





 这篇博客主要介绍了在Python2中遇到的使用requests+xpath无法获取豆瓣电视剧数据的问题,并转向使用requests+json成功获取数据的解决方案。通过分析页面源代码和数据来源URL:https://movie.douban.com/j/search_subjects?type=tv&tag=热门&sort=recommend&page_limit=20&page_start=0,博主分享了如何利用json解析来实现数据的抓取。
这篇博客主要介绍了在Python2中遇到的使用requests+xpath无法获取豆瓣电视剧数据的问题,并转向使用requests+json成功获取数据的解决方案。通过分析页面源代码和数据来源URL:https://movie.douban.com/j/search_subjects?type=tv&tag=热门&sort=recommend&page_limit=20&page_start=0,博主分享了如何利用json解析来实现数据的抓取。
直接上代码,第一种方式获取不到数据。
#.*-coding:utf-8-*-
import requests
import re
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
from lxml import etree
class spider(object):
# 获取url对应的网页源码
def getsource(self,url):
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:52.0) Gecko/20100101 Firefox/52.0'}
source = requests.get(url, headers=headers)
return source.text
def getNeedInfo(self,sourceHtml):
selector = etree.HTML(sourceHtml)
print selector
result = etree.tostring(selector)
#print(result.decode("utf-8"))
fd = open("result.txt", "w")
fd.write(result.decode("utf-8"))
fd.close()
html_title = selector.xpath('//a[@class="item"]/div[@class="cover-wp"]/img//@alt')
print html_title
html_score = selector.xpath('//a[@class="item"]/p/strong')
print html_score
for i in html_title:
print i
if __name__ == '__main__':
spider = spider()
url = "https://movie.douban.com/tv/"
print '正在处理:'+ url
sourceHtml = spider.getsource(url)
spider.getNeedInfo(sourceHtml)
spider 遇到了问题,之前requests + xpath的方法获取不到相应的数据。
页面源代码如下
<script type="text/tmpl" id="subject-tmpl">
<% if (playable) { %>
<a class="item" target="_blank" href="<%= url%>?tag=<%= tag%>&from=gaia_video">
<% } else {%>
<a class="item" target="_blank" href="<%= url%>?tag=<%= tag%>&from=gaia">
<% } %>
<div class="cover-wp" data-isnew="<%= is_new%>" data-id="<%= id%>">
<img src="<%= cover%>" alt="<%= title%>" data-x="<%= cover_x%>" data-y="<%= cover_y%>"/>
</div>
<p>
<% if (is_new) { %>
<span class="green">
<img src="https://img3.doubanio.com/f/movie/caa8f80abecee1fc6f9d31924cef8dd9a24c7227/pics/movie/ic_new.png" width="16" class="new" />
</span>
<% } %>
<%= title%>
<% if (rate !== '') { %>
<strong><%= rate%></strong>
<% } else {%>
<span>暂无评分</span>
<% } %>
</p>
</a>
</script>查看页面元素
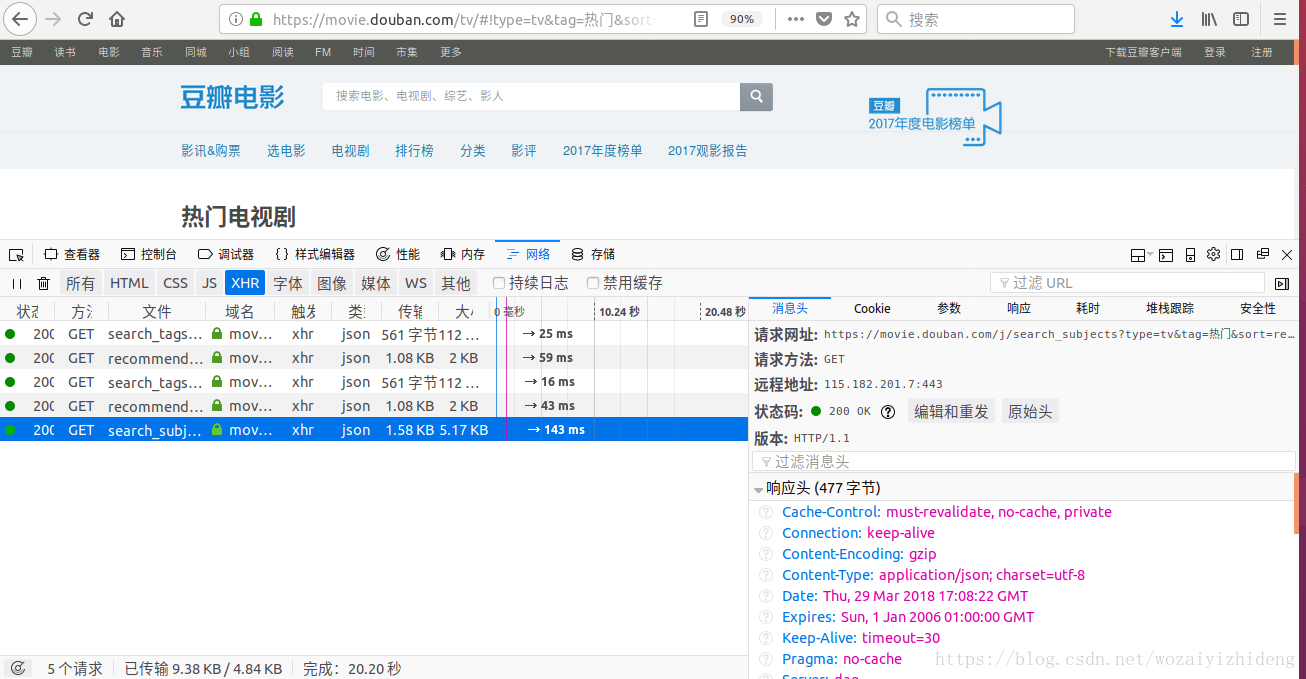
数据来源于下面这个网址:
https://movie.douban.com/j/search_subjects?type=tv&tag=热门&sort=recommend&page_limit=20&page_start=0
利用requests + json 实现数据获取
#!/usr/bin/python
# coding=utf-8
import requests
import json
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
#page_limit=20 最大值是500
url = 'https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%83%AD%E9%97%A8&sort=recommend&page_limit=20&page_start=0'
wbdata = requests.get(url).text
data = json.loads(wbdata)
print(type(data))
news = data["subjects"]
fd = open("douban-tv.txt", "w+")
for n in news:
print n['title'], n['rate'], n['url']
fd.write(n['title'])
fd.write(" ")
fd.write(n['rate'])
fd.write(" ")
fd.write(n['url'])
fd.write("\n")
fd.close()
$ python douban_tv.py
<type 'dict'>
迷雾 8.2 https://movie.douban.com/subject/27097811/
Unnatural 9.2 https://movie.douban.com/subject/27140017/
三国机密之潜龙在渊 6.5 https://movie.douban.com/subject/26801742/
硅谷 第五季 9.4 https://movie.douban.com/subject/27055699/
善良魔女传 6.3 https://movie.douban.com/subject/27613143/
Live 9.2 https://movie.douban.com/subject/27068596/
这!就是街舞 7.4 https://movie.douban.com/subject/27199901/
南方有乔木 5.3 https://movie.douban.com/subject/26765222/
热血街舞团 6.2 https://movie.douban.com/subject/27185291/
傲骨之战 第二季 9.6 https://movie.douban.com/subject/26997533/
老男孩 6.3 https://movie.douban.com/subject/27018233/
烈火如歌 5.3 https://movie.douban.com/subject/26703476/
美好生活 5.5 https://movie.douban.com/subject/26972555/
我的大叔 9.1 https://movie.douban.com/subject/27602137/
了不起的麦瑟尔夫人 第一季 8.8 https://movie.douban.com/subject/26813221/
粉雄救兵 第一季 9.2 https://movie.douban.com/subject/26964443/
加油吧威基基 8.8 https://movie.douban.com/subject/27603684/
天生一对 8.3 https://movie.douban.com/subject/26329065/
少年犯 9.1 https://movie.douban.com/subject/30145148/
我是大侦探 5.4 https://movie.douban.com/subject/30156707/

















 1868
1868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









