




本系列要对Python在数据处理中经常用的列表(list)、元组(tuple)、字典(dictionary)、array(数组)-numpy、DataFrame-pandas 、集合(set)等数据形式的特征、常用操作进行详述。
前三期的文章分别是:
今天,开启本系列的第四篇文章—Python数据系列(四)- 数组array-NumPy:Python的“运算加速氮气”。
1、概要
Numpy是Python的一个科学计算的库,提供了矩阵运算的功能,其一般与Scipy、matplotlib一起使用。其实,list已经提供了类似于矩阵的表示形式,不过numpy为我们提供了更多的函数。
NumPy数组是一个多维数组对象,称为ndarray,有以下特点:
- 数组的下标从0开始
- 同一个NumPy数组中所有元素的类型必须是相同的。
python中的list是python的内置数据类型,list中的数据类不必相同的,而array的中的类型必须全部相同。
在list中的数据类型保存的是数据的存放的地址,简单的说就是指针,并非数据,这样保存一个list就太麻烦了,例如list1=[1,2,3,‘a’]需要4个指针和四个数据,增加了存储和消耗cpu。
numpy中封装的array有很强大的功能,里面存放的都是相同的数据类型。
2、数组array的特点
- array 必须有相同数据类型属性 , list可以是多种数据类型的混合
- array特有的一些数据处理函数
- array数组可以是多维的
下面展示了数组的创建过程
In [1]: import numpy as np
In [2]: np.array([1,2,3,4])
Out[2]: array([1, 2, 3, 4])
In [3]: b=np.array([(1.5,2,3),])
In [4]: b=np.array([(1.5,2,3),(4,5,6)])
In [5]: b
Out[5]:
array([[1.5, 2. , 3. ],
[4. , 5. , 6. ]])
In [6]: c=array([(1.5,2,3),(4,5,6)])
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-6-9672fbd6917d> in <module>()
----> 1 c=array([(1.5,2,3),(4,5,6)])
NameError: name 'array' is not defined
In [7]: b=np.array([(1.5,2,3),(4,5,6)],dtype=int32)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-7-eff6f4bffe85> in <module>()
----> 1 b=np.array([(1.5,2,3),(4,5,6)],dtype=int32)
NameError: name 'int32' is not defined
In [8]: b=np.array([(1.5,2,3),(4,5,6)],dtype=int)
In [9]: b
Out[9]:
array([[1, 2, 3],
[4, 5, 6]])
3、生成均匀分布的array
- arange(最小值,最大值,步长)(左闭右开) : 创建等差数列
- linspace(最小值,最大值,元素数量):创建等差数列
- logspace(开始值, 终值, 元素个数): 创建等比数列
下面依旧演示这块内容,如下:
In [1]: import numpy as np
In [2]: np.array(12)
Out[2]: array(12)
In [3]: np.arange(12)
Out[3]: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
In [4]: np.arange(12).reshape(3,4)
Out[4]:
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
In [5]: np.arange(3,12)
Out[5]: array([ 3, 4, 5, 6, 7, 8, 9, 10, 11])
In [6]: np.arange(3,12,2)
Out[6]: array([ 3, 5, 7, 9, 11])
In [8]: np.linspace(6,12,5)
Out[8]: array([ 6. , 7.5, 9. , 10.5, 12. ])
In [10]: np.logspace(0,27,3)
Out[10]: array([1.00000000e+00, 3.16227766e+13, 1.00000000e+27])
In [12]: np.logspace(0,9,10)
Out[12]:
array([1.e+00, 1.e+01, 1.e+02, 1.e+03, 1.e+04, 1.e+05, 1.e+06, 1.e+07,
1.e+08, 1.e+09])
以上例子的起始位和终止位都是0,元素个数是10,但是生成的等比数列全部是1,这是因为在logspace中,起始位和终止位代表的是10的幂(默认基数为10),0代表10的0次方,9代表10的9次方
4、生成特殊数组
- np.ones: 创建一个数组, 其中的元素全为 1
- np.zeros: 创建元素全为 0 的数组, 类似 np.ones
- np.empty创建一个内容随机并且依赖与内存状态的数组。
- np.eye: 创建一个对角线为 1 其他为 0 的 NxN 的单位矩阵.
- np.identity: 创建一个主对角线为 1 其他为 0 的方阵.
下面依旧演示这块内容,如下:
In [1]: import numpy as np
In [2]: np.zeros((3,4))
Out[2]:
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
In [3]: np.ones((3,4))
Out[3]:
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
In [4]: np.eye((3,4))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-c9b076fe3a4b> in <module>()
----> 1 np.eye((3,4))
C:\Users\Administrator\Anaconda3\lib\site-packages\numpy\lib\twodim_base.py in e
ye(N, M, k, dtype, order)
199 if M is None:
200 M = N
--> 201 m = zeros((N, M), dtype=dtype, order=order)
202 if k >= M:
203 return m
TypeError: 'tuple' object cannot be interpreted as an integer
In [5]: np.eye(3)
Out[5]:
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
In [6]: np.identity(3)
Out[6]:
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
PS,此时是不是发现,np.identity 和np.eye的似乎没什么区别,输出结果一样,我们看下这两个的源码,就发现还是不一样的
# eye()
@set_module('numpy')
def eye(N, M=None, k=0, dtype=float, order='C'):
"""
Return a 2-D array with ones on the diagonal and zeros elsewhere.
"""
......
return m
# identity()
@set_module('numpy')
def identity(n, dtype=None):
"""
Return the identity array
"""
......
from numpy import eye
return eye(n, dtype=dtype)
区别很明显,函数 eye 和 indetity 都经过 set_module 装饰器装饰,而函数 identity 的返回值是经过 eye() 处理后返回的。并且eye的输入参数明显要比identity丰富。
eye(N, M=None, k=0, dtype=float, order='C') 参数介绍:
(1)N:int型,表示的是输出的行数
(2)M:int型,可选项,输出的列数,如果没有就默认为N
(3)k:int型,可选项,对角线的下标,默认为0表示的是主对角线,负数表示的是低对角,正数表示的是高对角。
(4)dtype:数据的类型,可选项,返回的数据的数据类型
(5)order:{‘C’,‘F'},可选项,也就是输出的数组的形式是按照C语言的行优先’C',还是按照Fortran形式的列优先‘F'存储在内存中
In [7]: np.eye(4)
Out[7]:
array([[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.]])
In [8]: np.eye(4,k=1) # k的使用规则在下图
Out[8]:
array([[0., 1., 0., 0.],
[0., 0., 1., 0.],
[0., 0., 0., 1.],
[0., 0., 0., 0.]])
In [9]: np.eye(4,k=-1)
Out[9]:
array([[0., 0., 0., 0.],
[1., 0., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.]])
In [10]: np.eye(4,k=-3)
Out[10]:
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[1., 0., 0., 0.]])
In [11]: np.eye(4,3)
Out[11]:
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.],
[0., 0., 0.]])
这个函数和之前的区别在于,这个只能创建方阵,也就是N=M
函数的原型:np.identity(n,dtype=None)
参数:n,int型表示的是输出的矩阵的行数和列数都是n
dtype:表示的是输出的类型,默认是float
返回的是nxn的主对角线为1,其余地方为0的数组案例
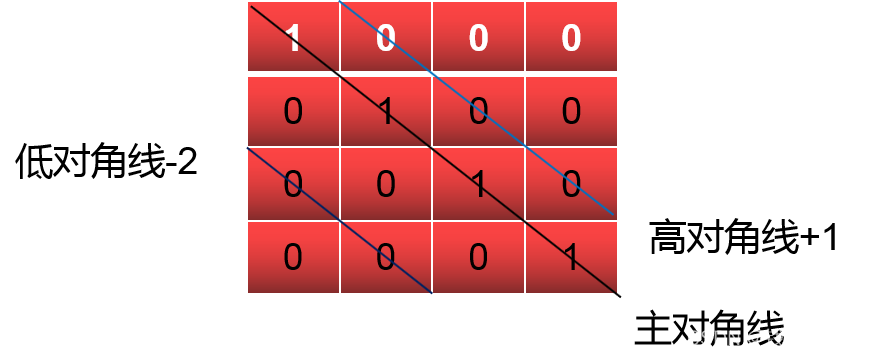
5、数组array的属性,数组索引,切片,赋值
In [1]: import numpy as np
In [2]: a=np.zeros((2,2,2))
In [3]: a
Out[3]:
array([[[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.]]])
In [4]: a.ndim
Out[4]: 3
In [5]: a.shape
Out[5]: (2, 2, 2)
In [6]: a.size
Out[6]: 8
In [7]: a.dtype
Out[7]: dtype('float64')
In [8]: a.itemsize
Out[8]: 8
In [9]: b=np.array([[1,2,3],[4,5,6]])
In [10]: b
Out[10]:
array([[1, 2, 3],
[4, 5, 6]])
In [11]: b[1,2] # 取第1行第2列的值(先行,后列)
Out[11]: 6
In [12]: b[1,:] # 取第1行的所有值
Out[12]: array([4, 5, 6])
In [13]: b[1,1:2] # 取第1行,第1:2列的值
Out[13]: array([5])
In [14]: b[1,:]=[7,8,9] # [7,8,9]赋值给第1行
In [15]: b
Out[15]:
array([[1, 2, 3],
[7, 8, 9]])
6、数组其他操作
In [2]: import numpy as np
In [3]: a=np.ones((2,3))
In [4]: b=np.eye(2)
In [5]: a=np.ones((2,2))
In [6]: a
Out[6]:
array([[1., 1.],
[1., 1.]])
In [7]: b
Out[7]:
array([[1., 0.],
[0., 1.]])
In [8]: a>=1 # 所有元素判断
Out[8]:
array([[ True, True],
[ True, True]])
In [9]: a+b # 数组对应求和
Out[9]:
array([[2., 1.],
[1., 2.]])
In [10]: a*b # 数组对应乘积(叉乘)
Out[10]:
array([[1., 0.],
[0., 1.]])
In [11]: a*2 # 数组对应位置*2
Out[11]:
array([[2., 2.],
[2., 2.]])
In [12]: a.dot(b) # 矩阵点乘(矩阵乘法)
Out[12]:
array([[1., 1.],
[1., 1.]])
In [13]: (a*2)**2 # a先乘2,在求对应位置平方
Out[13]:
array([[4., 4.],
[4., 4.]])
In [14]: a.sum() # 元素求和
Out[14]: 4.0
In [15]: a
Out[15]:
array([[1., 1.],
[1., 1.]])
In [16]: a.sum(axis=0) # axis=0按列元素求和,axis=1按行元素求和
Out[16]: array([2., 2.])
In [18]: a.min()
Out[18]: 1.0
In [19]: np.sin(a)
Out[19]:
array([[0.84147098, 0.84147098],
[0.84147098, 0.84147098]])
In [21]: np.floor(a)
Out[21]:
array([[1., 1.],
[1., 1.]])
In [22]: a
Out[22]:
array([[1., 1.],
[1., 1.]])
In [23]: np.int(a)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-23-0442803185fd> in <module>()
----> 1 np.int(a)
TypeError: only size-1 arrays can be converted to Python scalars
In [24]: np.exp(a) # e^a
Out[24]:
array([[2.71828183, 2.71828183],
[2.71828183, 2.71828183]])
In [25]: a
Out[25]:
array([[1., 1.],
[1., 1.]])
In [26]: np.vstack((a,b)) # 按行合并数组
Out[26]:
array([[1., 1.],
[1., 1.],
[1., 0.],
[0., 1.]])
In [27]: np.hstack((a,b)) # 按列合并数组
Out[27]:
array([[1., 1., 1., 0.],
[1., 1., 0., 1.]])
In [30]: np.hstack((a,b)).transpose() # 转置
Out[30]:
array([[1., 1.],
[1., 1.],
[1., 0.],
[0., 1.]])
7、数组运算
计算两个数组相同元素的数量
In [26]: a
Out[26]: array([1, 0, 1, 0])
In [27]: b
Out[27]: array([0, 0, 1, 0])
In [28]: c_bool = c==0
In [29]: c_bool
Out[29]: array([False, True, True, True])
In [30]: c_bool.sum()
Out[30]: 3
8、总结
NumPy和Pandas是Python在数据科学分析领域中最为常用的数据处理库,因为其底层是由C语言编写的,所以相比于Python运算慢的问题,NumPy能够为Python的数据处理插上翅膀,运算速度提升10倍,或100倍的量级。
补充
1、numpy.array和numpy.asarray的区别
numpy.array(object, dtype=None)
作用是将输入转换为数组
参数:
- object:创建的数组的对象,可以为单个值,列表,元胞等。
- dtype:创建数组中的数据类型。
- 返回值:给定对象的数组。
numpy.asarray(a, dtype=None, order=None)
作用是将输入转换为数组
参数:
- a:输入数据,可以转换为数组的任何形式。这包括列表,元组列表,元组,列表元组和ndarray。
- dtype:默认情况下,从输入数据中推断出数据类型
- order:是使用行优先(C风格)还是列优先(Fortran风格)内存表示形式。默认为“ C”。
- 返回:
– 如果输入已经是具有匹配dtype和order的ndarray,则不执行复制。
– 如果a是ndarray的子类,则返回基类ndarray。
np.array和np.asarray区别:
- array和asarray都可将结构数据转换为ndarray类型
- 但是主要区别就是当数据源是ndarray时,array仍会copy出一个副本,占用新的内存,但asarray不会。
之后如果小伙伴需要对Python中的数据包进行介绍介绍,希望再开通一个对数据包的介绍的专栏。本系列下一篇文章,我们探讨一下字符串string,这是一个最最最常见的数据形式。



















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











