




 本文深入讲解Java集合框架,包括Collection、List、Set、Map等核心接口与类的使用,探讨泛型的优势,以及集合工具类Collections的功能。文章还介绍了如何在集合中存储自定义对象,实现排序与比较。
本文深入讲解Java集合框架,包括Collection、List、Set、Map等核心接口与类的使用,探讨泛型的优势,以及集合工具类Collections的功能。文章还介绍了如何在集合中存储自定义对象,实现排序与比较。
Java 集合
主要集合概述
Java 主要有 3 种重要的集合类型:
-
List:是一个有序集合,可以放置重复的元素
-
Set:是一个无序集合,不允许放置重复的元素
-
Map:是一个无序集合,集合中包含一个键对象,一个值对象,键对象不允许重复,值对象可以重复
- 就像身份证号和姓名 : <键 , 值>
集合中只能存储引用类型,不能存储基本数据类型
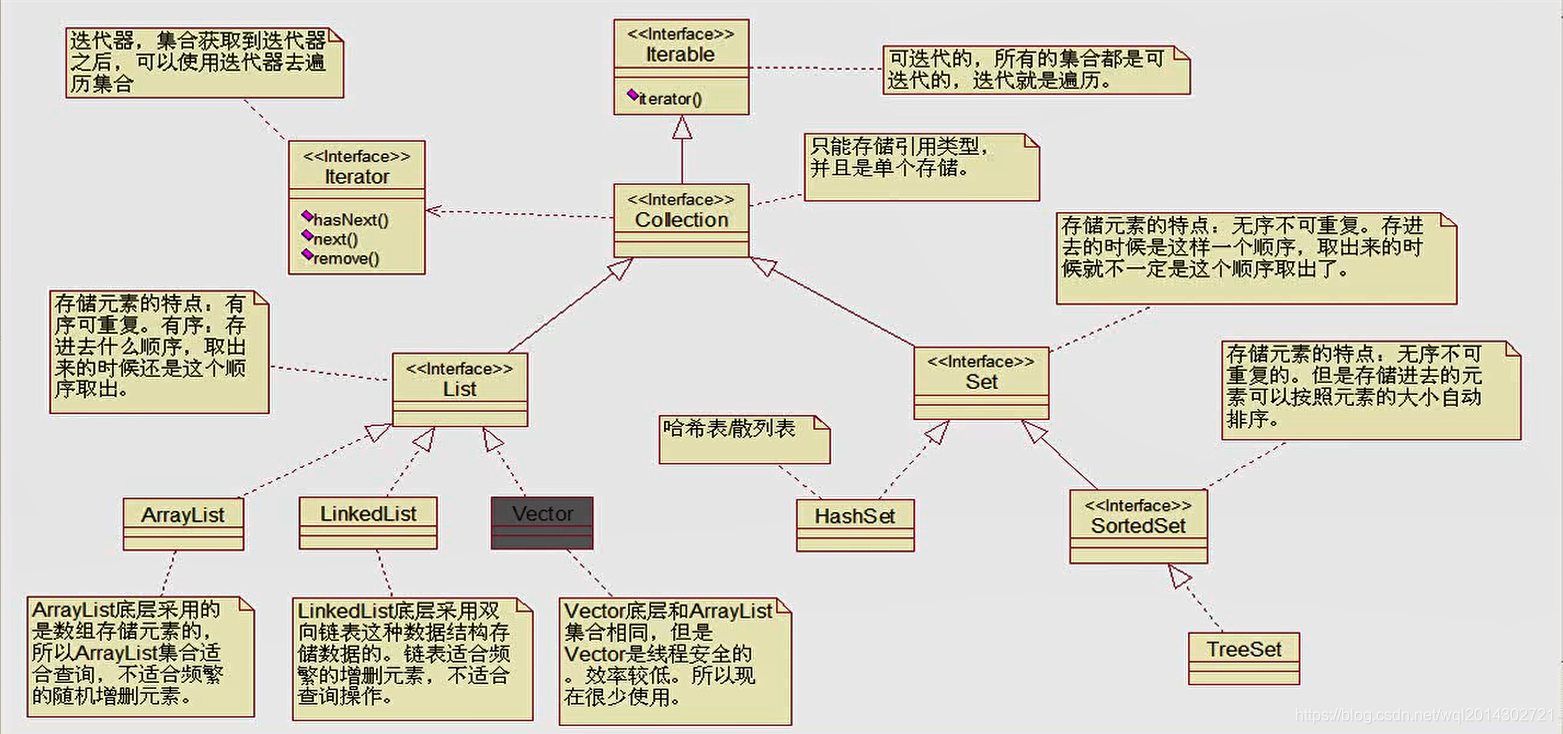
集合中 Collection 的继承结构图(重要·背下来)
Collection 中的常用方法
boolean add(E e)
boolean addAll(Collection<? extends E> c)
void clear()
boolean contains(Object o)
boolean containsAll(Collection<?> c)
int hashCode()
boolean isEmpty()
Iterator<E> iterator()
boolean remove(Object o)
boolean removeAll(Collection<?> c)
int size()
Object[] toArray()
-
举例1
import java.util.*; public class Test02 { public static void main(String[] args) { // 创建集合 Collection c = new ArrayList(); // 添加元素 c.add(1);// auto boxing c.add(new Integer(1)); Object o = new Object(); c.add(o); // 集合中只能单个存储元素,并且只能存储引用类行 c.add(new Customer("张三", 23)); // 获取元素个数 System.out.println(c.size());// 4 // 判断集合是否为空 System.out.println(c.isEmpty());// false Object[] resO = c.toArray(); for (int i = 0; i < resO.length; i++) { System.out.println(resO[i]); } // 移除某一个引用 c.remove(1); System.out.println(c.size());//3 // 清空集合 c.clear(); System.out.println(c.size());//0 // 判断集合是否为空 System.out.println(c.isEmpty());// true } } class Customer{ String name; int age; public Customer(String name, int age) { this.name = name; this.age = age; } @Override public String toString() { return "Customer [name=" + name + ", age=" + age + "]"; } } -
举例2-
Iterator迭代器Iterator iterator(); 获取集合所依赖的迭代器对象, 通过迭代器中的方法完成集合的遍历/迭代
注意: 这种方法是所有集合通用的遍历方式import java.util.*; /* Iterator iterator(); 获取集合所依赖的迭代器对象 通过迭代器中的方法完成集合的遍历/迭代 注意: 这种方法是所有集合通用的遍历方式 */ public class Test03 { public static void main(String[] args) { // 创建集合对象 Collection c = new LinkedList(); // 添加元素 c.add(122); // 自动装箱 c.add(false);// 自动装箱 c.add(399);// 自动装箱 // 迭代遍历 // 获取迭代器对象 // 不需要关心底层集合的具体类型,所有集合依赖的迭代器都实现了 java.util.Iterator; 接口 Iterator iterator = c.iterator(); // 迭代器对象是面向接口编程 // iterator 是引用,保存了内存地址,指向堆中的“迭代器对象” System.out.println(iterator); // java.util.LinkedList$ListItr@15db9742 // 开始调用方法,完成遍历,迭代 // 原则, 调用 iterator.next() 方法之前必须调用 iterator.hasNext() // while循环 while(iterator.hasNext()) { System.out.println(iterator.next()); } // for 循环 for(Iterator it = c.iterator(); it.hasNext();) { System.out.println(it.next()); } } } -
举例3-
contains()方法contains()底层是调用的equals()方法
注意:自己创建的类一般都要重写 Object 类中的 equals() 方法,使之用于比较内容
import java.util.*; // boolean contains(Object o) public class Test04 { public static void main(String[] args) { // 创建集合 Collection c = new ArrayList(); // 创建 Integer 类型的对象 Integer i1 = new Integer(256); // 添加元素 c.add(i1); System.out.println(c.contains(256));// true // 创建 Integer 类型的对象 Integer i2 = new Integer(256); // 虽然i2没有添加进c集合里面,但是contains()底层是调用的equals()方法 // Integer重写了Object类中的equals方法 // 所以下面执行结果为true System.out.println(c.contains(i2));// true Manger m1 = new Manger("张三", 12); c.add(m1); System.out.println(c.contains(m1));// true Manger m2 = new Manger("张三", 12); // Manger类重写equals方法后 System.out.println(c.contains(m2));// true } } class Manger{ String name; int id; public Manger(String name, int id) { this.name = name; this.id = id; } @Override public boolean equals(Object obj) { if(this == obj) { return true; } if(obj instanceof Manger) { Manger m = (Manger)obj; return this.name == m.name && this.id == m.id; } return false; } }-
ArrayList 中的contains()方法的实现
public boolean contains(Object o) { return indexOf(o) >= 0; } public int indexOf(Object o) { if (o == null) { for (int i = 0; i < size; i++) if (elementData[i]==null) return i; } else { for (int i = 0; i < size; i++) if (o.equals(elementData[i])) return i; } return -1; }
-
-
举例4-集合中的
remove()方法remove() 方法和contains()方法都需要集合中的对象重写 equals() 方法。 因为Object类中的equals方法是比较内存地址,而在现实的业务逻辑中不能比较内存地址,该比较内容。
import java.util.*; public class Test05 { public static void main(String[] args) { // 创建集合 Collection c = new ArrayList(); // 添加元素 Integer i1 = new Integer(10); c.add(i1); Integer i2 = new Integer(10); System.out.println(c.remove(i2));// true System.out.println(c.size());// 0 Manger m1 = new Manger("张三", 12); c.add(m1); Manger m2 = new Manger("张三", 12); // Manger类重写equals方法后 System.out.println(c.remove(m2));// true System.out.println(c.size());//0 } } -
举例5-迭代器中的
remove()方法在使用迭代器循环删除集合中的元素的时候,不能使用集合的
remove()方法,只能使用迭代器的remove()方法import java.util.*; public class Test06 { public static void main(String[] args) { // 创建集合 Collection c = new ArrayList(); c.add(1); c.add(2); c.add(3); // 创建迭代器对象 Iterator it = c.iterator(); while(it.hasNext()) { Object o = it.next(); it.remove();// 使用迭代器删除 } System.out.println(c.size());// 0 // 如果在迭代的过程中不使用迭代器的 remove()方法 // 使用 集合的 remove()方法可以吗 // 当然不可以,在第一次循环的时候没问题,但是第二次循环的时候 it对应的集合已经不是原来的集合了 // 报错ConcurrentModificationException /* c.add(1); c.add(2); c.add(3); it = c.iterator();// 需要重新指定 it while(it.hasNext()) { Object o = it.next(); c.remove(o);// 使用结合中的方法删除 // 报错ConcurrentModificationException } System.out.println(c.size()); // 0 */ } }List集合详解
List 是一个接口, 里面有自己规定的(独特的)方法
public interface List<E> extends Collection<E>-
举例1-List集合中存储的元素有序且可以重复
import java.util.*; public class Test07 { public static void main(String[] args) { List list = new ArrayList(); list.add(2); list.add(4); list.add(3); list.add(34); // 遍历 Iterator it = list.iterator(); while(it.hasNext()) { System.out.println(it.next()); } // E get(int index) 获取对应下标的元素 System.out.println(list.get(3)); } } -
举例2-深入
List集合-
ArrayList集合底层是数组,数组是有下标的,所以ArrayList有很多自己的特性(关于下标的特性)
-
ArrayList集合底层默认初始化数组大小为 10 ,扩大之后的容量是原容量的 1.5 倍
-
Vector 集合底层默认初始化数组大小为10,扩大之后的容量是原容量的 2 倍;
如何优化 ArrayLIst 和 Vector?
尽量减少扩容操作,因为扩容需要数组拷贝。一般推荐在创建集合的时候指定初始化数组的大小
-
方法
void add(int index, E element); Object get(int index); Object remove(int index); Object set(int index, Object element); List subList(int fromIndex, int toIndex)
import java.util.*; public class Test08 { public static void main(String[] args) { List l = new ArrayList(); l.add(23); l.add(123); l.add(321); l.add(69); // 在下标为 1 的地方添加 555 l.add(1, 555); // 将下标2的地方的数据更改为 100 l.set(2, 100); // 获取第1个元素 System.out.println(l.get(0)); System.out.println("======="); // 遍历(List 集合中特有的遍历方式) for(int i=0; i<l.size(); i++) { Object o = l.get(i); System.out.println(o); } } } -
-
Set对应的类及常用方法
Set 中存储的元素是无序, 不可重复的,存进去的顺序和取出来的顺序不一定一致。
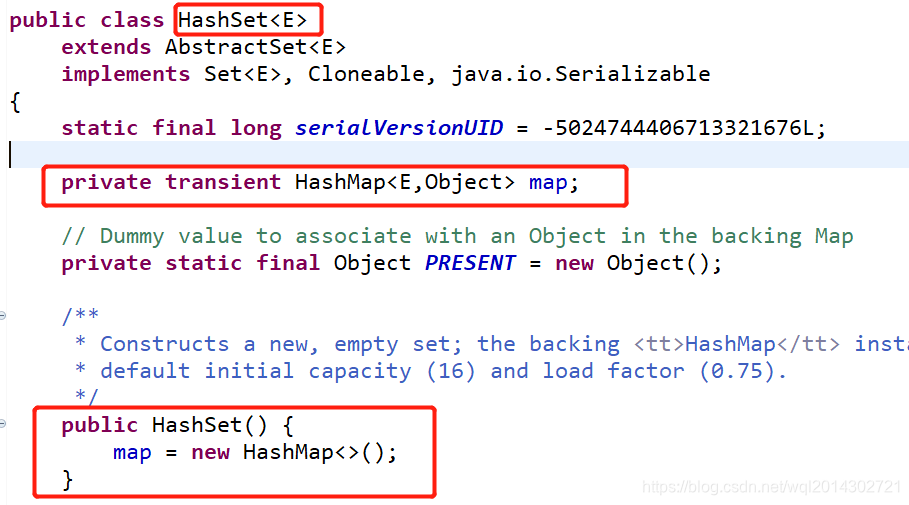
HashSet 类实现了Set接口(HashSet 的底层时间上是一个 HashMap,见下图·java的HashSet源码)
HashMap底层是哈希表
SortedSet 接口继承了Set 接口,其存储的元素也是无需,不可重复的,但是存进去的元素可以按照元素的大小自动排序,TreeSet 类实现了 SortedSet 接口
-
哈希表/散列表(较高的查找/删除/增加效率)
-
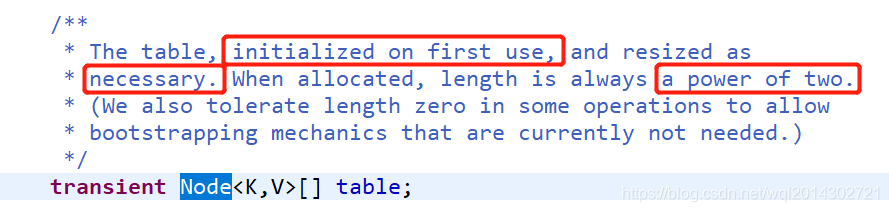
哈希表是数组和单向链表的结合
-
哈希表的本质是一个数组,只不过这个数组中的每一个元素都是一个单向链表
-
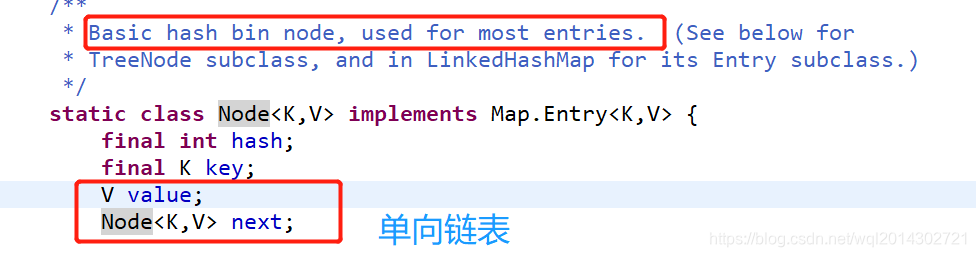
数组中每一个元素存储的是一个单向链表,单向链表中每一个节点存储的是:final int hash, Object key, Object value, Node<> next;
-
hash 值是通过
key调用hashcode()方法得到的值,再通过hash算法得到的值
-
在数组中每一个单向链表中节点的hash值都是相同的,代表了数组的下标
-
hashMap中有一个方法用于查找对应的节点:
Object get(Object key)public V get(Object key) { Node<K,V> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } -
hashMap中有一个添加元素的方法:
void put(Object key, Object value)public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; // tab = table if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; // hash 和 数组下标的对应关系:i = (n - 1) & hash if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);// 新的单向链表 else {// 已经存在的单向链表 Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }
-
-
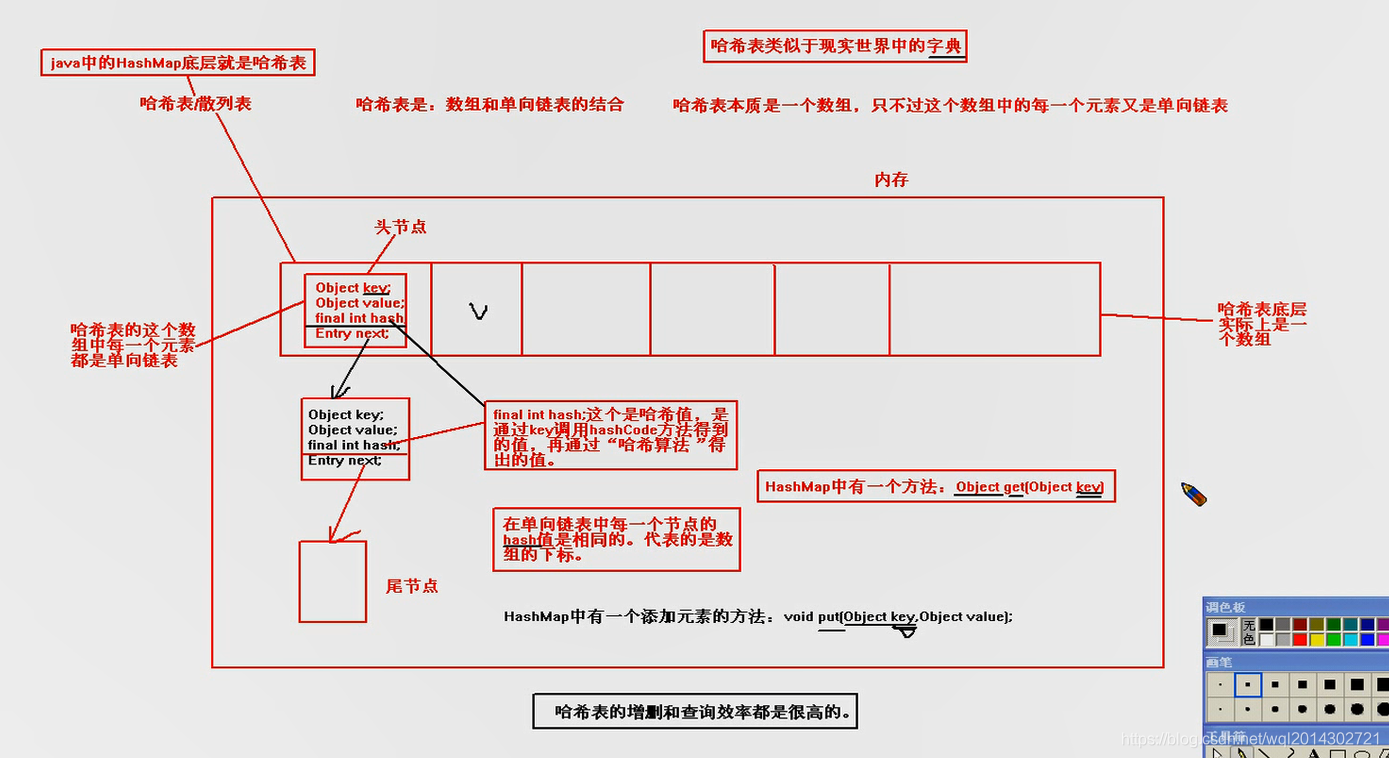
HashSet集合详解
- HashSet实际上是一个HashMap,HashMap底层采用了哈希表数据结构
- HashMap的初始容量是 16,缩放因子是 0.75
- 哈希表又叫散列表。哈希表的底层是一个数组,这个数组的每一个元素是一个单向链表,每一个单向链表都有一个独一无二的hash值,代表了数组的下标
- 在一个单向链表中每一个节点的hash值是相同的。
- hash值实际上是 key 调用 hashCode 方法,再通过 hash function 得到的值。
- 在一个单向链表中每一个节点的hash值是相同的。
- 向hash 表中添加元素的过程:
- 先调用被存储的
key的hashCode方法,经过hash function得到hash值- 如果在这个
hash表中不存在这个hash值,则直接加入元素。 - 如果该 hash 值已经存在,继续调用key之间的 equals 方法
- 如果equals方法返回 false,则将该元素田间
- 如果equals方法返回 true,则放弃添加该元素(元素不可重复,所以就不添加了)
- 如果在这个
- 先调用被存储的
import java.util.*;
public class Test09 {
public static void main(String[] args) {
Set s = new HashSet();
s.add(1);
s.add(1);
s.add(188);
s.add(100);
s.add(74);
s.add(85);
// 遍历
// 创建迭代器
Iterator it = s.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
// 输出
1
100
85
74
188
-
关于往
Set集合里面添加元素- 存储在
hashSet或者HashMap集合中Key部分的的元素,需要同时重写hashCode()和equals()方法
import java.util.*; public class Test10 { public static void main(String[] args) { Set s = new HashSet(); Employee e1 = new Employee("1000", "jack"); Employee e2 = new Employee("1000", "jack"); Employee e3 = new Employee("2000", "cook"); Employee e4 = new Employee("2000", "book"); Employee e5 = new Employee("4003", "barabase"); // 添加元素的时候,会先调用Employee里面的hashCode方法得到hash值,hash不一样往数组里面添加 // hash 一样,调用equals方法,返回false,插入到对应hash单向链表中 // 返回 true,不添加,所以要重写对应类里面的hashCode()方法和 s.add(e1); s.add(e2); s.add(e3); s.add(e4); s.add(e5); System.out.println(s.size()); } } class Employee{ String no; String name; public Employee(String no, String name) { this.no = no; this.name = name; } // 重写 Object 中的 hashCode @Override public int hashCode() { return this.no.hashCode();//直接使用 String 类里面的hashCode方法 } // 重写 Object中的equals方法 @Override public boolean equals(Object obj) { if(this == obj) { return true; } if(obj instanceof Employee) { Employee e = (Employee)obj; return (this.no == e.no && this.name == e.name); } return false; } } - 存储在
SortedSet接口介绍
-
SortedSet是一个接口
java.util.Set; java.util.SortedSet;//无需不可重复,但是可以按照元素大小自动排序 java.util.TreeSet;import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.*; public class Test11 { public static void main(String[] args) throws ParseException { SortedSet ss = new TreeSet(); ss.add(10); ss.add(22); ss.add(12); ss.add(34); ss.add(28); // 遍历 Iterator it = ss.iterator(); while(it.hasNext()) { System.out.println(it.next()); } /* 输出 10 12 22 28 34 */ // 字符串 SortedSet strs = new TreeSet(); String s1 = "Jack"; String s2 = "Tom"; String s3 = "Jerry"; String s4 = "Pack"; strs.add(s1); strs.add(s2); strs.add(s3); strs.add(s4); it = strs.iterator(); while(it.hasNext()) { System.out.println(it.next()); } /* 输出 Jack Jerry Pack Tom */ // 日期 String st1 = "2008-08-08"; String st2 = "2009-08-08"; String st3 = "2008-02-03"; String st4 = "2008-12-14"; SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd"); Date d1 = sdf.parse(st1); Date d2 = sdf.parse(st2); Date d3 = sdf.parse(st3); Date d4 = sdf.parse(st4); SortedSet times = new TreeSet(); times.add(d1); times.add(d2); times.add(d3); times.add(d4); // 遍历 it = times.iterator(); while(it.hasNext()) { Object o = it.next(); if(o instanceof Date) { Date t = (Date) o; System.out.println(sdf.format(t)); } } /* 输出 2008-02-03 2008-08-08 2008-12-14 2009-08-08 */ } }-
Collection 里面只能存储引用类型
-
SortedSet里面存储的元素不重复,无需,但是会自动根据元素大小来排序
-
为什么不同类型的数据(Integer, String, Date)都可以进行比较大小呢?
因为他们都实现了 Compareable接口,实现了里面的 compareTo() 方法
-
-
-
SortedSet集合里面的元素是如何排序的?
在上面的程序中,我们使用了Sun公司已经写好的Date类/String类型的数据存储到TreeSet集合中,发现可以直接排序,那么我们尝试以下往SortedSet中存储我们自己写的类会发生什么呢?
import java.util.*; public class Test12 { public static void main(String[] args) { SortedSet ss = new TreeSet(); User u1 = new User(10); User u2 = new User(13); User u3 = new User(12); User u4 = new User(15); User u5 = new User(11); ss.add(u1); ss.add(u2); ss.add(u3); ss.add(u4); ss.add(u5); Iterator it = ss.iterator(); while(it.hasNext()) { System.out.println(it.next()); } } } class User{ int age; public User(int age) { this.age = age; } @Override public String toString() { return "User[age="+this.age+"]"; } }// 编译成功,运行错误 Exception in thread "main" java.lang.ClassCastException: com.test.collections.User cannot be cast to java.lang.Comparable at java.util.TreeMap.compare(Unknown Source) at java.util.TreeMap.put(Unknown Source) at java.util.TreeSet.add(Unknown Source) at com.test.collections.Test12.main(Test12.java:11)运行报 “类型转换错误” 的错误, 我们自己写的类不能转换成
java.lang.Comparable类型,所以我们应该实现Comparable接口里面的方法所以说 凡是放在
SortedSet里面的元素 必须 实现了Comparable接口里面的compareTo()方法。import java.util.*; public class Test12 { public static void main(String[] args) { SortedSet ss = new TreeSet(); User u1 = new User(10); User u2 = new User(13); User u3 = new User(12); User u4 = new User(15); User u5 = new User(11); ss.add(u1); ss.add(u2); ss.add(u3); ss.add(u4); ss.add(u5); Iterator it = ss.iterator(); while(it.hasNext()) { System.out.println(it.next()); } } } class User implements Comparable{// 继承Comparable接口实现里面的方法 int age; public User(int age) { this.age = age; } @Override public String toString() { return "User[age="+this.age+"]"; } // 实现Comparable 接口中的 compareTo方法 @Override public int compareTo(Object o) { return this.age-((User)o).age; } }这样就可以成功运行了,输出结构是按照年龄从小到大排序的
User[age=10] User[age=11] User[age=12] User[age=13] User[age=15] -
让
SortedSet集合做到排序还有另一种方式:java.util.Comparator- 单独编写一个比较器,传入到
TreeSet对象中。 - 比较推荐此类写法,因为不需要改变存入
SortedSet内元素的类,具有更低的耦合性

import java.util.*; public class Test13 { public static void main(String[] args) { @SuppressWarnings("unchecked") SortedSet ss = new TreeSet(new ProductComparator()); Product p1 = new Product(32); Product p2 = new Product(12); Product p3 = new Product(24); Product p4 = new Product(13); ss.add(p1); ss.add(p2); ss.add(p3); ss.add(p4); // 遍历 Iterator it = ss.iterator(); while(it.hasNext()) { System.out.println(it.next()); } } } class Product{ double price; public Product(double price) { this.price = price; } @Override public String toString() { return "Product["+this.price+"]"; } } class ProductComparator implements Comparator{ @Override public int compare(Object o1, Object o2) { if(o1 instanceof Product && o2 instanceof Product) { double price1 = ((Product)o1).price; double price2 = ((Product)o2).price; if(price1 == price2) { return 0; }else if(price1 > price2) { return 1; }else { return -1; } } return 0; } }也可以使用匿名内部类
import java.util.*; public class Test13 { public static void main(String[] args) { @SuppressWarnings("unchecked") SortedSet ss = new TreeSet(new Comparator() {// 匿名内部类 @Override public int compare(Object o1, Object o2) { double price1 = ((Product)o1).price; double price2 = ((Product)o2).price; if(price1 == price2) { return 0; }else if(price1 > price2) { return 1; }else { return -1; } } }); Product p1 = new Product(32); Product p2 = new Product(12); Product p3 = new Product(24); Product p4 = new Product(13); ss.add(p1); ss.add(p2); ss.add(p3); ss.add(p4); // 遍历 Iterator it = ss.iterator(); while(it.hasNext()) { System.out.println(it.next()); } } } class Product{ double price; public Product(double price) { this.price = price; } @Override public String toString() { return "Product["+this.price+"]"; } }输出结果:// 已经排序了
Product[12.0] Product[13.0] Product[24.0] Product[32.0] - 单独编写一个比较器,传入到
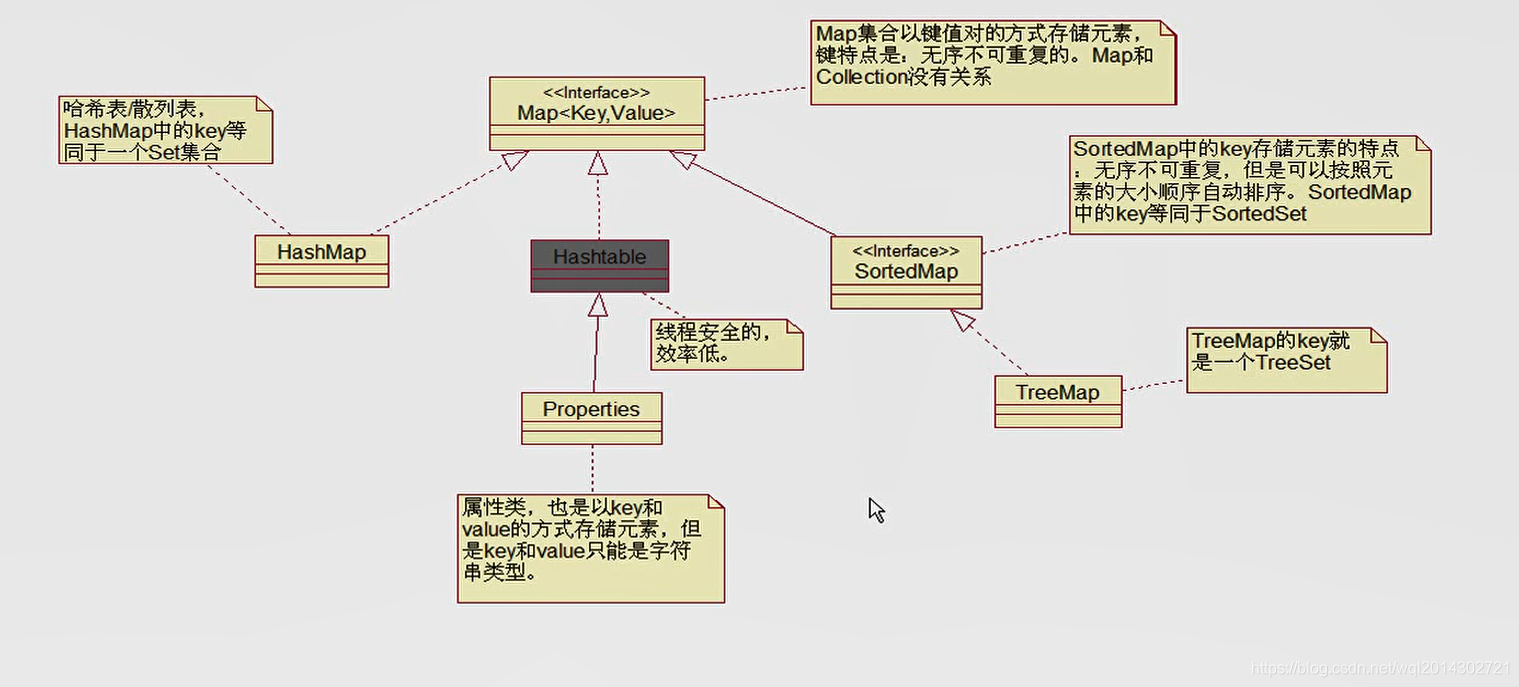
集合中 Map 的继承结构图(重要)
Map和Collection没有关系
-
Map是一个父接口,HashMap类和Hashtable类实现了Map接口,SortedMap接口继承Map接口,TreeMap类实现了SortedMap接口 -
HashMap中的key要重写hashCode()和equals()方法 -
SortedMap或者TreeMap的key要实现Comparable接口中的compareTo()方法。或者单独写一个Comparator比较器 -
Properties类继承自Hashtable,是一个属性类,也是以key-value的方式存储元素,但是key-value只能是字符串
Map集合中常用的方法
- 存储在
Map集合中的key部分的元素需要同时重写hashCode()和equals()方法。
void clear();
boolean isEmpty();
int size();
V get(Object key);
V put(K key, V value); // 注意:map中如果key重复了,value将会覆盖key对应的值
boolean containsKey(Object key);
boolean containsValue(Object value);
V remove(Object key);
Set keySet();
Collection values();
Set entrySet()
import java.util.*;
public class Test14 {
public static void main(String[] args) {
// 1.创建集合
Map persons = new HashMap();
// 2. 存储键值对
persons.put("10000", "Javk");
persons.put("10001", "Cook");
persons.put("10002", "Book");
persons.put("10003", "Kook");
persons.put("10004", "Pook");
persons.put("10002", "BooJ");
// 3. 判断键值对的个数
// Map 中的key是无序的不可重复的
System.out.println(persons.size());// 5
// 4. 判断Map中是否包含某key
System.out.println(persons.containsKey("10003"));// true
// 5. 判断Map中是否包含某value
System.out.println(persons.containsValue("Javk"));// true
System.out.println(persons.containsValue("Book"));// false
// 6. 通过 key 获取value
String key = "10002";
Object value = persons.get(key);
System.out.println(value);// BooJ // BooJ将Book覆盖掉了
// 7. 通过key删除键值对
persons.remove("10004");
System.out.println(persons.size());// 4
// 8. 获取所有的value
Collection values = persons.values();
Iterator it = values.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
// 9. 获取所有的 key
Set keys = persons.keySet();
it = keys.iterator();
while(it.hasNext()) {
Object id = it.next();
Object name = persons.get(id);
System.out.println(id+"-->"+name);
}
// 10. entrySet
Set entrySet = persons.entrySet();
it = entrySet.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
Hashtable & Properties常用方法介绍
-
Hashtable是线程安全的,但是效率低- 初始化容量是 11, 加载因子是 0.75
HashMap的初始化容量是 16, 加载因子是 0.75
-
Properties是一个属性类,继承自Hashtable类,存储的key-value只能是字符串import java.util.*; public class Test15 { public static void main(String[] args) { // 1.创建属性类对象 Properties p = new Properties(); // 2. 存储元素 p.setProperty("driver", "oracle.jdbc.driver.OracleDriver"); p.setProperty("username", "tailor"); // 注意 key 不能重复,如果重复则覆盖原来的value p.setProperty("username", "tailor95"); p.setProperty("password", "balabala"); p.setProperty("url", "jdbc:oracle:thin:@192.168.1.100:1512:balabala"); // 3. 通过 key 获取 value String v1 = p.getProperty("driver"); String v2 = p.getProperty("username"); String v3 = p.getProperty("password"); String v4 = p.getProperty("url"); System.out.println(v1); System.out.println(v2); System.out.println(v3); System.out.println(v4); } }输出:
oracle.jdbc.driver.OracleDriver tailor95 balabala jdbc:oracle:thin:@192.168.1.100:1512:balabala
SortedMap & TreeMap
-
SortedMap中key的特点:无序不重复,但是存进去的元素可以按照大小自动排序- 如果想自动排序,
key部分的元素需要:或者实现Comparable接口, 或者单独实现一个比较器Comparator- 下面代码是 实现了
Comparable接口
- 下面代码是 实现了
import java.util.*; public class Test16 { public static void main(String[] args) { // Map 中的key 存储 product, value存储 重量 // 1. 创建 map集合 SortedMap sm = new TreeMap(); // 2. 准备 对象 ProductMap p1 = new ProductMap("西瓜", 0.5); ProductMap p2 = new ProductMap("苹果", 3.0); ProductMap p3 = new ProductMap("香蕉", 2.0); ProductMap p4 = new ProductMap("橘子", 1.5); // 3. 添加到map中 sm.put(p1, 8.0); sm.put(p2, 5.0); sm.put(p3, 2.0); sm.put(p4, 3.0); // 4. 遍历 Iterator it = sm.keySet().iterator(); while(it.hasNext()) { Object p = it.next(); Object w = sm.get(p); System.out.println(p+"===>"+w); } } } class ProductMap implements Comparable{// 实现 Comparable接口 String name; double price; public ProductMap(String name, double price) { this.name = name; this.price = price; } // 重写 toString @Override public String toString() { return "[Product:"+this.name+"--->"+this.price+"]"; } @Override public int compareTo(Object o) { double price1 = this.price; double price2 = ((ProductMap)o).price; if(price1 > price2) { return 1; }else if(price1 < price2) { return -1; }else return 0; } }-
下面代码是单独实现了一个比较器
Comparator(使用了匿名内部类)package com.test.collections; import java.util.*; public class Test16 { public static void main(String[] args) { // Map 中的key 存储 product, value存储 重量 // 1. 创建 map集合 // SortedMap sm = new TreeMap(); SortedMap sm = new TreeMap(new Comparator() {// 单独实现了一个比较器 @Override public int compare(Object o1, Object o2) { double price1 = ((ProductMap)o1).price; double price2 = ((ProductMap)o2).price; if(price1 > price2) { return 1; }else if(price1 < price2) { return -1; }else return 0; } }); // 2. 准备 对象 ProductMap p1 = new ProductMap("西瓜", 0.5); ProductMap p2 = new ProductMap("苹果", 3.0); ProductMap p3 = new ProductMap("香蕉", 2.0); ProductMap p4 = new ProductMap("橘子", 1.5); // 3. 添加到map中 sm.put(p1, 8.0); sm.put(p2, 5.0); sm.put(p3, 2.0); sm.put(p4, 3.0); // 4. 遍历 Iterator it = sm.keySet().iterator(); while(it.hasNext()) { Object p = it.next(); Object w = sm.get(p); System.out.println(p+"===>"+w); } } } class ProductMap{ String name; double price; public ProductMap(String name, double price) { this.name = name; this.price = price; } // 重写 toString @Override public String toString() { return "[Product:"+this.name+"--->"+this.price+"]"; } }输出:可见key按照价格排了序
[Product:西瓜--->0.5]===>8.0 [Product:橘子--->1.5]===>3.0 [Product:香蕉--->2.0]===>2.0 [Product:苹果--->3.0]===>5.0
- 如果想自动排序,
关于集合工具类Collections的用法
-
java.util.Collections是一个类,是集合的工具类,可以实现对集合的操作-
java.util.Collection是一个接口 -
Collections里面的sort方法,实现集合内的元素的排序static void sort(List list)-
示例1
import java.util.*; public class Test17 { public static void main(String[] args) { // 1. 创建List集合 List l = new ArrayList(); // 2. 添加元素 l.add(10); l.add(20); l.add(14); l.add(23); // 3. 遍历 for(int i=0; i<l.size(); i++) { System.out.println(l.get(i)); } // 调用 Collcetions类中的 sort方法排序 Collections.sort(l); // 遍历 System.out.println("========="); for(Iterator it = l.iterator();it.hasNext();) { System.out.println(it.next()); } } }输出:
10 20 14 23 ========= 10 14 20 23 -
Collcetions类中的sort()方法怎么对集合中的元素进行排序?- 将
Set集合转换为List类型
import java.util.*; public class Test18 { public static void main(String[] args) { // 1. 创建set集合 Set s = new HashSet(); // 2. 添加元素 s.add(12); s.add(10); s.add(21); s.add(32); // 3. 创建List###########就是在这操作的############### List list = new ArrayList(s); // 4. 调用Collections工具类中的sort()方法进行排序 Collections.sort(list); // 5. 遍历 Iterator it = list.iterator(); while(it.hasNext()) { System.out.println(it.next()); } } } - 将
-
是不是
List中存储的所有类型的元素都可以调用Collections类中的sort方法?- 当然不是,元素要么实现
Comparable接口,要么单独写一个比较器Comparator- 下面代码运行错误:
java.lang.ClassCastException: Person cannot be cast to java.lang.Comparable- 需要实现
Comparable接口
- 需要实现
- 下面代码运行错误:
import java.util.*; public class Test19 { public static void main(String[] args) { // 创建集合 List list = new ArrayList(); // 准备数据 Person p1 = new Person(); Person p2 = new Person(); Person p3 = new Person(); Person p4 = new Person(); // 添加数据 list.add(p1); list.add(p2); list.add(p3); list.add(p4); // 调用Collections类中的sort方法 Collections.sort(list); // 遍历输出 Iterator it = list.iterator(); while(it.hasNext()) { System.out.println(it.next()); } } } class Person{ // 没有实现 Comparable }-
实现
Comparable接口package com.test.collections; import java.util.*; public class Test19 { public static void main(String[] args) { // 创建集合 List list = new ArrayList(); // 准备数据 Person p1 = new Person(); Person p2 = new Person(); Person p3 = new Person(); Person p4 = new Person(); // 添加数据 list.add(p1); list.add(p2); list.add(p3); list.add(p4); // 调用Collections类中的sort方法 Collections.sort(list); // 遍历输出 Iterator it = list.iterator(); while(it.hasNext()) { System.out.println(it.next()); } } } class Person implements Comparable{ @Override public int compareTo(Object o) { return 0; } }
- 当然不是,元素要么实现
-
Collections类中的synchronizedList(List list)方法可以将线程不安全的ArrayList转换成线程安全的import java.util.*; public class Test20 { public static void main(String[] args) { List list = new ArrayList(); Collections.synchronizedList(list); // 这之后,list就是线程安全的了 } }
-
泛型初步
主要介绍jdk5.0的新特性: 泛型(属于编译期的概念)
为什么引入泛型
- 可以统一集合中的数据类型
- 可以减少强制类型转换
泛型语法如何实现
-
泛型是编译阶段的语法,在编译阶段统一集合中的数据类型
List使用泛型
import java.util.*; public class Test21 { public static void main(String[] args) { // 创建泛型集合// 创建String类型的集合 List<String> list = new ArrayList<String>(); // 添加元素 //list.add(1);// 编译错误 list中存储的是String类型,所以不能添加 Integer 类型的数据 list.add("Jack"); list.add("Tom"); list.add("Jerry"); list.add("Snobe"); // 遍历泛型集合 Iterator<String> it = list.iterator(); while(it.hasNext()) { String s = it.next(); System.out.println(s); } } }-
Map使用泛型import java.util.*; public class Test22 { public static void main(String[] args) { // 创建集合 Map<String, Integer> maps = new HashMap<String, Integer>(); // 添加元素 maps.put("苹果", 23); maps.put("橘子", 18); maps.put("香蕉", 3); maps.put("西瓜", 64); // 遍历 // 得到所有的key Set<String> keys = maps.keySet(); Iterator<String> it = keys.iterator(); while(it.hasNext()) { String key = it.next(); Integer i = maps.get(key); System.out.println(key+"--->"+i); } } } -
SortedSet使用泛型- 注意实现
Comparable接口
import java.util.*; public class Test23 { public static void main(String[] args) { // 创建集合 SortedSet<Manager> ss = new TreeSet<Manager>(); // 准备数据 Manager m1 = new Manager(23.0); Manager m2 = new Manager(22.0); Manager m3 = new Manager(23.4); Manager m4 = new Manager(12.0); Manager m5 = new Manager(18.5); ss.add(m1); ss.add(m2); ss.add(m3); ss.add(m4); ss.add(m5); // 遍历数据 Iterator<Manager> it = ss.iterator(); while(it.hasNext()) { it.next().work(); } } } class Manager implements Comparable<Manager>{ // 实现 Comparable接口 double sal; public Manager(double sal) { this.sal = sal; } public void work() { System.out.println("工作,一个月"+sal+"元"); } @Override public String toString() { return sal+""; } @Override public int compareTo(Manager o) { if(this.sal > o.sal) { return 1; }else if(this.sal < o.sal) { return -1; } return 0; } } - 注意实现
自定义泛型
public class Test24 {
public static void main(String[] args) {
MyClass<String> mc = new MyClass<String>();
// mc.m1(100);// 编译错误
mc.m1("Jack");;
}
}
class MyClass<T>{
void m1(T t) {
System.out.println(t);
}
}
泛型的优点和缺点
- 优点:同一类型,减少强制转换
- 缺点:只能存储一种类型
forEach
关于增强 for 循环(JDK5.0新特性)
语法:
for(类型 变量:数组名/集合名){}
-
集合如果想使用 **增强
for**循环这种语法,集合需要使用 泛型- 不使用泛型也可以,但是
for里面的变量类型应该是Object
import java.util.*; public class Test25 { public static void main(String[] args) { int[] a= {1,2,3,4}; for(int e: a) { System.out.println(e); } System.out.println("=========="); // 集合 Set<String> s = new HashSet<String>(); s.add("张三"); s.add("李四"); s.add("王五"); s.add("赵六"); // 遍历 for(String name:s) { System.out.println(name); } } } - 不使用泛型也可以,但是
-
增强
for循环的缺点:- 没有下标
end


















 6203
6203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











