




 本文介绍了Redis的相关知识,包括5种数据类型、持久化机制(RDB和AOF)、事务处理、内存管理与数据淘汰机制、集群(主从复制和哨兵),还阐述了何时选择RDB或AOF,以及Redis事务回滚情况,最后说明了其适用于读多写少场景,如数据缓存、单点登录等。
本文介绍了Redis的相关知识,包括5种数据类型、持久化机制(RDB和AOF)、事务处理、内存管理与数据淘汰机制、集群(主从复制和哨兵),还阐述了何时选择RDB或AOF,以及Redis事务回滚情况,最后说明了其适用于读多写少场景,如数据缓存、单点登录等。
1. 5种数据类型
| 属性 | string | list | hash | set | zset |
| 特点 | 存放基础数据类型的数据,最多存512MB数据 | 有序可重复 | 键值对 | 无序不可重复 | 有序不可重复 |
| 内部编码(默认) | 1. Int:8个字节的长整型 2. Embstr:小于39个字节的字符串 3. Raw:大于39个字节的字符串 | 1. ziplist(压缩列表):元素个数小于512个且每个元素的值小于64字节,省内存,实现多个元素的连续存储 2. linkedList(链表):不满足1条件 | 1.ziplist(压缩列表):元素个数小于512个且每个元素的值小于64字节,省内存,实现多个元素的连续存储 2. hashtable(哈希表): 不满足1条件读写效率下降,复杂度为o(1) | 1.intset(整数集合):元素都是整数且元素个数小于512个省内存 2. hashtable(哈希表):不满足1条件 | 1.ziplist(压缩列表):元素个数小于128个且元素值都小于64字节 skiplist(跳跃表):不满足1条件 |
| 典型使用场景 | 1.缓存 2.session共享 3.计数 4.限速(接口访问次数) | 1.消息队列 | 存放的是对象 | 1.存标签,得共同爱好(取交集) | 1.排行榜 |
2. 持久化机制
即将内存中的数据保存到磁盘,以防因进程退出而导致内存数据的丢失
2.1 RDB
2.1.1 触发时间
- 手动执行
- 自动触发:m秒内进行了n此修改,触发bgsave
- 从节点执行全量复制,触发bgsave
- 执行debug reload,触发save
- shutdown且没有开启AOF,触发bgsave
2.1.2 触发RDB过程
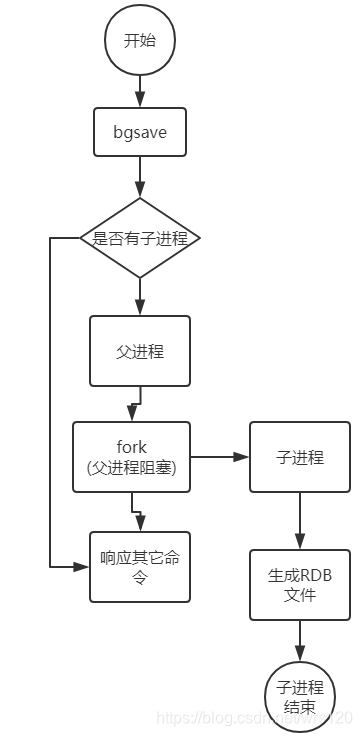
2.1.3 优点
- RDB是一个紧凑的二进制压缩文件,适用于全量复制,备份等
- redis加载RDB 远远快于 AOF
2.1.4缺点
- 无法实时保存
2.2 AOF
2.2.1 触发时间
每输入一条命令,都会先写入aof_buf中,然后根据配置的不同策略同步到磁盘
2.2.2 触发AOF的过程
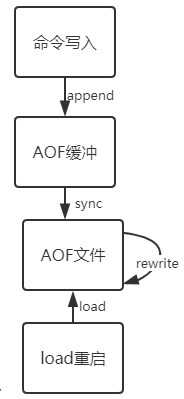
2.2.3 文件同步sync的3种方式
- always: 命令写入aof_buf后调用系统fsync操作同步到AOF文件,完成后线程返回(有阻塞)
- ererysec: 命令写入aof_buf后调用write,write完成线程返回。fsync有专门线程负责每秒同步一次文件(不阻塞)
- no: 命令写入aof_buf后调用write,write完成线程返回,不对AOF文件同步,同步由操作系统负责,通常周期最长30秒(不阻塞)
write操作会触发延迟写delayed write机制(同步之前宕机,缓冲数据将丢失),fsync强制同步磁盘针对单个文件,会阻塞直到写入磁盘完成后返回
2.2.4 重写机制

注:fork在RDB中出现在bgsave过程,而在AOF中出现在重写过程
2.2.5 优点
- 实时备份
2.2.6 缺点
- 恢复时不如RDB加载快
2.3 选择RDB还是AOF
- 允许某段时间内数据丢失,则选择RDB
- 数据的绝对安全,可以选择RDB+AOF
3.事务处理
3.1 MULTI
用于标记事务块的开始。Redis会将后续的命令逐个放入队列中,然后才能使用EXEC命令原子化地执行这个命令序列
3.2 EXEC
在一个事务中执行所有放入队列的命令,然后恢复正常的连接状态.其中当使用WATCH命令时,只有当受监控的键没有被修改时,EXEC命令才会执行事务中的命令,这种方式利用了检查再设置(CAS)乐观锁的机制。返回值是一个数组,其中的每个元素分别是原子化事务中的每个命令的返回值。 当使用WATCH命令时,如果事务执行中止,那么EXEC命令就会返回一个Null值
3.3 DISCARD
清除所有先前在一个事务中放入队列的命令,然后恢复正常的连接状态。若使用了WATCH命令,那么DISCARD命令就会将当前连接监控的所有键取消监控
3.4 WATCH
当某个事务需要按条件执行时,就要使用这个命令将给定的键设置为受监控的
3.5 UNWATCH
清除所有先前为一个事务监控的键
3.6 什么时候回滚,什么时候不回滚
回滚: 调用EXEC命令之前发生的错误会回滚,比如 语法有错误
不回滚: 调用EXEC命令之后发生的错误会回滚,比如命令格式没有错误但是内部值的类型不匹配,比如给一个string类型数据进行incr操作
3.7 redis为什么不支持回滚
在事务运行期间,虽然Redis命令可能会执行失败,但是Redis仍然会执行事务中余下的其他命令,而不会执行回滚操作,你可能会觉得这种行为很奇怪。然而,这种行为也有其合理之处:只有当被调用的Redis命令有语法错误时,这条命令才会执行失败(在将这个命令放入事务队列期间,Redis能够发现此类问题),或者对某个键执行不符合其数据类型的操作:实际上,这就意味着只有程序错误才会导致Redis命令执行失败,这种错误很有可能在程序开发期间发现,一般很少在生产环境发现。 Redis已经在系统内部进行功能简化,这样可以确保更快的运行速度,因为Redis不需要事务回滚的能力。对于Redis事务的这种行为,有一个普遍的反对观点,那就是程序有可能会有缺陷(bug)。但是,你应当注意到:事务回滚并不能解决任何程序错误。例如,如果某个查询会将一个键的值递增2,而不是1,或者递增错误的键,那么事务回滚机制是没有办法解决这些程序问题的。请注意,没有人能解决程序员自己的错误,这种错误可能会导致Redis命令执行失败。正因为这些程序错误不大可能会进入生产环境,所以我们在开发Redis时选用更加简单和快速的方法,没有实现错误回滚的功能(来自网络)
4.内存管理与数据淘汰机制
4.1 最大内存设置
最大内存设置,默认情况下,在32位OS中,Redis最大使用3GB的内存,在64位OS中则没有限制。
在使用Redis时,应该对数据占用的最大空间有一个基本准确的预估,并为Redis设定最大使用的内存。否则在64位OS中Redis会无限制地占用内存(当物理内存被占满后会使用swap空间),容易引发各种各样的问题。
在内存占用达到了maxmemory后,再向Redis写入数据时,Redis会:
- 根据配置的数据淘汰策略尝试淘汰数据,释放空间
- 如果没有数据可以淘汰,或者没有配置数据淘汰策略,那么Redis会对所有写请求返回错误,但读请求仍然可以正常执行
在为Redis设置maxmemory时,需要注意:如果采用了Redis的主从同步,主节点向从节点同步数据时,会占用掉一部分内存空间,如果maxmemory过于接近主机的可用内存,导致数据同步时内存不足。所以设置的maxmemory不要过于接近主机可用的内存,留出一部分预留用作主从同步。
4.2 数据淘汰机制
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略(回收策略)。redis 提供 6种数据淘汰策略:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
5. 集群
5.1 主从复制
存在的最大问题就是不能实现高可用:当主节点出现故障时,从节点不能自动晋升为主节点,主要手动修改
5.2 哨兵
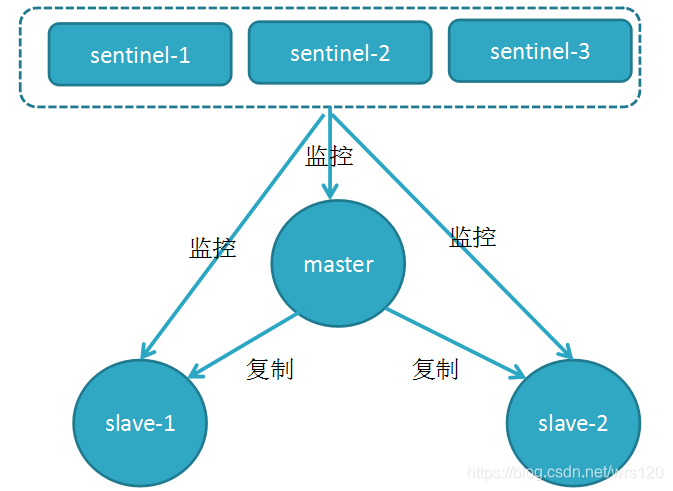
5.2.1 redis sentinel客户端连实现原理
- 遍历Sentinel节点集合获取一个可用的Sentinel节点,后面会介绍Sentinel节点之间可以共享数据, 所以从任意一个Sentinel节点获取主节点信息都是可以的

- 通过sentinel get-master-addr-by-name master-name这个API来获取对应主节点的相关信息
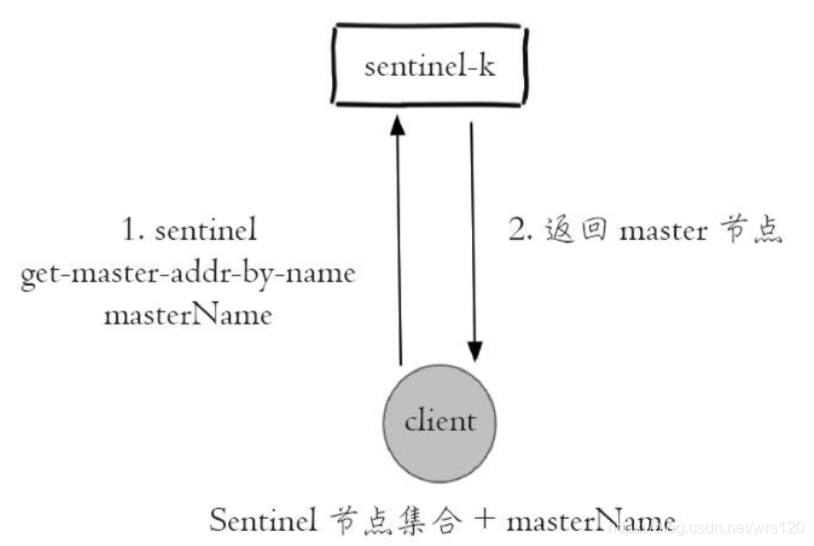
- 验证当前获取的“主节点”是真正的主节点,这样做的目的是为了防止故障转移期间主节点的变化
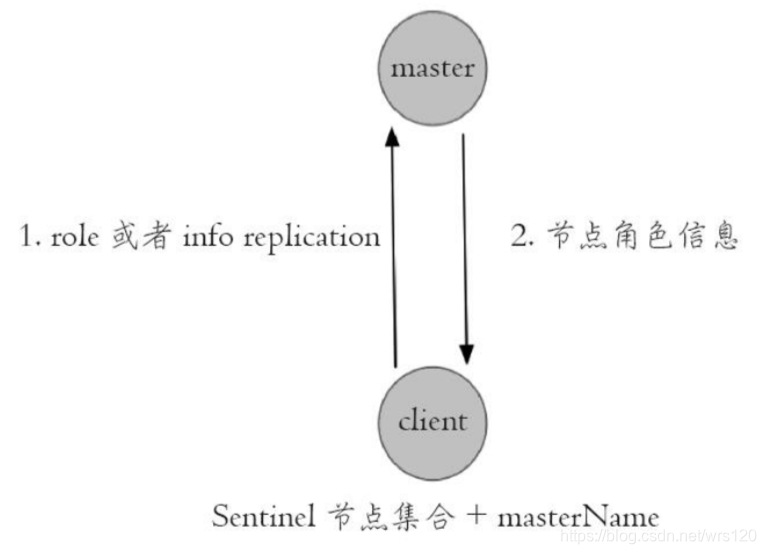
- 保持和Sentinel节点集合的“联系”,时刻获取关于主节点的相关“信息”

从上面的模型可以看出,redis sentinel客户端只有在初始化和切换主节点时需要和sentinel进行通信来获取主节点信息,所以在设计客户端时需要将sentinel节点集合考虑成配置(相关节点信息和变化)发现服务。
5.2.2 实现原理
- 每隔1秒,每个sentinel节点会向主节点,从节点,其余sentinel节点发送ping命令做一次心跳检查机制,判断这些节点是否可达
- 每隔2秒,每个sentinel会向频道发送当前sentinel节点和对主节点的判断,同时其余sentinel会订阅该频道,了解其他sentinel节点(是否有新sentinel节点加入)和它们对主节点的判断(sentinel节点之间交换主节点数据,作为后面客观下线以及领导者选举的依据)
- 每隔10秒,每隔sentinel节点会向从节点和主节点发送info命令获取最新拓扑结构
- 通过info命令,获取从节点信息,这也是为什么sentinel节点不需要显示配置监控节点
- 当有从节点加入时能立刻感知出来
- 节点不可达或故障转以后,可以通过info命令实时更新节点拓扑信息
6. 应用场景
- 数据缓存(商品数据、新闻、热点数据)
- 单点登录
- 秒杀、抢购
- 网站访问排名
总之:rediss适用于读多写少的情况

















 1742
1742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









