




C语⾔有九种控制语句可分为以下三类:
一. 条件判断语句也叫分⽀语句:if语句、switch语句;
1. if语句
if 语句的语法形式如下:
if ( 表达式)
语句
表达式成⽴(为真),则语句执⾏,表达式不成⽴(为假),则语句不执⾏
在C语⾔中,0为假,⾮0表⽰真,也就是表达式的结果如果是0,则语句不执⾏,表达式的结果如果不
是0,则语句执⾏
2.if...else... 语句
if ( 表达式 )
语句
else
语句
3.嵌套if
#include <stdio.h>
int main()
{
int num = 0;
scanf("%d", &num);
if(num > 0)
{
if(num%2== 0)
printf("偶数\n");
else
printf( "奇数\n" );
}
else
printf("⾮正数\n");
}
return 0;
}
记住这样⼀条规则, else 总是跟最接近的 if 匹配
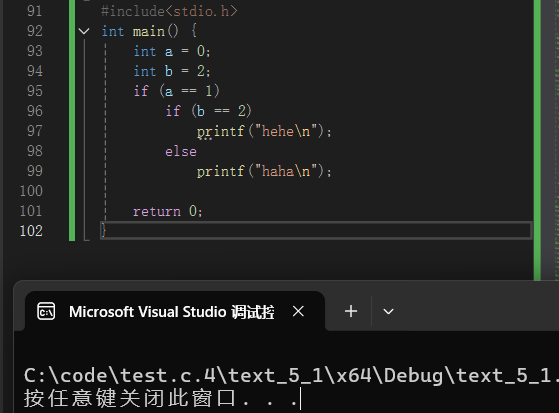
什么也不输出,这就是悬空 else 的问题,如果有多个 的 if 匹配。 可以记住这样⼀条规则, else 总是跟最接近 if匹配的,if else是一条语句
4.switch 语句
switch 语句是⼀种特殊形式的 if...else 结构,⽤于判断条件有多个结果的情况。它把多重的 else if 改成更易⽤、可读性更好的形式
#include <stdio.h>
int main()
{
int n = 0;
scanf("%d", &n);
switch(n % 3){
case 0:printf("整除,余数为0\n");
case 1: printf("余数是1\n");
case 2: printf("余数是2\n");
}
return 0;
}
注意:
1. case 和后边的数字之间必须有空格
2. 每⼀个 case 语句中的代码执⾏完成后,需要加上 break ,才能跳出这个 switch 语句。
switch 后面必须是整型表达式
case 后的值,必须是整形常量表达式
switch语句中的default:前面的case子句都不执行时执行default
switch语句中的case和default的顺序问题
在 switch 语句中 case ⼦句和 default ⼦句有要求顺序吗? default 只能放在最后吗?其实,在 switch 语句中 case 语句和 default 语句是没有顺序要求的,只要你的顺序是满⾜实际需求的就可以。 不过我们通常是把 default ⼦句放在最后处理的。
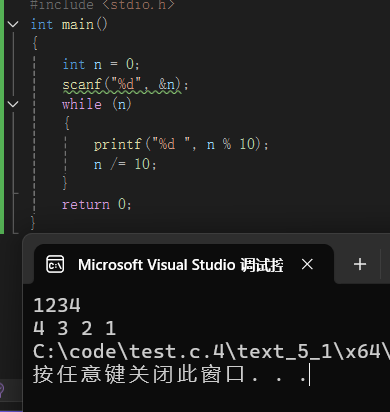
二. 循环执⾏语句:do while语句、while语句、for语句;
while循环(先判断再执行)
for循环(先判断再执行)
for(表达式1; 表达式2; 表达式3);
语句;//如果循环体想包含更多的语句,可以加上⼤括号
表达式2⽤于循环结束条件的判断
表达式3⽤于循环变量的调整
do-while 循环(先执行再判断)
do
语句;
while(表达式);
循环的嵌套
例:找出100~200之间的素数,并打印在屏幕上
#include<stdio.h>
#include<math.h>
int main() {
int i = 0;
bool temp;
for (i = 101;i < 200;i += 2) {
temp = true;
for (int j = 2;j < sqrt(i);j++) {
if (i % j == 0) {
temp = false;
break;
}
}
if (temp == true)
printf("%d ", i);
}
printf("\n");
return 0;
}
三. 转向语句:break语句、goto语句、continue语句、return语句
• break 的作⽤是⽤于永久的终⽌循环,只要 break 被执⾏,直接就会跳出循环,继续往后执 ⾏。 • continue 的作⽤是跳过本次循环中continue 后边的代码,在 for 循环和 while 循环中有 所差异的。
goto语句
for(...)
{
for(...)
{
for(...)
{
if(disaster)
goto error;
}
}
}
error:
//...
goto 语句如果使⽤的不当,就会导致在函数内部随意乱跳转,打乱程序的执⾏流程,所以我们的建 议是能不⽤尽量不去使⽤。

















 1186
1186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









