






 博主遇到访问淘宝和京东导致Chrome、Edge崩溃的问题,尝试多种常规解决方案无效。通过查看系统日志,发现DWrite.dll可能与系统版本不兼容,而Gabriola.ttf字体缺失。将Gabriola.ttf字体正确安装并选择"为所有用户安装",解决了崩溃问题,建议有类似错误日志的朋友可以尝试此方法。
博主遇到访问淘宝和京东导致Chrome、Edge崩溃的问题,尝试多种常规解决方案无效。通过查看系统日志,发现DWrite.dll可能与系统版本不兼容,而Gabriola.ttf字体缺失。将Gabriola.ttf字体正确安装并选择"为所有用户安装",解决了崩溃问题,建议有类似错误日志的朋友可以尝试此方法。
近期自己电脑出现只要访问淘宝和京东就崩溃问题,其他网站都不会出问题,尝试过升级chrome,清除浏览器数据,禁用chrome插件,按照网上一些处理chrome崩溃办法都没用,chrome不行换edge吧,神奇的是edge也是同样的问题,换firefox正常,由于之前升级到win10 1903,一度怀疑系统问题,但笔记本也同样升级过,访问正常,电信劫持也考虑过,挂vpn也崩溃,而且笔记本也能正常访问,换dns也不行,hosts,lsp等也检查过。实在没辙,如果重装系统就太麻烦了,后来打算调试chrome标签页崩溃信息,查方法得过程中看到google的一些提示,说可以看下系统日志,果然当标签页崩溃后会产生两个错误,如图
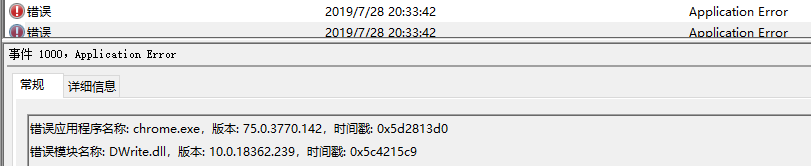

先看下DWrite.dll,版本跟系统版本一致,应该是升级时有更新,如果是与chrome有兼容问题也处理不了,要么win10降级,要么等chrome或win10升级.
再看下Gabriola.tff,进入系统字体目录 c:\windows\fonts,还真没有这个字体,看了下笔记本上字体目录,是有这个字体的,感觉有戏,拷贝一份放到台式机fonts下,系统提示安装字体,完成后运行chrome,问题和错误日志照旧。到fonts目录下双击字体文件,能看到预览,字体应该没问题,但是字体图标是灰色的,经网上搜索,灰色表示字体被系统隐藏了,右键点击字体,菜单中选择显示,字体的图标变成正常的黑色了,运行chrome,问题和错误日志照旧,重启电脑后依然照旧,难道字体没装对?删除后按照一般装字体步骤再装一遍,右键点击字体文件,选择“安装”,我右键点击字体文件时,赫然发现还有个选项是
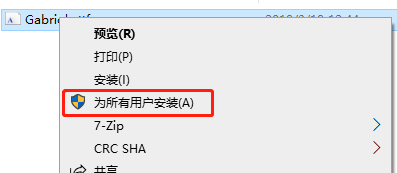
好吧,试下这个,不管怎样,每个用户都装肯定好些,安装好后运行chrome,问题解决,终于又可以愉快的上淘宝和京东了。
总结一下,说了那么多,其实就是字体丢失了,字体为何会丢失就不知道了,但引起chrome和edge崩溃就很蛋疼,安装字体时选择“为所有用户安装”是关键,如果有朋友碰到同样的问题,有同样的错误日志的可以试下看能否解决问题。

















 1449
1449

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









