




1、了解
java 解决的是高并发问题,大数据解决的是海量数据存储与分析问题。
可以理解为国内版的Sqoop。
但是比Sqoop要快,Sqoop底层是MR(Map任务),基于磁盘的,DataX基于内存的,所以速度比较快。
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、SQL Server、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS 等各种异构数据源之间高效的数据同步功能。
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
关系型数据库的数据都是结构化的,排列非常整齐
非关系型数据库都是非结构化的,非常的错乱。(异构)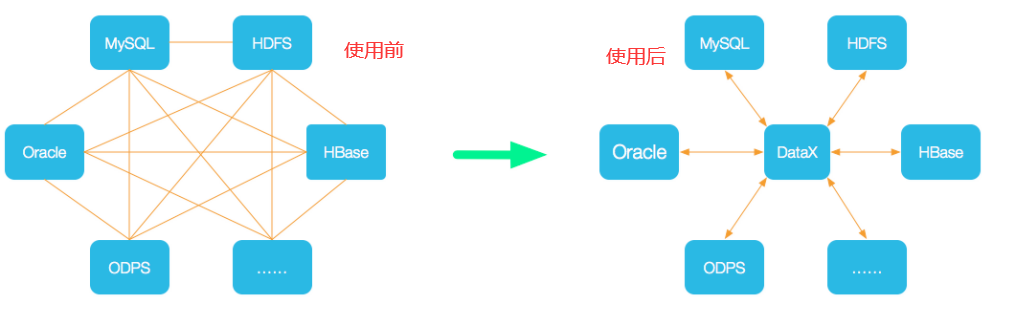
2、下载地址
此前已经开源DataX1.0版本,此次介绍为阿里云开源全新版本DataX3.0,有了更多更强大的功能和更好的使用体验。Github主页地址:https://github.com/alibaba/DataX
DataX是阿里云DataWorks数据集成的开源版本。假如github访问速度比较慢,或者访问不上,科学上网。
3、DataX3.0 框架设计

类似于之前的Flume:
source --> ReadPlugin
channel --> Channel
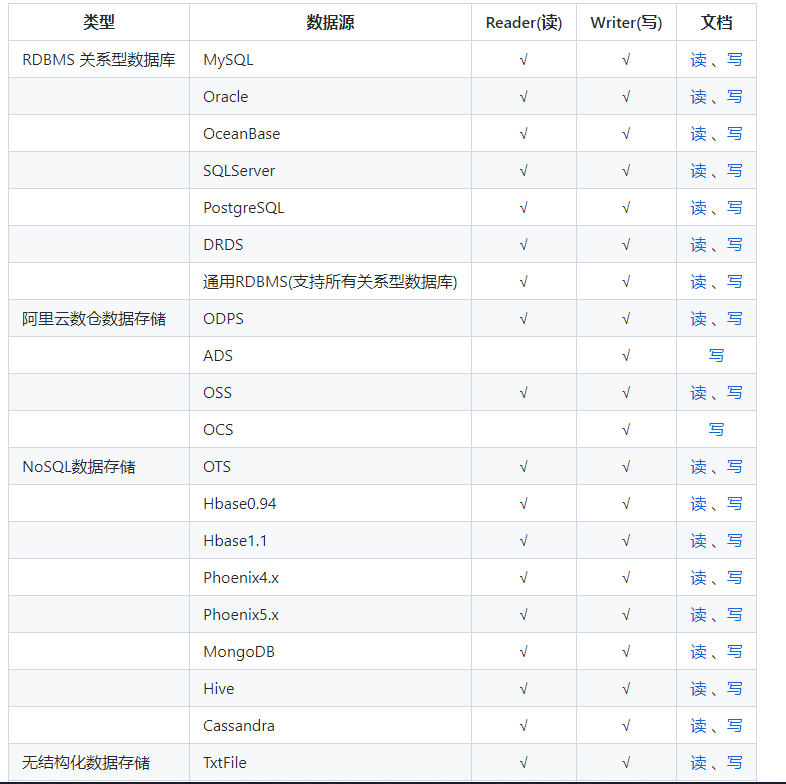
sink --> WritePlugin4、支持的数据源有哪些(几乎所有)
5、核心架构
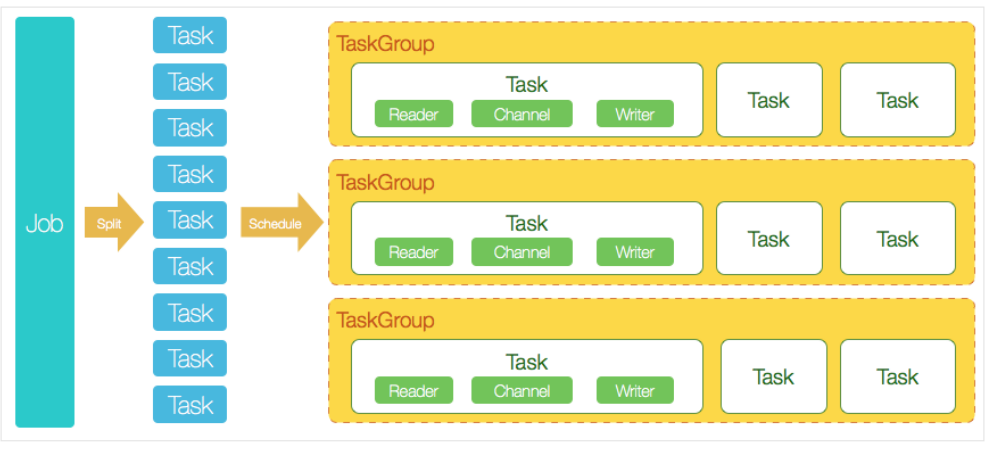
datax中的数据导入导出,是并行执行的,并且是基于内存的,所以比较快!6、安装
1、上传 /opt/modules
2、解压 tar -zxvf datax.tar.gz -C /opt/installs
3、修改/etc/profile
配置环境变量:
export DATAX_HOME=/opt/installs/datax
export PATH=$PATH:$DATAX_HOME/bin
source /etc/profile测试一下:
Play一下自带的案例:
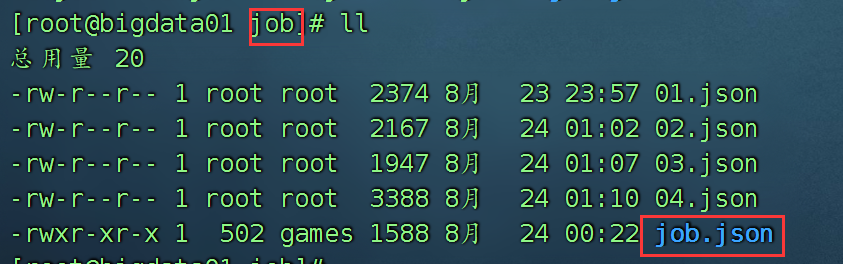
编辑这个案例:job.json文件
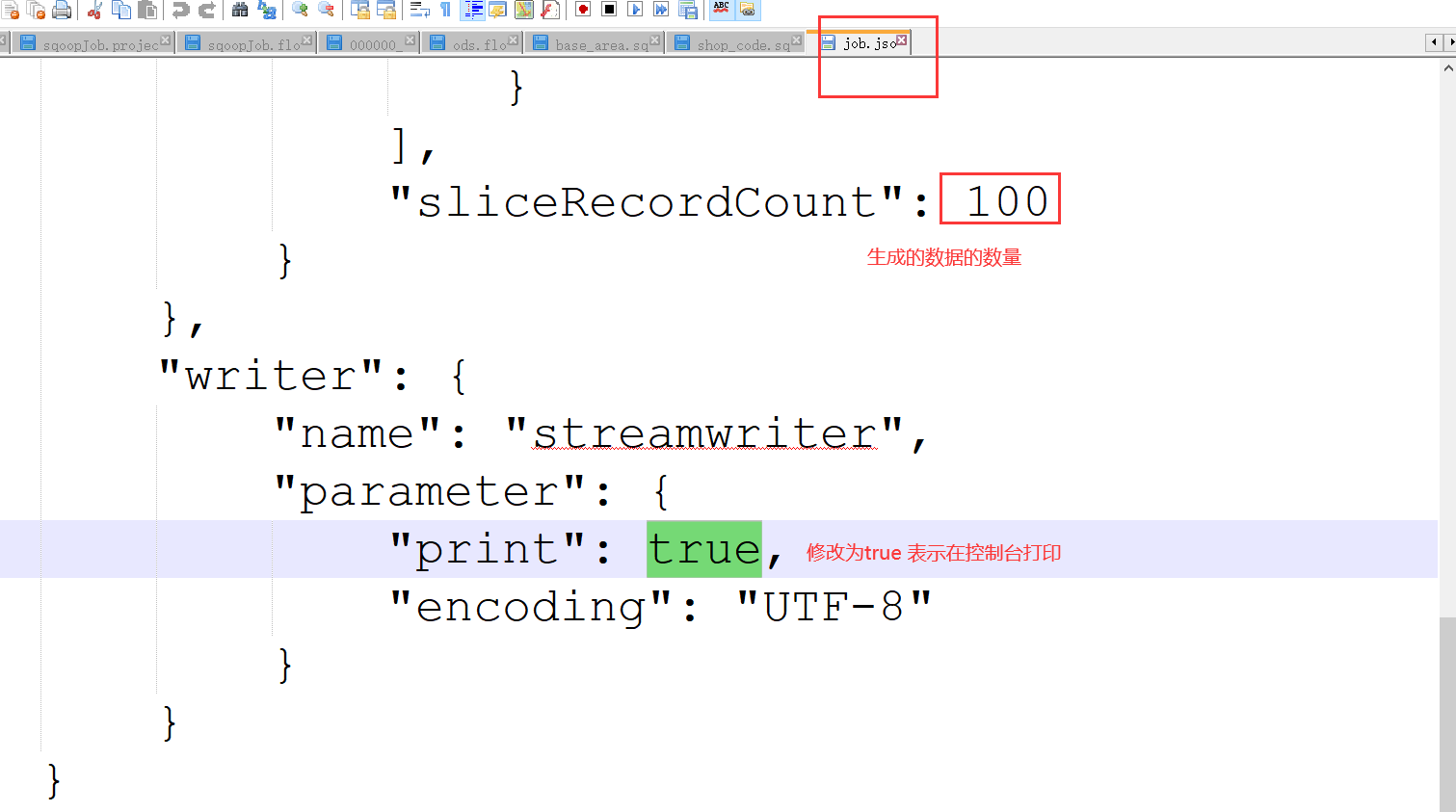
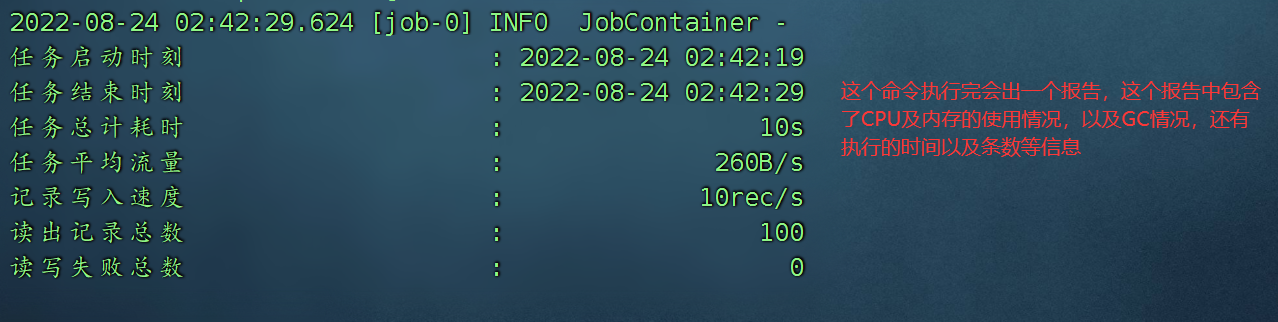
运行一下:
datax.py job.json
假如你运行报错如下:
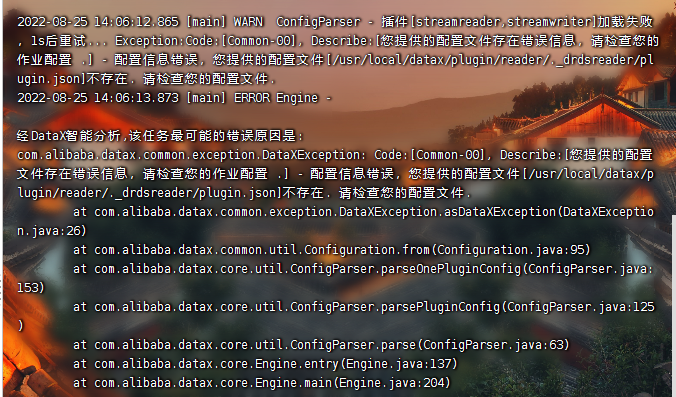
报错:
配置信息错误,您提供的配置文件[/opt/installs/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件rm -rf /opt/installs/datax/plugin/*/._*
说明运行该脚本的位置不对,找不到对应的json文件。

因为以后要链接mysql数据库,mysql数据库的驱动包少不了:
cp /opt/installs/sqoop/lib/mysql-connector-java-8.0.26.jar /opt/installs/datax/lib/7、实战
1) MySQLReader 案例
在job 文件夹 创建一个文件 mysql2stream.json ,代码如下
创建一个表,用于测试:
CREATE TABLE emp(
empno INT PRIMARY KEY,
ename VARCHAR(50),
job VARCHAR(50),
mgr INT,
hiredate DATE,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT
) ;
INSERT INTO emp VALUES(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);
INSERT INTO emp VALUES(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);
INSERT INTO emp VALUES(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);
INSERT INTO emp VALUES(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);
INSERT INTO emp VALUES(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);
INSERT INTO emp VALUES(7698,'BLAKE','MANAGER',7839,'1981-05-01 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











