




 本文详细介绍了Hadoop高可用(HA)集群的搭建过程,包括原理说明、环境准备、集群规划、Zookeeper集群搭建、Hadoop集群搭建的具体步骤。涵盖Hadoop下载、解压、配置文件调整、环境变量设置、无密登录配置、节点拷贝、集群启动及网页查看等内容。
本文详细介绍了Hadoop高可用(HA)集群的搭建过程,包括原理说明、环境准备、集群规划、Zookeeper集群搭建、Hadoop集群搭建的具体步骤。涵盖Hadoop下载、解压、配置文件调整、环境变量设置、无密登录配置、节点拷贝、集群启动及网页查看等内容。
1. 原理说明
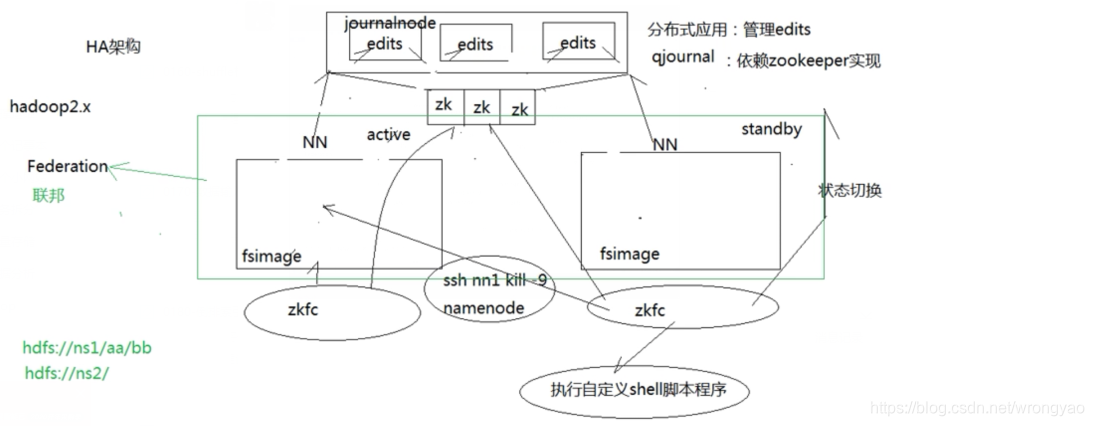 注:
注:
- 不能让两个NN都正常响应请求,某个时间只有一个节点正常响应为Active节点,另外一台为StandBy;
- StandBy无缝切换到Active,意味着两台机的数据需要一致;
- 为了避免brain spilt现象,一发送ssh 指令杀死active进程,另外执行自定义脚本(关电源啥的),这种机制成为fencing机制。
2. 环境准备
根据centos集群搭建配置好集团环境
- 修改Linux主机名
- 修改IP
- 修改主机名和IP的映射关系 /etc/hosts里面要配置的是内网IP地址和主机名的映射关系
- 关闭防火墙
- ssh免密登陆
- 安装JDK,配置环境变量等
3. 集群规划
| 主机名 | 运行进程 |
|---|---|
| centos0010 | NameNode、DFSZKFailoverController(zkfc) |
| centos0020 | NameNode、DFSZKFailoverController(zkfc) |
| centos0030 | ResourceManager |
| centos0040 | ResourceManager |
| centos0050 | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| centos0060 | DataNode、NodeManager、JournalNode、QuorumPeerMain |
| centos0070 | DataNode、NodeManager、JournalNode、QuorumPeerMain |
进程名称说明:
- NameNode - hdfs元素据管理进程
- DFSZKFailoverController - 监控namenode的运行状态进程
- ResourceManager - yarn的主管进程
- DataNode - hdfs的数据管理进程
- NodeManager - yarn的处理进程
- JournalNode - qjournal的进程,处理hdfs的edis文件
- QuorumPeerMain - zookeeper的进程
3. zookeeper集群搭建
4. hadoop集群搭建
4.1 Hadoop下载
4.2 解压
4.3 配置文件
4.3.1 配置环境变量
export JAVA_HOME=/home/rongyao/app/jdk1.8.0_201
export JRE_HOME=/home/rongyao/app/jdk1.8.0_201/jre
export HADOOP_HOME=/home/rongyao/app/hadoop-3.2.0
export IDEA_HOME=/home/rongyao/app/idea-IC-193.6015.39
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$IDEA_HOME/bin:$PATH
下面的文件配置,在centos0010先配置好,发到其它的主机即可,所有的配置文件都在hadoop-3.2.0/etc/hadoop下
4.3.2 hadoo-env.sh配置
配置JAVA_HOME
JAVA_HOME=/home/rongyao/app/jdk1.8.0_201
4.3.3 core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1/</value>
</property>
<!-- 指定hadoop工作数据目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/rongyao/app/hadoop-3.2.0/data</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>centos0050:2181,centos0060:2181,centos0070:2181</value>
</property>
</configuration>
4.3.4 hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>centos0010:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>centos0010:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>centos0020:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>centos0020:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://centos0050:8485;centos0060:8485;centos0070:8485/ns1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/rongyao/app/hadoop-3.2.0/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/rongyao/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
4.3.5 mapred-site.xml
<configuration>
<!--指定map-reduce的资源调度集群-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
4.3.6 yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>centos0030</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>centos0040</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>centos0050:2181,centos0060:2181,centos0070:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>centos0030:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>centos0030:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>centos0030:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>centos0030:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>centos0030:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>centos0030:23142</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>centos0040:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>centos0040:8030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>centos0040:8088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>centos0040:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>centos0040:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>centos0040:23142</value>
</property>
</configuration>
4.3.7 workers
works文件是datanode的节点所在位置,也是nodemanager节点所在位置,这边恰巧datanode和nodemanager节点都在centos0050、60、70三台主机上所以workers文件统一配置即可,否者需要在centos0010、20指定datanode节点,30、40执行nodemanager节点
centos0050
centos0060
centos0070
4.4 无密登录
- centos0010到centos0020,centos0030,centos0040,centos0050,centos0060,centos0070的无密登录
- centos0030到centos0030,centos0040,centos0050,centos0060,centos0070的无密登录
配置流程参考centos集群搭建
4.5 拷贝节点
将在centos0010配置好的节点拷贝到其它主机上
scp -r hadoop-3.2.0/ centos20:/home/rongyao/app/
4.6 启动集群
4.6.1 启动zookeeper集群
在centon0050、60、70三台机上启动好zookeeper集群
4.6.2 格式化hdfs
在centos0010上执行
hdfs namenode -format
格式化以后会在core-site.xml中的/home/rongyao/app/hadoop-3.2.0/data配置目录,生成namenode的文件(fsimage),要想保持两台namenode数据一致,需要将初始数据从centos0010拷贝到centos0020;
# 方式一:直接拷贝 centos0010上执行
[rongyao@centos0010 data]$ clear
[rongyao@centos0010 data]$ pwd
/home/rongyao/app/hadoop-3.2.0/data
[rongyao@centos0010 data]$ ls
dfs
[rongyao@centos0010 data]$ scp -r dfs/ centos0020:/home/rongyao/app/hadoop-3.2.0/data/
# 方式二:centos0020上执行(也是拷贝)
hdfs namenode -bootstrapStandby
4.6.3 格式化zkfc
在centos0010上执行
hdfs zkfc -formatZK
在zookeeper上建好一些数据 在zookeeper的根目录下建立/hadoop-ha
4.6.4 启动hdfs集群
在centos0010执行
start-dfs.sh
4.6.5 启动yarn集群
start-yarn.sh
4.7 网页查看
4.7.1 hdfs
http://centos0010:50070
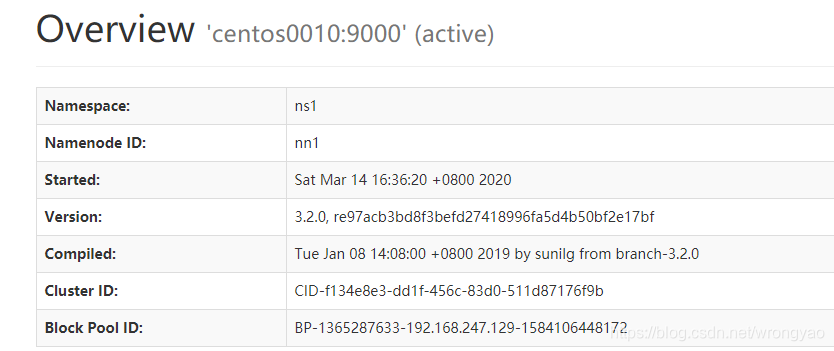
http://centos0020:50070
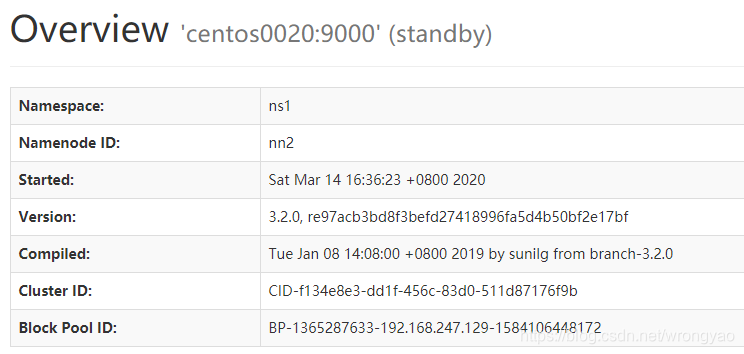
4.7.2 yarn
http://centos0040:8088
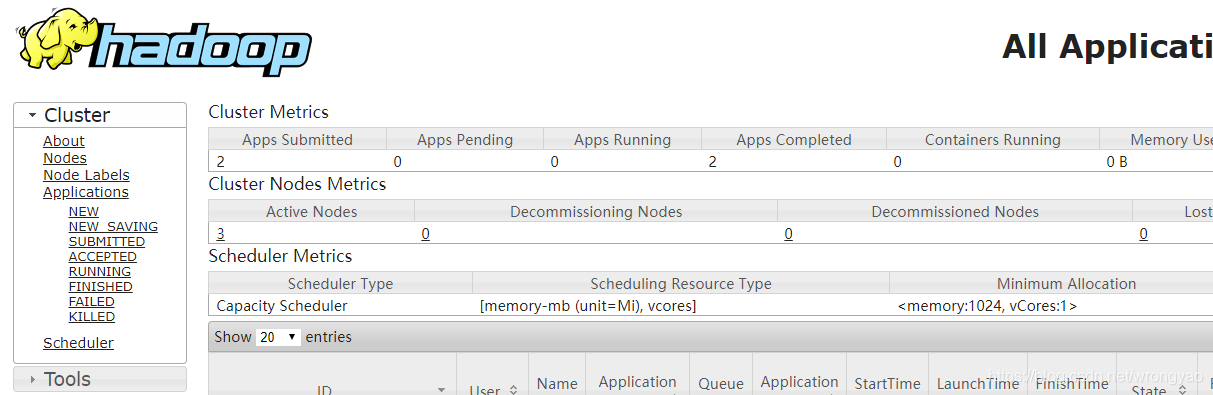
4.8 增加节点
# 在新配置的机器上 运行这个命令,datanode会自动加入集群,前提是有相同的配置文件
hadoop-daemon.sh start datanode
# 新版的上述命令被替换为下面这个
hdfs --daemon start datanode
# 所有的节点如下
balancer run a cluster balancing utility
datanode run a DFS datanode
dfsrouter run the DFS router
diskbalancer Distributes data evenly among disks on a given node
httpfs run HttpFS server, the HDFS HTTP Gateway
journalnode run the DFS journalnode
mover run a utility to move block replicas across storage types
namenode run the DFS namenode
nfs3 run an NFS version 3 gateway
portmap run a portmap service
secondarynamenode run the DFS secondary namenode
sps run external storagepolicysatisfier
zkfc run the ZK Failover Controller daemon

















 579
579




 到【灌水乐园】发言
到【灌水乐园】发言







