




 本文介绍了SDXL,一个用于更逼真图像生成的最新模型,以及ComfyUI,一个方便的AI绘画软件。SDXL具备高清输出、脸部生成和文字处理能力。用户可通过DreamStudio在线体验或下载ComfyUI进行本地使用。ComfyUI支持多种AI模型,包括SD系列和其它模型,适用于不同硬件平台。文章提供了软件获取、模型配置和使用步骤,帮助读者快速开始AI图像创作。
本文介绍了SDXL,一个用于更逼真图像生成的最新模型,以及ComfyUI,一个方便的AI绘画软件。SDXL具备高清输出、脸部生成和文字处理能力。用户可通过DreamStudio在线体验或下载ComfyUI进行本地使用。ComfyUI支持多种AI模型,包括SD系列和其它模型,适用于不同硬件平台。文章提供了软件获取、模型配置和使用步骤,帮助读者快速开始AI图像创作。
今天主要分享两个东西,一个是ComfyUI软件包,一个是SDXL的两个模型。

有这两个东西就可以快速出图了
先来简单介绍一下SDXL的特点。
Stable Diffusion XL 或 SDXL 是最新的图像生成模型,与以前的 SD 模型(包括 SD 2.1)相比,它专为更逼真的输出而定制,具有更详细的图像和构图。
借助 Stable Diffusion XL,您现在可以通过改进的脸部生成来制作更逼真的图像,在图像中生成清晰的文字,并使用更短的提示创建更美观的艺术作品。
根据官网的介绍和我的关注点,大概总结一下几个特征。
- 基于1024x1024训练,更加高清,v2是768,V1.5是512。
- 模型很大,体积很大,参数很大,35/66亿。
- 可以在图片中显示清晰的文字
- 人物和人脸生成效果更好
- 提供了多种图像风格,大概15种。
- 提示词更短,理解力上升,默认效果提升了好多。
具体的出图效果,可以参考之前的文章《SDXL的15中风格》
XSDL0.9可以在官方网站DreamStudio在线体验,也可以在本地离线使用。本地使用的话就需要ComfyUI和XSDL0.9的官方模型。
ComfyUI和Stable-Diffusion-WebUI的作用差不多,也是用来做AI绘画。
关于这个软件,大概知道以下几点就够了。
一个是这个软件的界面和webui有较大的差异。
一个是它全面支持SD1.x, SD2.x 和 SDXL等AI绘画模型。
当然也支持lora,Hypernetworks,Embeddings/Textual inversion
官方提供了集成包,支持CPU和GPU,惬意的很。
支持英伟达,ADM(Linux),苹果电脑。
可以兼容Stable Diffusion WebUI。
然后说一下模型
目前官方只在Huggingface上发布了模型,需要填写一个表格才能获取。官方分享了两个模型,一个叫Base 12.9GB ,一个叫refiner 5.65GB(适合图生图)。
XSDL软硬件要求:
操作系统 Win10/WIN11/Linux
内测 16GB RAM
显卡 Nvidia RTX20+ ,AMD (Linux)
显存 8GB+ RAM
这是官方给出的说明,我自己测试了win10/10,3060/3070都可以正常运行。
下面具体地说一下,怎么使用软件和模型,生成图片。
1.获取软件并解压
首先获取软件,软件我已经准备好了,公X号“托尼不是塔克”发送 “SDXL” 就可以直接获取了。
里面放了两个版本的软件,一个是包含了模型,解压即可使用。一个是单纯的软件,下载之后添加模型即可使用。
2. 确认模型放置正确
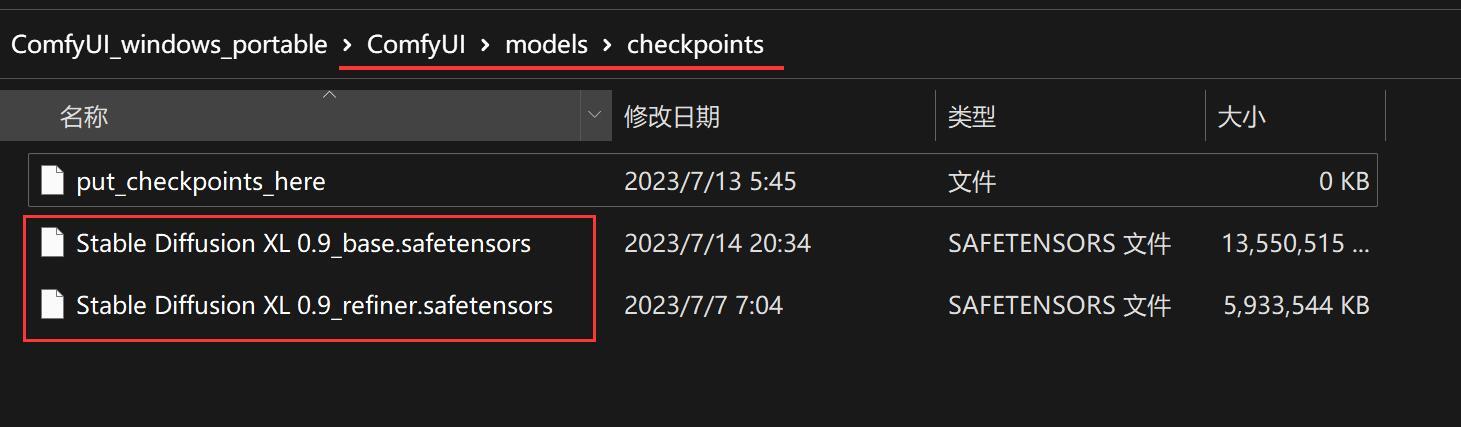
查看如图所示的位置,确保至少有一个模型文件。两个都有的话,最好了。
3. 启动软件
确认模型已经就位,其他就不用管了,直接点击bat文件启动即可。
压缩包里面提供了两个bat,一个是cpu,一个是GPU,根据自己情况选择就好了。最好是有显卡,直接选GPU。CPU的速度...
点击bat之后,软件很快就会启动完成。
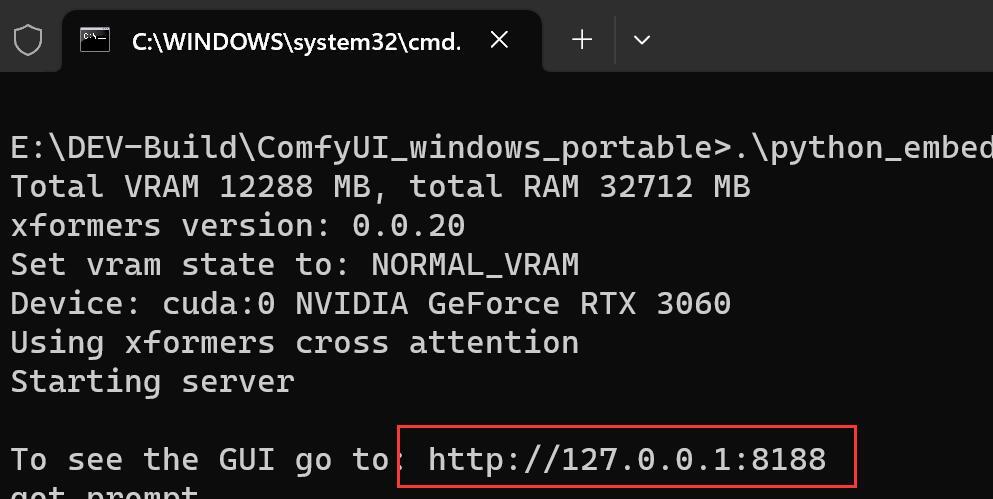
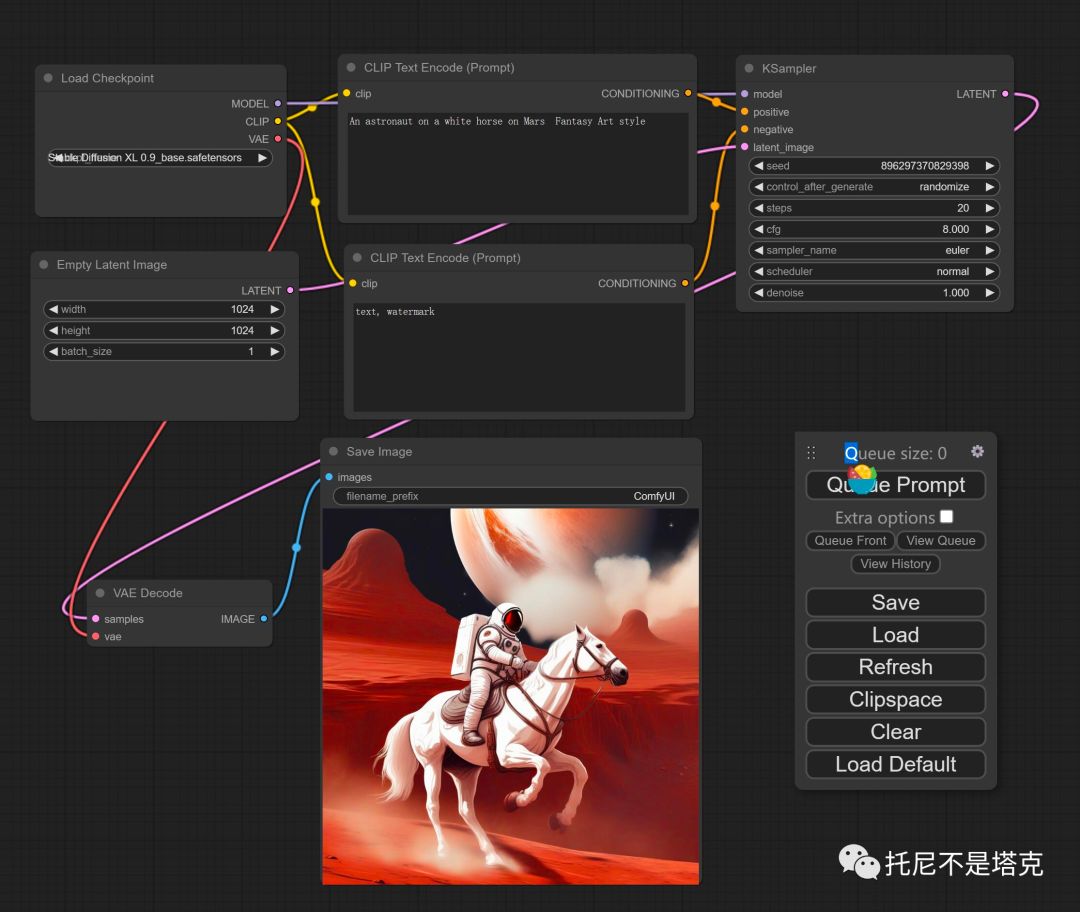
启动成功后,会出现一个网址,并且会自动调用浏览器,打开这个网址。
4. 使用软件
第一次使用软件可能有点不知所措,不要慌,你基本不需要改什么,就能出图了。
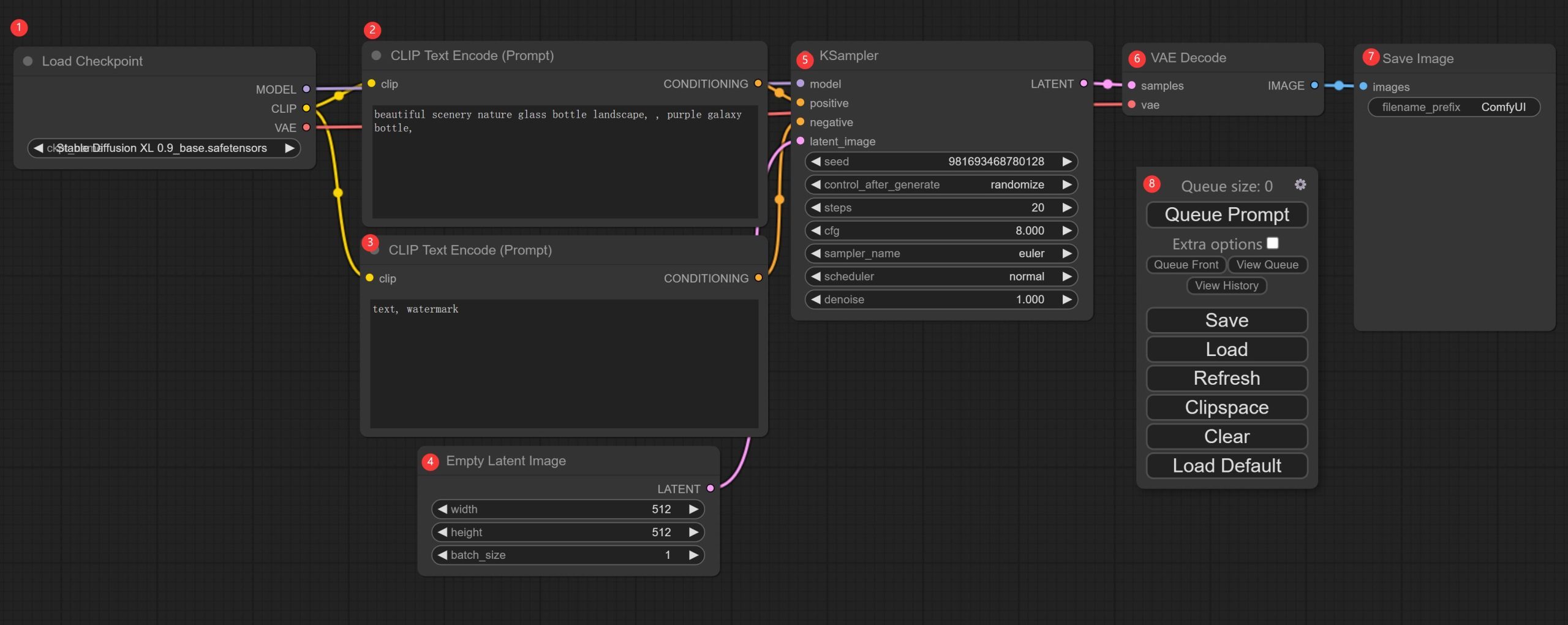
我稍微介绍一下,每个块的功能。
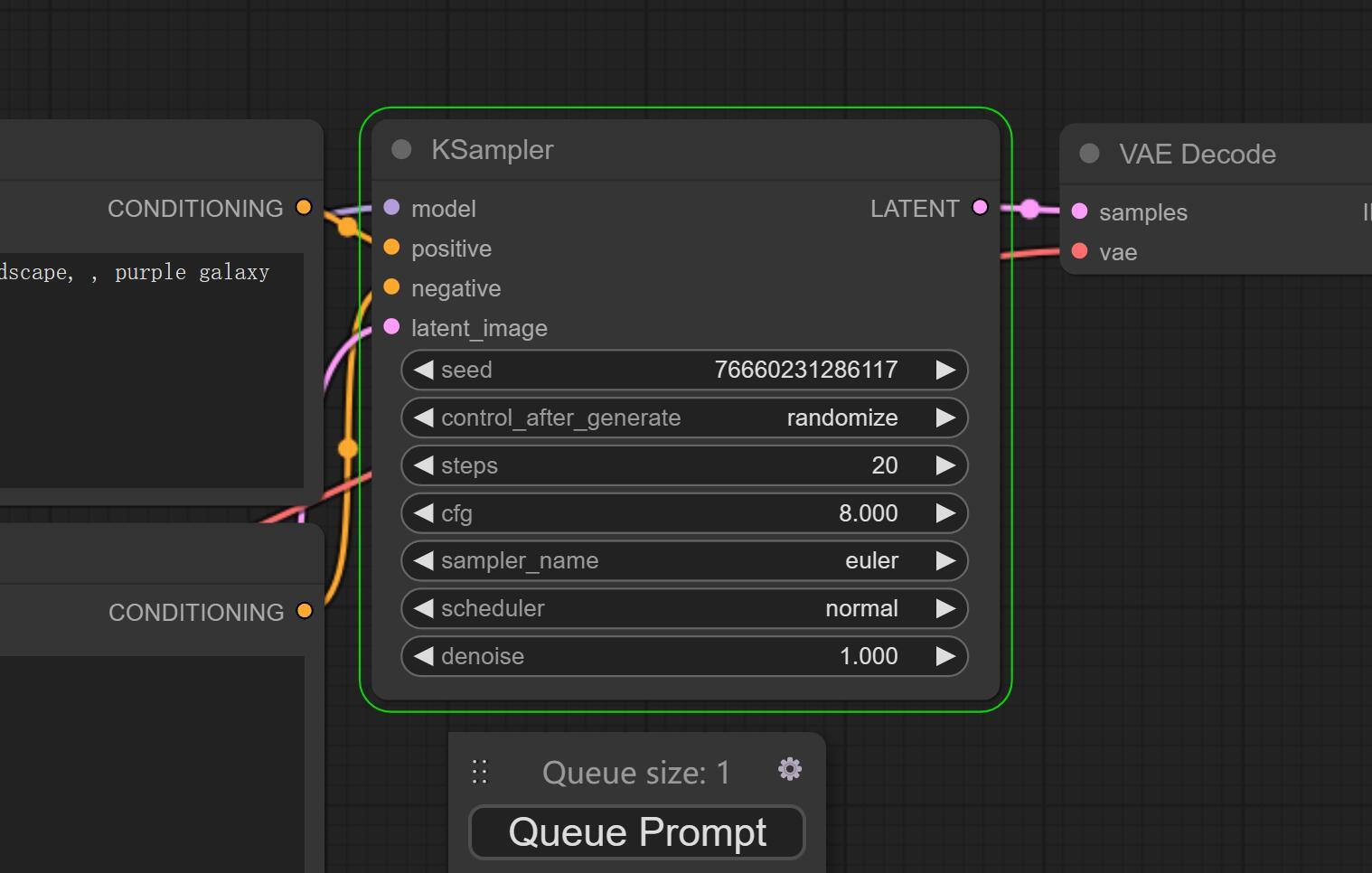
①模型加载器(Load Checkpoint)
这个模块主要用来加载模型,通过左右两个箭头可以切换模型。也可以点击中间区域,会出现一个下拉列表,点击其中一个即可选中。
选中后不会立即加载,等出图的时候才会加载。
②提示词输入(CLIP Text Encode)
这就是最主要的一部分了。
这是提示词输入框,输入你想要的图的描述词,注意要写英文。不会的可以中文翻译成英文。
③负向提示词(CLIP Text Encode)
这里写的就是你不要出现的东西。比如默认不要文字Text,不要水印WaterMark。
④分辨率设置(Empty Latent Image)
这里主要设置图像的大小和一次生成的数量。大小默认可能是512x512,但是这个模型表现最佳的像素应该是1024x1024。我是直接切换成了1024。
数量的话默认1就可以了。如果你想批量生成,那么改一下这里就可以了。
点击中间区域,就会跳出一个输入框,输入数字后,按回车就可以了。
⑤采样器设置(Ksamper)
这里主要是设置生成参数,和SDW基本类似,不懂就先不用管。
⑥ VAE设置
这个没什么好说的,默认就好了。
⑦ 结果预览
生成后的图片会显示在这里。这里有一个叫filename_prefix设置项目,作用是设置生成图片的前缀。如果你出图比较多,要区分不同的前缀,可以在这里改,一般不用动它。
⑧操作面板
这个面板刚打开的时候可能吸附在右上角,你可以拖动到任意位子。
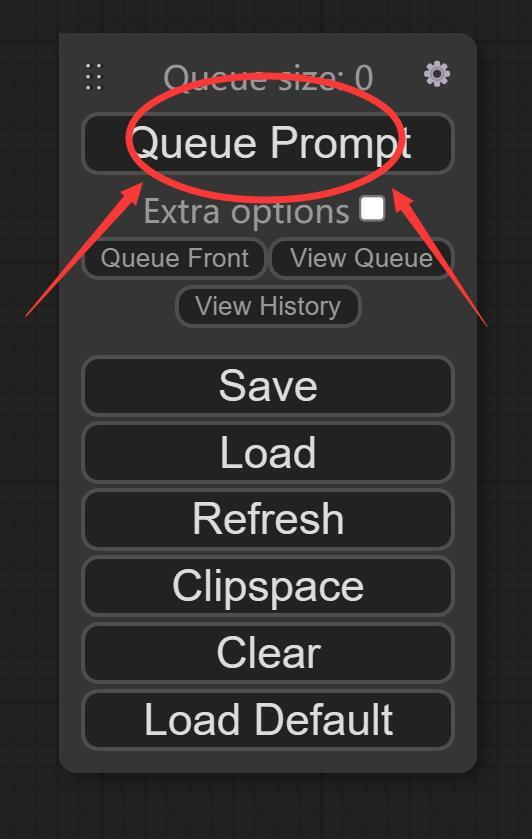
这个面板上其实只要关注Queue Prompt就好了。在设置好所有参数之后,点击这个按钮就会开始出图了。相当于SDW的“生成” 按钮。
Save:保存当前配置
Load:加载已经存在的配置
Refresh : 刷新界面
ClipSpace: 不太清楚
Clear:清除界面上的东西
Load Default : 重置界面
我们什么设置都不改直接点击“Queue Prompt” ,软件就会开始加载模型了。
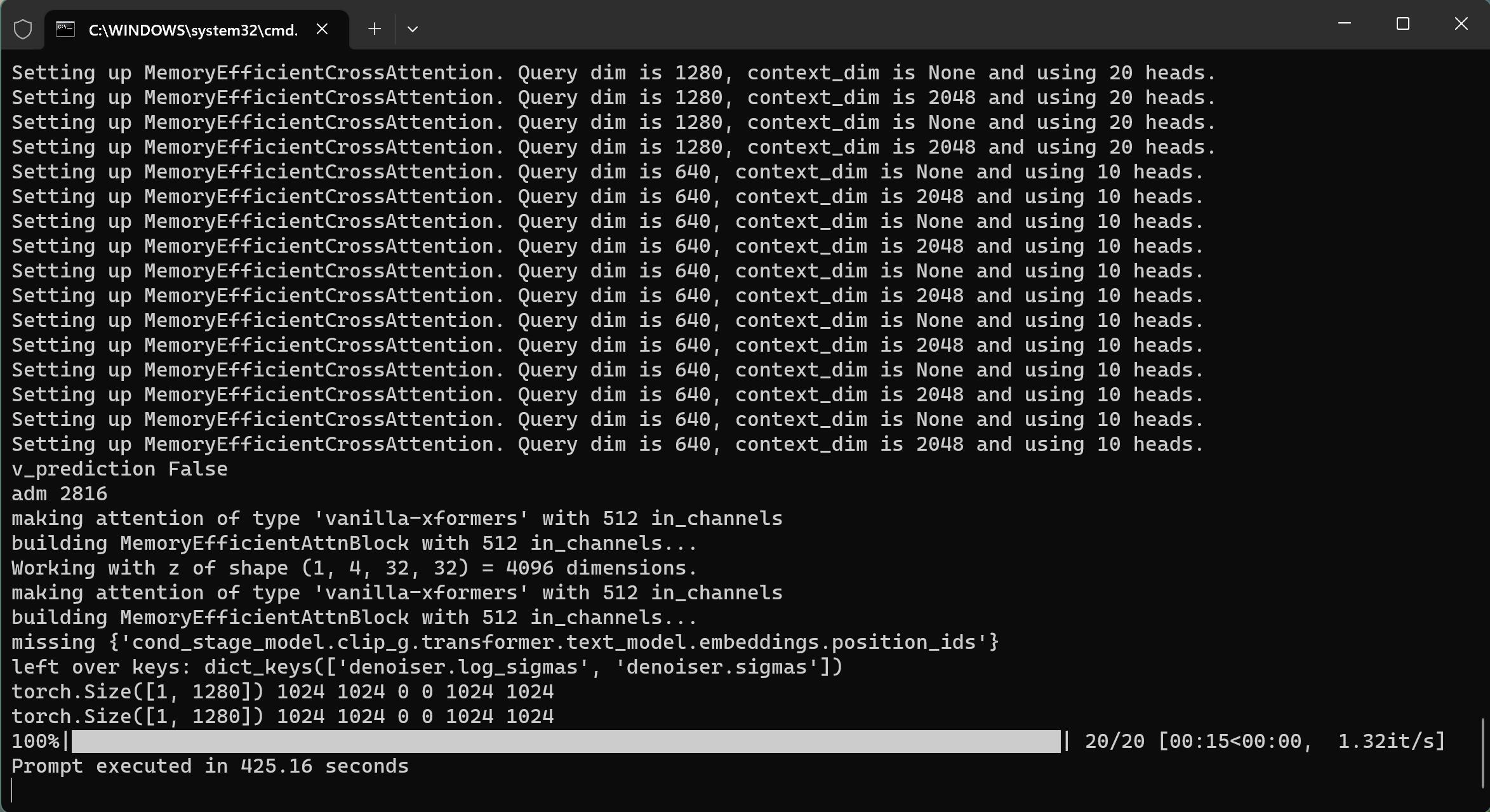
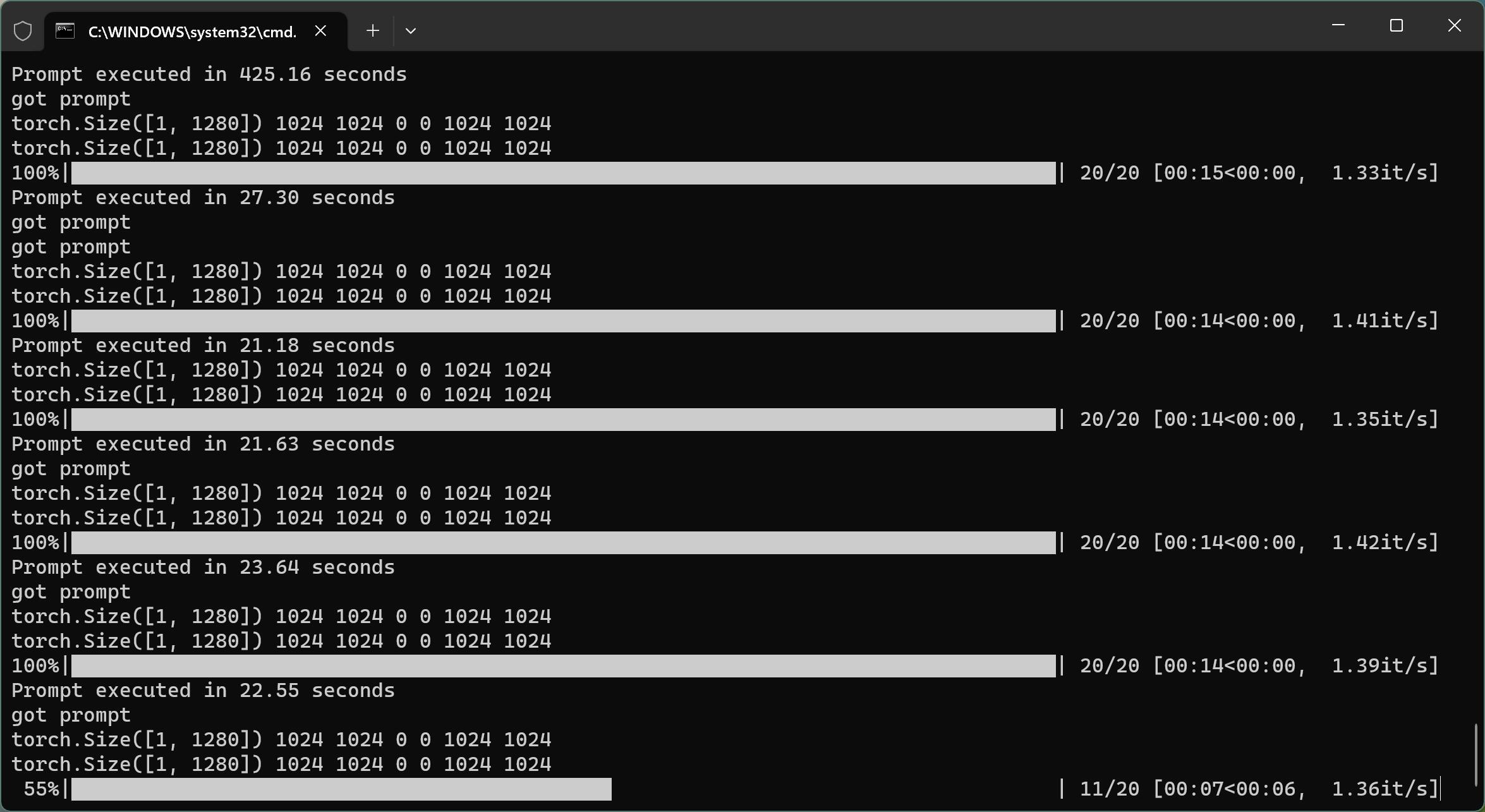
根据你的配置不同,加载时间长短不一样。比如我某一台电脑中,加载了400多秒。加载的时候,内存占用也不小。
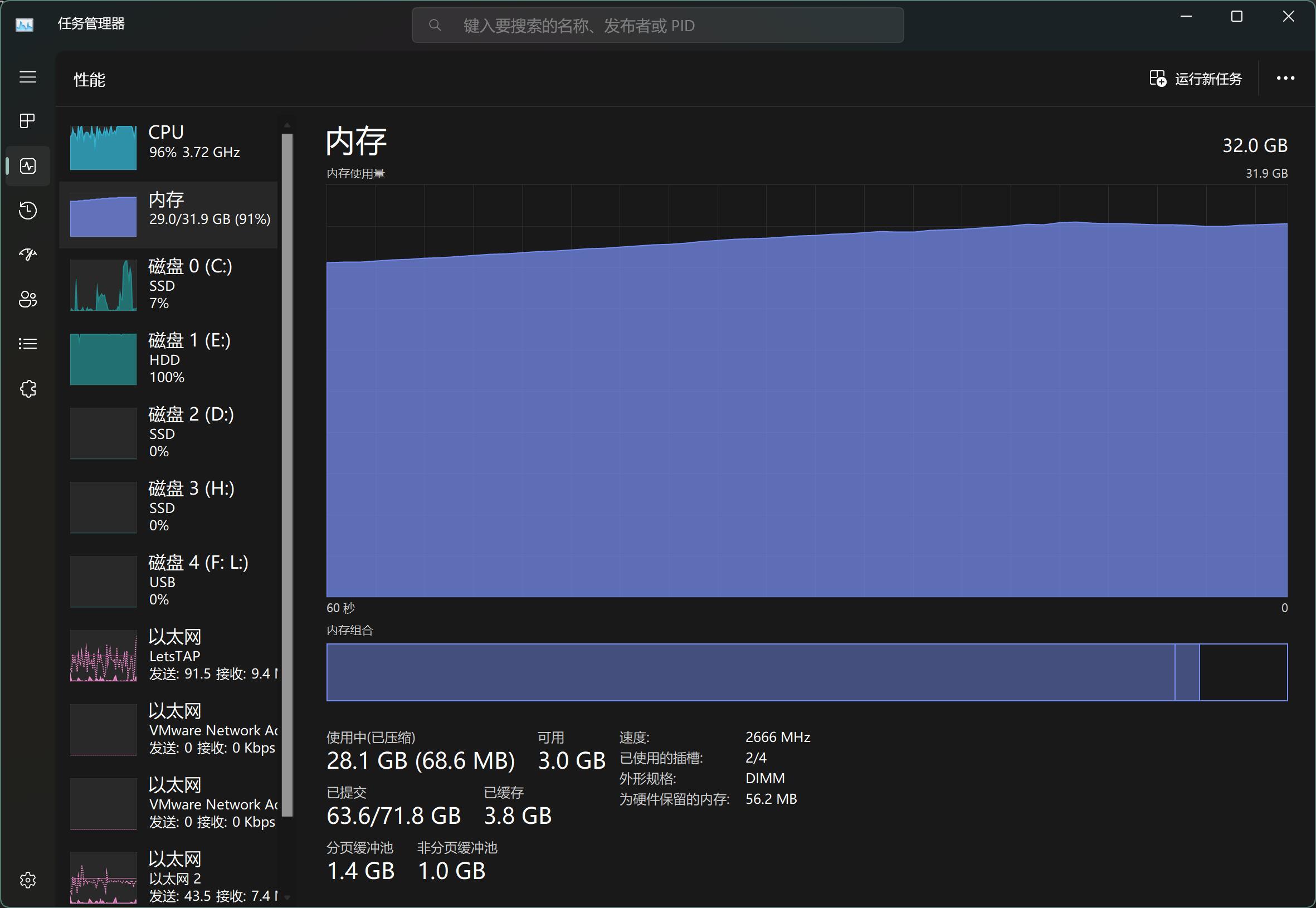
另外一台电脑就比较快,内存用的也比较少。具体是什么原因还没有排查过,可能和CPU,内存,硬盘有关系。
这个软件,会用绿色框来表示,当前的进度。绿色框在哪里,就表明运行到哪个步骤了。
第一次运行,模型加载处消耗的会消耗比较多的时间,后面出图的时候基本消耗在Ksampler这里。
虽然模型很大,但是软件出图的时间也还好,3060上大概在10几秒。
软件默认的提示词应该是“beautiful scenery nature glass bottle landscape, , purple galaxy bottle,” 大概就是生成一个紫色的“星空瓶”(这个名字是我们家娃说的)。
如果不是这个提示词,可以点击“Load Default” ,就会自动设置好所有参数了,包括提示词。
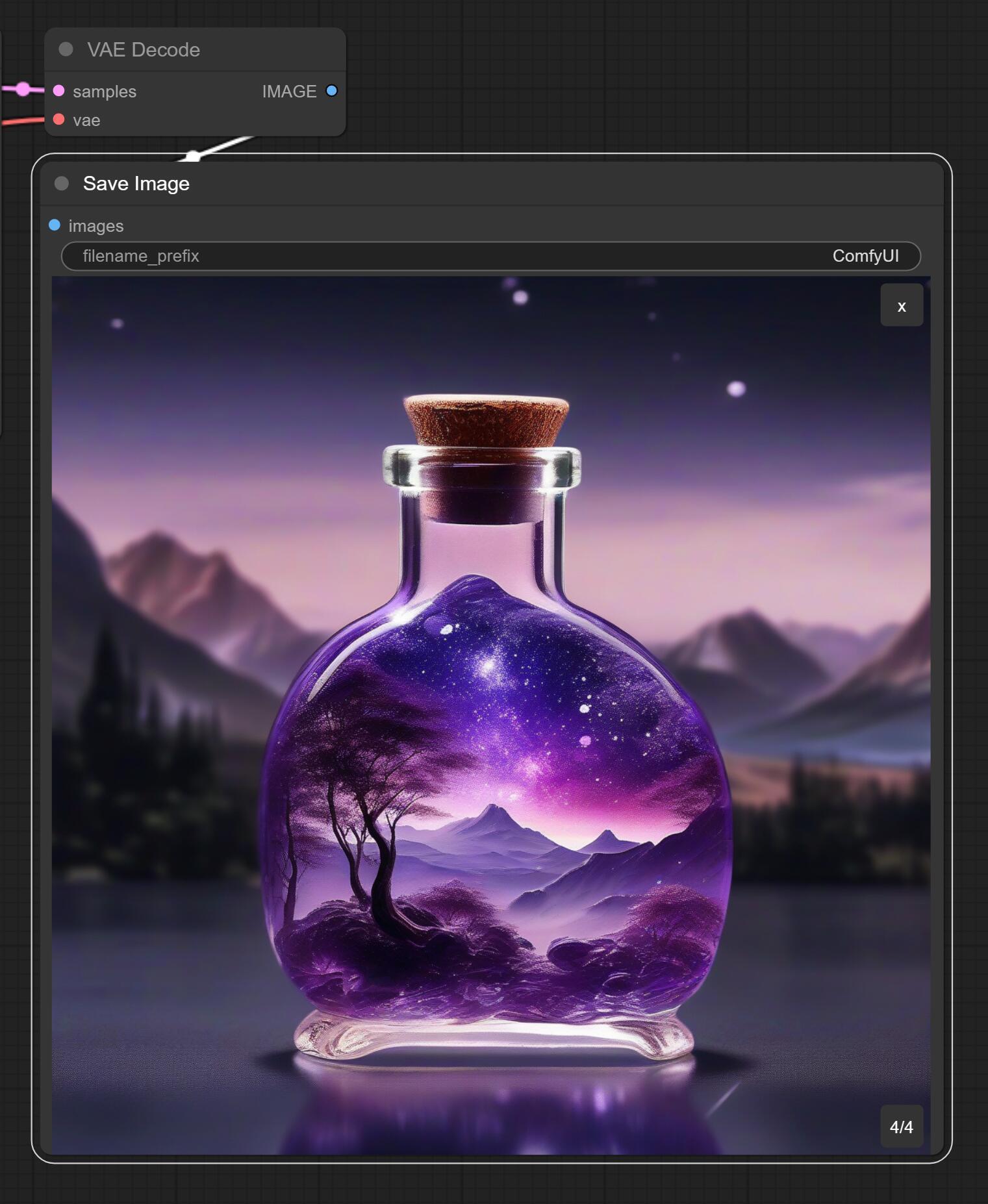
生成之后,拖动边角,可以改变这个图片的大小。到这一步,我们就算是已经用上XSDL0.9版本了,等1.0出来之后,只要把模型加进来就可以了。
另外,尝试了一下昨天的关键词“一个在火星上骑着白马的宇航员” ,出效果的稳定性感觉上没有1.0版机器人高,但是也能出类似的图片。


这是全部参数默认,没有加任何附加内容的效果图!后面配套和攻略出来了,应该还会有巨大的提升。
另外,这个软件还能和SDW配合使用,只要在配置文件里面做一个简单的配置。
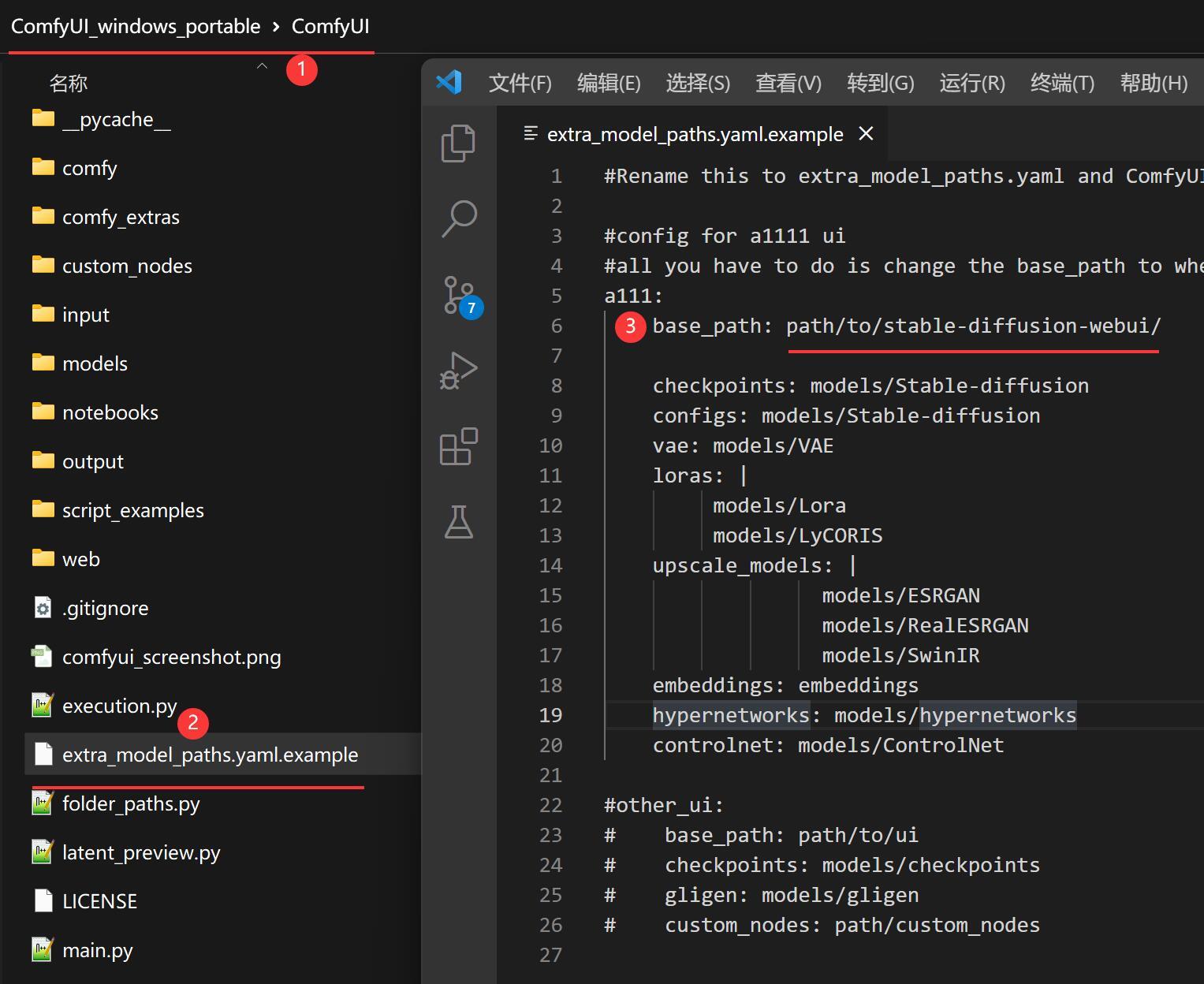
找到extra_model_paths.yaml.example文件,打开,修改里面的base_path。把这个地址改成你SDW文件所在地址。
设置完成后,保存文件,把.example后缀去掉。
然后重新启动ComfyUI就可以读取SDW里面的模型文件了。
这样就不需要把模型搬来搬去了。
好了, 该说的都说了。
我相信只要电脑配置够,人人都能玩起来。
ComfyUI是官方提供一键运行包,用起来相当方便。
最后,大家可以活动一下手指。
把点赞,在看,分享都点一点咯!!!
最后提醒一下,发送“SDXL” 即可获取软件和模型~~



















 893
893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









