




 本文介绍了如何使用朴素贝叶斯进行文本分类,包括从文本构建词向量、计算概率、调整分类器及应用到垃圾邮件过滤和广告区域倾向分析。通过Python实现,涉及词袋模型和条件独立性假设。
本文介绍了如何使用朴素贝叶斯进行文本分类,包括从文本构建词向量、计算概率、调整分类器及应用到垃圾邮件过滤和广告区域倾向分析。通过Python实现,涉及词袋模型和条件独立性假设。
PS:该系列数据都可以在图灵社区(点击此链接)中随书下载中下载(如下)

1 基于贝叶斯决策理论的分类方法
朴素贝叶斯
优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据。
贝叶斯决策理论的核心思想:选择具有最高概率的决策。先行知识:朴素贝叶斯算法推导、极大似然估计详解。在进行实战之前可以先阅读这两篇博客进行理论学习,值得注意的是朴素(naive)的含义便是假设每个特征相互独立,具体见上面两篇博文。
2 使用Python进行文本分类
要从文本中获取特征,需要先拆分文本。这里的特则来自文本的词条(token),一个词条是字符的任意组合。可以把词条想象为单词,也可以使用非单词词条,如URL、IP地址或者任意其他字符串。然后将每一个文本片段表示为一个词条向量,其中值为1表示词条出现在文档中,0表示词条未出现。
以在线社区的留言板为例。为了不影响社区的发展,我们要屏蔽侮辱性的言论,所以要构建一个快速过滤器,如果某条留言使用了负面或者侮辱性的语言,那么就将该留言表示为内容不当。对此问题建立两个类别:侮辱类和非侮辱类,使用1和0分别表示。
2.1 准备数据:从文本中构建词向量
把文本看成单词向量或者词条向量,也就是说将句子转换为向量。创建bayes.py文件添加如下代码:
import numpy as np
def loadDataSet():
'''创建一些实验样本'''
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1] #1代表侮辱性文字,0代表正常言论
return postingList,classVec
def createVocabList(dataSet):
'''创建一个包含在所有文档中出现的不重复词的列表'''
#创建一个空集
vocabSet = set([])
for document in dataSet:
#创建两个集合的并集
vocabSet = vocabSet | set(document)
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
'''词表到向量的转换函数'''
returnVec = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print("the word: " + word + " is not in my Vocabulary!")
return returnVec
保存bayes.py文件,在python命令行下进行测试:
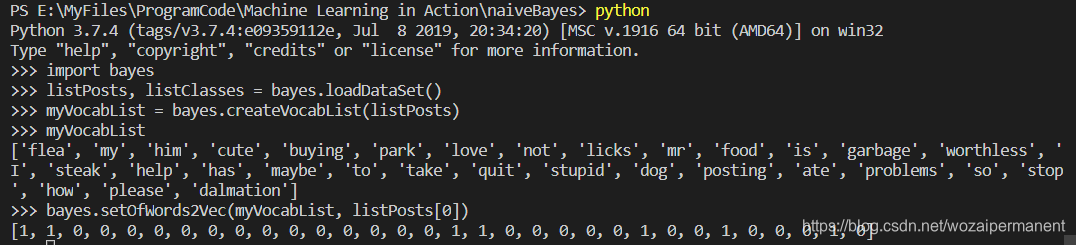
检查myVocabList会发现这里面不会出现重复的单词,由于该词表没有排序,所以运行结果里面词的顺序可能会不一样;然后调用createVocabList()函数为postList中的第一行言论构建一个词向量。
2.2 训练算法:从词向量计算概率
现在已经知道了一个词是否出现在一篇文档中,也知道该文档所属的类别。根据贝叶斯准则:
p ( c i ∣ w ⃗ ) = p ( w ⃗ ∣ c i ) p ( c i ) p ( w ⃗ ) p(c_i|\vec w) = \frac{p(\vec w|c_i)p(c_i)}{p(\vec w)} p(ci∣w)=p(w)p(w∣ci)p(ci)
其中 w ⃗ \vec w w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 817
817

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









