




code1 :
title = "This is a test sentence."
with open(r'title.txt', "a+") as f:
f.write(title)
f.close()

code2 :
output = '\t'.join(['name','title','age','gender'])
print (output)
with open('test.txt', "a+") as f:
f.write(output)
f.close()
code3:
with open(r'title.txt', "r", encoding ='utf-8') as f:
result = f.read()
print (result)
code4:
import csv
output_list = ['1', '2','3','4']
with open('test2.csv', 'a+', encoding='utf-8', newline='') as csvfile:
w = csv.writer(csvfile)
w.writerow(output_list)
读数据:
import csv
with open('test.csv', 'r',encoding='utf-8') as csvfile:
csv_reader = csv.reader(csvfile)
for row in csv_reader:
print(row)
print(row[0])
数据库:
mysql> CREATE DATABASE scraping;
Query OK, 1 row affected (0.02 sec)
mysql> USE scraping;
Database changed
mysql> CREATE TABLE urls(
-> id INT NOT NULL AUTO_INCREMENT,
-> url VARCHAR(1000) NOT NULL,
-> content VARCHAR(4000) NOT NULL,
-> created_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
-> PRIMARY KEY (id)
-> );
Query OK, 0 rows affected (0.08 sec)
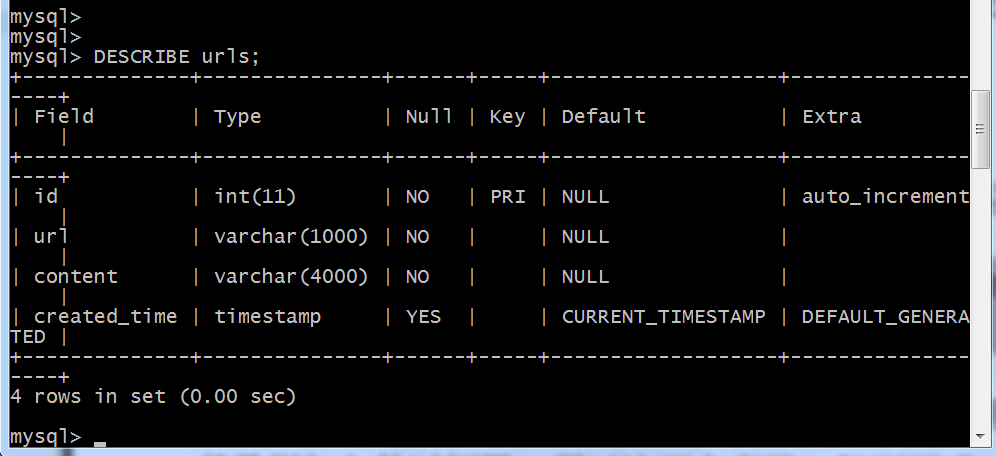
mysql> DESCRIBE urls;
mysql>
mysql>
mysql> INSERT INTO urls (url, content) VALUES ("www.baidu.com","这是内容");
Query OK, 1 row affected (0.01 sec)
mysql>
mysql>
mysql>
mysql> SELECT * FROM urls WHERE id=1;
+----+---------------+--------------+---------------------+
| id | url | content | created_time |
+----+---------------+--------------+---------------------+
| 1 | www.baidu.com | 这是内容 | 2019-08-23 12:29:47 |
+----+---------------+--------------+---------------------+
1 row in set (0.00 sec)
mysql>
mysql>
mysql>
mysql>
mysql> SELECT url,content FROM urls WHERE id=1;
+---------------+--------------+
| url | content |
+---------------+--------------+
| www.baidu.com | 这是内容 |
+---------------+--------------+
1 row in set (0.00 sec)
mysql>
mysql>
mysql>
mysql>
mysql> SELECT id,url FROM urls WHERE content LIKE "%内容%";
+----+---------------+
| id | url |
+----+---------------+
| 1 | www.baidu.com |
+----+---------------+
1 row in set (0.00 sec)
mysql>
mysql>
mysql> DELETE FROM urls WHERE url="www.baidu.com";
Query OK, 1 row affected (0.01 sec)
mysql>
mysql>
mysql> INSERT INTO urls (url,content) VALUES ("www.santostang.com","Santos blog"
);
Query OK, 1 row affected (0.01 sec)
mysql>
mysql> UPDATE urls SET url="www.google.com",content="Google" WHERE id = 2;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql>
深入学习:
http://www.runoob.com/mysql/mysql-tutorial.html
mysql> SELECT * FROM scraping.urls;
+----+----------------+------------------+---------------------+
| id | url | content | created_time |
+----+----------------+------------------+---------------------+
| 2 | www.google.com | Google | 2019-08-23 12:39:05 |
| 3 | www.baidu.com | This is content. | 2019-08-23 14:25:23 |
+----+----------------+------------------+---------------------+
2 rows in set (0.00 sec)
mysql>
代码:
import pymysql
# 打开数据库连接
db = pymysql.connect("localhost", "root", "1234", "scraping")
# 使用cursor()方法获取操作游标
cursor = db.cursor()
# SQL 插入语句
sql = """INSERT INTO urls (url, content) VALUES ('www.baidu.com', 'This is content.')"""
try:
# 执行sql语句
cursor.execute(sql)
# 提交到数据库执行
db.commit()
except:
# 如果发生错误则回滚
db.rollback()
# 关闭数据库连接
db.close()
代码:
import requests
from bs4 import BeautifulSoup
import pymysql
db = pymysql.connect("localhost", "root", "1234", "scraping")
cursor = db.cursor()
link = "http://www.santostang.com/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'}
r = requests.get(link, headers=headers)
soup = BeautifulSoup(r.text, "lxml")
title_list = soup.find_all("h1", class_="post-title")
print (title_list)
for eachone in title_list:
url = eachone.a['href']
title = eachone.a.text.strip()
cursor.execute("INSERT INTO urls (url, content) VALUES (%s, %s)", (url, title))
db.commit()
db.close()

















 1652
1652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









