







一、项目介绍
1、项目背景
现在是互联网的时代, 每个人的生活中都会使用到互联网的各种应用, 我们会进行网络购物, 会进行新闻浏览, 视频浏览, 微信聊天等等, 当我们在使用互联网的时候, 我们的所有的数据都需要通过运行商(电信, 移动,联通)进行数据的发送和接收, 对于每一个访问, 运营商都可以获取到对应的请求信息, 我们可以通过对网络请求的信息分析, 及时掌握互联网的动态和行业前沿, 并且根据用户的请求访问数据, 我们可以分析互联网行业的发展现状和每个城市的互联网的发展程度等等. 通过对于互联网的发展的相关指标分析, 可以为政府部门, 商业公司提供一些决策分析的数据。
离线数仓:spark + hive
实时数仓:flink
2、项目的价值
1)企业价值
- 为相关统计部门提供数据支持, 比如上网的用户时长, 上网的用户人数, 上网模式的占比等等
- 为行业发展的预测提供数据支撑
- 为企业发展提供数据支撑, 分析每个网站的访问情况
2)学习价值
- 完整的大数据项目实战流程
- 最新的大数据生态技术 Hadoop3.1.3, Spark3, Hive3.1.2
- 数据仓库的设计和建设
3、项目的最终效果
4、项目的系统流程分析
大数据平台开发 -- 帮助企业自研大数据平台
数仓(离线数仓、实时数仓)
BI工程师 (报表开发) 数据分析
ETL工程师
大数据运维
售前工程师(技术专家)
5、数据格式说明

完整一条日志记录格式
{
"client_ip": "139.212.175.95",
"device_type": "mobile",
"time": 1659959785000,
"type": "5G",
"device": "cf287649b5b1443c903b7405fa08cb07",
"url": "https://www.yy.com/travel"
}二、大数据环境搭建
Vmware 是什么? 帮助我们在windows上安装另一个操作系统的软件。(虚拟盒子virtual Box,mac系统 pd)
Centos7.xxxx.iso --> 镜像文件,类似于操作系统安装盘
以下这个图是centos安装过之后的系统,只能打开。
1、集群规划
安装jdk的时候,先安装biz01,然后将其拷贝到hadoop01~03上。
jps命令如果识别不了,是jdk的问题。
biz01上安装了mysql5.7。
搭建了大数据hadoop平台。(训练-->linux 使用越来越熟练,体会到脚本的力量)。
河南企业:牧原、蜜雪冰城、锅圈、双汇、宇通、中原银行(中原消费金融)、富士康 等。技术脱虚向实。
关于虚拟机的安装:
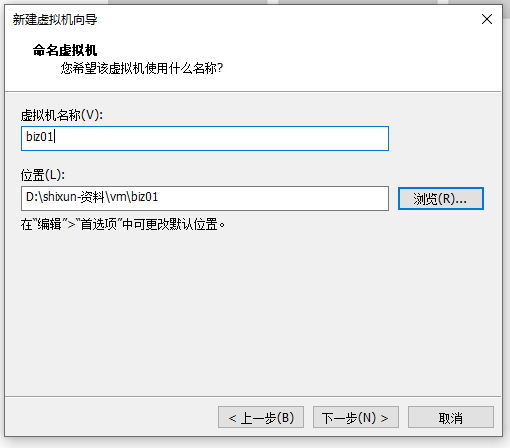
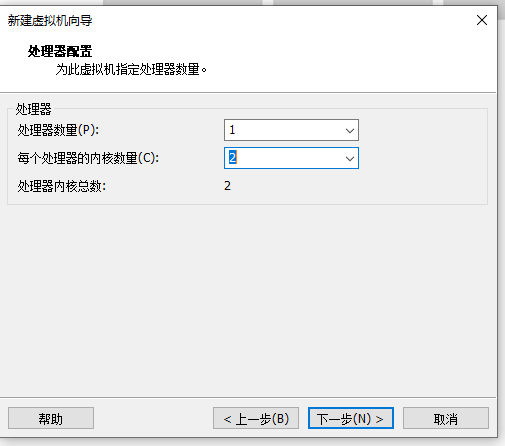
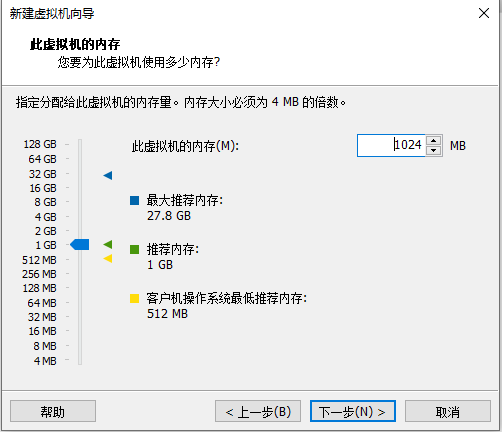
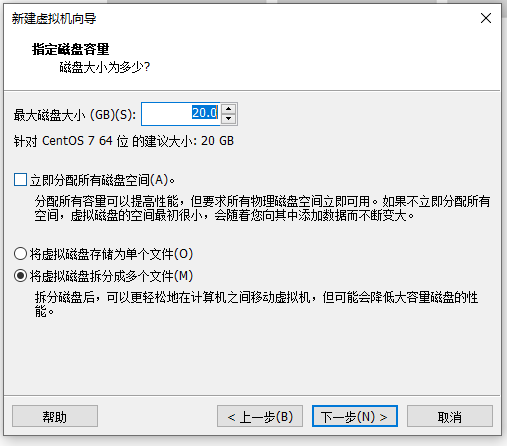
以上图:14 修改为114
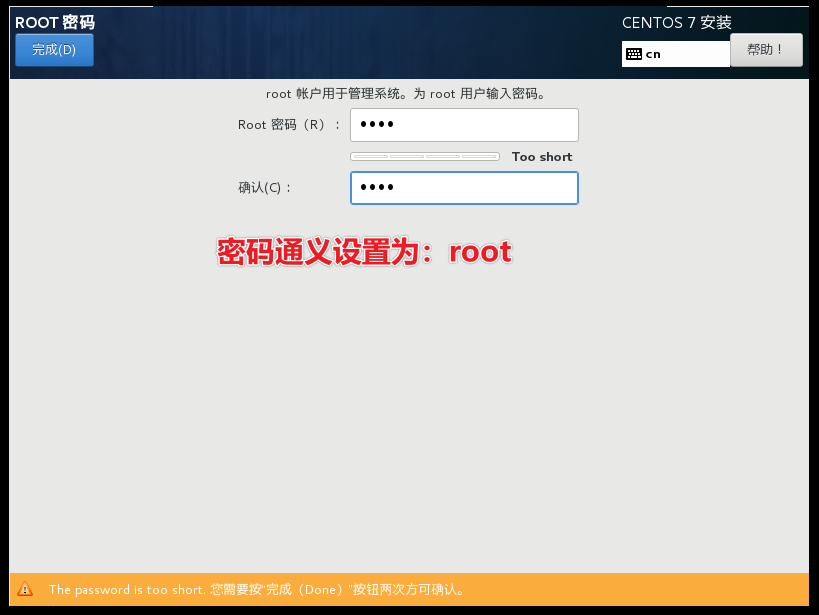
2、统一环境配置
2.1 IP地址设置
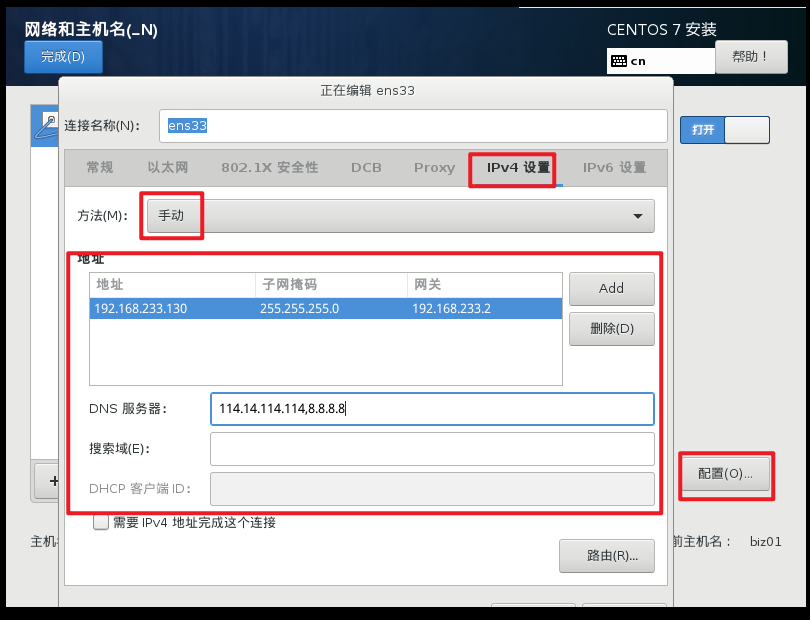
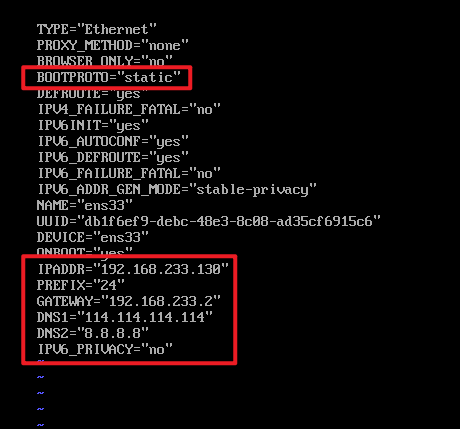
- 修改Ip地址
vi /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static" # 设置为静态ip static
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
NAME="ens33" # 网卡的名称
DEVICE="ens33" # 设备的名称
ONBOOT="yes" # 设置为yes, 表示开机启动
IPADDR="192.168.233.130" # ip地址
PREFIX="24" # 子网掩码
GATEWAY="192.168.233.2" # 网关
DNS1="114.114.114.114" # DNS- 重启网络服务
systemctl restart network- 测试网络
ping www.baidu.com
如果可以ping通公网: 说明 ip地址和网关都配置正确
如果通过 ip addr 不能查看到ip地址, 说明配置有错误
如果可以ping通内网 192.168.46.1 但是不能ping通外网的话, 则说明网关配置有错误
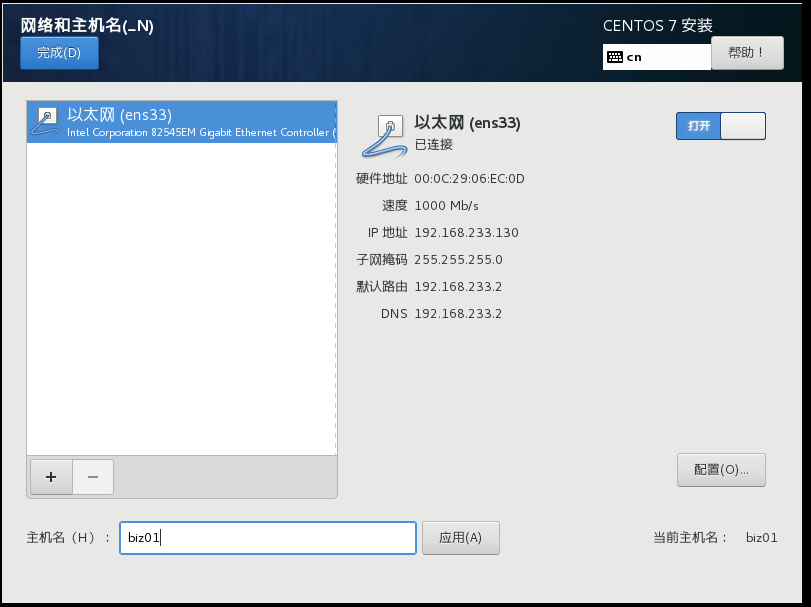
ctrl + c 退出2.2 设置主机名
- 编辑主机名配置文件
vi /etc/hostname
hadoop012.3 设置域名映射解析
- 编辑hosts文件
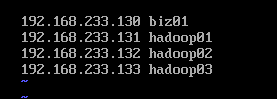
vi /etc/hosts
192.168.46.145 hadoop01 hadoop01
192.168.46.146 hadoop02 hadoop02
192.168.46.147 hadoop03 hadoop03
192.168.46.148 biz01 biz01
2.4 关闭防火墙和Selinux
- 关闭防火墙
systemctl stop firewalld 停止防火墙
systemctl disable firewalld 开机不启动防火墙- 关闭Selinux
vi /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disabled
# SELINUXTYPE= can take one of three values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
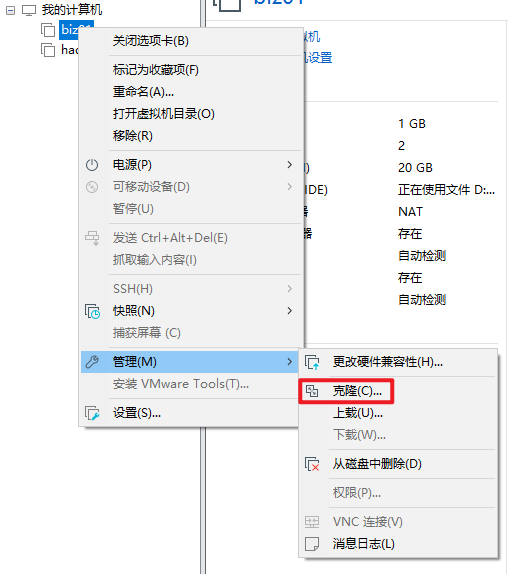
SELINUXTYPE=targeted至此第一台服务器设置完成,进行克隆clone
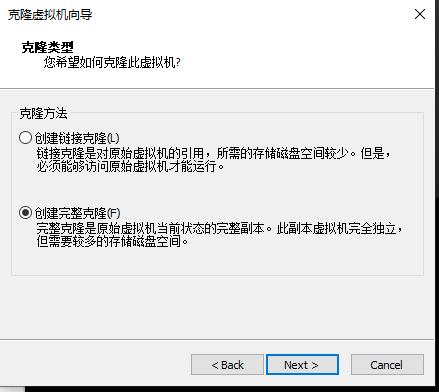
2.4.1 三台服务器的克隆
将第一台关闭,然后右键,克隆
修改hadoop01、hadoop02、hadoop03 的ip 以及主机名
vi /etc/sysconfig/network-scripts/ifcfg-ens33 修改ip
修改完之后记得重启网络 systemctl restart network
修改主机名 vi /etc/hostname --> hadoop01
reboot 重启虚拟机
hadoop02 和 03 操作都是一样的首先第一步查看自己的IP号段是多少:
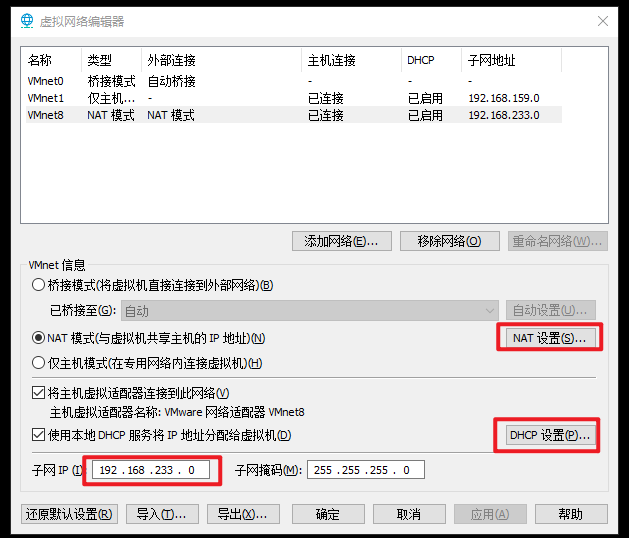
修改IP地址:
如果以上还是解决不了问题,怎么办?
2.4.2 可以使用远程连接工具连接你的虚拟机
连接四台服务器。
2.5 配置免密登录
- 在所有节点生成公钥和私钥 biz01
ssh-keygen -t rsa
后面直接所有的交互都敲回车 即可
- 拷贝公钥到每台服务器
ssh-copy-id biz01
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03
- 验证ssh登录
ssh hadoop01
exit # 退出ssh登录
ssh-keygen -t rsa
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop032.6 配置服务器节点时钟同步
- 在所有节点安装ntpdate
yum install -y ntpdate
ntpdate time1.aliyun.com
- 同步时间脚本
#!/bin/bash
# 定义阿里云 NTP 服务器地址
ALI_NTP_SERVER="ntp1.aliyun.com"
# 定义要同步时间的主机列表
HOSTS=("hadoop01" "hadoop02" "hadoop03")
for host in "${HOSTS[@]}"; do
echo "Syncing time on $host"
ssh -n $host "ntpdate -u ${ALI_NTP_SERVER}"
donechmod u+x sync-date.sh如果有问题,请修改为阿里云的yum地址:
修改阿里云的镜像文件:
1、cd /etc/yum.repos.d/
2、备份⼀下:mv CentOS-Base.repo CentOS-Base.repo.bak
3、下载阿⾥云镜像到本地:
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
4、清除yum的缓存
yum clean all
yum makecache
5、yum install -y ntpdate2.7 安装常用软件
在四台虚拟机上全部运行如下命令,下载软件。
yum install -y vim
yum install -y net-tools
yum install -y lrzsz
yum install -y rsync
yum install -y wget2.8 创建统一目录
在四台虚拟机上全部运行如下命令:
mkdir -p /bigdata/{soft,server}
/bigdata/soft 安装文件的存放目录 存放软件安装包
/bigdata/server 软件安装的目录 存放软件安装的实际位置2.9 定义同步数据脚本
安装软件rsync
yum install -y rsync --因为以前安装过了,此处不需要安装
配置同步脚本[hadoop01]
mkdir /root/bin
cd /root/bin
vim xsync
#!/bin/bash
#1 获取命令输入参数的个数,如果个数为0,直接退出命令
paramnum=$#
echo "paramnum:$paramnum"
if (( paramnum == 0 )); then
echo no params;
exit;
fi
# 2 根据传入参数获取文件名称
p1=$1
file_name=`basename $p1`
echo fname=$file_name
#3 获取输入参数的绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取用户名称
user=`whoami`
#5 循环执行rsync
current=`hostname`
nodes=$(cat /root/bin/works)
for host in $nodes; do
echo ------------------- $host --------------
if [ "$host" != "$current" ];then
rsync -rvl $pdir/$file_name $user@$host:$pdir
fi
done给脚本赋权限:
chmod u+x xsync创建works文件[hadoop01]
cd /root/bin
vi works
hadoop01
hadoop02
hadoop032.10 添加环境变量【hadoop01】
vi /etc/profile.d/custom_env.sh
#!/bin/bash
#root/bin
export PATH=$PATH:/root/bin
source /etc/profile设置文件执行权限
chmod u+x /root/bin/xsync
2.11、测试同步脚本
3、 jdk环境安装 [hadoop01]
3.1 把安装的软件上传到/bigdata/soft 目录
- 解压到指定目录
-C :指定解压到指定目录
tar -zxvf /bigdata/soft/jdk-8u241-linux-x64.tar.gz -C /bigdata/server/
3.2 创建一个软链接
cd /bigdata/server
ln -s jdk1.8.0_241/ jdk1.8
3.3 配置环境变量
vi /etc/profile.d/custom_env.sh
export JAVA_HOME=/bigdata/server/jdk1.8
export PATH=$JAVA_HOME/bin:$PATH
重新加载配置文件
source /etc/profile
3.4 测试验证
java -version
3.5 同步至所有节点
# 同步到biz01, hadoop01, hadoop02, hadoop03
xsync /etc/profile.d/custom_env.sh
xsync /bigdata/server/jdk1.8.0_241
xsync /bigdata/server/jdk1.8
通过如下命令同步软件到biz01 下:
scp -r /etc/profile.d/custom_env.sh biz01:/etc/profile.d/custom_env.sh
scp -r /bigdata/server/jdk1.8.0_241 biz01:/bigdata/server/jdk1.8.0_241
在biz01 创建软链接
cd /bigdata/server
ln -s jdk1.8.0_241/ jdk1.84、MySQL数据库安装
4.1 卸载已经安装的MySQL数据库
## 查询MySQL相关的依赖
rpm -qa |grep mysql
rpm -qa | grep mariadb
## 如果存在, 则通过rpm -e --nodeps 进行卸载
rpm -e mariadb-libs-5.5.56-2.el7.x86_64 --nodeps4.2 获取rpm在线安装仓库文件[/bigdata/soft]
cd /bigdata/soft
wget https://dev.mysql.com/get/mysql80-community-release-el7-6.noarch.rpm4.3 安装mysql的仓库文件
rpm -ivh mysql80-community-release-el7-6.noarch.rpm
4.4 修改mysql仓库的配置文件
cd /etc/yum.repos.d/
mysql-community.repo: 用于指定下载哪个版本的安装包
mysql-community-source.repo: 用于指定下载哪个版本的源码
`禁用8.0的版本, 启用5.7的版本`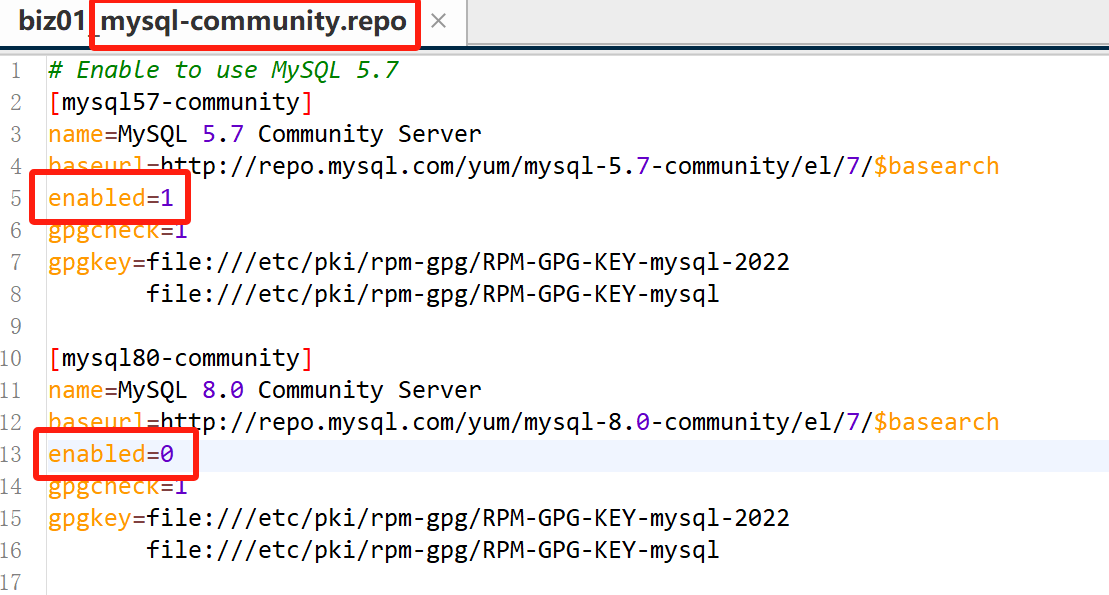
4.5 安装MySQL5.7
## 导入签名的信息key
rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022
## 安装5.7
yum install -y mysql-community-server4.6 启动数据库
systemctl start mysqld
systemctl status mysqld
systemctl enable mysqld4.7 登录数据库
## 查看初始密码
less /var/log/mysqld.log |grep pass
## 登录数据库
mysql -uroot -p
右键复制密码4.8 修改MySQL数据库密码策略
set global validate_password_length=4;
set global validate_password_policy=0;4.9 创建远程登录用户
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
#创建一个远程登录用户
create user 'root'@'%' identified by '123456';
## 设置远程登录权限
grant all privileges on *.* to 'root'@'%';
exit 退出mysql客户端4.10 设置服务器编码为utf8
vi /etc/my.cnf
## 在mysqld下面设置
character_set_server=utf8
## 重启服务
systemctl restart mysqld可以使用一些mysql的客户端软件,比如 SQLog、Navicat MySQL、DataGrip
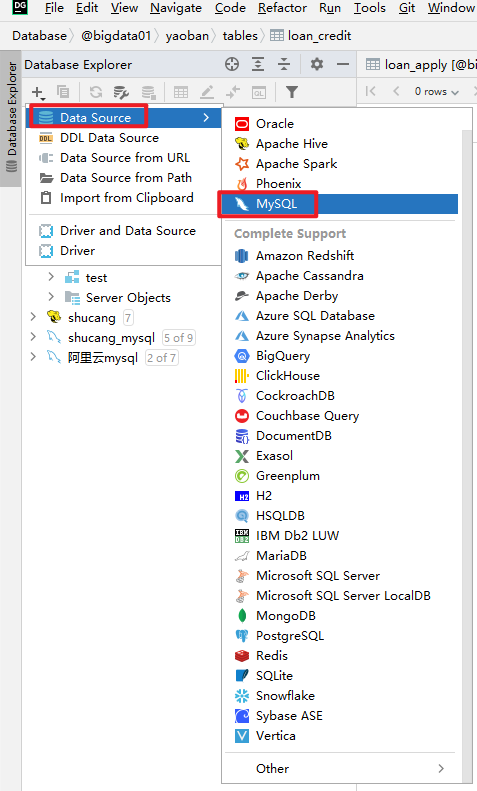
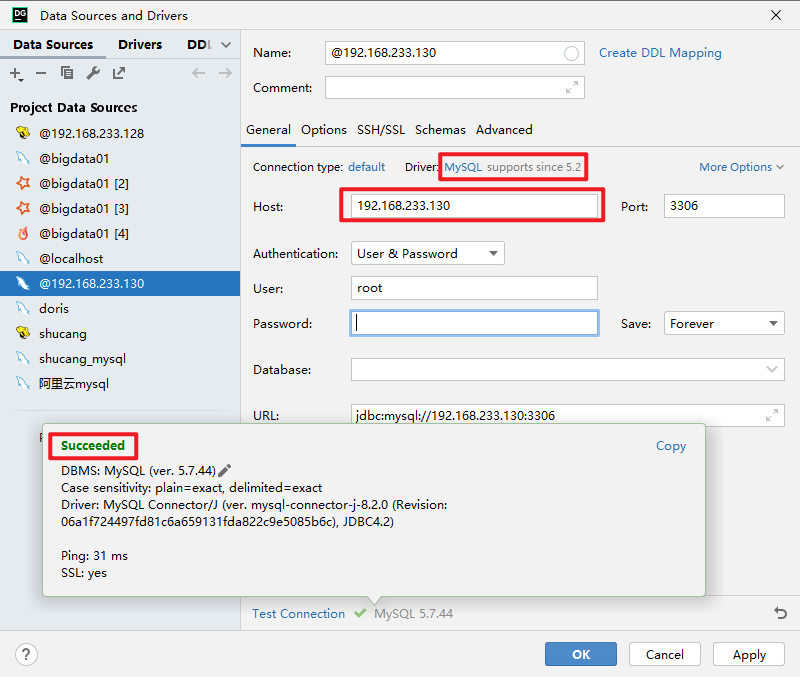
5、Hadoop集群安装
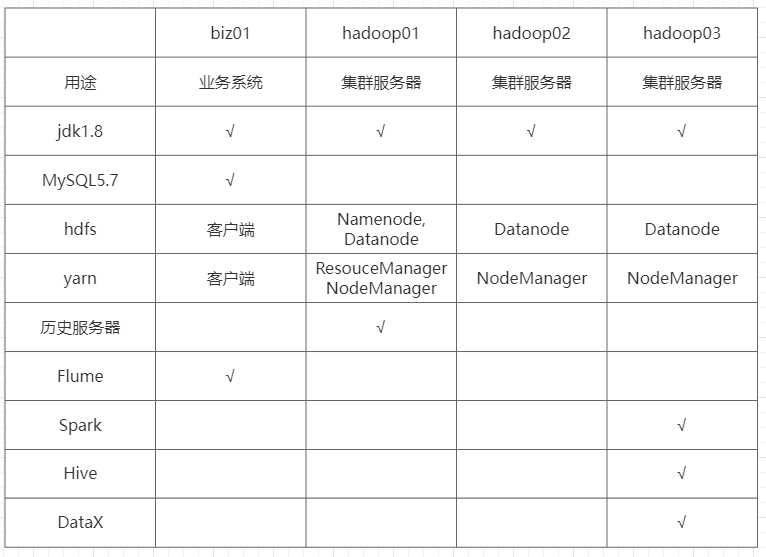
5.1 集群规划
| hadoop01 | hadoop02 | hadoop03 | |
| 角色 | 主节点 | 从节点 | 从节点 |
| NameNode | √ | ||
| DataNode | √ | √ | √ |
| ResourceManager | √ | ||
| NodeManager | √ | √ | √ |
| SecondaryNameNode | √ | ||
| Historyserver | √ |
biz01 : 安装的是mysql
hadoop01 ~ hadoop03 : 大数据集群
hadoop分为哪几部分:hdfs、yarn、mapreduce
5.2 上传安装包到hadoop01
5.3 解压到指定目录
cd /bigdata/soft
tar -zxvf /bigdata/soft/hadoop-3.3.3.tar.gz -C /bigdata/server/
5.4 创建软链接
cd /bigdata/server
ln -s hadoop-3.3.3/ hadoop
5.5 常见的Hadoop软件目录说明
| 目录 | 作用 | 说明 |
| bin/ | Hadoop最基本的管理脚本和使用脚本 | hdfs: 文件上传命令<br/>hadoop文件管理基础命令<br/>yarn: 资源调度相关<br/>mapred: 程序运行, 启动历史服务器 |
| etc/ | Hadoop配置文件的目录 | core-site.xml<br/>hdfs-site.xml<br/>mapred-site.xml<br/>yarn-site.xml |
| include/ | 对外提供的编程库头文件 | 对外提供的编程库头文件(具体动态库和静态库在lib目录中),<br />这些头文件均是用C++定义的,通常用于C++程序访问HDFS或者编写MapReduce程序 |
| lib/ | 动态库和静态库 | 该目录包含了Hadoop对外提供的编程动态库和静态库,<br />与include目录中的头文件结合使用。 |
| libexec/ | shell配置文件 | 各个服务对用的shell配置文件所在的目录,<br />可用于配置日志输出、启动参数(比如JVM参数)等基本信息。 |
| sbin/ | Hadoop管理命令 | 主要包含HDFS和YARN中各类服务的启动/关闭脚本 |
| share/ | 官方自带示例 | Hadoop各个模块编译后的jar包所在的目录 |
5.6 Hadoop配置文件修改
Hadoop安装主要就是配置文件的修改,一般在主节点进行修改,完毕后scp分发给其他各个从节点机器。
下面文件的操作目录:/bigdata/servers/hadoop/etc/haddop下,不要弄错。
5.6.1 hadoop-env.sh
文件中设置的是Hadoop运行时需要的环境变量。JAVA_HOME是必须设置的,即使我们当前的系统中设置了JAVA_HOME,它也是不认识的,因为Hadoop即使是在本机上执行,它也是把当前的执行环境当成远程服务器。
vim hadoop-env.sh
54行的JAVA_HOME的设置
export JAVA_HOME=/bigdata/server/jdk1.8
在文件末尾添加如下内容
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
5.6.2 core-site.xml
hadoop的核心配置文件,有默认的配置项core-default.xml。core-default.xml与core-site.xml的功能是一样的,如果在core-site.xml里没有配置的属性,则会自动会获取core-default.xml里的相同属性的值。
cd /bigdata/server/hadoop/etc/hadoop/
vim core-site.xml
在文件的configuration的标签中添加以下内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/bigdata/data/hadoop</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>5.6.3 hdfs-site.xml
HDFS的核心配置文件,有默认的配置项hdfs-default.xml。
hdfs-default.xml与hdfs-site.xml的功能是一样的,如果在hdfs-site.xml里没有配置的属性,则会自动会获取hdfs-default.xml里的相同属性的值。
cd /bigdata/server/hadoop/etc/hadoop/
vim hdfs-site.xml
<!-- 指定secondarynamenode运行位置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>5.6.4 mapred-site.xml
MapReduce的核心配置文件,有默认的配置项mapred-default.xml。
mapred-default.xml与mapred-site.xml的功能是一样的,如果在mapred-site.xml里没有配置的属性,则会自动会获取mapred-default.xml里的相同属性的值。
cd /bigdata/server/hadoop/etc/hadoop/
vim mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>5.6.5 yarn-site.xml
YARN的核心配置文件,有默认的配置项yarn-default.xml。
yarn-default.xml与yarn-site.xml的功能是一样的,如果在yarn-site.xml里没有配置的属性,则会自动会获取yarn-default.xml里的相同属性的值。
cd /bigdata/server/hadoop/etc/hadoop/
vim yarn-site.xml
<!-- 指定YARN的主角色(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序默认值:"" -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
</property>
<!-- 保存的时间7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>5.6.6 workers
workers文件里面记录的是集群主机名。主要作用是配合一键启动脚本如start-dfs.sh、stop-yarn.sh用来进行集群启动。这时候workers文件里面的主机标记的就是从节点角色所在的机器。
cd /bigdata/server/hadoop/etc/hadoop/
vim workers
hadoop01
hadoop02
hadoop035.7 同步hadoop软件包到hadoop02和hadoop03
第一种方式:
scp -r hadoop-3.3.3/ hadoop02:$PWD
scp -r hadoop-3.3.3/ hadoop03:$PWD
在hadoop02节点配置软链接
ln -s hadoop-3.3.3/ hadoop
在hadoop03节点配置软链接
ln -s hadoop-3.3.3/ hadoop
xsync /bigdata/server/hadoop-3.3.3
xsync /bigdata/server/hadoop5.8 [所有节点(不包含biz01)]配置环境变量
先修改hadoop01上的环境变量
vim /etc/profile.d/custom_env.sh
export HADOOP_HOME=/bigdata/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
xsync /etc/profile.d/custom_env.sh5.9 Hadoop集群启动
启动方式
要启动Hadoop集群,需要启动HDFS和YARN两个集群。注意:首次启动HDFS时,必须在主节点hadoop01对其进行格式化操作。本质上是一些清理和准备工作,因为此时的HDFS在物理上还是不存在的。
hadoop namenode -format
使用老闫说的命令执行:
所有命令都在hadoop01上执行:
start-dfs.sh 启动hdfs
start-yarn.sh 启动yarn
手动单个节点启动
在主节点hadoop01启动namenode
cd /bigdata/server/hadoop/bin
./hdfs --daemon start namenode
在hadoop02启动secondarynamenode
cd /bigdata/server/hadoop/bin
./hdfs --daemon start secondarynamenode
在所有节点启动datanode
cd /bigdata/server/hadoop/bin
./hdfs --daemon start datanode
查看进程情况
jps
netstat -ntlp
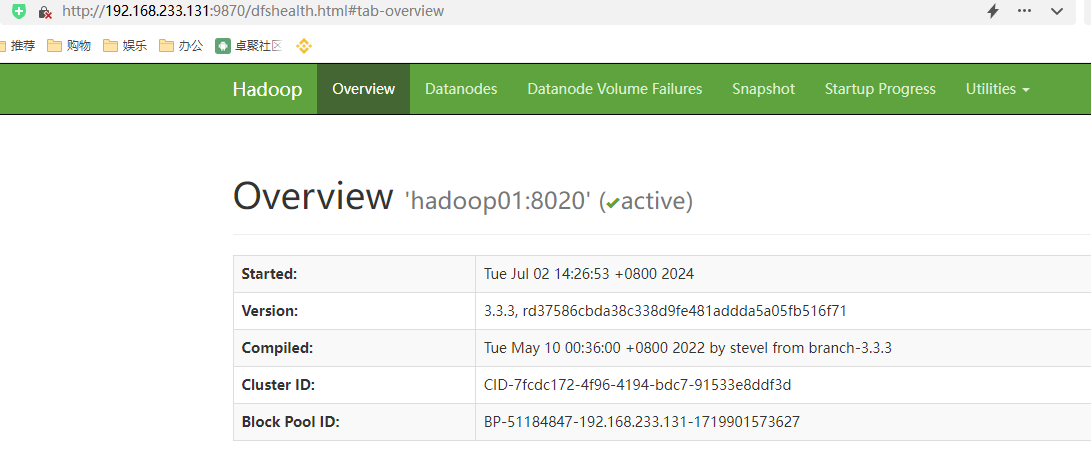
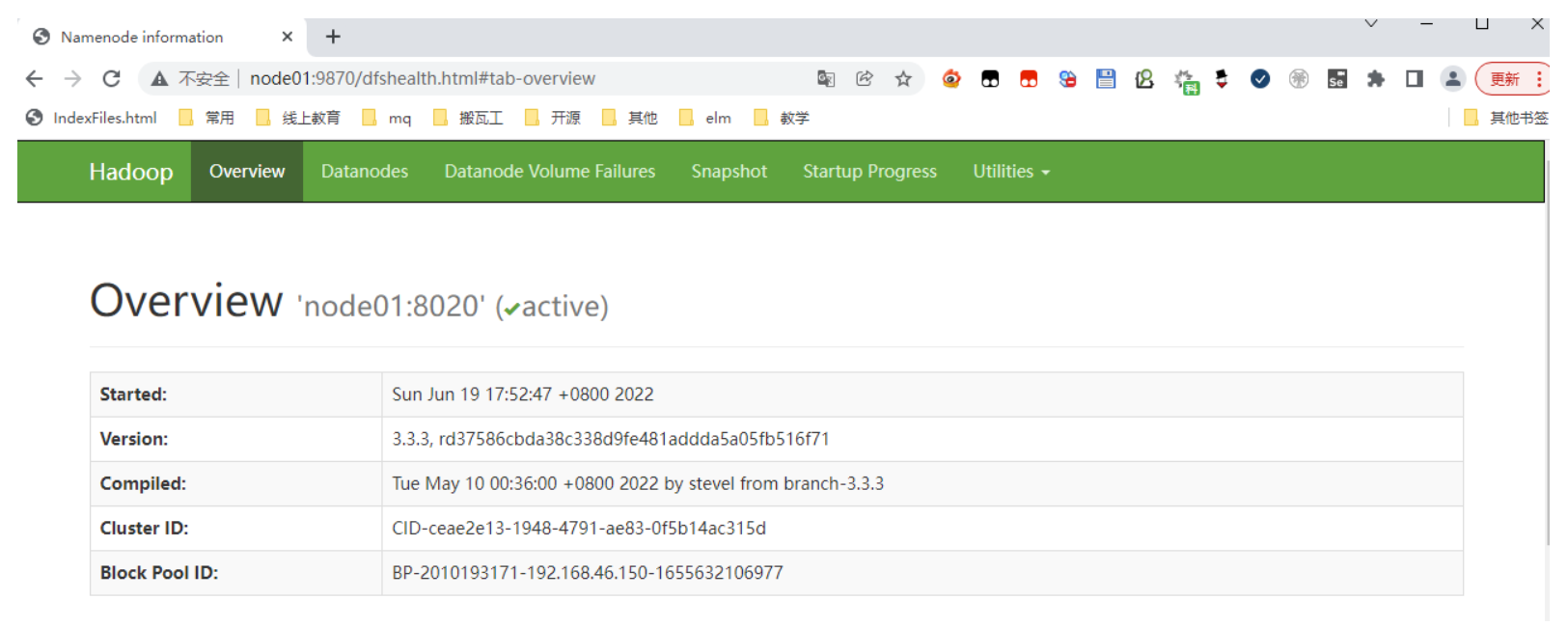
其中hdfs的web端口: hadoop01:9870已经可以正常访问
在主节点hadoop01启动ResouceManager
cd /bigdata/server/hadoop/bin
./yarn --daemon start resourcemanager
在所有节点启动Nodemanager
cd /bigdata/server/hadoop/bin
./yarn --daemon start nodemanager
如果想要停止某个节点上某个角色,只需要把命令中的start改为stop即可。
5.10 一键脚本启动
如果配置了etc/hadoop/workers和ssh免密登录,则可以使用程序脚本启动所有Hadoop两个集群的相关进程,在主节点所设定的机器上执行。
hdfs:/bigdata/server/hadoop/sbin/start-dfs.sh
yarn:/bigdata/server/hadoop/sbin/start-yarn.sh
停止脚本
hdfs:/bigdata/server/hadoop/sbin/stop-dfs.sh
yarn:/bigdata/server/hadoop/sbin/stop-yarn.sh
完整的一键启动hdfs和yarn脚本
start-all.sh: 启动所有的hdfs和yarn的脚本
stop-all.sh: 停止所有的hdfs和yarn的脚本
5.11 启动后的效果
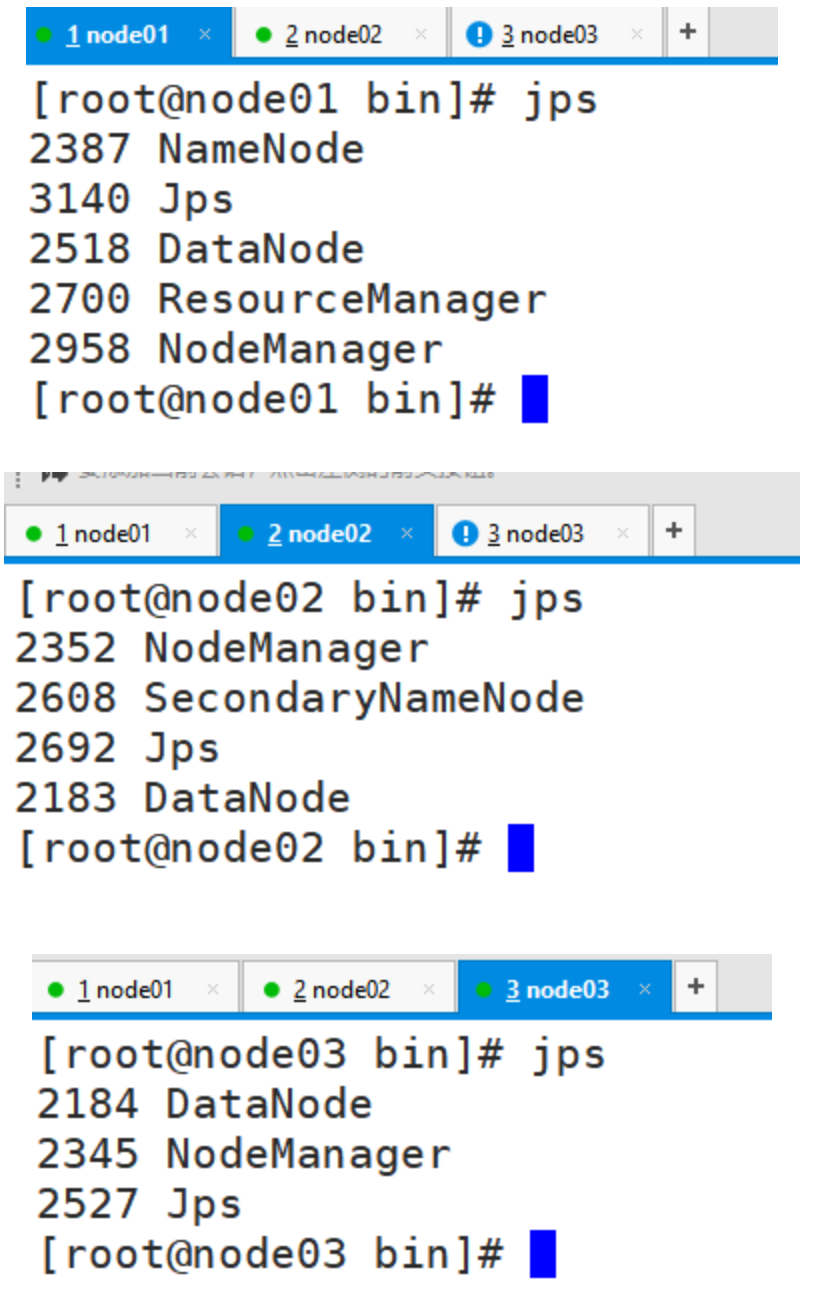
集群Web访问UI
hdfs: http://hadoop01:9870
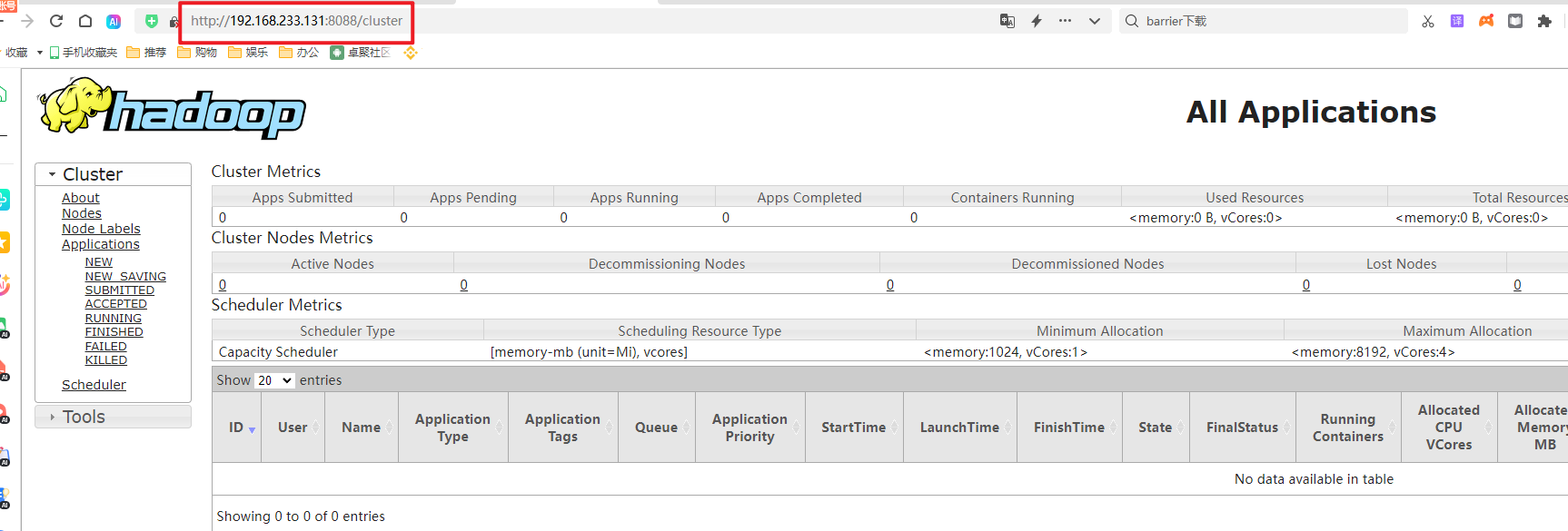
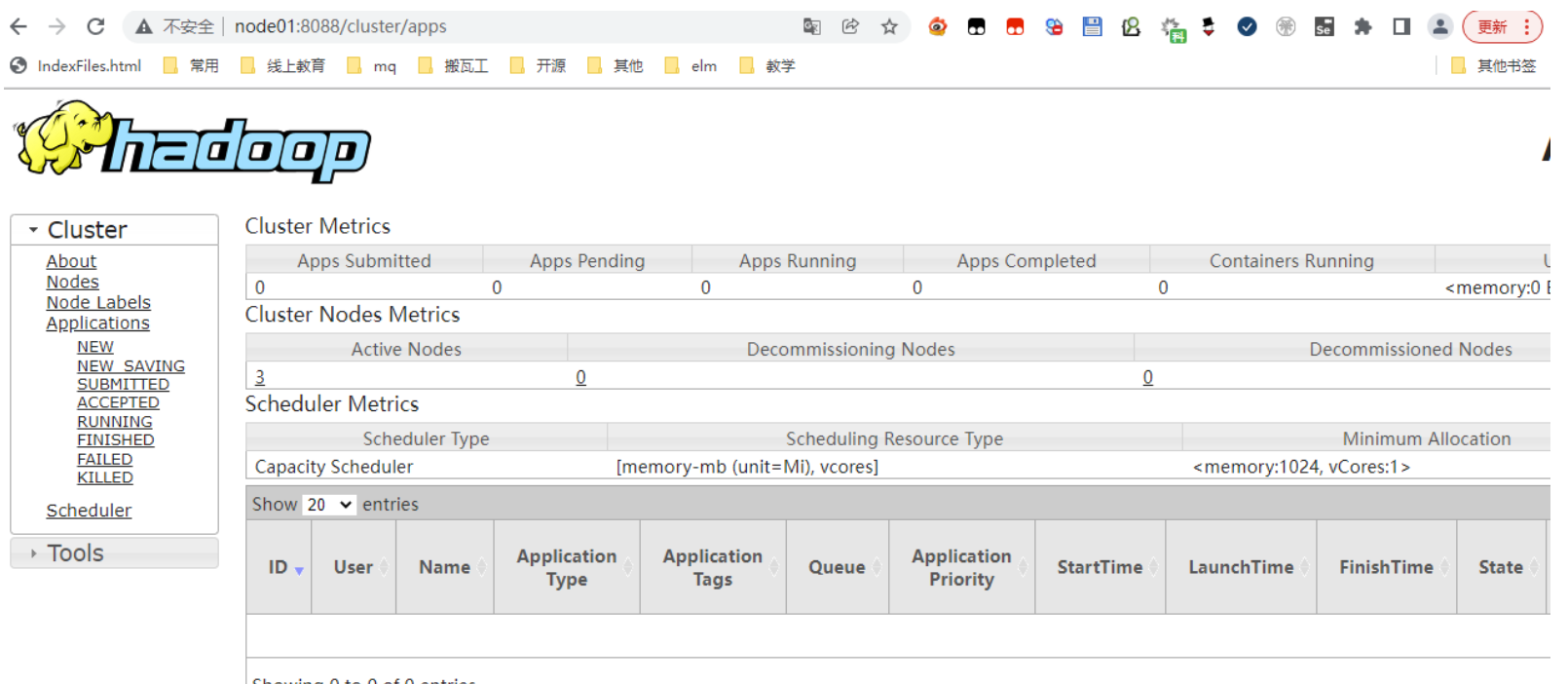
yarn:http://hadoop01:8088
以下是配置日志服务器的:
MapReduce JobHistory
JobHistory用来记录已经finished的mapreduce运行日志,日志信息存放于HDFS目录中,默认情况下没有开启此功能,需要在mapred-site.xml中配置并手动启动。
修改mapred-site.xml 【hadoop01】
cd /bigdata/server/hadoop/etc/hadoop/
vim mapred-site.xml
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop02:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop02:19888</value>
</property>第一种做法:
scp mapred-site.xml hadoop02:$PWD
scp mapred-site.xml hadoop03:$PWD
cd /bigdata/server/hadoop-3.3.3/etc/hadoop
xsync mapred-site.xml 在hadoop02节点启动JobHistory
cd /bigdata/server/hadoop/bin
./mapred --daemon start historyserver
访问web管理界面
http://192.168.233.132:19888/jobhistory
先进入:cd /root/bin
脚本的内容进行修改:
#!/bin/bash
USAGE="使用方法:sh jps-cluster.sh'"
NODES=("hadoop01" "hadoop02" "hadoop03")
for NODE in ${NODES[*]};do
echo "--------$NODE--------"
ssh $NODE "/bigdata/server/jdk1.8/bin/jps"
done
echo "-------------------------------------------"
echo "--------jps-cluster.sh脚本执行完成!--------"
chmod u+x jps-cluster.sh以后在hadoop01上,任何地方,都可以使用 jps-cluster.sh 查看整个大数据集群的所有服务。
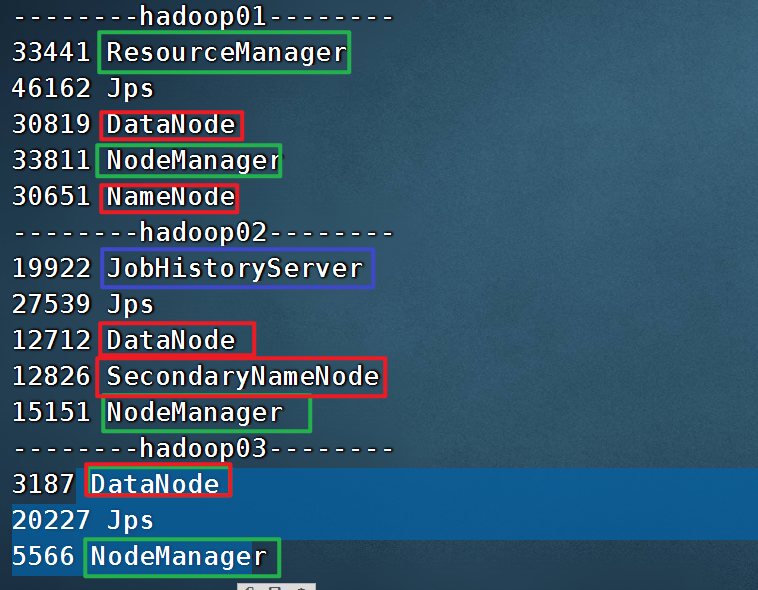
假如某个服务没有启动正常,先查看相关日志。
一定要记住:安装之前,先检查 hadoop01 是否可以免密登录到 hadoop01 02 03 上。
5.12 运行演示程序
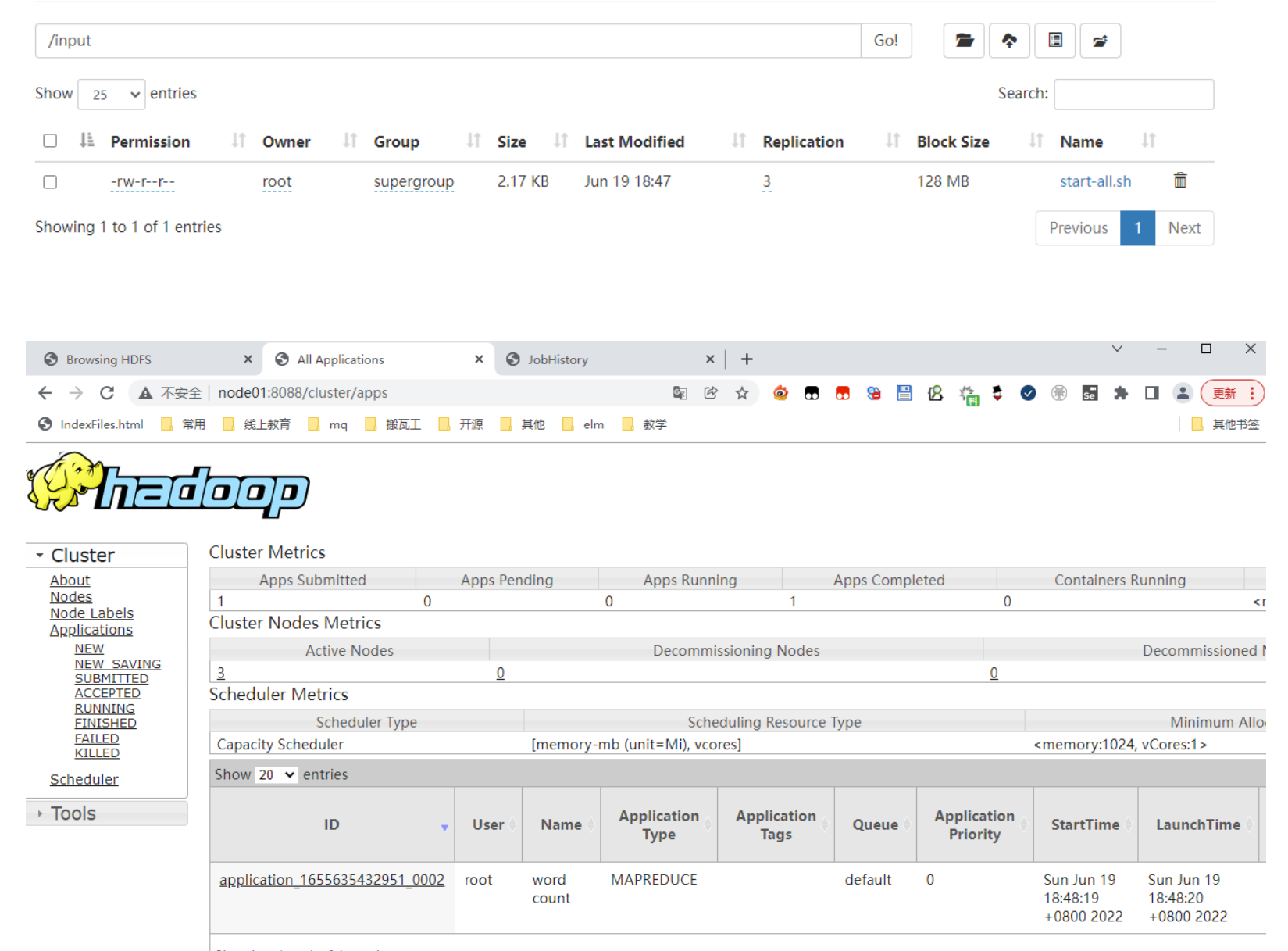
在hdfs创建一个目录:
hdfs dfs -mkdir /input
上传文件到hdfs的/input目录
hdfs dfs -put start-all.sh /input
运行示例程序
hadoop jar /bigdata/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.3.jar wordcount /input /output
三、数仓建模理论
1、OLTP和OLAP
On-Line Transaction Processing联机事务处理过程(OLTP),也称为面向交易的处理过程,其基本特征是前台接收的用户数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果,是对用户操作快速响应的方式之一。
联机分析处理OLAP是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。其中F是快速性(Fast),指系统能在数秒内对用户的多数分析要求做出反应;A是可分析性(Analysis),指用户无需编程就可以定义新的专门计算,将其作为分析的一部 分,并以用户所希望的方式给出报告;M是多维性(Multi—dimensional),指提供对数据分析的多维视图和分析;I是信息性(Information),指能及时获得信息,并且管理大容量信息. 主要是一个数据分析系统, 要求有较快的时间响应
对于我们常用的关系型数据库, 对于数据一致性要求比较高, 基本都是我们的OLTP系统
对于我们常见的数据分析系统, 主要是根据已有的业务数据进行统计分析, 比如管理驾驶舱 数据统计分析, 比如做BI报表, 做机器学习等, 这些我们会专门在一个数据分析系统OLAP系统进行统计分析
问题: 为什么不在业务系统做数据分析呢
1 数据分析会影响业务系统的效率, 降低业务系统的处理性能
2 分析系统的数据有可能来自多个业务系统和业务日志文件, 比如来自财务系统, 客户管理系统, 订单管理系统, 商城系统等
3 分析系统的设计模型和业务系统的设计模型是不一致的, 针对于分析系统, 我们会使用维度建模, 对于业务系统, 我们会使用ER建模
数据库属于 OLTP,注重事务(安全)
hive 属于OLAP: 注重分析
2、什么是数据库建模
在设计数据库时,对现实世界进行分析、抽象、并从中找出内在联系,进而确定数据库的结构,这一过程就称为数据库建模
常见的数据库建模有关系建模和维度建模
建议:在学校的时候考个中级软考证(数据库设计)--以考代评 (带国徽的证书)
数仓建模理论:关系建模(按照数据库的三范式)和 维度建模(整个企业中数仓建模的核心理论Kimball)
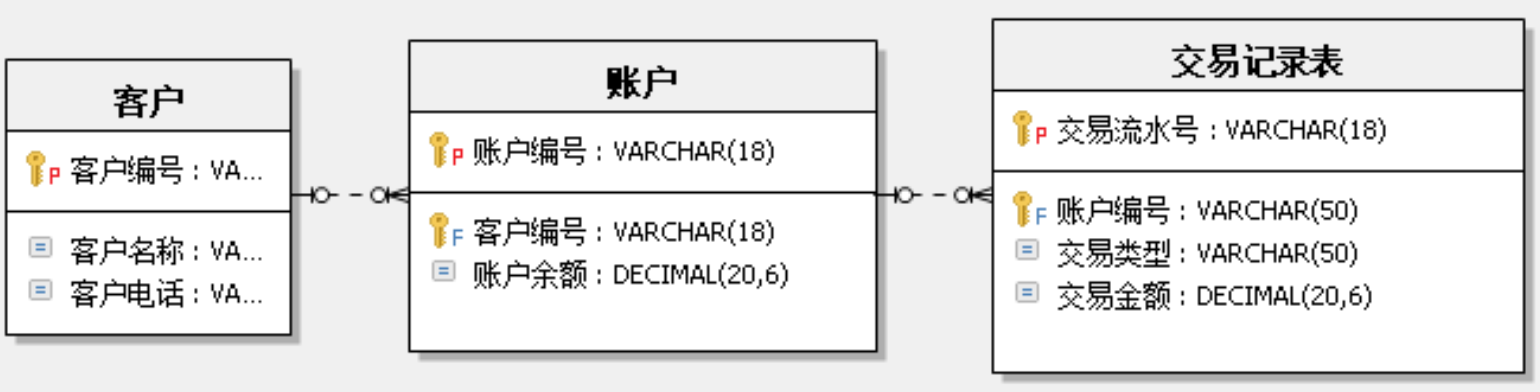
关系建模
关系建模将复杂的数据抽象为两个概念——实体和关系,并使用规范化的方式表示出来。关系模型如图所示,从图中可以看出,较为松散、零碎,物理表数量多。
关系模型严格遵循第三范式(3NF),数据冗余程度低,数据的一致性容易得到保证。由于数据分布于众多的表中,查询会相对复杂,在大数据的场景下,查询效率相对较低。
关系建模是通过准确的业务规则来描述业务运作的过程
业务规则:
1 一个客户拥有多个银行账户
2 一个银行账户只属于一个客户
3 一个银行账户会有多个银行业务交易
4 一个银行业务交易记录只属于一个银行账户
维度建模 Kimball
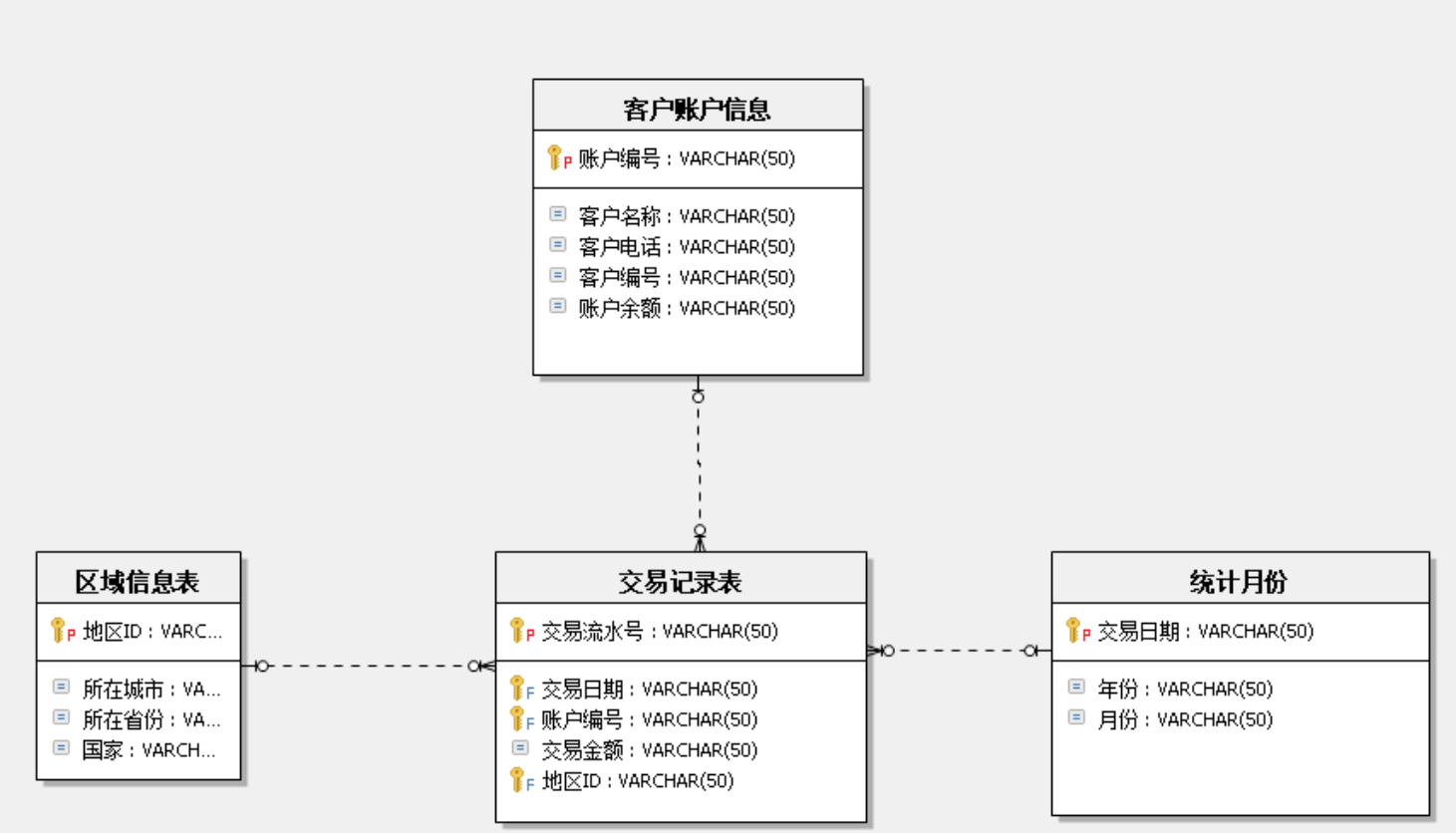
什么是维度建模:就是建模的时候分为事实表和维度表。
维度模型以数据分析作为出发点,不遵循三范式,故数据存在一定的冗余。维度模型面向业务,将业务用事实表和维度表呈现出来。表结构简单,故查询简单,查询效率较高。
维度建模是面向查询主题分析
` 维度建模是根据不同的维度进行统计分析的维度模型`
统计需求分析:
1 围绕账户交易记录表进行统计
2 根据时间(月份, 季度, 年份)进行时间维度的统计
3 根据地区(城市,省份,国家)进行对应的地区维度进行统计
4 根据账户, 客户的信息进行对应的
维度建模在OLAP的数据仓库的设计中, 为了方便我们的查询效率, 通常采用的是维度建模, 在维度建模的设计中, 我们使用的最多的
事实表
事实表是指存储有事实记录的表,如系统日志、销售记录等;事实表的记录在不断地动态增长,所以它的体积通常远大于其他表。
事实表作为数据仓库建模的核心,需要根据业务过程来设计,包含了引用的维度和业务过程有关的度量。
维度表
维度表或维表,有时也称查找表,是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联;相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。常见的维度表有:日期表(存储与日期对应的周、月、季度等的属性)、地点表(包含国家、省/州、城市等属性)等。维度是维度建模的基础和灵魂。
什么是事实表: 谁在什么时候干了一件什么事儿,这就是事实,把这个实时记录下来就是事实表。
维度表:一般是名字 ,比如年龄,籍贯,长相,爱好。
维度建模的好处是: 便于查询,查询速度快。
缺点是:数据有冗余,占用磁盘空间,是利用空间换时间。
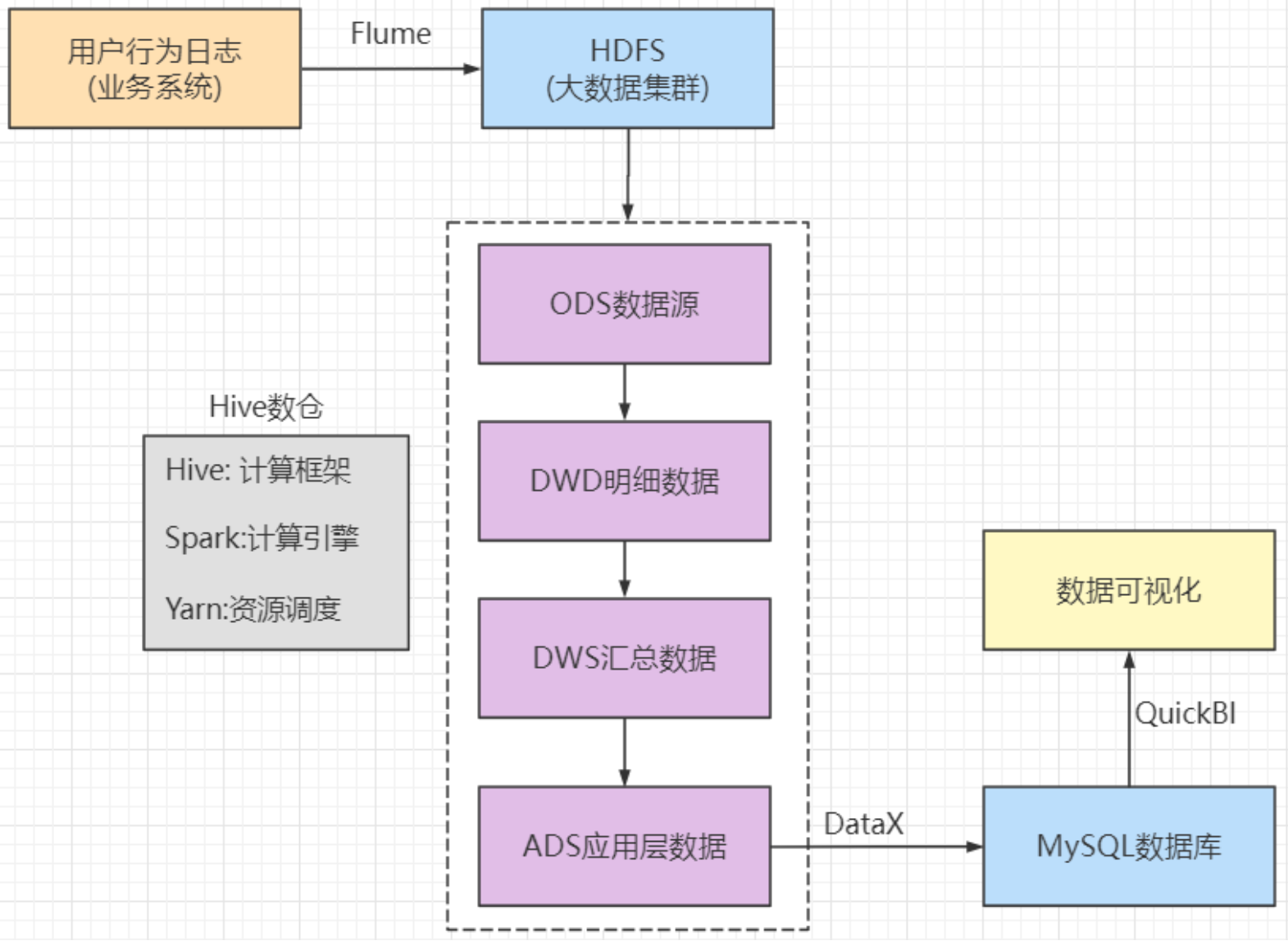
数据仓库分层
数仓分层结构
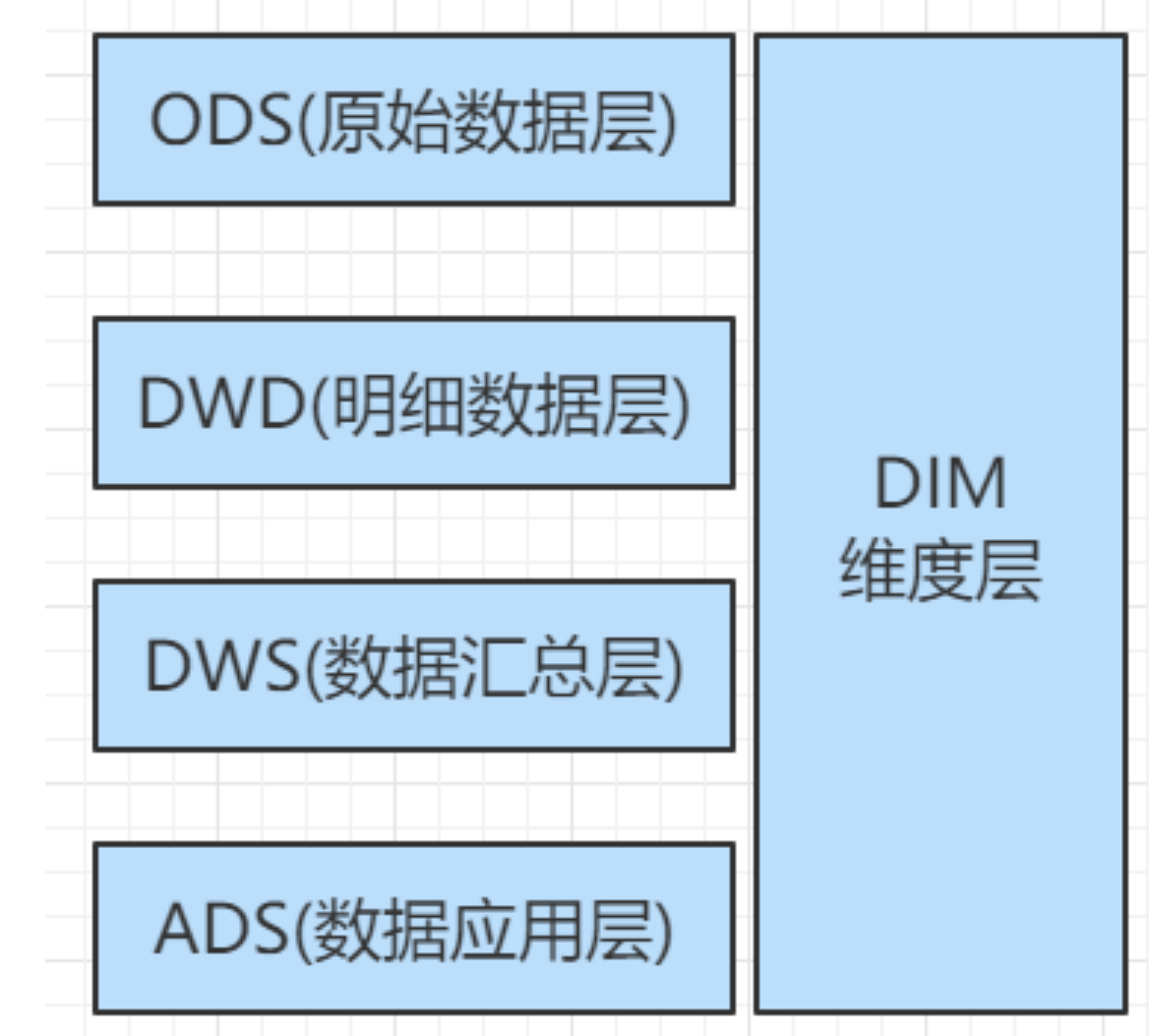
先将数据放入ods层 --> dwd层 --> dws 层 --> ads层 --> 导出到mysql
为什么要分层? 你开了一个饭馆,没有客人来吃饭,你在做什么?
买菜-->择菜-->切菜--> 做成半成品 等
因为指标查询要的是速度,天下武功,为快不破。
ODS层: 存放业务系统采集过来的原始数据, 直接加载的业务数据, 不做处理
DWD层: 对于ODS层的数据做基本的处理, 并且进行业务事实的分析和定位(不合法的数据处理, 空值的处理), 一行数据代表的是一个业务行为
DWS层, 对于DWD层的业务数据进行按天或者按照一定的周期进行统计分析, 是一个轻度聚合的结果
DIM层, 维度统计层, 对于需要统计分析(group by)的相关的条件进行统一的设计和规范, 比如时间, 地区, 用户等
ADS(数据应用层): 需要的业务统计分析结果, 一般会把ADS层的数据抽取到业务数据库MySQL中
3、为什么需要对数据仓库分层
- 把复杂问题简单化 不同的层次负责不同的功能定位
- 减少重复开发 对于DIM, DWS可以根据主题进行自上而下的设计, 抽取通用的功能
- 隔离原始数据 ODS层原始数据, 可以对统计结果进行回溯, 方便问题的定位。
介绍一个网址,专门用于查看各个行业的指标的:神策数据|大数据分析与营销科技解决方案服务商
四、数据采集
1、日志数据生成 [hadoop01]
1.1 安装Redis数据库
redis : 是一个NoSQL数据库,基于内存实现的数据库,速度非常快,一般用于做缓存。 --> 缓存之王
下载redis
cd /bigdata/soft
wget https://download.redis.io/redis-stable.tar.gz- 解压到指定目录
tar -zxvf redis-stable.tar.gz安装一些gcc编译库
- yum install -y gcc g++ gcc-c++ make
- 编译并且安装
进入到redis的源码目录
cd redis-stable
make MALLOC=libc
make PREFIX=/bigdata/server/redis install- 拷贝配置文件redis.conf并且修改
cd /bigdata/server/redis
mkdir {conf,data} # conf 配置文件目录 data 数据存放目录 log日志文件目录
cd /bigdata/soft/redis-stable
cp redis.conf /bigdata/server/redis/conf/cd /bigdata/server/redis/conf/
bind 0.0.0.0 # 配置可以所有的地址都可以访问redis 第87行
protected-mode no # 关闭保护模式 第111行
daemonize yes # 后台启动运行 309行
dir ./data # 相关的数据和日志文件的存放目录 510行
dbfilename dump.rdb # 数据文件存放 不需要修改
logfile "redis.log" # 指定logfile的文件名 默认没有日志文件 355行- 启动和关闭redis
cd /bigdata/server/redis
# 启动redis
bin/redis-server conf/redis.conf
查看进行redis是否运行呢?
netstat -nltp
查看是否有6379端口的进程
# 关闭redis
bin/redis-cli shutdown
# 登录到redis
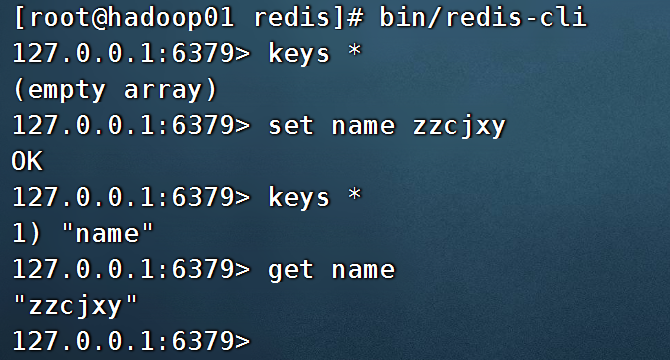
bin/redis-cli
1.2 配置系统环境
- 导入redis的数据库备份dump文件
第一步:先停止redis服务 bin/redis-cli shutdown
第二步:将dump.rdb 拷贝进去
第三步:启动redis服务 bin/redis-server conf/redis.conf
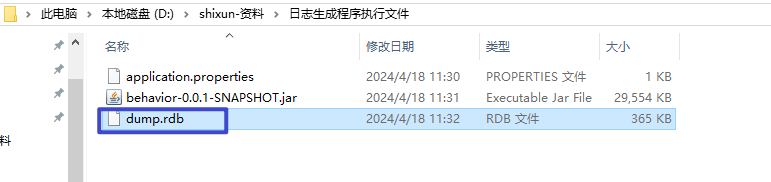
将本地的dump.rdb 文件,放入hadoop01 下的redis 目录下的data 目录
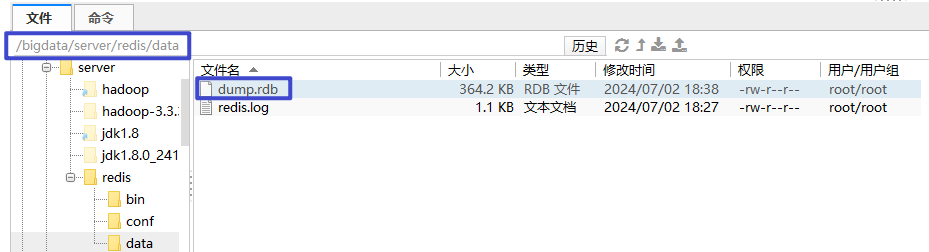
关闭redis命令
[root@hadoop01 redis]# bin/redis-cli shutdown
启动redis
[root@hadoop01 redis]# bin/redis-server conf/redis.conf
进入redis
[root@hadoop01 redis]# bin/redis-cli
查看里面的内容:
keys *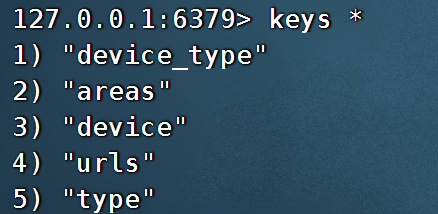
2、在/bigdata/soft 下,拖拽两个文件
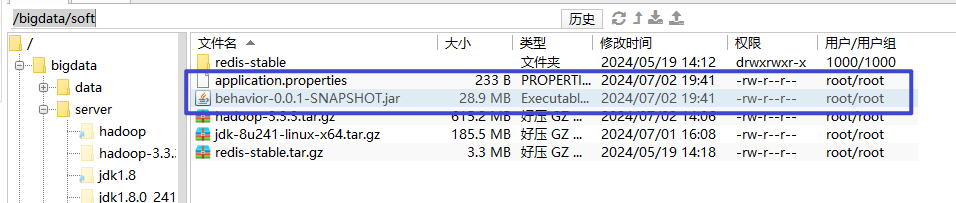
修改启动web应用的application.properties配置文件
SpringBoot : 是一个java web中的顶顶大名的主流框架。
拓展:javaweb 小伙伴现在都在搞 spring cloud alibaba。
# 生成日志的存放路径
logPath=/home/log/behavior
# redis数据库的连接地址 端口 密码
spring.redis.host=localhost
spring.redis.port=6379
spring.redis.password=
# web应用服务器的启动端口
server.port=8080mkdir -p /home/log/behavior
进入到/bigdata/soft
运行jar包
java -jar behavior-0.0.1-SNAPSHOT.jar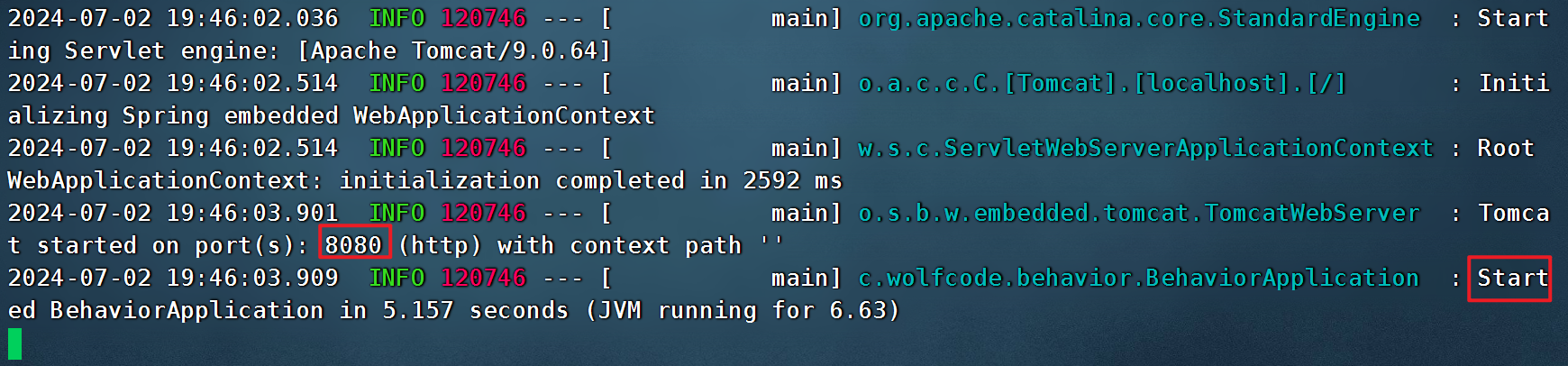
窗口不要关闭,使用浏览器访问一下。
1.3 启动日志系统
需要可执行的jar包和配置文件在同一目录
访问接口,生成日志
# date: 具体生成哪一天的数据 count: 具体生成的数据量
http://192.168.233.131:8080/create/log?date=2022-08-08&count=1000在浏览器中执行

注意: 为了上课统一, 这里生成2022-08-08 至 2022-08-14 共7天的数据【一定要是2022年的,因为后面授课还会有一个日期维度表,里面只有2022年的数据】
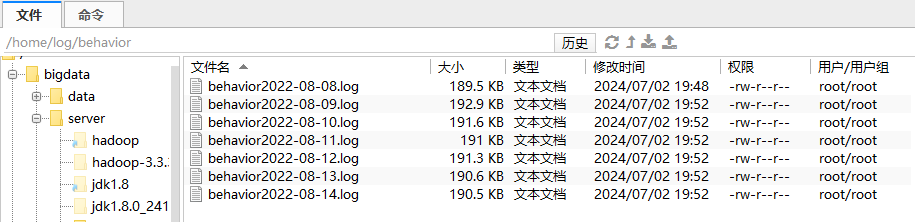
2、数据采集
2.2 安装flume数据采集软件【hadoop01】
在hadoop01上安装flume数据采集软件
# 1 上传apache-flume-1.9.1-bin.tar.gz 到 /bigdata/soft 目录
# 2 解压到指定目录
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /bigdata/server
# 3 创建软链接
cd /bigdata/server
ln -s apache-flume-1.9.0-bin/ flume2.3 配置环境变量
vi /etc/profile.d/my_env.sh
#!/bin/bash
#JAVA_HOME
export JAVA_HOME=/bigdata/server/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
#FLUME_HOME
export FLUME_HOME=/bigdata/server/flume
export PATH=$PATH:$FLUME_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/bigdata/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
#加载配置文件
source /etc/profile
验证flume的安装是否成功:
flume-ng version2.4 测试环境
通过jps-cluster.sh 命令查看hadoop集群是否启动
如果没有启动: start-dfs.sh
# 测试hadoop环境
hdfs dfs -ls /2.5 配置Flume采集数据
flume 是一个专门抽取日志数据的工具,可以将本地的文件,抽取到hdfs上。
2.5.1 在lib目录添加一个ETL拦截器
- 处理标准的json格式的数据, 如果格式不符合条件, 则会过滤掉该信息
- 处理时间漂移的问题, 把对应的日志存放到具体的分区数据中
在业务服务器的Flume的lib目录添加itercepter-etl.jar
通过java代码编写一个拦截器,将日志中不是json数据的数据过滤掉,只保留符合json格式的数据。
将拦截器放入到flume/lib 下
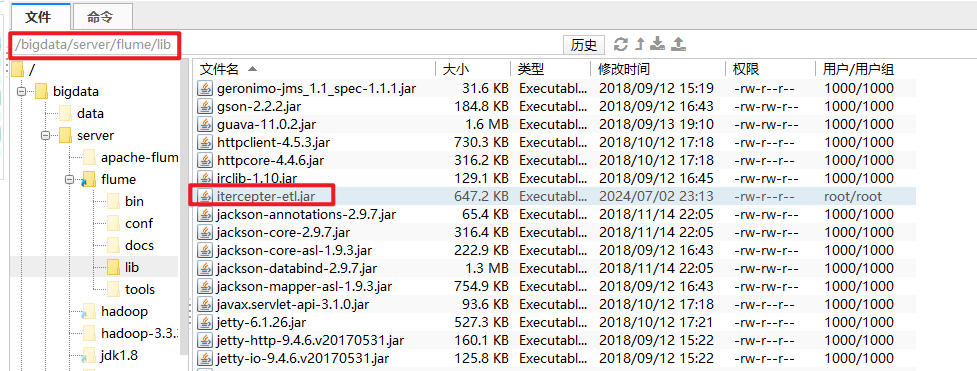
2.5.2 配置采集数据到hdfs文件的配置
在flume的家目录创建文件 jobs/log_file_to_hdfs.conf
mkdir /bigdata/server/flume/conf/jobs
cd /bigdata/server/flume/conf/jobs/
vi log_file_to_hdfs.conf
#为各组件命名
a1.sources = r1
a1.channels = c1
a1.sinks = k1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /home/log/behavior/.*
a1.sources.r1.positionFile = /bigdata/server/flume/position/behavior/taildir_position.json
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = cn.wolfcode.flume.interceptor.ETLInterceptor$Builder
a1.sources.r1.interceptors = i2
a1.sources.r1.interceptors.i2.type = cn.wolfcode.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /behavior/origin/log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = DataStream
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c12.5.3 运行数据采集命令
# 进入到Flume的目录
cd /bigdata/server/flumebin/flume-ng agent --conf conf/ --name a1 --conf-file conf/jobs/log_file_to_hdfs.conf -Dflume.root.logger=INFO,console两者二选一,不要都执行。
# 后台启动运行
nohup bin/flume-ng agent --conf conf/ --name a1 --conf-file conf/jobs/log_file_to_hdfs.conf -Dflume.root.logger=INFO,console >/bigdata/server/flume/logs/log_file_to_hdfs.log 2>&1 &2.5.4 日志采集效果
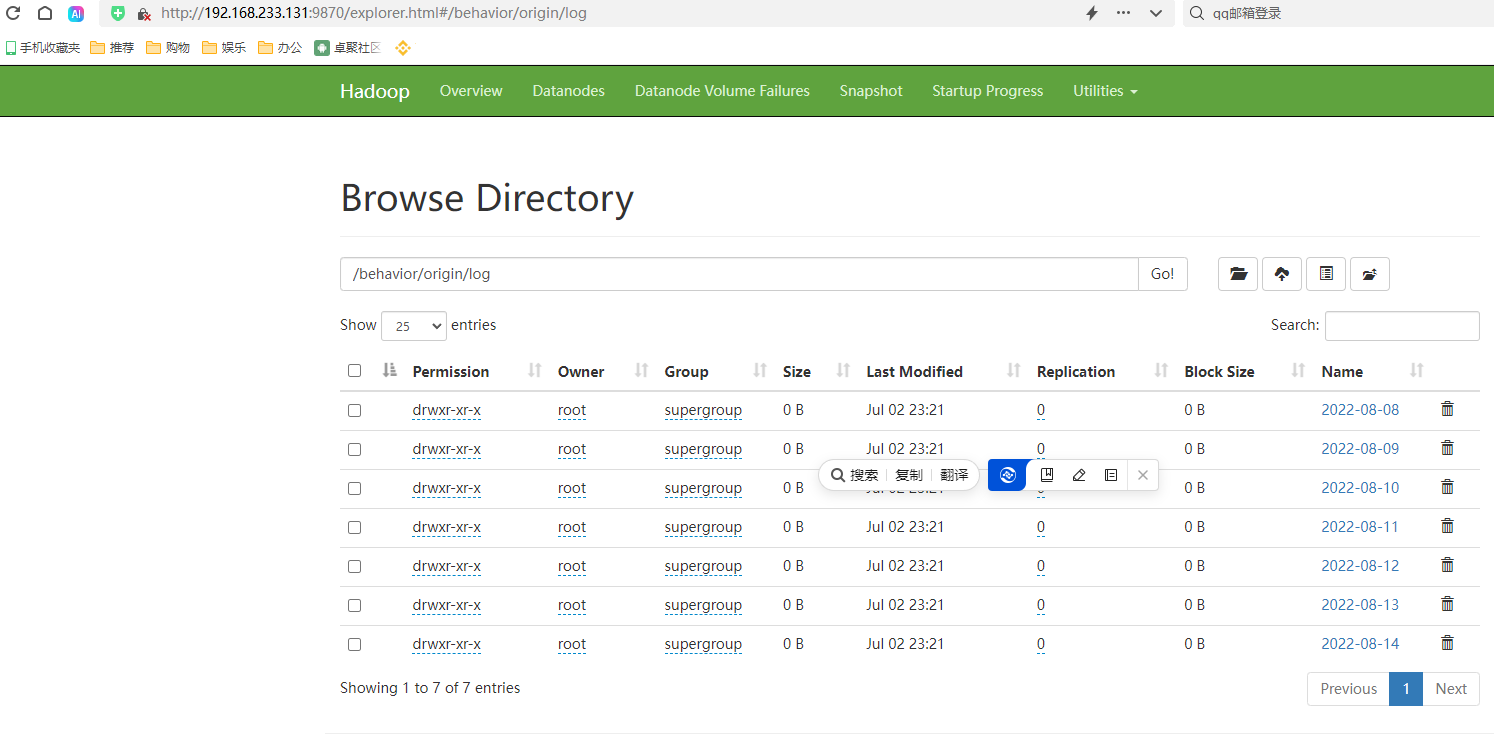
思考题:
本地数据上传至hdfs 一个命令即可搞定,为什么要使用flume呢?
答:假如日志是不断产生的,只要文件夹中有新的日志,就会自动上传hdfs,这样的效果必须使用flume。
为什么你的hdfs 中缺少一些服务?
1、哪个上面缺什么服务,就在哪个服务器上看日志
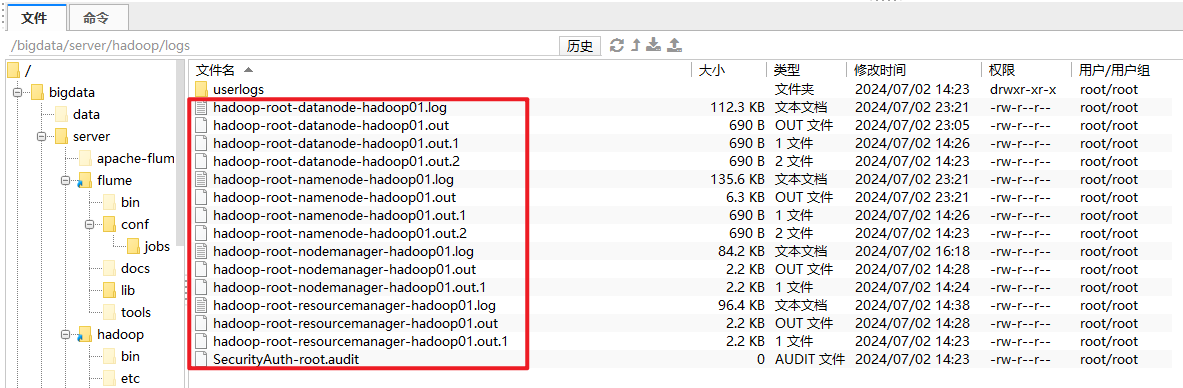
2、假如找不到原因,来了终极方案
第0步: hadoop01 是否免密登录到 01 02 03 上
第一步:stop-all.sh 停止所有服务
第二步:将hadoop01 ~ 03 上全部执行如下命令
rm -rf /bigdata/data/hadoop/
第三步:在hadoop01 上进行格式化
hadoop namenode -format
第四步: start-dfs.sh
五、数据仓库建设
5.1 Hive环境集成
5.1.1 Hive环境配置
Hive是数据仓库中最常用的一个组件, 但是第一代的Hive的执行引擎是MapReduce,运行起来比较慢, 后面Hive的执行引擎用的比较多的有Tez,Spark
Hive on Spark 核心组件是Hive, 只是把运行的执行引擎替换为了Spark内存计算框架, 提高的程序运行的效率
其中Hive主要负责数据的存储以及SQL语句的解析
Spark on Hive 核心组件是Spark, 只是把Spark的的数据存储使用Hive以及元数据管理使用Hive, Spark负责SQL的解析并且进行计算
在这里我们采用Hive-on-Spark的设计架构
Hive : 优点可以创建表,可以存储海量数据,底层使用了hdfs,缺点是执行sql速度慢,特别的慢。
可以将计算引擎从mapreduce 修改为 spark ,速度就变快了。
5.1.2 安装Hive环境[hadoop03]
使用编译好的源码软件
# 上传安装文件 /bigdata/soft
apache-hive-3.1.2-bin.tar.gz
# 解压到指定目录
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /bigdata/server/
# 创建软链接
cd /bigdata/server/
ln -s apache-hive-3.1.2-bin hive配置环境变量
vim /etc/profile.d/custom_env.sh
## hive
export HIVE_HOME=/bigdata/server/hive
export PATH=$PATH:$HIVE_HOME/bin加载环境变量
source /etc/profile
修改配置文件
cd /bigdata/server/hive/conf
创建配置文件vi hive-site.xml
<configuration>
<-- 元数据存储的数据库配置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://biz01:3306/hive?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<-- 数据文件存储的目录配置 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<-- 去掉metastore的校验 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<-- 设置thrift的访问端口 hiveserver2 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<-- 设置hiveserver2绑定的主机 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop03</value>
</property>
<-- 禁用权限认证 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<-- hive客户端配置, 显示表头信息 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<-- hive客户端配置, 显示当前数据库 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>记得拷贝mysql的jar包到lib 目录下。
将 mysql-connector-java-5.1.27-bin.jar 上传至 /bigdata/server/apache-hive-3.1.2-bin/lib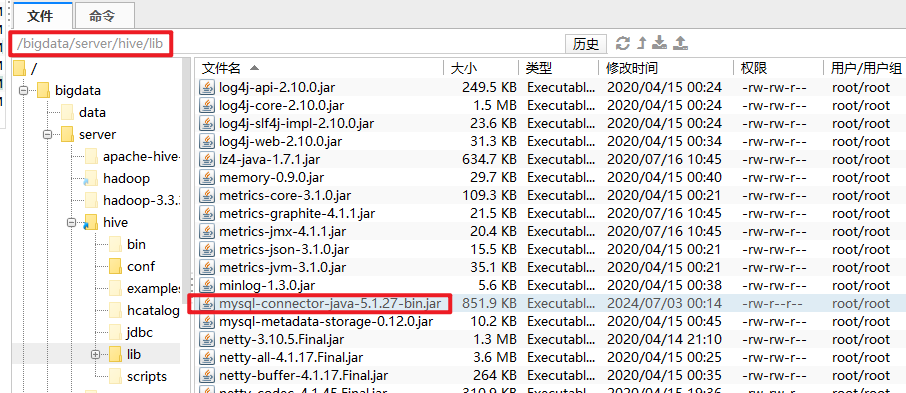
初始化元数据信息
在mysql中创建数据库hive
create database hive;
删除掉配置文件hive-site.xml中所有的中文注释

schematool -initSchema -dbType mysql -verbose-- 解决元数据中文乱码
# 设置注释中文乱码的问题 在MySQL的元数据库设置
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;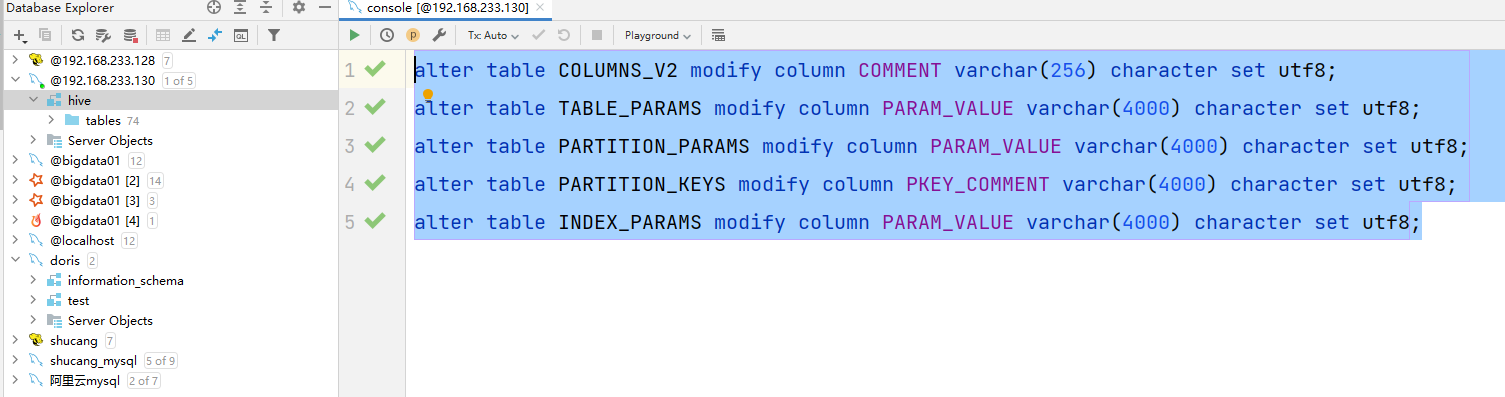
测试环境
启动hive客户端
- 在hadoop03中输入 hive
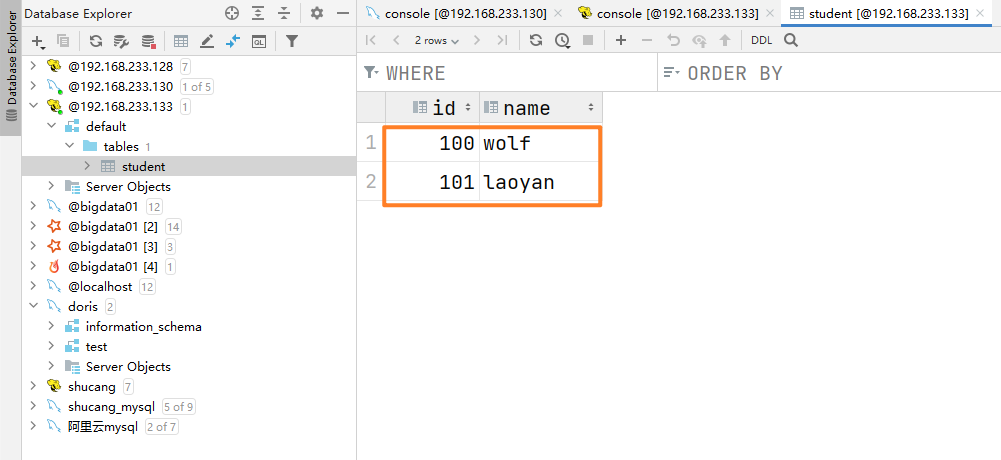
创建一张测试表
- create table student(id int, name string);
通过insert插入测试数据
- insert into student values(100,'wolf');
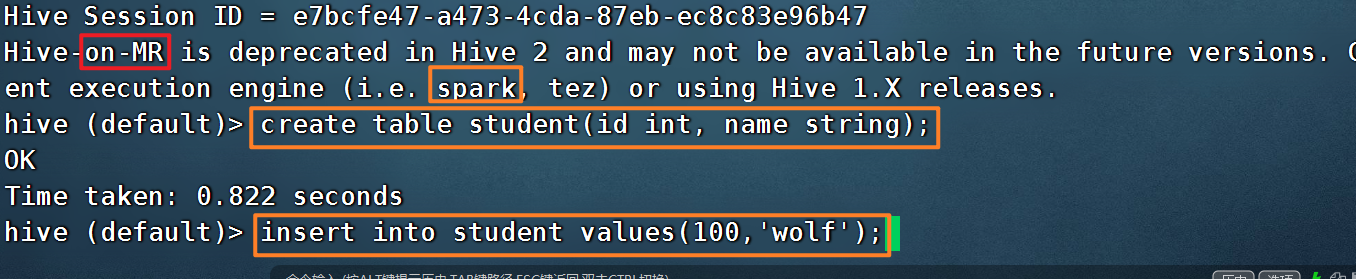
使用hive 执行sql语句,记得开启yarn。
start-yarn.sh
5.2 Spark环境配置[hadoop03]
5.2.1 上传安装文件 【/bigdata/soft】
spark-3.0.0-bin-without-hadoop.tgz
5.2.2 解压软件
tar -zxvf spark-3.0.0-bin-without-hadoop.tgz -C /bigdata/server/
# 创建软链接
cd /bigdata/server/
ln -s spark-3.0.0-bin-without-hadoop spark5.2.3修改配置文件
cd /bigdata/server/spark/conf/
mv spark-env.sh.template spark-env.sh
vim conf/spark-env.sh
# spark-on 配置
export HADOOP_CONF_DIR=/bigdata/server/hadoop/etc/hadoop
export YARN_CONF_DIR=/bigdata/server/hadoop/etc/hadoop
# spark的classpath依赖配置
export SPARK_DIST_CLASSPATH=$(/bigdata/server/hadoop/bin/hadoop classpath)5.2.4 配置历史服务器
cd /bigdata/server/spark/conf/
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
# 默认提交到yarn集群运行
spark.master=yarn
spark.eventLog.enabled=true
spark.eventLog.dir=hdfs://hadoop01:8020/spark/log
spark.executor.memory=1g
spark.driver.memory=1g在hdfs上创建历史日志存放目录
hdfs dfs -mkdir -p /spark/log
5.2.5 配置环境变量
vim /etc/profile.d/custom_env.sh
# spark
export SPARK_HOME=/bigdata/server/spark
export PATH=$PATH:$SPARK_HOME/bin加载环境变量
source /etc/profile
5.2.6 测试运行
cd /bigdata/server/spark
# 提交示例程序
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
examples/jars/spark-examples_2.12-3.0.0.jar 105.3 Hive on Spark
5.3.1 上传spark的依赖到hdfs
cd /bigdata/server/
hdfs dfs -mkdir -p /spark/jars
# 这里需要上传spark纯净的jar包目录(不含hadoop的jar包)
hdfs dfs -put spark/jars/* /spark/jars/
5.3.2 修改hive的配置文件
cd /bigdata/server/hive/confvim conf/hive-site.xml
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop01:8020/spark/jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和Spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>5.3.3 启动测试
启动hive客户端, 在hadoop03的任意目录下
- hive
创建一张测试表 (如果已经有这个表了,无需创建)
- create table student(id int, name string);
通过insert插入测试数据
- insert into student values(101,'laoyan');
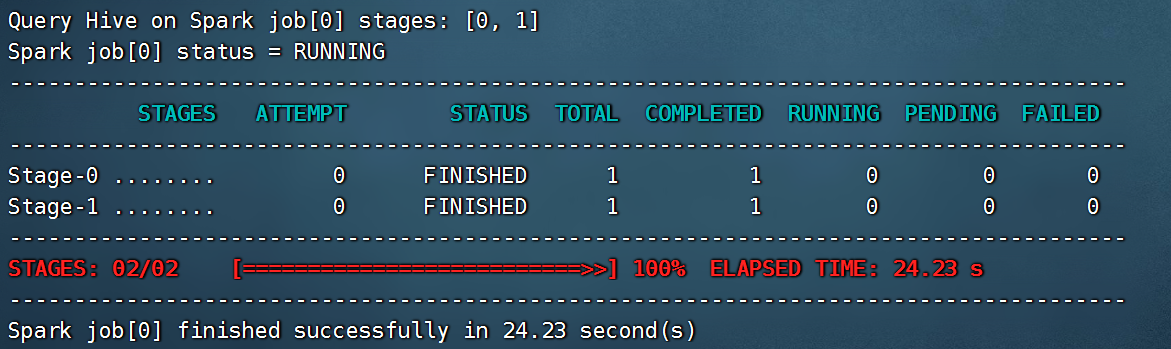
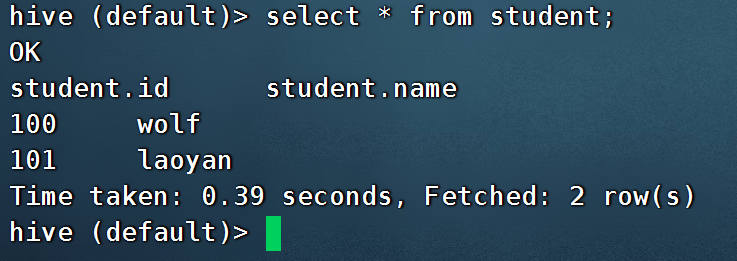
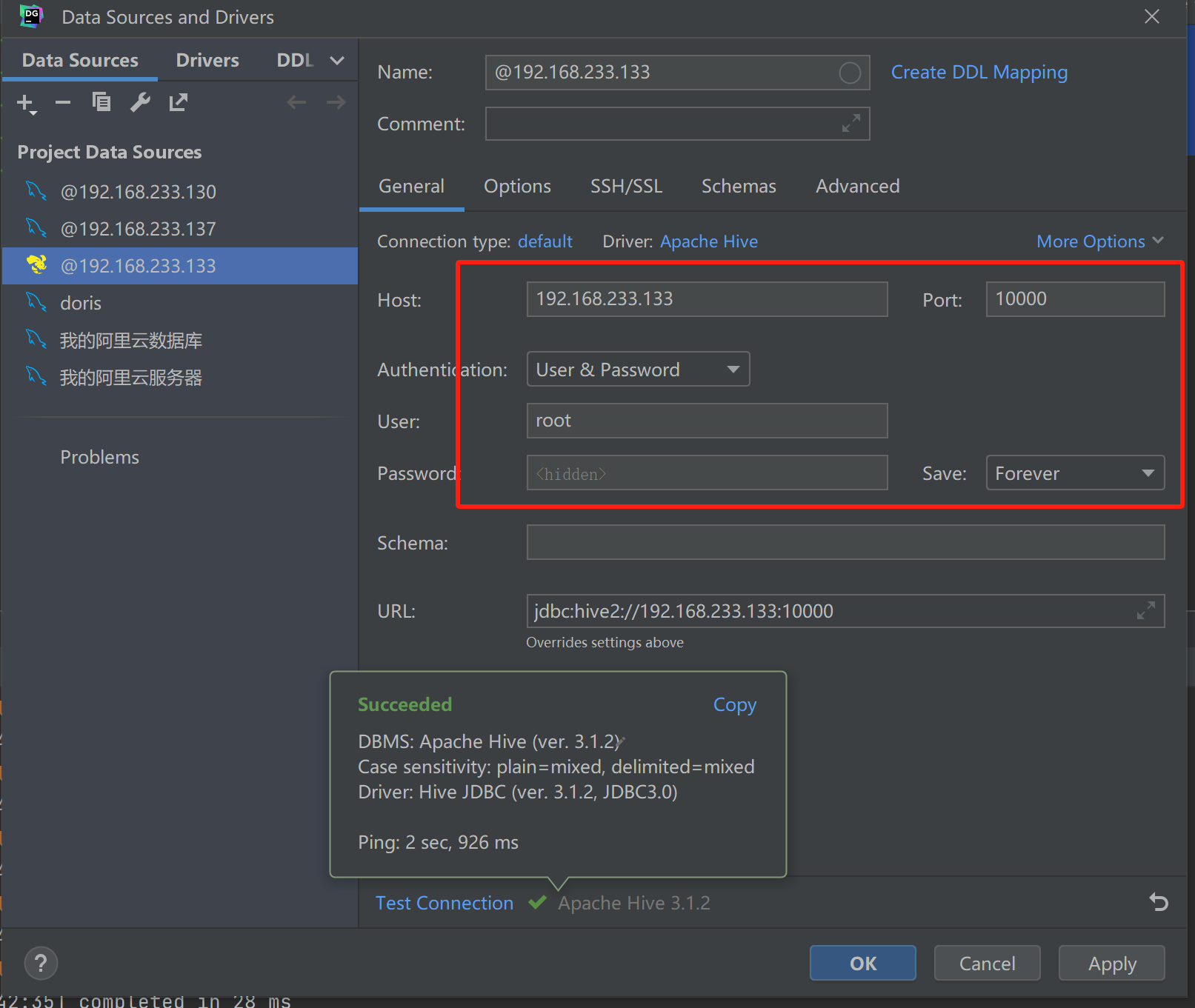
5.3.4 使用开发工具Datagrip连接Hive
# 使用工具连接Hive
mkdir /bigdata/server/hive/logs
cd /bigdata/server/hive
nohup bin/hiveserver2 > /bigdata/server/hive/logs/hive.log 2>&1 &
hiveserver2 启动是比较慢的,如何知道已经启动成功了
netstat -nltp --> 查看端口
watch netstat -nltp --> 监听是否有新端口被启用了
也可以通过查看日志的形式得知hiveserver2是否启动成功。
tail -f /bigdata/server/hive/logs/hive.log可以先使用beeline客户端去连接测试一下:(跳过可以不测试)
连接方式:
方式1:
step1. beeline 回车
step2. !connect jdbc:hive2://bigdata01:10000 回车
step3. 输入用户名 回车 数据库用户名
step4. 输入密码 回车 此处的密码是数据库密码
方法2(直连):
beeline -u jdbc:hive2://bigdata01:10000 -n 用户名
解析:
hive2,是Hive的协议名称
ip: Hiveserver2服务所在的主机IP。
10000,是Hiveserver2的端口号
退出:
Ctrl+ C 可以退出客户端
5.4 数据仓库建设
5.4.1 ODS源数据层
create database behavior;- 建表语句
-- 创建电信用户行为日志表
drop table if exists ods_behavior_log;
use behavior;
create external table ods_behavior_log
(
line string
)
partitioned by (dt string)
location '/behavior/ods/ods_behavior_log';为什么要创建表 ? 因为我需要将我的用户行为数据导入到表中,进行分析。
- 加载数据
load data inpath '/behavior/origin/log/2022-08-08' into table ods_behavior_log partition (dt = '2022-08-08');
以上sql虽然可以导入数据,但是由于我们的数据太多,需要执行7次这样的语句,所以说我们编写了一个脚本。
- 导入数据脚本 【可以帮助我们批量导入很多天的】
cd /bigdata/server/hive/scripts
脚本名称为:origin_to_ods_init_behavior_log.sh
touch origin_to_ods_init_behavior_log.sh
chmod u+x origin_to_ods_init_behavior_log.sh
#!/bin/bash
if [ $# -ne 2 ]; then
echo "useage origin_to_ods_init_behavior_log.sh start_date end_date"
exit
fi
EXPORT_START_DATE=$1
EXPORT_END_DATE=$2
i=$EXPORT_START_DATE
while [[ $i < `date -d "+1 day $EXPORT_END_DATE" +%Y-%m-%d` ]]
do
SQL="load data inpath '/behavior/origin/log/$i' into table behavior.ods_behavior_log partition(dt='$i');"
hive -e "$SQL"
i=`date -d "+1 day $i" +%Y-%m-%d`
done./origin_to_ods_init_behavior_log.sh 2022-08-08 2022-08-14查看数据是否导入:
查看分区数
show partitions ods_behavior_log;
查看10条内容
select * from ods_behavior_log limit 10;
查看总条数:7000条
select count(1) from ods_behavior_log;新的一天,新的服务器集群:
hadoop01: start-dfs.sh start-yarn.sh --> start-all.sh
hadoop03: 启动hiveserver2
cd /bigdata/server/hive
nohup bin/hiveserver2 > /bigdata/server/hive/logs/hive.log 2>&1 &
查看是否启动成功:
watch netstat -nltp
5.4.2 创建udf函数
- 定义udf函数
public class UrlHandlerUdf extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
// 参数长度判断
if(objectInspectors.length != 1){
throw new UDFArgumentLengthException("传入的数据参数的长度不正确!");
}
// 判断输入参数的类型
if(!objectInspectors[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(0,"输入的参数类型不正确!!!");
}
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
if(deferredObjects[0].get() == null){
return "" ;
}
String data = deferredObjects[0].get().toString();
int index = data.indexOf("?");
if(index > 0 ){
data = data.substring(0,index);
}
if (data.startsWith("https://")){
data=data.replaceFirst("https://","http://");
}
return new Text(data.getBytes(StandardCharsets.UTF_8));
}
}public class Ip2Loc extends GenericUDF {
public List<Map<String,String>> mapList = new ArrayList<>();
static {
String host = "hadoop01";
int port = 6379;
Jedis jedis = new Jedis(host, port);
Set<String> areas = jedis.smembers("areas");
for (String area : areas) {
JSONObject jsonObject = JSON.parseObject(area);
Map<String,String> map = new HashMap<>();
map.put("city",jsonObject.getString("city"));
map.put("province",jsonObject.getString("province"));
mapList.add(map);
}
// 把map数据写入到文件
}
// 初始化参数判断
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
// 参数长度判断
if(objectInspectors.length != 1){
throw new UDFArgumentLengthException("传入的数据参数的长度不正确!");
}
// 判断输入参数的类型
if(!objectInspectors[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentTypeException(0,"输入的参数类型不正确!!!");
}
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
// 返回一个字符串 广东省|广州市
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
if(deferredObjects[0].get() == null){
return "" ;
}
int index = (int) (Math.random() * mapList.size());
Text new_str = new Text((mapList.get(index).get("city")+"_"+(mapList.get(index).get("province"))).getBytes(StandardCharsets.UTF_8));
return new_str;
}
@Override
public String getDisplayString(String[] strings) {
return "";
}
}- 打包文件hive_udf_custom-1.0.0.jar 并且上传到指定目录(spark/jars)
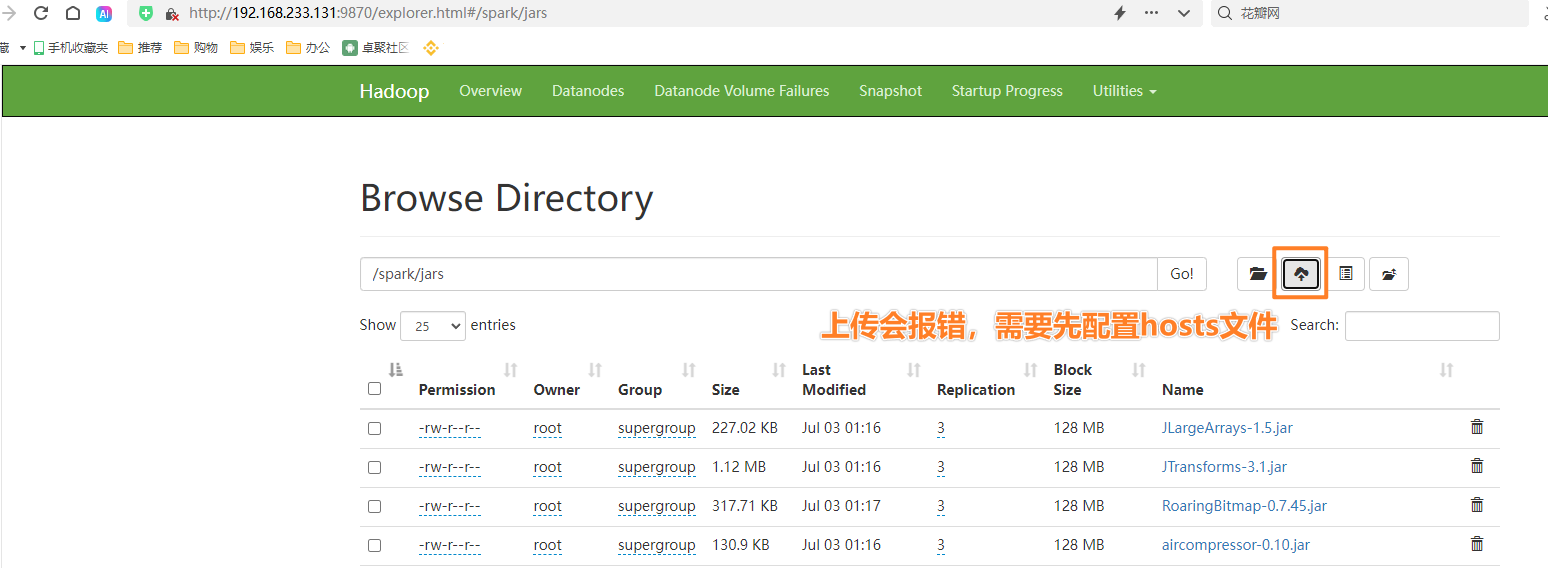
在上传过程中如果发现报错,提示无法上传的情况,请修改windows下的hosts文件。

具体的路径在:
由于安全校验问题,先将hosts文件拖拽至桌面,修改完成之后再拖回去。
hosts的内容追加如下(千万不要覆盖):
192.168.233.130 biz01
192.168.233.131 hadoop01
192.168.233.132 hadoop02
192.168.233.133 hadoop03jedis-3.3.0.jar
commons-pool2-2.6.2.jar
fastjson2-2.0.1.jar
hive_udf_custom-1.0.0.jar
hive-exec-3.1.2.jar
- 上传对应的依赖到hive的安装目录的lib/ [hadoop03]
jedis-3.3.0.jar
commons-pool2-2.6.2.jar
fastjson2-2.0.1.jar
hive_udf_custom-1.0.0.jar
- 注册全局函数
接着重启一下hiveserver2 服务,然后再次连接才能执行如下语句。

cd /bigdata/server/hive
[root@hadoop03 hive]# nohup bin/hiveserver2 > /bigdata/server/hive/logs/hive.log 2>&1 &
[root@hadoop03 hive]# tail -f /bigdata/server/hive/logs/hive.log在hive的客户端或者datagrip 下:执行如下代码:
假如redis没有启动,会影响我的函数的运行。
hadoop01:
cd /bigdata/server/redis
bin/redis-server conf/redis.conf
create function get_city_by_ip
as 'cn.wolfcode.udf.Ip2Loc' using jar 'hdfs://hadoop01:8020//spark/jars/hive_udf_custom-1.0.0.jar';create function url_trans_udf
as 'cn.wolfcode.udf.UrlHandlerUdf' using jar 'hdfs://hadoop01:8020//spark/jars/hive_udf_custom-1.0.0.jar';- 测试函数
select get_city_by_ip("192.168.113.1");
select url_trans_udf("http://www.baidu.com?name=kw");5.4.3 DWD明细数据层 【d-->detail】
- 创建dwd表数据
-- 创建dwd明细表数据
-- 获取到城市, 省份
-- 获取到url的资源路径 去掉查询参数
-- 定义表
DROP TABLE IF EXISTS dwd_behavior_log;
CREATE EXTERNAL TABLE dwd_behavior_log
(
`client_ip` STRING COMMENT '客户端IP',
`device_type` STRING COMMENT '设备类型',
`type` STRING COMMENT '上网类型 4G 5G WiFi',
`device` STRING COMMENT '设备ID',
`url` STRING COMMENT '访问的资源路径',
`city` STRING COMMENT '城市',
`ts` bigint comment "时间戳"
) COMMENT '页面启动日志表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/behavior/dwd/dwd_behavior_log'
TBLPROPERTIES ("orc.compress" = "snappy");
select * from dwd_behavior_log;- 加载数据
测试一下:
select split(get_city_by_ip("192.168.113.133"),'_')[0];
-- 设置支持动态分区处理
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_behavior_log partition (dt)
select get_json_object(line, '$.client_ip'),
get_json_object(line, '$.device_type'),
get_json_object(line, '$.type'),
get_json_object(line, '$.device'),
url_trans_udf(get_json_object(line, '$.url')),
split(get_city_by_ip(get_json_object(line, '$.client_ip')),"_")[0],
get_json_object(line, '$.time'),
dt
from ods_behavior_log;假如你在使用hadoop集群的时候,报错,提示namenode 没有退出安全模式,可以选择手动退出。
在hadoop01上执行:
hdfs dfsadmin -safemode leave
5.4.4 DWS宽表汇总数据 【这一层其实可以不做】
- 建表语句
-- 定义表
DROP TABLE IF EXISTS dws_behavior_log;
CREATE EXTERNAL TABLE dws_behavior_log
(
`client_ip` STRING COMMENT '客户端IP',
`device_type` STRING COMMENT '设备类型',
`type` STRING COMMENT '上网类型 4G 5G WiFi',
`device` STRING COMMENT '设备ID',
`url` STRING COMMENT '访问的资源路径',
`city` STRING COMMENT '城市',
`ts` bigint comment "时间戳"
) COMMENT '页面启动日志表'
PARTITIONED BY (`dt` STRING)
STORED AS ORC
LOCATION '/behavior/dws/dws_behavior_log'
TBLPROPERTIES ("orc.compress" = "snappy");- 加载数据
--装载数据
insert overwrite table dws_behavior_log partition (dt)
select client_ip, device_type, type, device, url, city, ts, dt
from dwd_behavior_log;5.4.5 创建维度表
维度建模理论:数仓中只有两种表,维度表和事实表

时间维度表
- 建表语句
-- 创建时间维度
drop table if exists behavior.dim_date;
create external table dim_date
(
date_id string comment "日期",
week_id string comment "周",
week_day string comment "星期",
day string comment "一个月的第几天",
month string comment "第几个月",
quarter string comment "第几个季度",
year string comment "年度",
is_workday string comment "是否是工作日",
holiday_id string comment "国家法定假日"
)
row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/behavior/dim/dim_date';- 加载数据
直接把数据文件dim_date_2022 上传到/behavior/dim/dim_date即可
查询数据
- select * from dim_date
地区维度表
- 建表语句
-- 创建地区维度表
drop table if exists dim_area;
create external table dim_area
(
city string comment "城市",
province string comment "省份",
area string comment "地区"
)
row format delimited fields terminated by '\t'
lines terminated by '\n'
location '/behavior/dim/dim_area';- 加载数据
直接把数据文件dim_area 上传到/behavior/dim/dim_area即可
5.4.6 ADS层统计数据 【数据服务层、数据集市】其实就是指标
- 用户城市分布
-
- 创建表语句
drop table if exists ads_user_city;
create external table ads_user_city
(
city string comment "城市",
province STRING comment "省份",
area STRING comment "区域",
dt string comment "日期",
count bigint comment "访问数量"
) COMMENT '用户城市分布'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/behavior2/ads/ads_user_city';-
- 插入统计数据
insert into ads_user_city
select t1.city,t2.province,t2.area,t1.dt,count(1)
from dws_behavior_log t1 join dim_area t2 on t1.city=t2.city
group by t1.city, t2.province,t2.area, t1.dt;- 每个网站的上网的模式
-
- 建表语句
drop table if exists ads_visit_type;
create external table ads_visit_type
(
url string comment "访问地址",
type string comment "访问模式 4G 5G Wifi",
dt STRING comment "日期",
month String comment "月度",
quarter String comment "季度",
count bigint comment "统计数量"
)comment "网站访问的上网模式分布"
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
location "/behavior2/ads/ads_visit_type";-
- 插入数据
insert overwrite table ads_visit_type
select t1.url, t1.type,t1.dt, t2.month, t2.quarter, count(1)
from dws_behavior_log t1 join dim_date t2 on t1.dt=t2.date_id
group by t1.url, t1.type, t1.dt, t2.month, t2.quarter;- 每个网站的上网类型
-
- 建表语句
drop table if exists ads_visit_mode;
create external table ads_visit_mode
(
url string comment "访问地址",
device_type string comment "上网模式 移动 pc",
dt string comment "上网日期",
count bigint comment "统计数量"
) comment "网站的上网模式分布"
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
location "/behavior2/ads/ads_visit_mode";-
- 插入数据
insert into table ads_visit_mode
select url, device_type,dt, count(1)
from dws_behavior_log
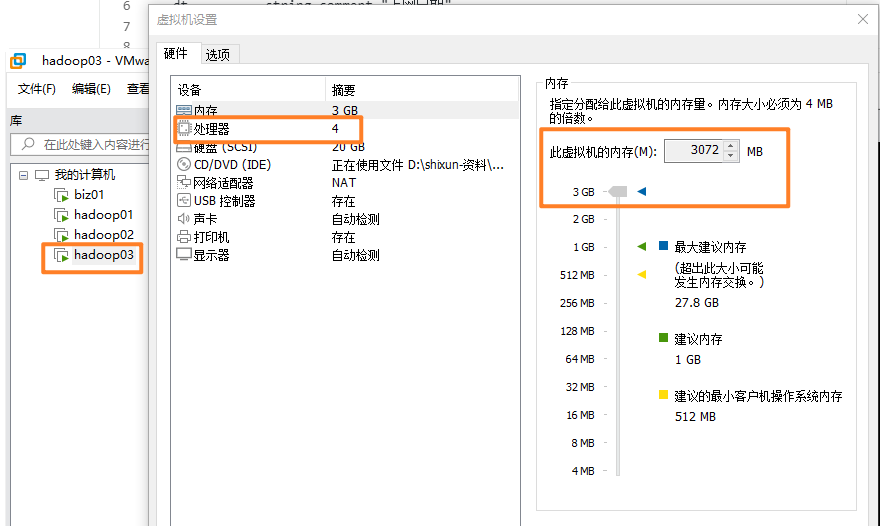
group by url, device_type,dt;可能遇到的问题:
1、需要调整hadoop03的内存大小
2、自定义函数时,第一个函数不起作用
1) hdfs上一定要上传5个jar包 【/spark/jars】
2) hadoop03 上的hive 的lib 下,上传 4 个jar
3) 一定要使用群里我在课堂上刚给你打的jar包
![]()
不要使用以前的jar包。
4) 假如你创建函数失败了,重新退出再进入

5)redis 一定要启动。
六、数据可视化
6.1 Datax的基本安装
datax 是一个数据导入导出工具,阿里出品。可以将数仓中的数据导出到mysql等数据库中。市面上还有同类型的产品sqoop。
- 下载软件
https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/20220530/datax.tar.gz
- 上传的服务器的指定目录(hadoop02) [/bigdata/soft 下]
解压到指定目录
- tar -zxvf datax.tar.gz -C /bigdata/server/
运行示例程序
- python bin/datax.py job/job.json
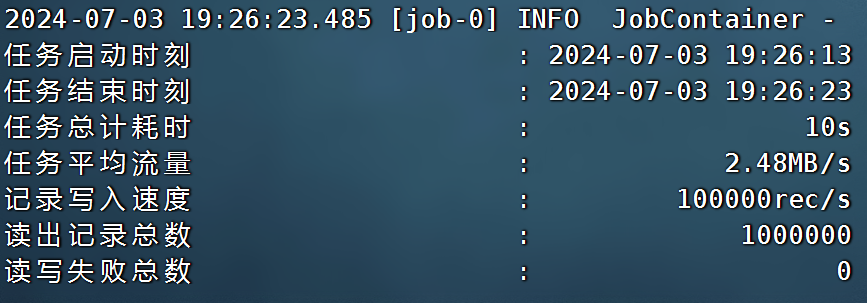
datax的官网:GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
6.2 Datax的基本使用
在MySQL中创建对应的表结构
create database behavior_bi;用户城市分布
CREATE TABLE `ads_user_city` (
city varchar(80) DEFAULT NULL COMMENT '城市',
province varchar(80) DEFAULT NULL COMMENT '省份',
area varchar(80) DEFAULT NULL COMMENT '区域',
dt varchar(80) DEFAULT NULL COMMENT '日期',
count bigint DEFAULT NULL COMMENT '统计数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='用户城市分布';访问时间统计
create table ads_visit_type(
url VARCHAR(80) COMMENT '访问地址',
type VARCHAR(80) COMMENT '访问模式',
dt VARCHAR(80) COMMENT '日期',
month VARCHAR(80) COMMENT '月度',
quarter VARCHAR(80) COMMENT '季度',
count bigint COMMENT '统计数量'
) COMMENT '网站访问的上网模式分布';网站访问的上网模式分布
create table ads_visit_mode
(
url VARCHAR(80) comment "访问地址",
device_type VARCHAR(80) comment "上网模式 移动 pc",
dt VARCHAR(80) comment "上网日期",
count bigint comment "统计数量"
) comment "网站的上网模式分布" ;导出数据脚本
cd /bigdata/server/datax/job
- ads_user_city.json
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/behavior2/ads/ads_user_city/*",
"defaultFS": "hdfs://hadoop01:8020",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "long"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "123456",
"column": [
"city",
"province",
"area",
"dt",
"count"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from ads_user_city"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://biz01:3306/behavior_bi?useUnicode=true&characterEncoding=utf-8&useSSL=false",
"table": [
"ads_user_city"
]
}
]
}
}
}
]
}
}python bin/datax.py job/ads_user_city.json- ads_visit_type.json
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/behavior2/ads/ads_visit_type/*",
"defaultFS": "hdfs://hadoop01:8020",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "string"
},
{
"index": 4,
"type": "string"
}
{
"index": 5,
"type": "long"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "replace",
"username": "root",
"password": "123456",
"column": [
"url",
"type",
"dt",
"month",
"quarter",
"count"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from ads_visit_type"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://biz01:3306/behavior_bi?useUnicode=true&characterEncoding=utf-8&useSSL=false",
"table": [
"ads_visit_type"
]
}
]
}
}
}
]
}
}ads_visit_mode.json
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "hdfsreader",
"parameter": {
"path": "/behavior2/ads/ads_visit_mode/*",
"defaultFS": "hdfs://hadoop01:8020",
"column": [
{
"index": 0,
"type": "string"
},
{
"index": 1,
"type": "string"
},
{
"index": 2,
"type": "string"
},
{
"index": 3,
"type": "long"
}
],
"fileType": "text",
"encoding": "UTF-8",
"fieldDelimiter": "\t"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"writeMode": "replace",
"username": "root",
"password": "123456",
"column": [
"url",
"device_type",
"dt",
"count"
],
"session": [
"set session sql_mode='ANSI'"
],
"preSql": [
"delete from ads_visit_mode"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://biz01:3306/behavior_bi?useUnicode=true&characterEncoding=utf-8&useSSL=false",
"table": [
"ads_visit_mode"
]
}
]
}
}
}
]
}
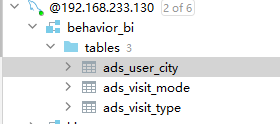
}数据库中的数据:
6.4 使用帆软BI进行可视化展示
BI可视化工具特别多:FineBI、SuperSet、QuickBI、PowerBi、达芬奇
帆软FineBI官网:FineBI_BI数据可视化工具 - 帆软大数据分析平台解决方案
下载地址:免费下载FineBI - FineBI自助大数据分析工具
我的激活码:3a62c643-cb146dd90-f598-ccb44d281c60
连接数据库:
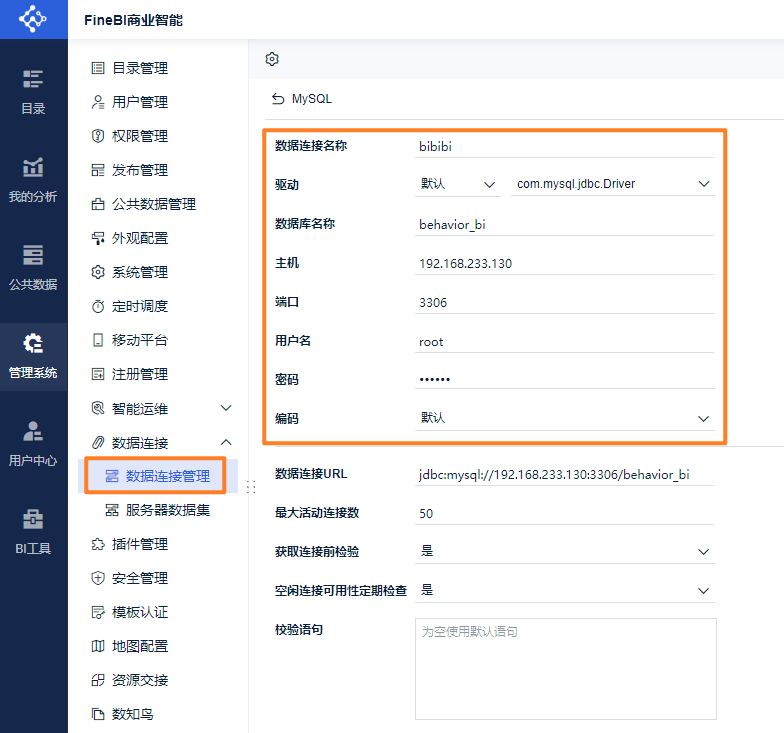
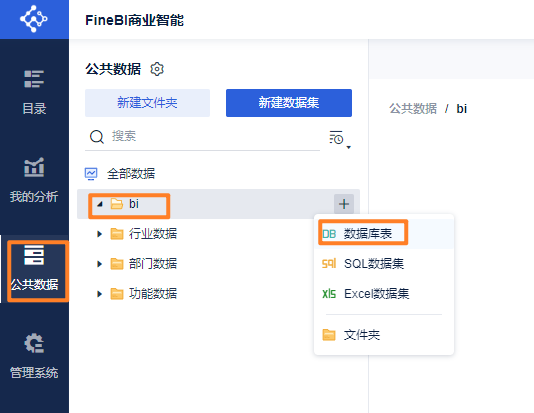
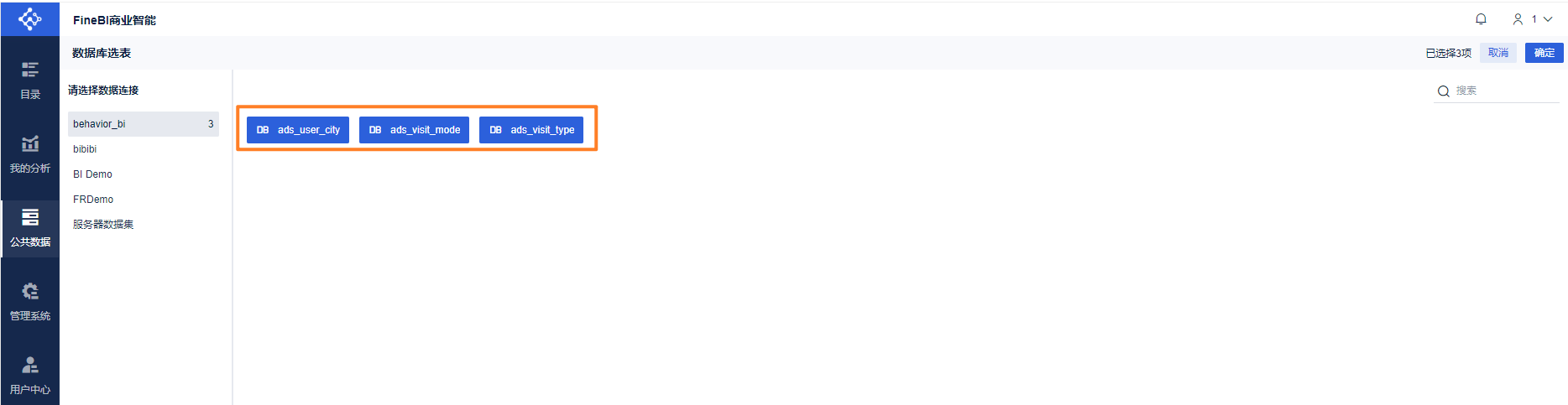
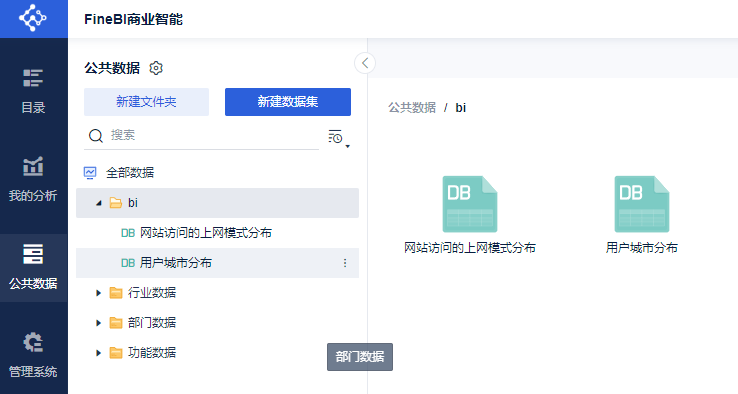
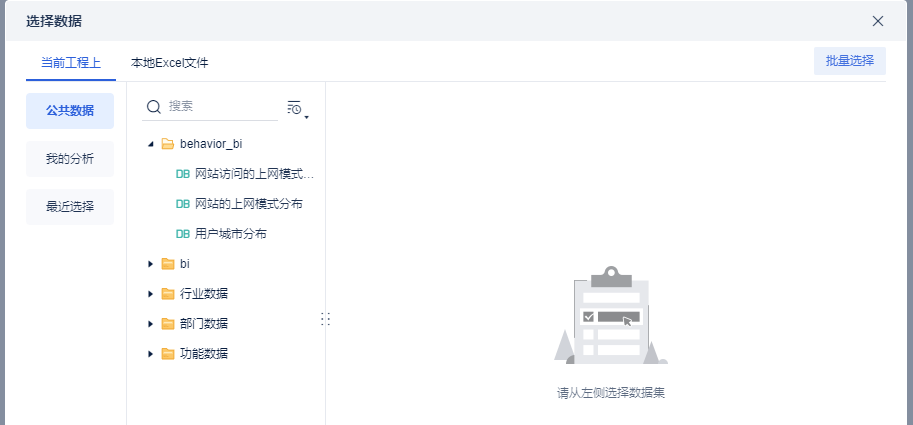
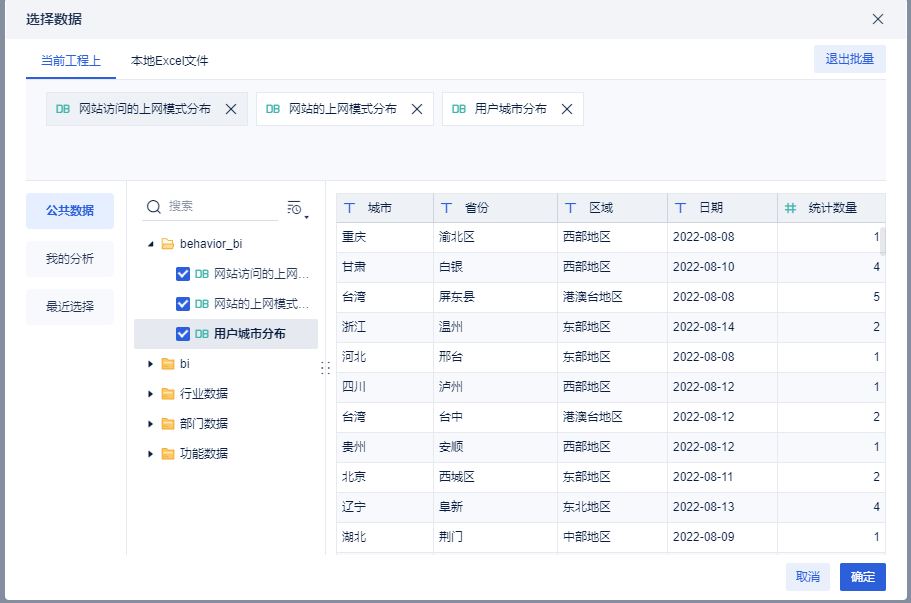
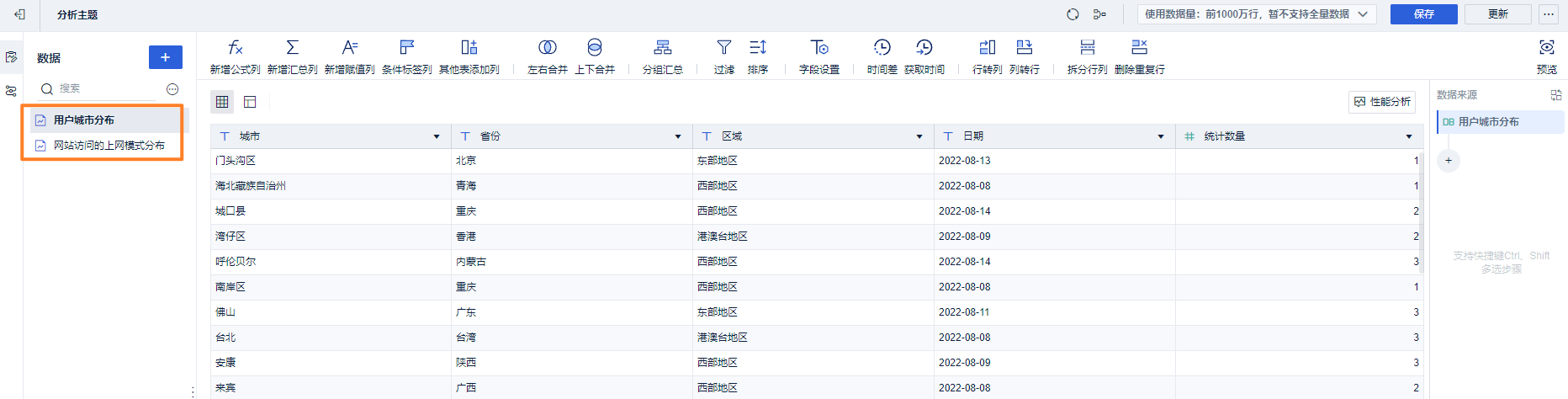
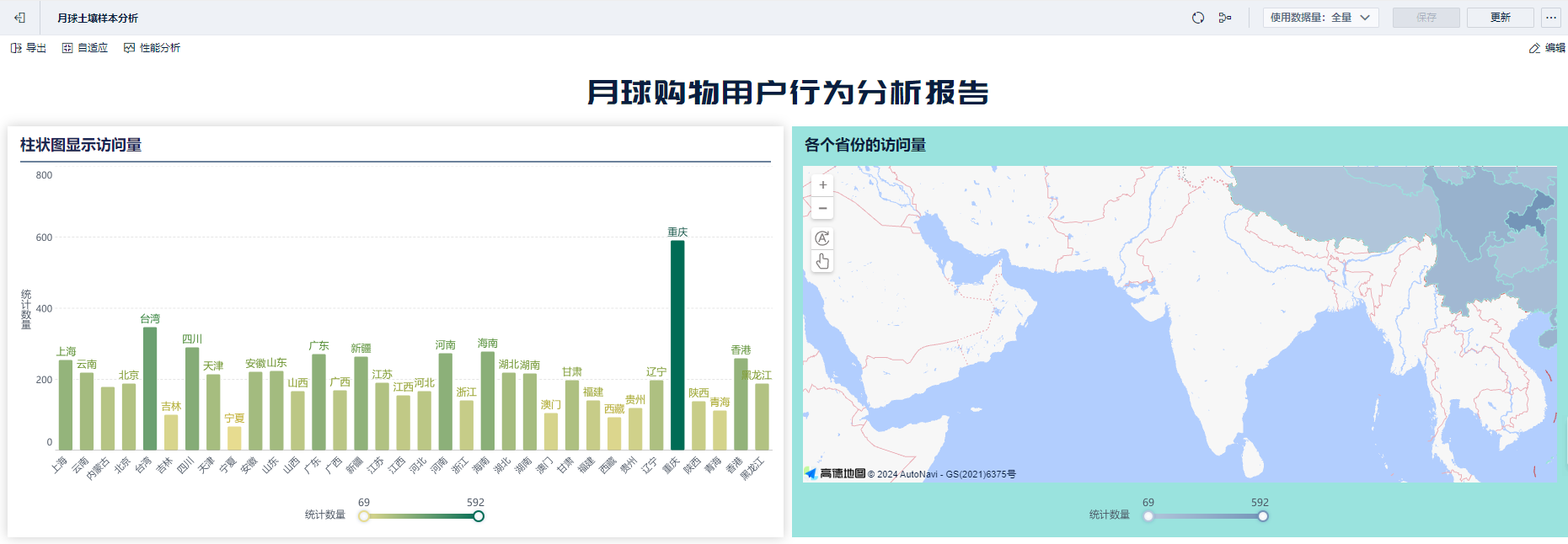
第一个指标:各个省份的数量统计
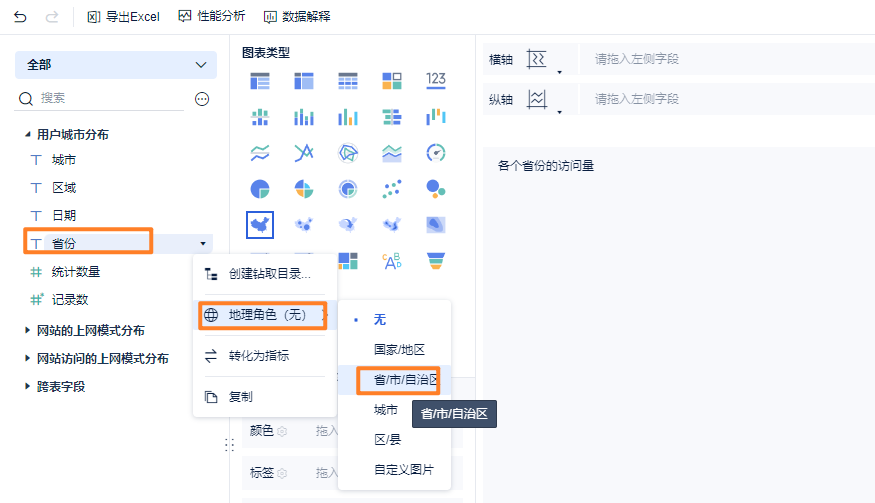
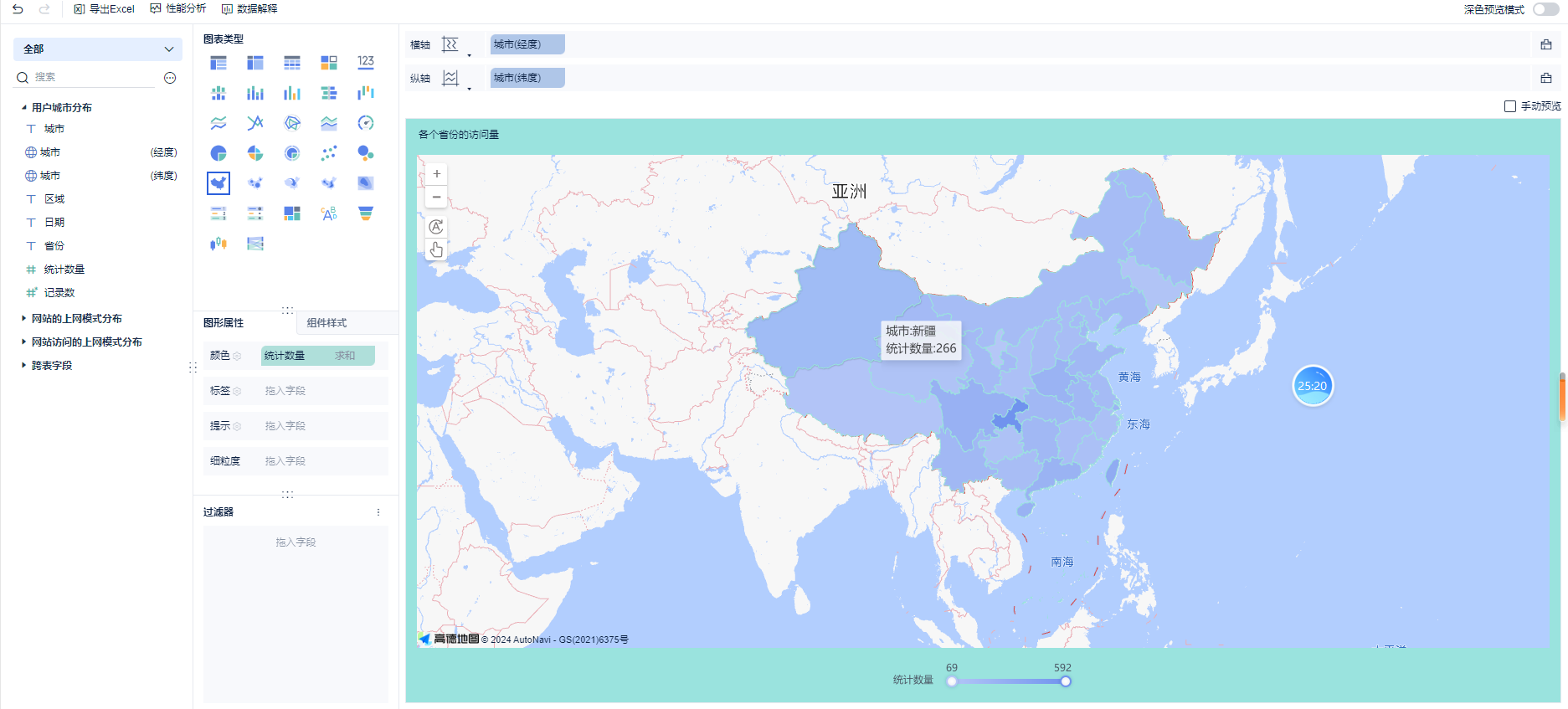
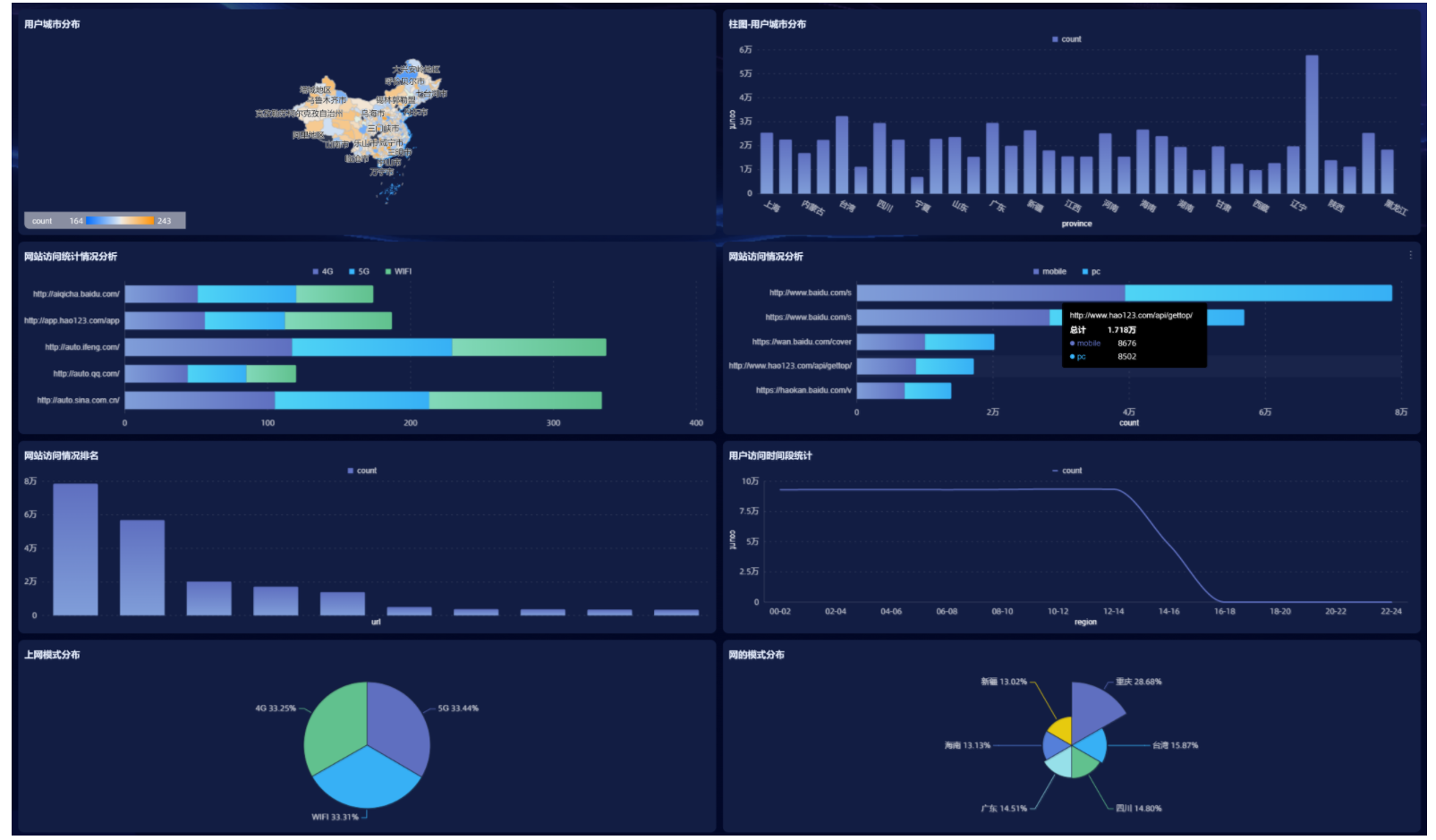
第二个指标:柱状图展示
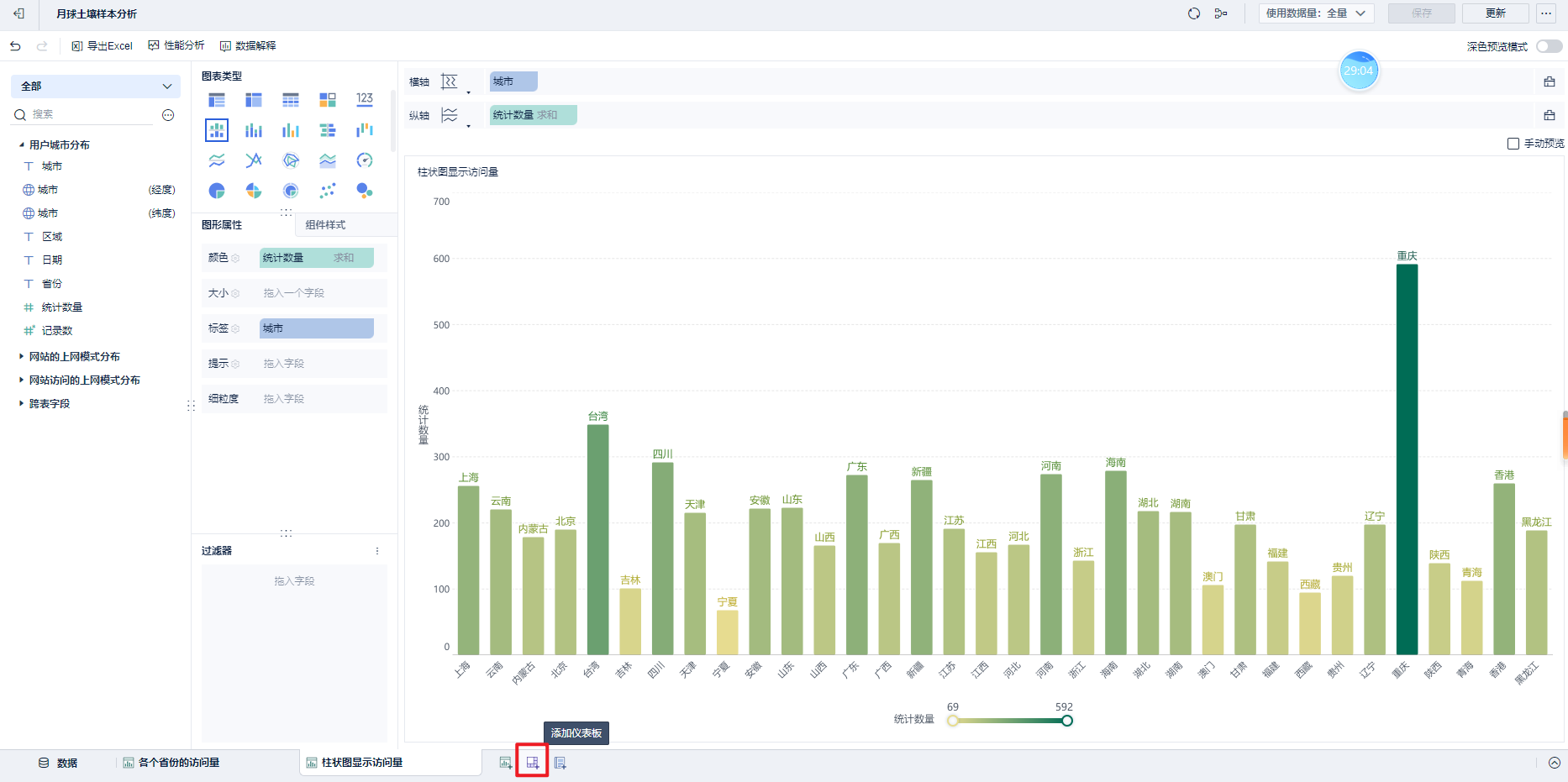
添加一个仪表盘:
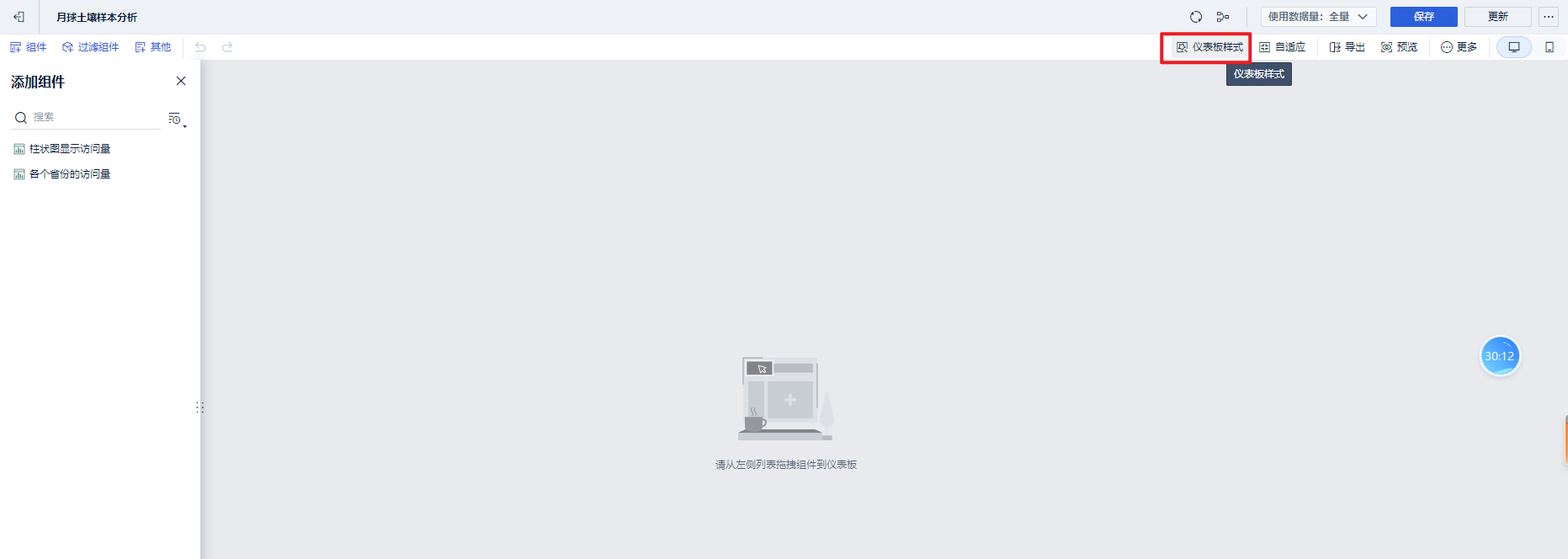
添加仪表盘样式,设置文本组件。

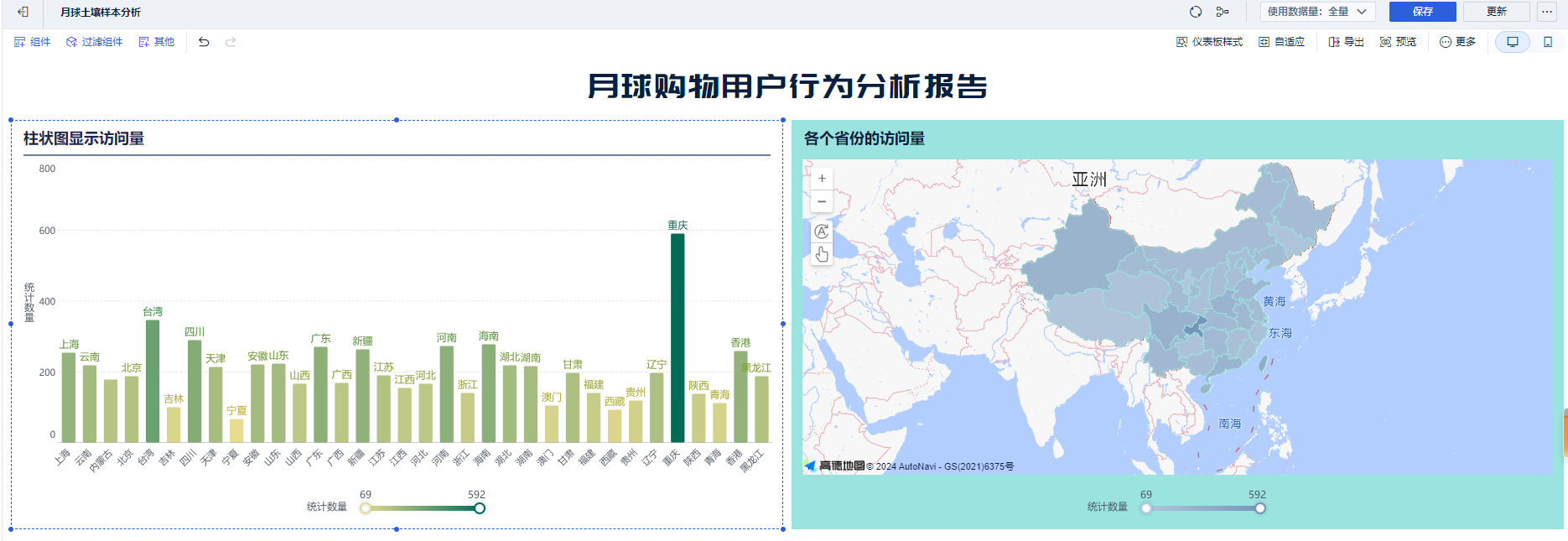
第三个指标:
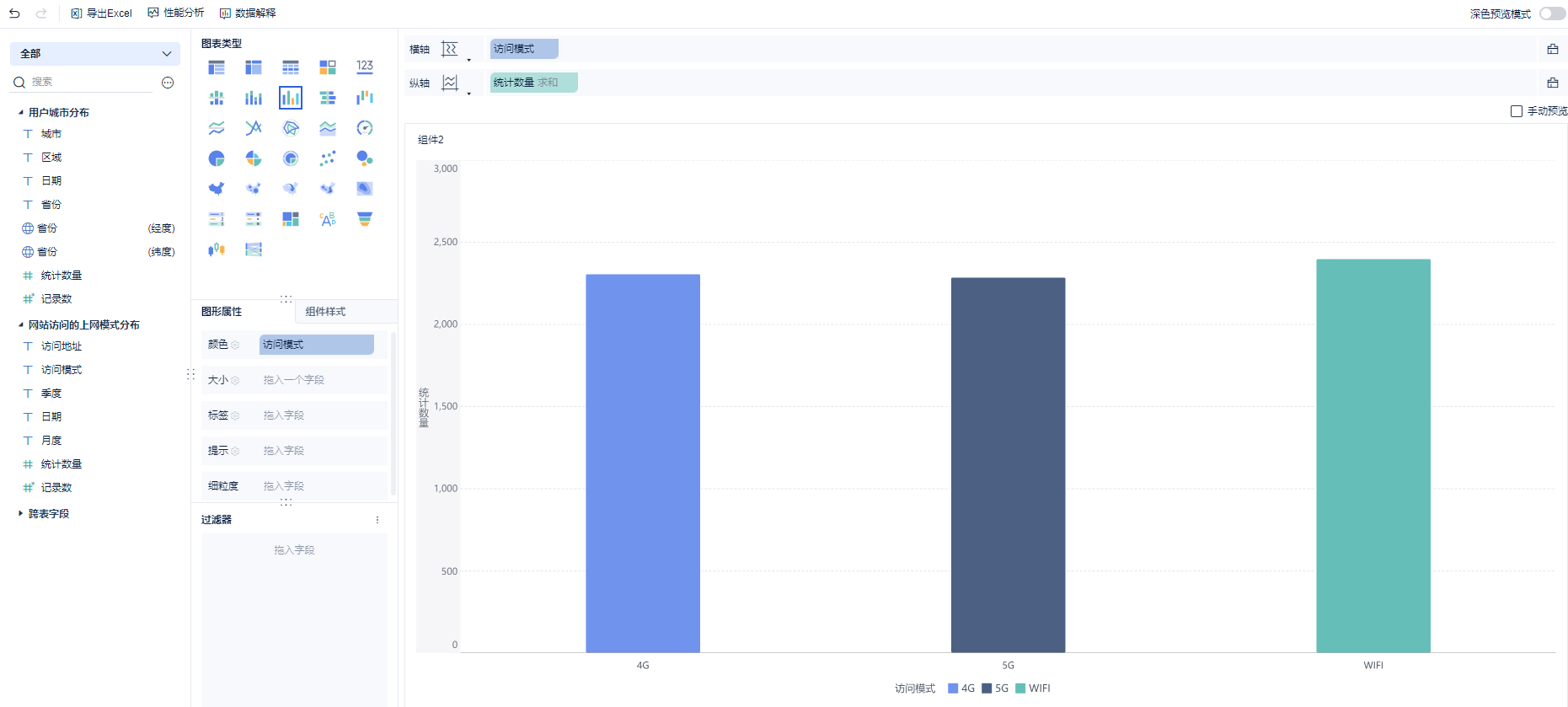
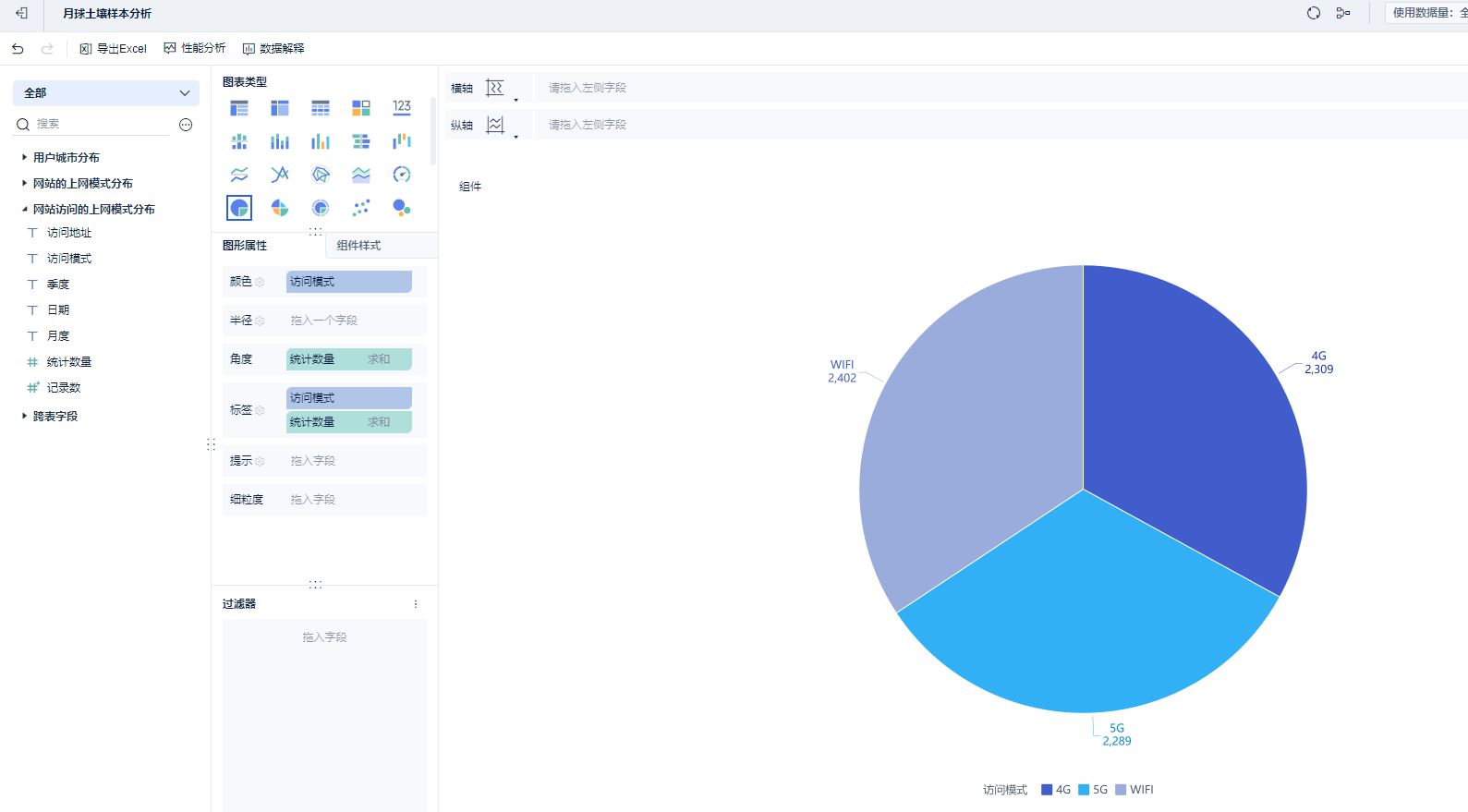
第四种展示形式:
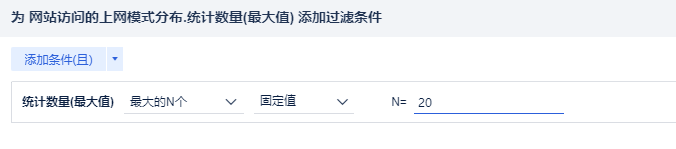
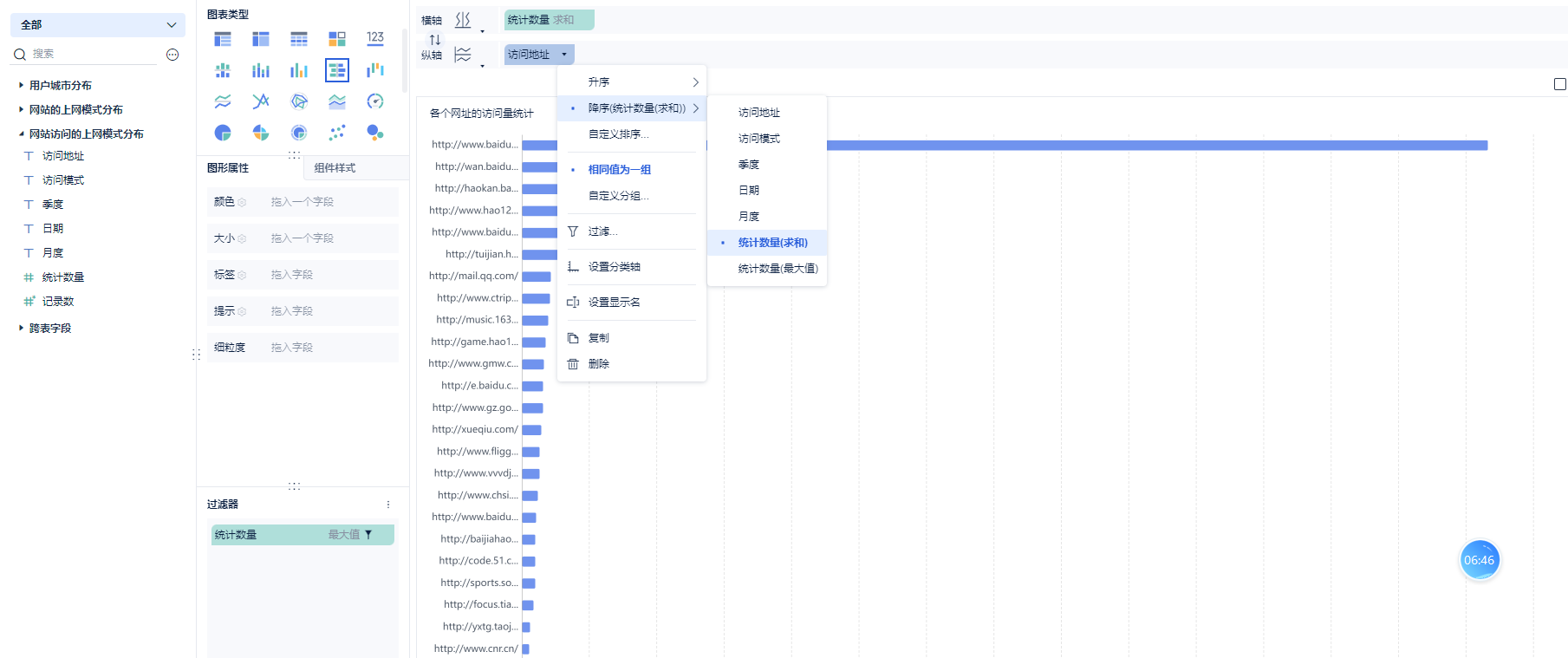
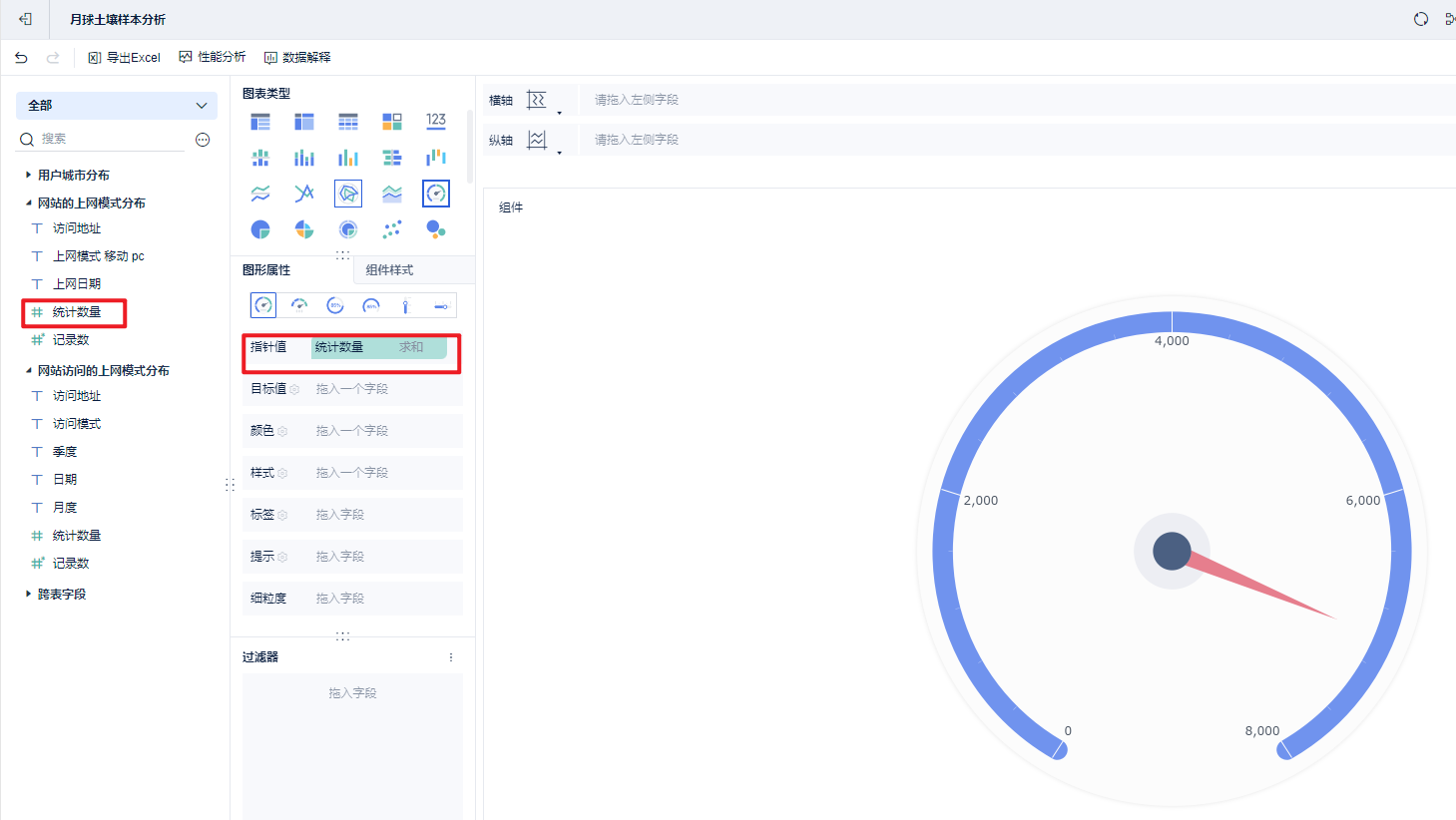
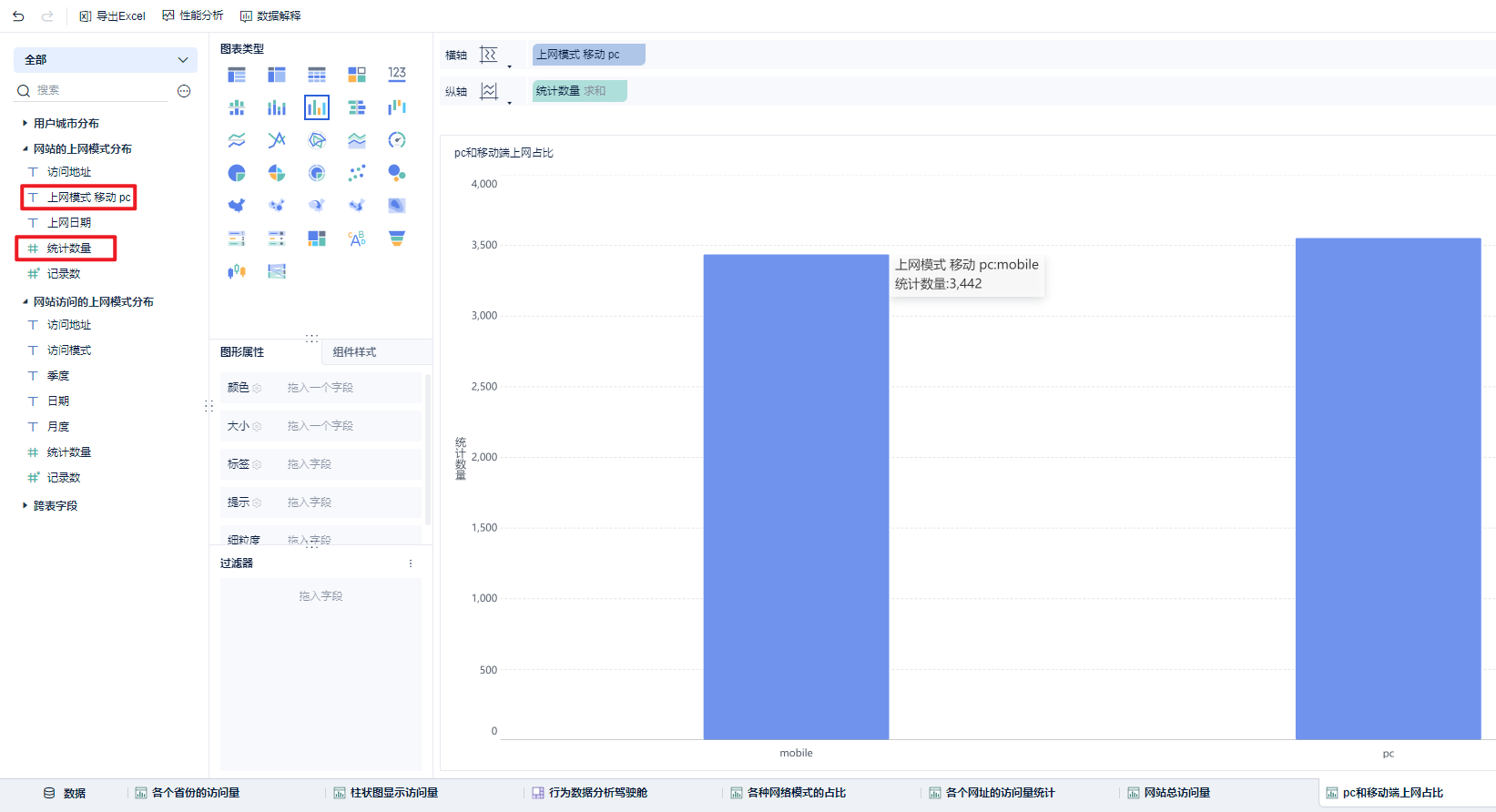
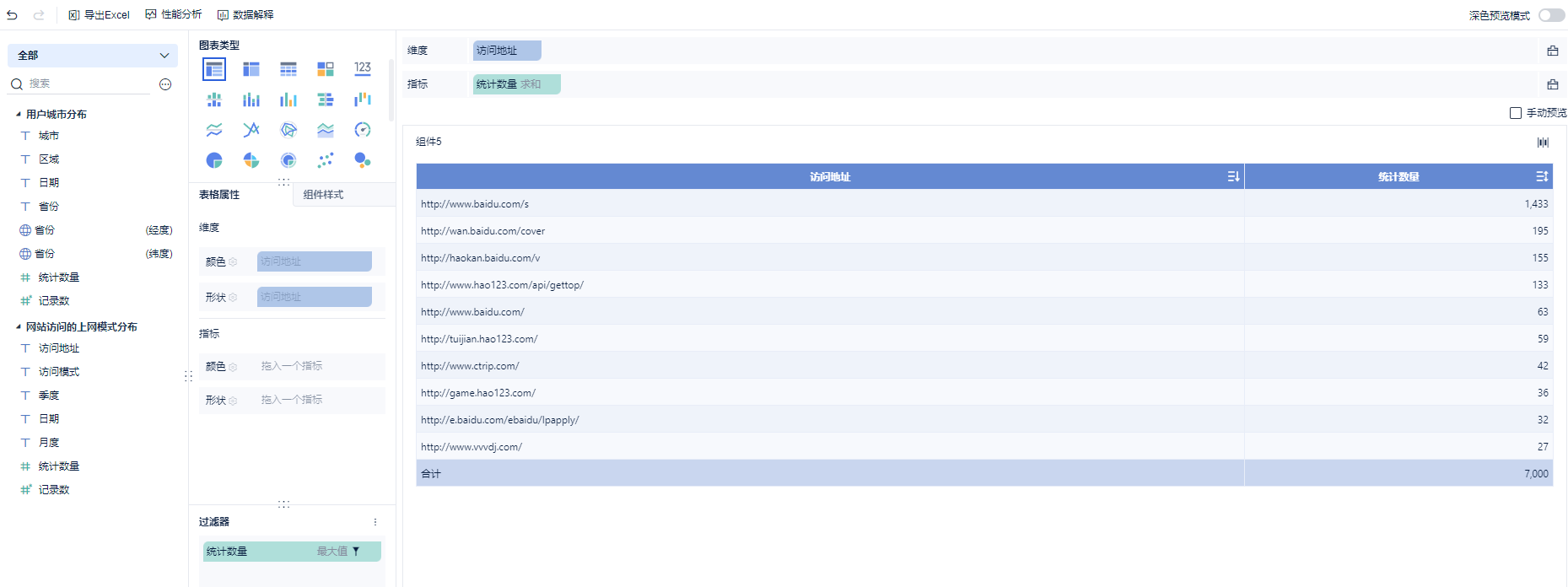
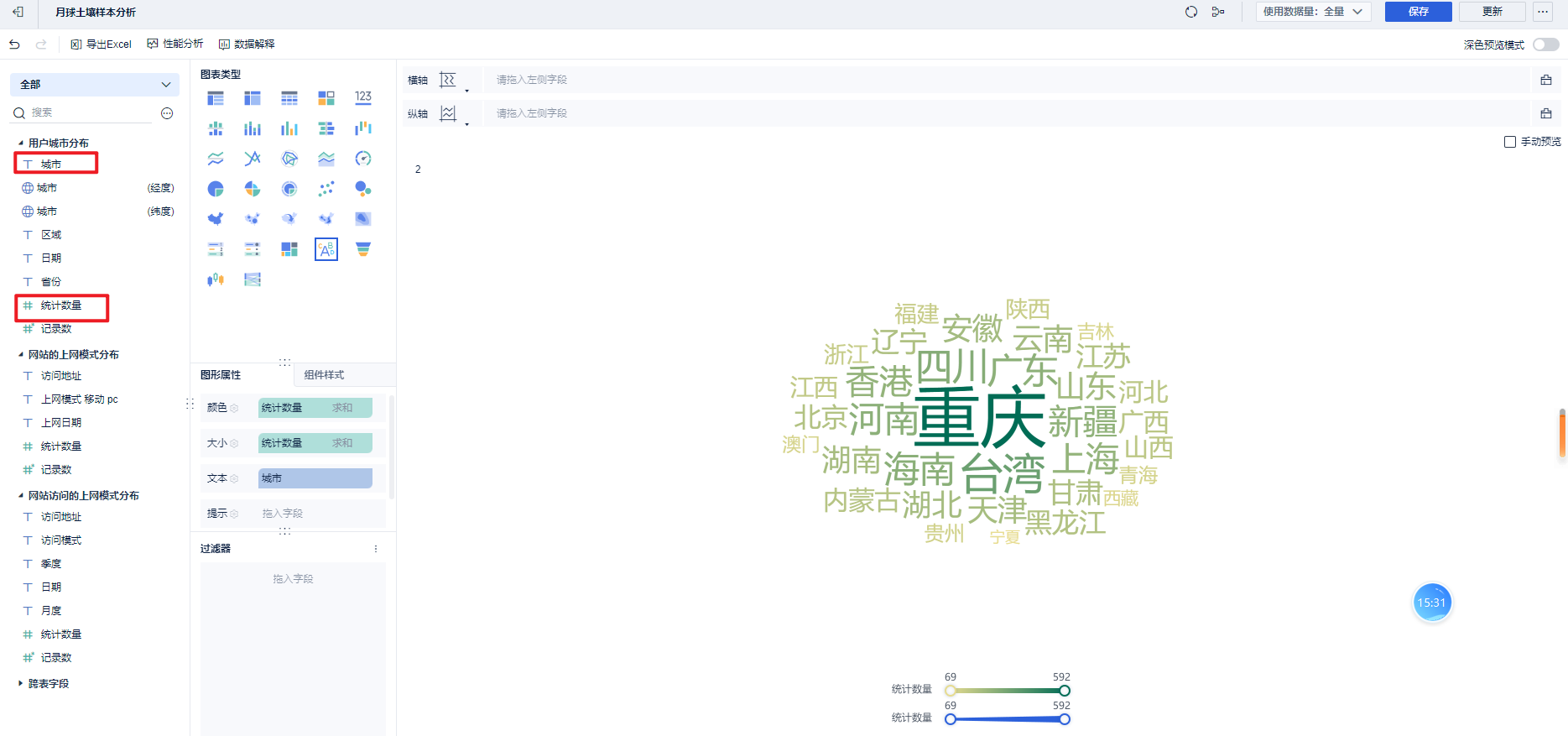
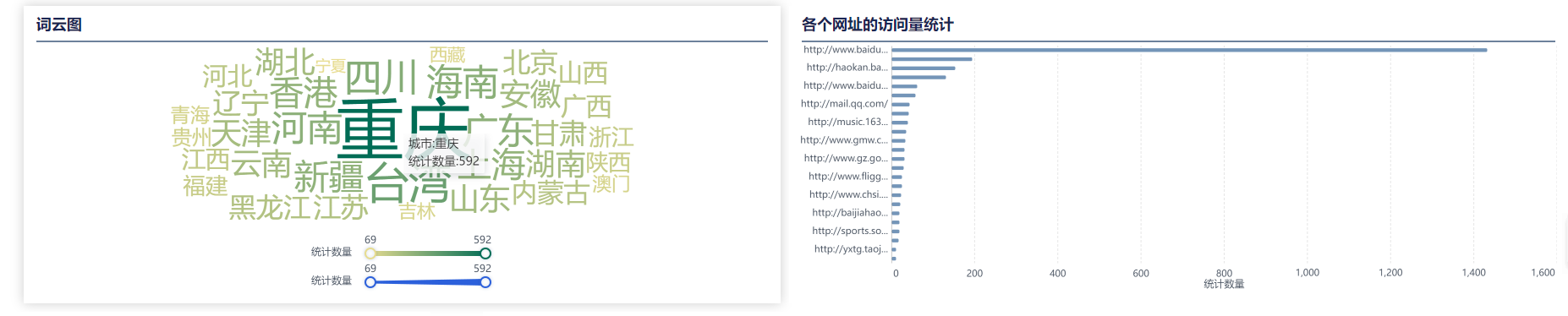
词云图:
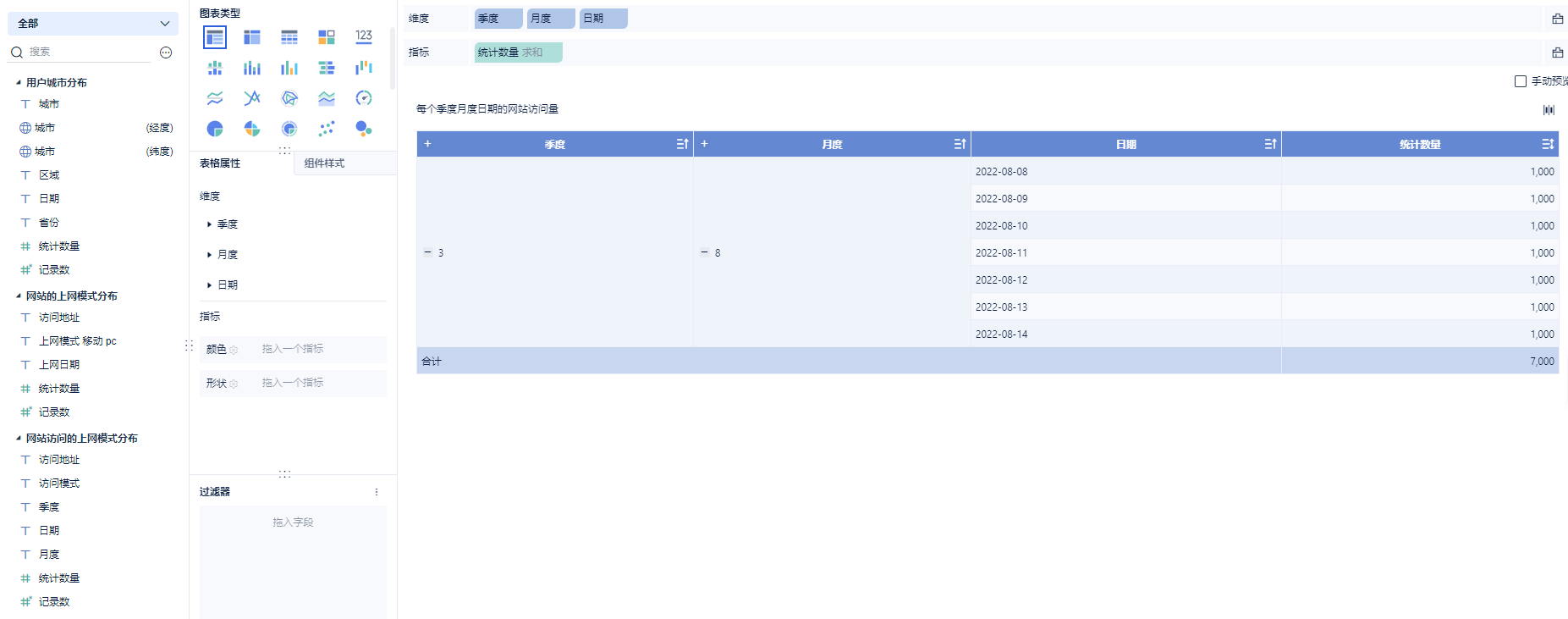
每个季度月度日期的网站访问量:
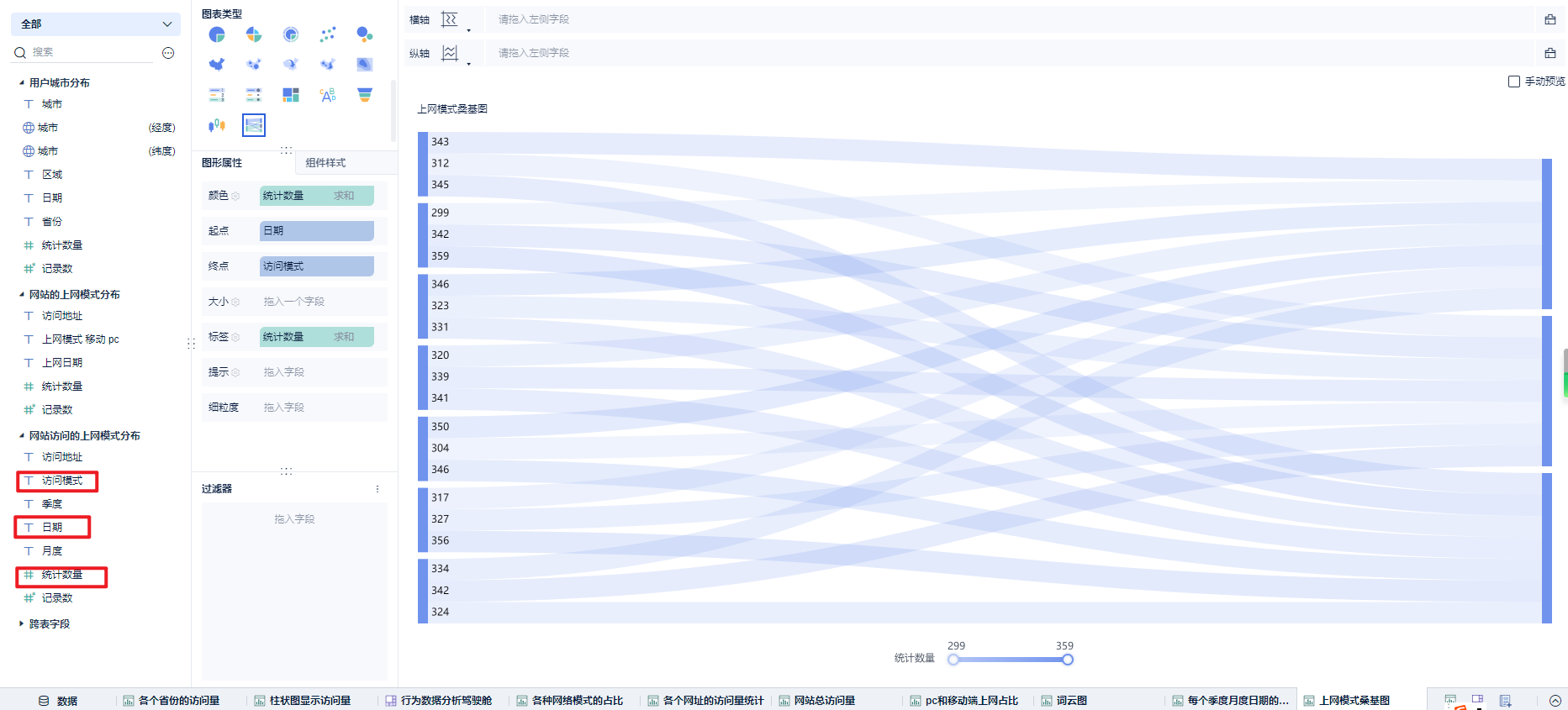
每天的访问方式的访问量统计:桑基图
6.3.4 展示图表




















 9330
9330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











