



基本使用
ChatModel和ChatClient
SpringAi支持非常多的模型,为了统一处理,SpringAi声明了ChatModel接口,各个模型的starter中有ChatModel对应的实现。
当我们引入ollama的依赖后
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
可以在程序中搜索到OllamaChatModel
ChatClient是获取与模型进行对话获取响应的入口,需要给ChatClient提供ChatModel,ChatClient也是一个接口,不过SpringAi提供了默认的实现。
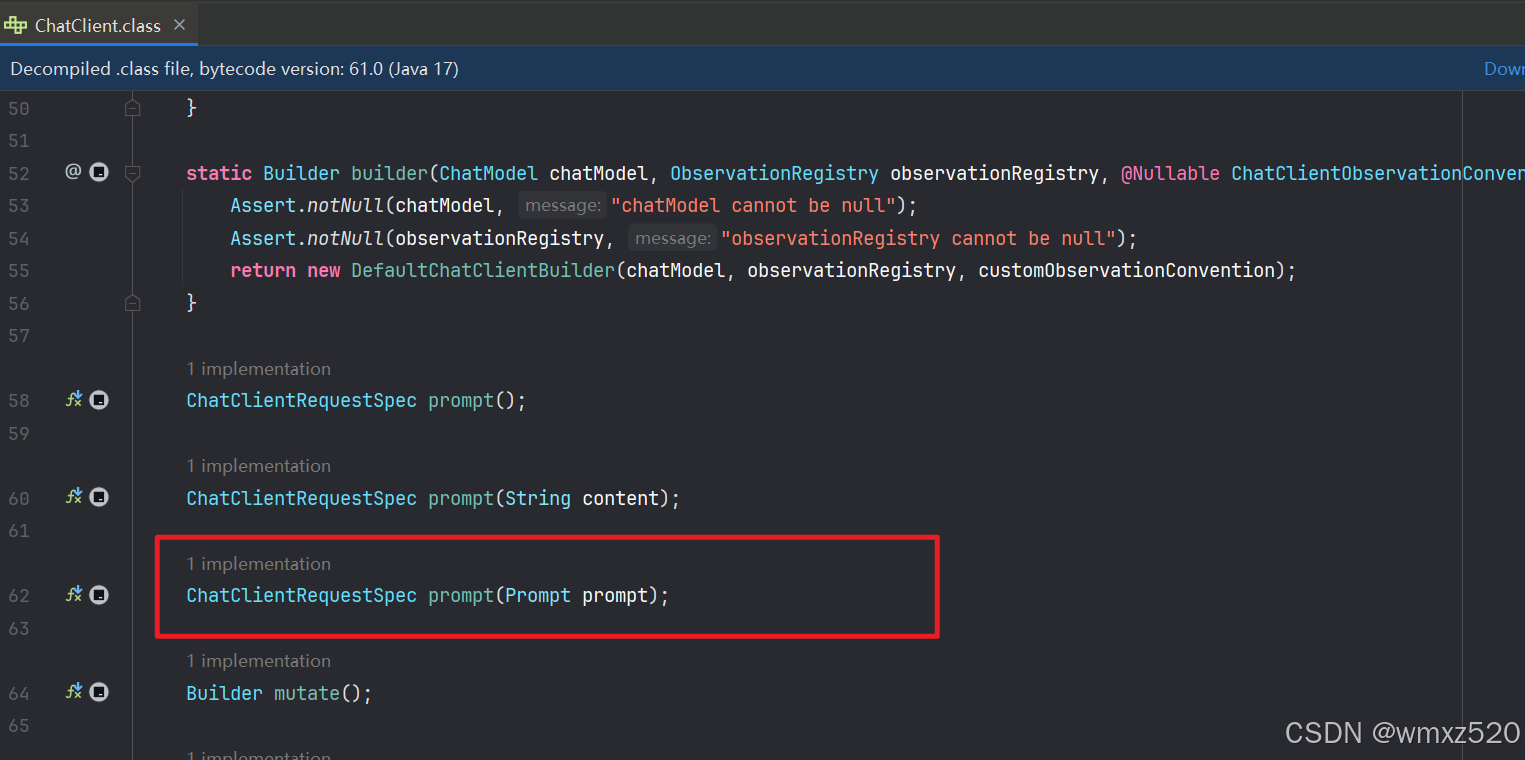
简单对话
这里调用的是本地的ollama中的模型,需要提前下载对应的模型。当然也可以通过api key调用远程的模型服务。
1、引入ollama starter依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
2、配置
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
model: deepseek-r1:14b
3、创建ChatClient
@Configuration
public class MyAiConfig {
@Bean
public ChatClient chatClient(ChatModel chatModel) {
return ChatClient.builder(chatModel).build();
}
}
4、对话controller编写
@RestController
@RequestMapping("/ai-chat")
public class ChatController {
@Autowired
private ChatClient chatClient;
@GetMapping("/chat1")
public String chat(@RequestParam String message) {
return chatClient.prompt(message).call().content();
}
}
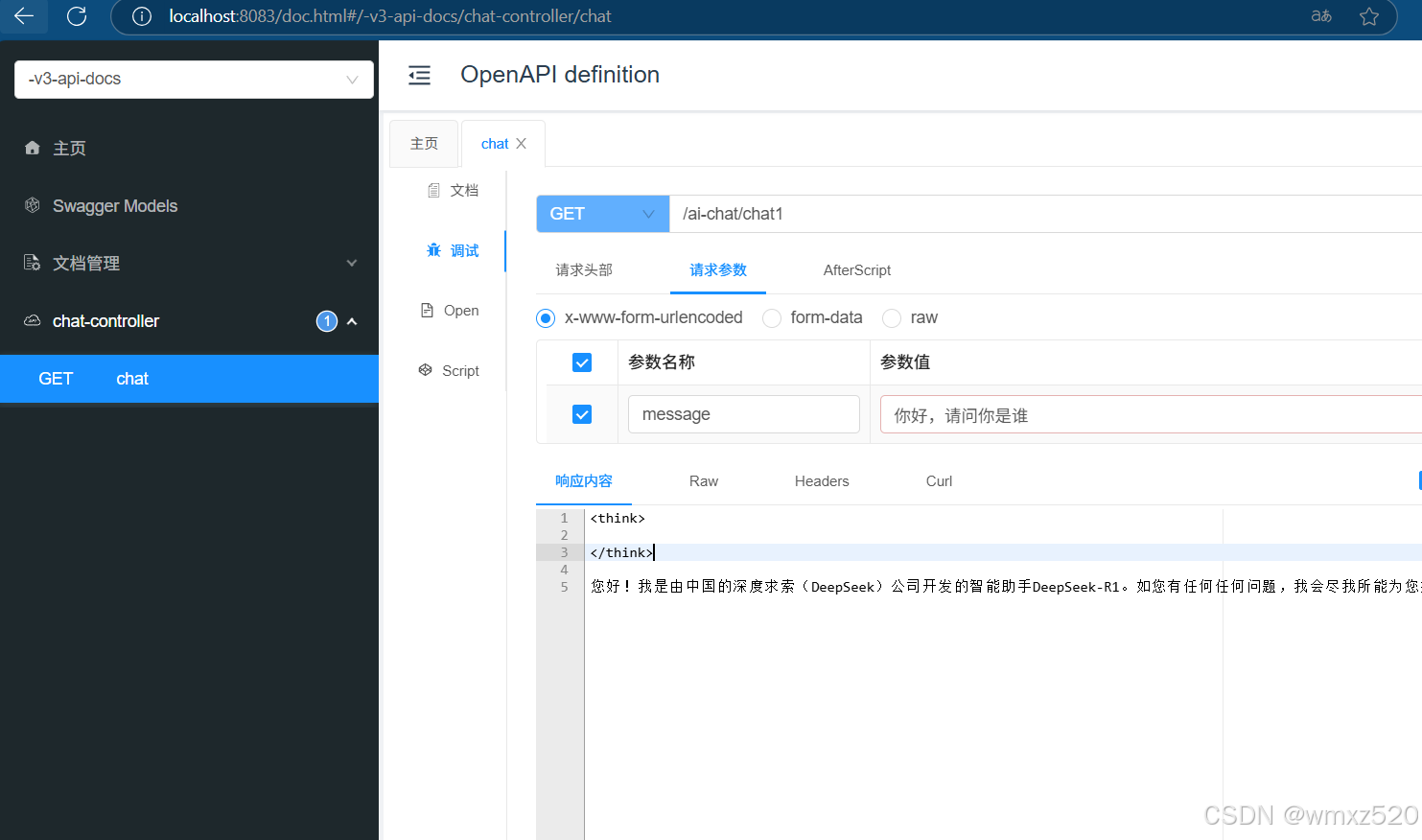
5、测试结果,可以看到模型输出了响应。
流式输出
由于大模型生成响应可能比较慢,为了提高用户体验,所以出现了流式输出,即不等待大模型回答完成后,把输出一次性传输到客户端,而是将输出不断地传输到客户端。
@GetMapping("/chat2")
public Flux<String> chat1(@RequestParam String message) {
return chatClient.prompt().user(message).stream().content();
}
预设角色
在创建ChatClient的时候,可以给模型设置角色,这样模型会按照设置的角色来回答问题。
通过defaultSystem方法预设角色。
@Bean
public ChatClient chatClient(ChatModel chatModel) {
return ChatClient.builder(chatModel).defaultSystem("你是一名医生,擅长诊断病情并提供对应的治疗方案").build();
}
prompt(提示词)
SpringAi中主要有以下几类提示词模板:
- PromptTemplate:通用的提示词模板类,用于构建包含占位符的提示语句;适用于需要动态替换变量的任意提示内容;
- AssistantPromptTemplate:专门用于生成模型助手角色的提示词模板,当需要定义 AI 助手的行为或初始指令时使用;
- FunctionPromptTemplate:用于生成与函数调用相关的提示词模板;当需要模型根据特定函数描述进行推理或调用时使用;
- SystemPromptTemplate:用于生成系统级别的提示词模板,通常用于设置模型的整体行为;用于生成系统级别的提示词模板,通常用于设置模型的整体行为;
示例
通过@Value注解加载提示词模板
@Value("classpath:/my-prompt-template.st")
private Resource systemResource;
@GetMapping("/chat4")
public String chat4(@RequestParam String message) {
SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemResource);
Prompt prompt = systemPromptTemplate.create();
return chatClient.prompt(prompt).user(message).call().content();
}
提示词模板内容
你是我的好朋友,请用东北话回答问题,回答问题的时候适当添加表情符号。
今天是 {{current_date}}。
输出:
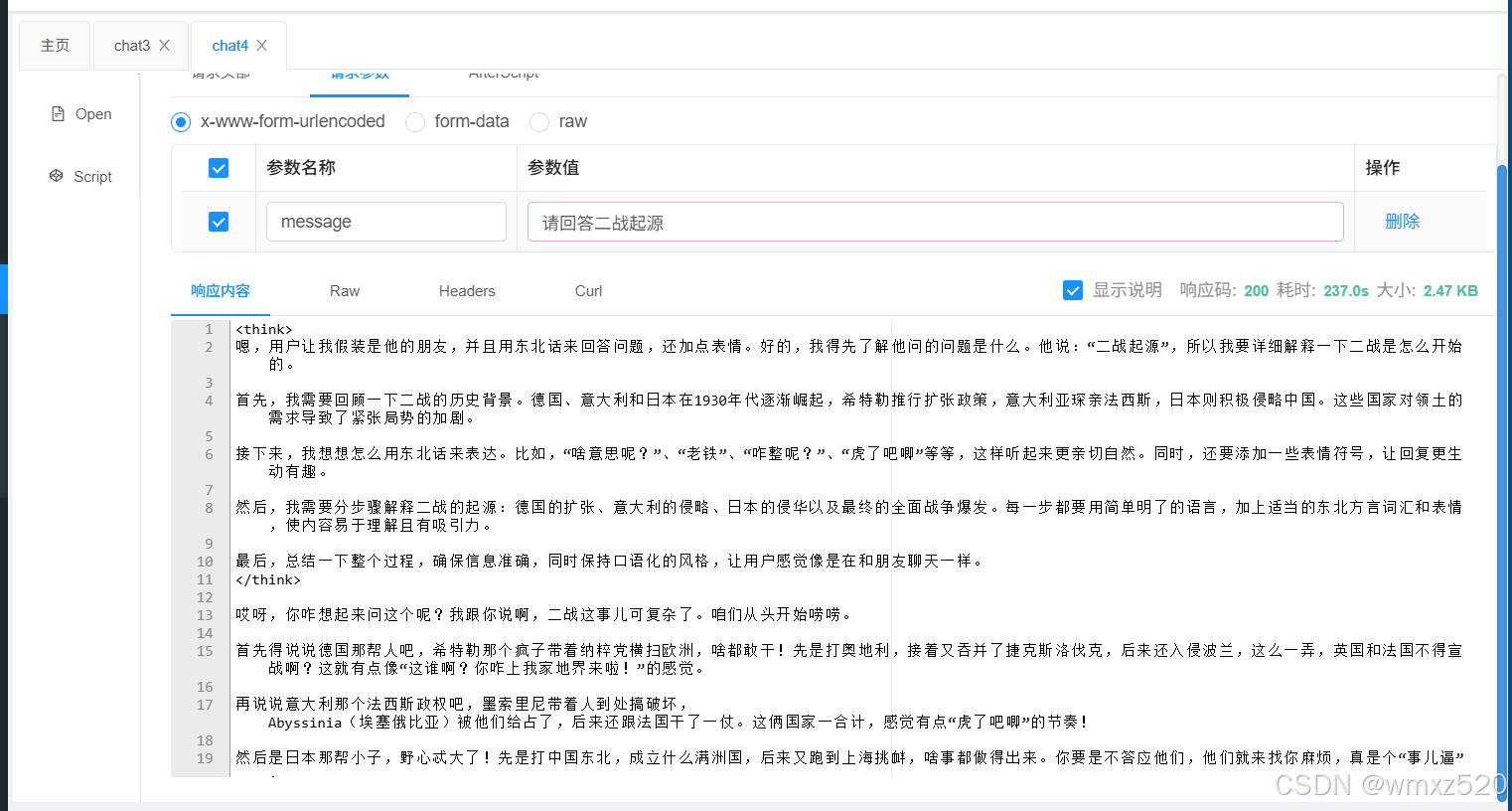
function call(工具调用)
使用@Tool注解定义工具
public class DateTimeUtil {
/**
* @Tool注解:
* 1、name:工具的名称。如果未提供,则将使用方法名称。AI 模型在调用工具时使用此名称来识别工具。因此,不允许在同一个类中有两个同名的工具
* 2、returnDirect:工具结果是应直接返回给客户端还是传递回模型
* 3、description:工具的描述,模型可以使用它来了解何时以及如何调用工具
* @return
*/
@Tool(name = "",
description = "Get the current date and time in the user's timezone")
public String getCurrentTime() {
return LocalDateTime.now().atZone(LocaleContextHolder.getTimeZone().toZoneId()).toString();
}
/**
* @ToolParam注解:
* 1、required:参数是必需的还是可选的。默认情况下,所有参数都被视为必需参数
* 2、description:description:参数的描述,模型可以使用该描述来更好地了解如何使用它
* @param time
*/
@Tool(name = "setAlarm", description = "Set a user alarm for the given time")
void setAlarm(@ToolParam(description = "Time in ISO-8601 format") String time) {
LocalDateTime alarmTime = LocalDateTime.parse(time, DateTimeFormatter.ISO_DATE_TIME);
System.out.println("Alarm set for " + alarmTime);
}
}
通过tools方法添加工具,模型会自动调用工具
chatClient.prompt().tools(new DateTimeUtil()).user(message).call().content();
由于我使用的是本地的deepseek-r1不支持tool,报错了,这里就不放测试结果了。
[400] Bad Request - {"error":"registry.ollama.ai/library/deepseek-r1:14b does not support tools"}


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









