




 本文深入探讨了栈和队列这两种基本数据结构的概念、特性及其应用。详细解释了栈的后进先出(LIFO)原理,包括进栈、出栈操作,以及栈在递归中的作用。同时,阐述了队列的先进先出(FIFO)特性,介绍了队列的抽象数据类型和不同存储方式,如顺序存储和链式存储。
本文深入探讨了栈和队列这两种基本数据结构的概念、特性及其应用。详细解释了栈的后进先出(LIFO)原理,包括进栈、出栈操作,以及栈在递归中的作用。同时,阐述了队列的先进先出(FIFO)特性,介绍了队列的抽象数据类型和不同存储方式,如顺序存储和链式存储。
1.栈:栈(stack)是限定仅在表尾进行插入和删除操作的线性表
2.允许插入和删除的一端称为栈顶,另一端称为栈底,不含任何数据数据元素的称为空栈。栈又称后进先出的线性表
3.栈的插入操作,叫进栈;栈的删除操作, 叫出栈
4.。不一定最先进栈的元素就只能最后出栈,在不是所有元素都进栈的情况下,事先进去的元素也可以出栈,只要保证栈顶元素出栈即可
5.栈限定了线性表的插入和删除位置
6.栈的抽象数据类型(ADT)
ADT 栈(stack)
Data
同线性表。元素具有相同的类型,相邻元素具有前驱和后继关系
Operation
InitStack (*S) : 初始化操作,建立一个空栈S
DestroyStack(*S) : 若栈存在,则销毁它
ClearStack(*S): 将栈清空
StackEmpty(S): 若栈为空,返回True, 否则返回false
GetTop(S,*e):若栈存在且非空,用e返回S的栈顶元素
Push(*S,e):若栈S存在,插入新元素e到栈S中并成为栈顶元素
Pop(*S,*e):删除栈S中栈顶元素,并用e返回其值
StackLength(S):返回栈S的元素个数
endADT
7.对于数组而言用下标为0的一端表示栈底,top表示栈顶元素在数组中的位置,通常把空栈的判定条件top为-1,当栈中存在一个元素时,则top=0
8.栈的结构定义
typedef int SElemType; //SElemType类型根据实际情况而定,这里假设为int
typedef struct
{
SElemType data[MAXSIZE];
int top; //用于栈顶的指针
}SqStack;
9.进栈操作push
//插入元素e为新的栈顶元素
Status Push(SqStack *S, SElemType e)
{
if(S->top == MAXSIZE -1 ) //栈满
return ERROR;
S->top++; //栈顶指针增加1
S->data[S->top]=e; //将新插入的元素给栈顶空间
return OK;
}
10.出栈操作 pop
//若栈不为空,则删除S的栈顶元素,用e返回其值,并返回OK;否则返回ERROR
Status Pop(SqStack *S, SElemType *e)
{
if(S->top==-1)
return ERROR;
*e=S->data[S->top]; //将要删除的栈顶元素赋值给e
S->top--; //栈顶指针减1
return OK;
}
两栈共享空享空间:
使用前提:
1.相同的数据类型
2.当两个章的空间需求有相反关系时,一个栈增加,一个栈减少
3.说白了 就是用一个数组存放两个栈,数组的两端为两个栈底
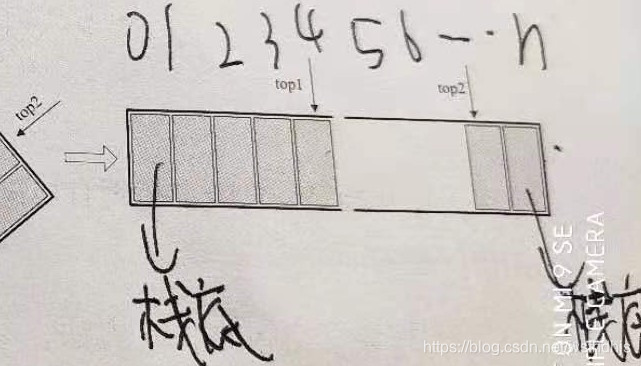
两栈共享空间的结构代码:
//两栈共享空间结构
typedef struct
{
SElemType data[MAXSIZE];
int top1; //栈1栈顶指针
int top2; //栈2栈顶指针
}SqDoubleStack;
两栈共享空间的push方法(插入元素)
//插入元素e为新的栈顶元素
Status Push(SqDoubleStack *S, SElemType e, int stackNumber) //stackNumber判断是栈1还是栈2
{
if(S->top1+1==S->top2) //栈满,不能在push新的元素
return ERROR;
if(stackNumber==1) //栈1有元素进栈
S->data[++S->top1]=e; //若栈1则先top1+1后给数组元素赋值
else if (stackNumber==2) //栈2有元素进栈
S->data[--S->top2]=e; //若栈2则先top2-1后给数组元素赋值
return OK;
}
两栈共享空间pop方法
//若栈不为空,则删除S的栈顶元素,stackNumber是判断栈1还是栈2
Status Pop(SqDoubleStack *S, SElemType * e, int stackNumber)
{
if(stackNumber == 1)
{
if(S->top1==-1) //说明栈1是空栈,则退出
return ERROR;
*e=S->data[S->top1--]; //将栈1的栈顶元素出栈
}
else if(stackNumber==2)
{
if(S->top2==MAXSIZE) //说明栈2已经是空栈,溢出
return ERROR;
*e=S->data[S->top2++]; //将栈2的栈顶元素出栈
}
return ok;
}
4.6
1.栈的链式存储结构,简称链栈,栈顶放在头结点。对于链栈而言没有满栈的情况,对于空栈而言,对于空栈而言top=NULL
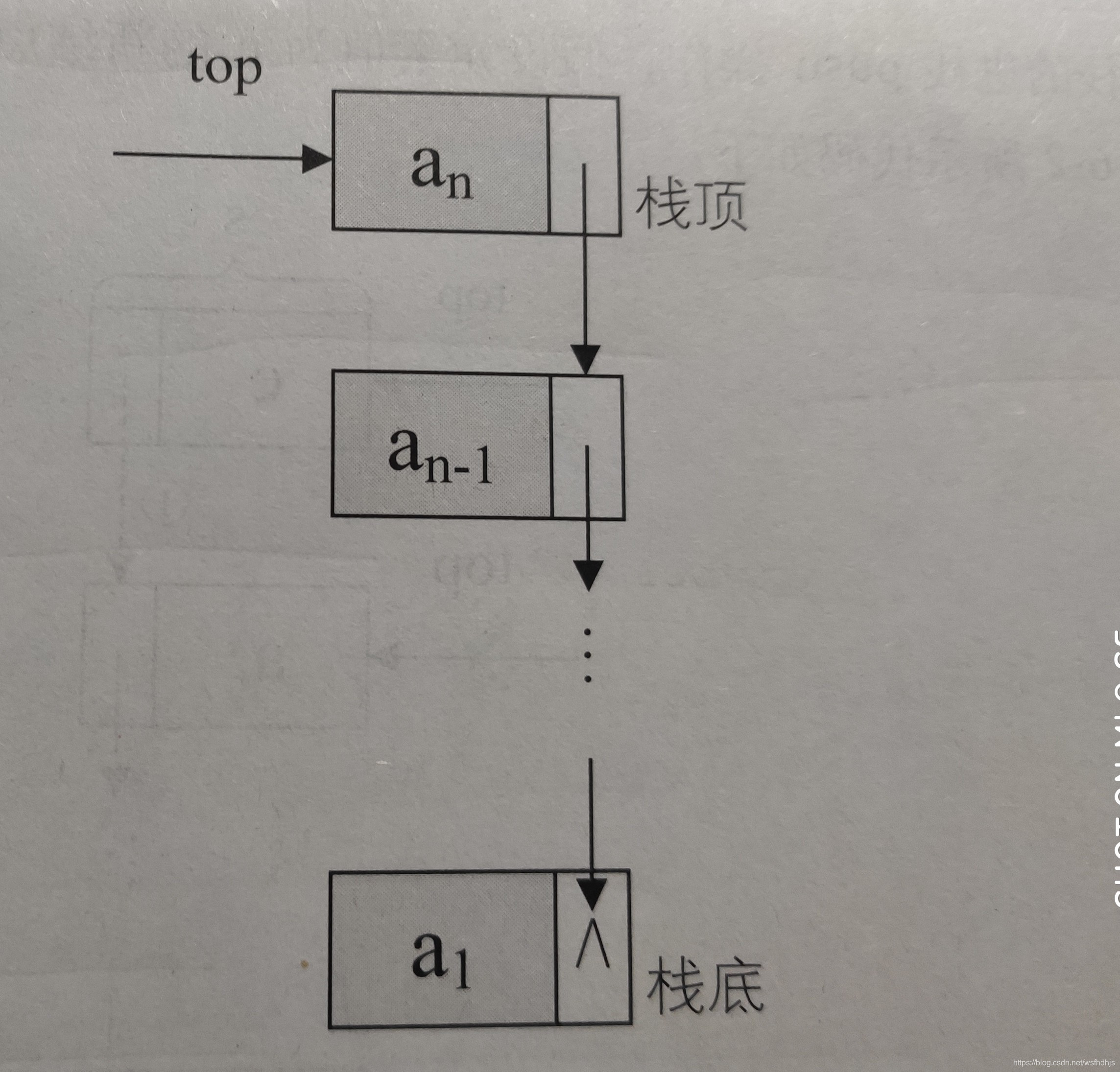
链栈的结构代码:
typedef struct StackNode (链表结构的定义)
{
SElemType data;
struct StackNode *next;
}StackNode, *LinkStackPtr;
typedef struct LinkStack (将栈顶指针和元素总数count构成一个结构)
{
LinkStackPtr top;
int count;
}LinkStack;
栈的链式存储结构–进栈操作
Status Push(LinkStack *S,SElemType e)
{
LinkStackPtr s=(LinkStackPtr) malloc (sizeof(StackNode)); //分配一个结构,并将该结构地址改为LinkStackPtr类型
s->data=e; //将要插入的元素放到新的结构的data中
s->next=S->top; //将原来的栈顶的地址,放到新的结构中的next中
S->top=s; //将新的结点s做为栈顶指针
S->count++;
return OK;
} 时间复杂度为o(1)
栈的链式存储结构–出栈操作
//若栈不为空,则是删除S的栈顶元素,用e返回其值,并返回OK; 否则放回ERROR
Status Pop(LinkStack *S,SElemType *e)
{
LinkStackPtr p;
if(StackEmpty (*S))
return ERROR;
*e=S->top->data; //将栈顶的数据放到*e中
p=S->top;
S->top=S->top->next; //将栈顶指针下移一位,指向后一结点
free(p); //释放掉结点p
S->count--;
return OK;
} 时间复杂度为o(1)
4.7对于链栈和顺序栈的使用建议:
如果栈的使用过程中元素变化不可预料,有时很小,有时很大则使用链栈,如果变化在可控的范围内,建议使用顺序栈会更好。 我认为栈的顺序存储和链式存储相比于普通数组和链表在 (有一个结构存放栈顶元素指针和一个数组)(有一个结构存放栈顶元素指针和链表结构的个数)
4.8.1递归实现裴波那契数列
//裴波那契数列递归函数
int Fbi(int i)
{
if(i<2)
return i == 0 ? 0:1;
return Fbi(i-1)+Fbi(i-2);
}
int main()
{
int i;
for(int i=0; i<40; i++)
printf("%d",Fbi(i));
return 0;
}
迭代的方式计算裴波那契数列
int main()
{
int i;
int a[40];
a[0]=0;
a[1]=1;
printf("%d",a[0]);
printf("%d",a[1]);
for(i=2; i<40; i++)
{
a[i]=a[i-1]+a[i-2];
printf("%d",a[i]);
}
return 0;
}
如图Fbi(5)的函数执行过程
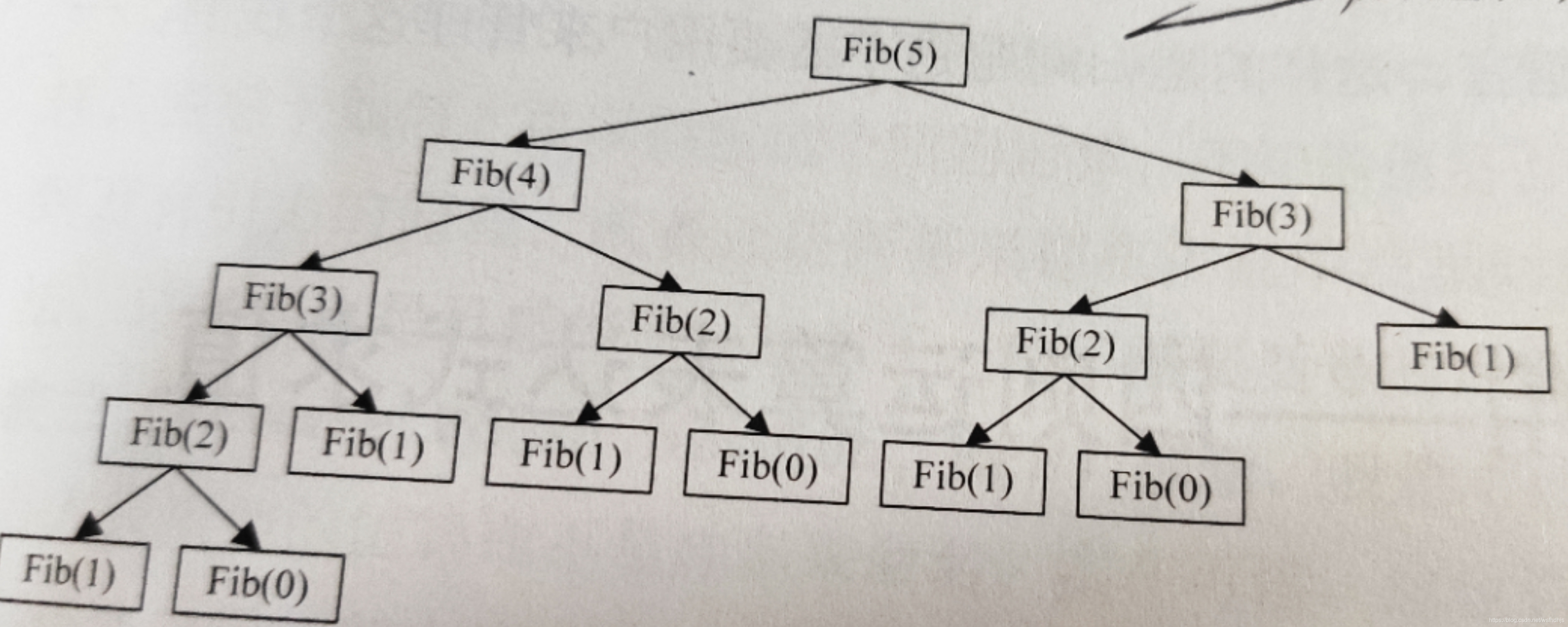
4.8为什么要用栈实现递归:
在前行阶段,对于每一层递归,函数的局部变量,参数值以及返回地址都被压入栈中。在退回阶段,位于栈顶的局部变量,参数值和返回地址被弹出,用于返回调用层次中执行执行代码的其余部分,也就是恢复了调用的状态。
4.9.2
后缀表达式法:
从右至左遇到一个符号,计算该符号前的两个数字
中缀表达式转后缀表达式
规则:
从左至有遍历中缀表达式的每个数字和符号,若是数字就输出,即成为后缀表达式的一部分;若是符号,则判断其与栈顶符号的优先级,是有括号或优先级不高于栈顶符号(惩处优先加减)则栈顶元素一次出栈并输出,并将当前符号进栈,一直到最终输出后缀表达式位置
如:9+(3-1)*3+10/2 最终结果 : 9 3 1 -3 * + 10 2 / +
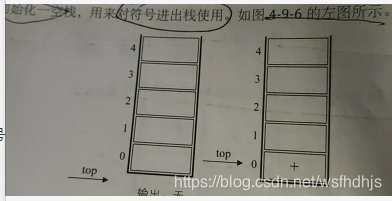

4.10
队列是只允许在一端进行插入插入操作,而在另一端进行删除操作的线性表
队列是先进先出的线性表,而栈是先进后出的线性表,允许插入的一端称为对为,允许删除的一端称为对头
4.11
队列的抽象数据类型:
ADT 队列(Queue)
Data
同线性表。元素具有相同的类型,相邻元素具有前驱和后继关系。
Operation
InitQueue (*Q): 初始化操作,建立一个空队列Q
DestroyQueue(*Q): 若队列Q存在,则销毁它
ClearQueue(*Q):将队列清空
QueueEmpty(Q):若队列为空,返回True,否则返回false
GetHead(Q,*e):若队列Q存在且非空,用e返回队列Q的对头元素
EnQueue(*Q,e):若队列Q存在,插入新元素e到队列Q中并成为队尾元素
DeQueue(*Q,*e):删除队列Q中对头元素,并用e返回其值
QueueLength(Q):返回队列Q的元素个数
endADT
4,12队列插入时往队尾插所以时间复杂度为o(1),将元素出队时,必须从下标为0的地方处,所以时间复杂度为o(n)
注意队列的顺序存储时队头不一定在下标为0的地方,front指向对头元素,rear指针指向队尾元素的下一个位置,同时当font=rear时,队列为空,不是只有一个元素
4.12.2循环队列的顺序存储结构
循环队列的定义:( 普通数组没有front和rear指针)
队列的这种头尾相连的顺序存储结构为循环队列。
当要插入的元素溢出,则可以向前插入元素就是rear可以放到队列前面。
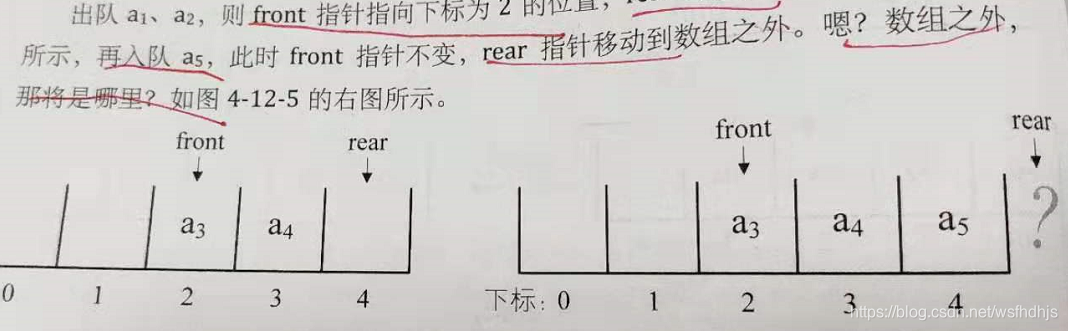
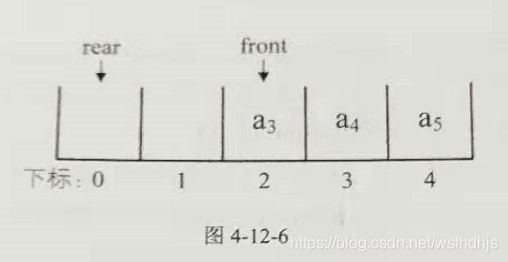
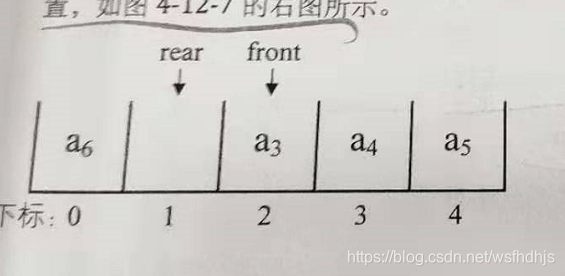
此时要出入a6直接在rear之前插入,时间复杂度为0(1),不然a6就插入到数组外面,则溢出
判断队满的公式为 (rear+1)%QueueSize == front
计算队列的长度公式为(rear-front+QueueSize)%QueueSize
循环队列的顺序存储结构代码:
typedef int QElemType;
typedef struct
{
QElemType data[MAXSIZE];
int front; //头指针
int rear; //尾指针,若队列不为空,指向队列尾元素的下一个位置
}SqQueue;
循环对列初始化的代码:
Status InitQueue(SqQueue *Q)
{
Q->front = 0;
Q-> rear = 0;
return OK;
}
循环队列求队列长度代码:
int QueueLength(SqQueue Q)
{
return (Q.rear-Q.front+MAXSIZE) % MAXSIZE;
}
循环队列的入队操作代码:
Status EnQueue (SqQueue *Q, QElemType e)
{
if((Q->rear+1)%MAXSIZE == Q->front) //队列满的判断
return ERROR;
Q->data[Q->rear]=e; //将元素e放到队尾
Q->rear=(Q->rear+1) %MAXSIZE //将rear指针向后移一位,若到最后则转到数组头部
return OK:
}
循环队列的出队列操作:
Status DeQueue (SqQueue *Q, QElemType *e)
{
if(Q->front==Q->rear)
return ERROR;
*e=Q->data[Q->front]; //将队列头元素赋值给e
Q->front=(Q->front+1)%MAXSIZE; //front指针向后移一位置,若到最后则转到数组头部
return OK;
}
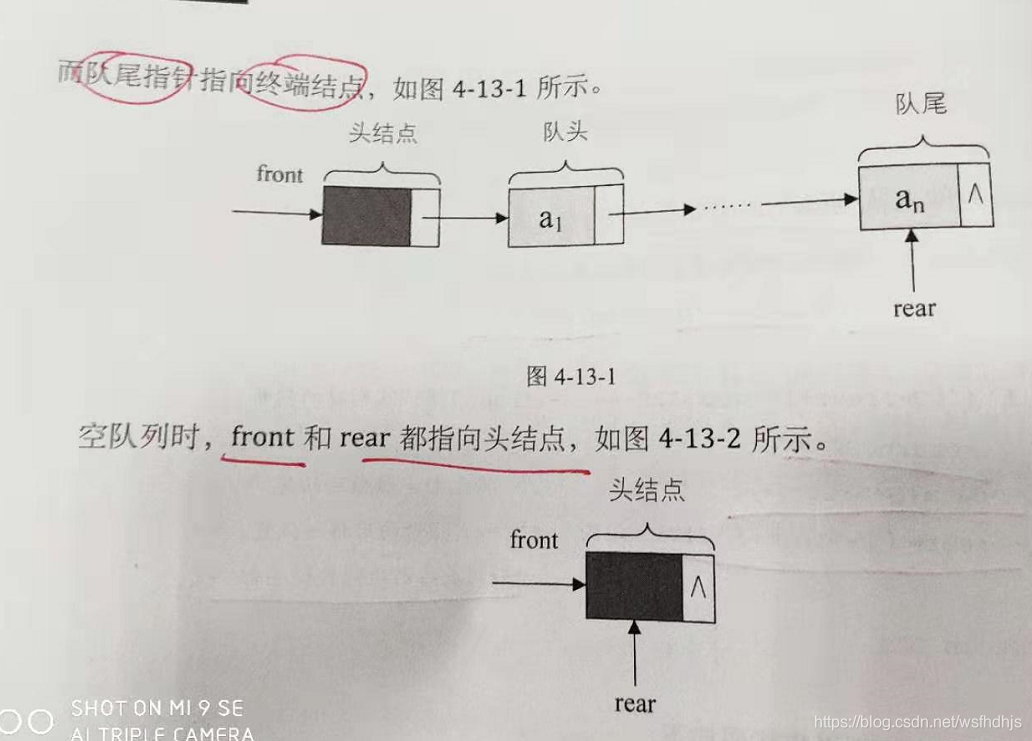
4.13循环队列的链式存储结构
就是线性表的单链表,只不过他只能尾进头出而已,简称为链队列 (普通链表就是尾进尾出)
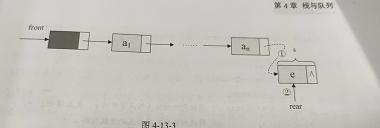
front指向头结点,rear指向队尾结点,如图
空队列时,front和rear都指向头结点
链队列的结构为:
typedef int QElemType; //QElemType 类型根据实际情况而定,这里假设为int
typedef struct QNode //结点结构
{
QElemType data;
struct QNode *next;
}QNode, *
typedef struct //队列的链表结构
{
QueuePtr front,rear; //队头,队尾指针
}LinkQueue;
链队列的插入代码:
//插入元素e为Q的新的队尾元素
Status EnQueue (LinkQueue *Q, QElemType e)
{
QueuePtr s=(QueuePtr)malloc(sizeof(QNode)) //分配一个新结点
if(!d)
exit(OVERFLOW) //存储分配失败
s->data=e; //把要存储的元素e放到新的结点的数据域中
s->next=NULL;
Q->rear->next=s; //Q是一个结构,里面有队头,队尾指针。而队头,队尾指针指向结点见 见图中2
Q->rear=s; //把当前结点s设为队尾结点,rear指向。 见图中2
}
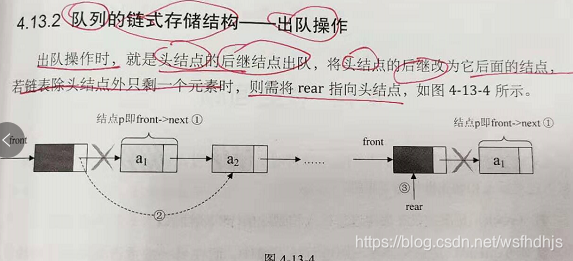
链对列的出队操作
出队操作时,就是头结点的后继结点出队,将头结点的后继改为他后面的结点,若链表除头结点外只剩下一个元素时,则需将rear指向头结点,如图
链队列的出队操作代码
Status DeQueue (LinkQueue *Q,QElemType *e)
{
QueuePtr p;
if(Q->front==Q->rear) //若队列为空
return ERROR;
p=Q->front->next; //将欲删除的对头结点暂存给p,见上图1
*e=p->data; //将欲删除的队头结点的值赋值给e
Q->front->next=p->next; //将原队头结点后继p->next赋值给头结点后继,见上图2
if(Q->rear==p) //若链表头除头结点外只剩下一个元素时,用front撞rear,将要删除的结点撞出去,嘿嘿伪代码,就这样理解即可
Q->rear=Q->front;
free(p);
return OK;
}
总之,如果能确定队列长度最大值的情况下,建议使用循环队列,无法预估队列长度时,则用链队列

















 2351
2351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









