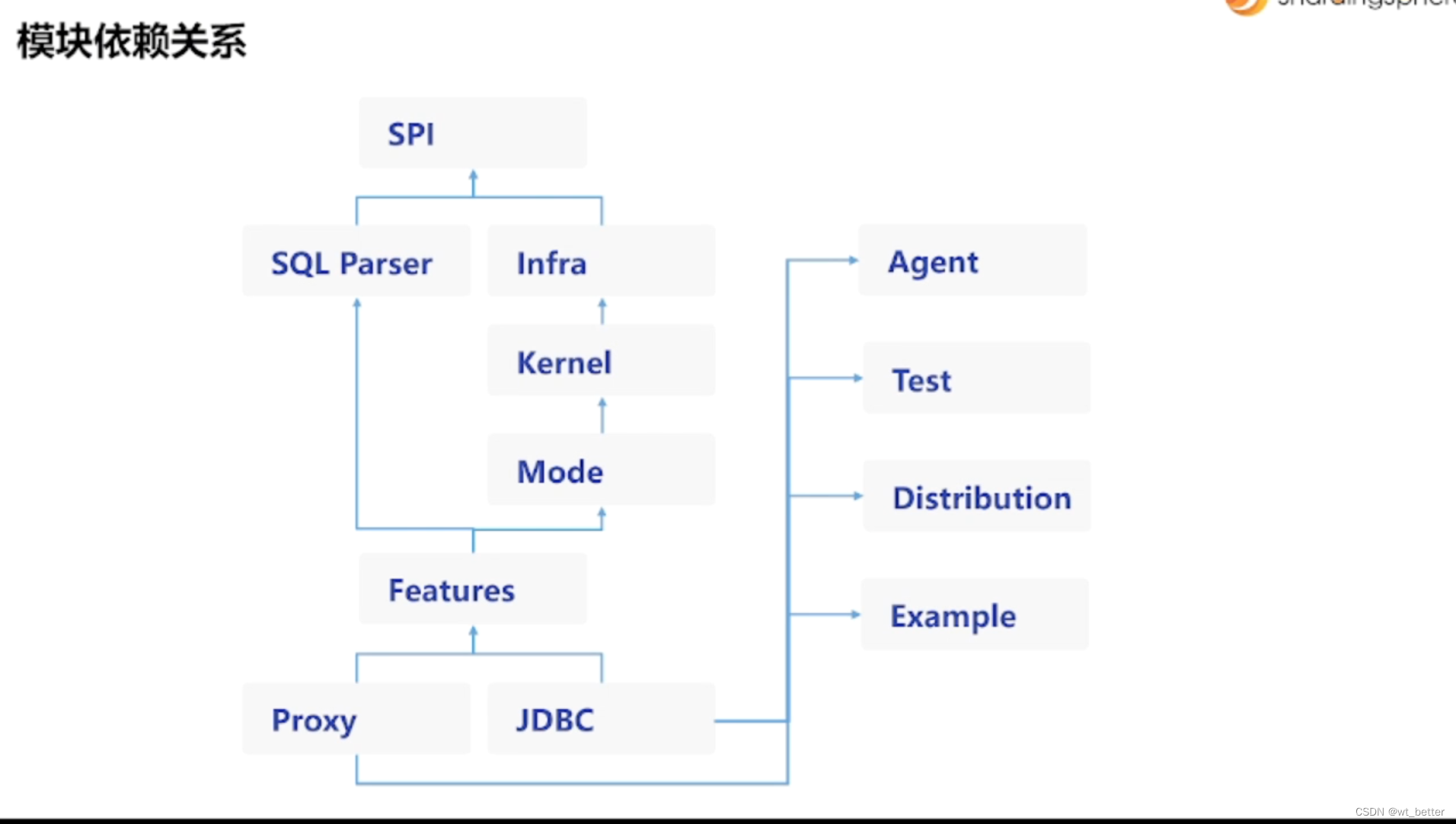
模块依赖关系

















 2604
2604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









