




回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。 在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
在机器学习领域中的大多数任务通常都与预测(prediction)有关。 当我们想预测一个数值时,就会涉及到回归问题。 常见的例子包括:预测价格(房屋、股票等)、预测住院时间(针对住院病人等)、 预测需求(零售销量等)。 但不是所有的预测都是回归问题。 在后面的章节中,我们将介绍分类问题。分类问题的目标是预测数据属于一组类别中的哪一个。
线性回归的基本元素
线性回归(linear regression)可以追溯到19世纪初, 它在回归的各种标准工具中最简单而且最流行。 线性回归基于几个简单的假设: 首先,假设自变量x和因变量y之间的关系是线性的, 即y可以表示为x中元素的加权和,这里通常允许包含观测值的一些噪声; 其次,我们假设任何噪声都比较正常,如噪声遵循正态分布。
为了解释线性回归,我们举一个实际的例子: 我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。 为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。 这个数据集包括了房屋的销售价格、面积和房龄。 在机器学习的术语中,该数据集称为训练数据集(training data set) 或训练集(training set)。 每行数据(比如一次房屋交易相对应的数据)称为样本(sample), 也可以称为数据点(data point)或数据样本(data instance)。 我们把试图预测的目标(比如预测房屋价格)称为标签(label)或目标(target)。 预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。

线性模型
线性假设是指目标(房屋价格)可以表示为特征(面积和房龄)的加权和,如下面的式子:
这个过程中的求和将使用广播机制 (广播机制在数据操作中有详细介绍)。 给定训练数据特征X和对应的已知标签y, 线性回归的目标是找到一组权重向量w和偏置b: 当给定从X的同分布中取样的新样本特征时, 这组权重向量和偏置能够使得新样本预测标签的误差尽可能小。

损失函数
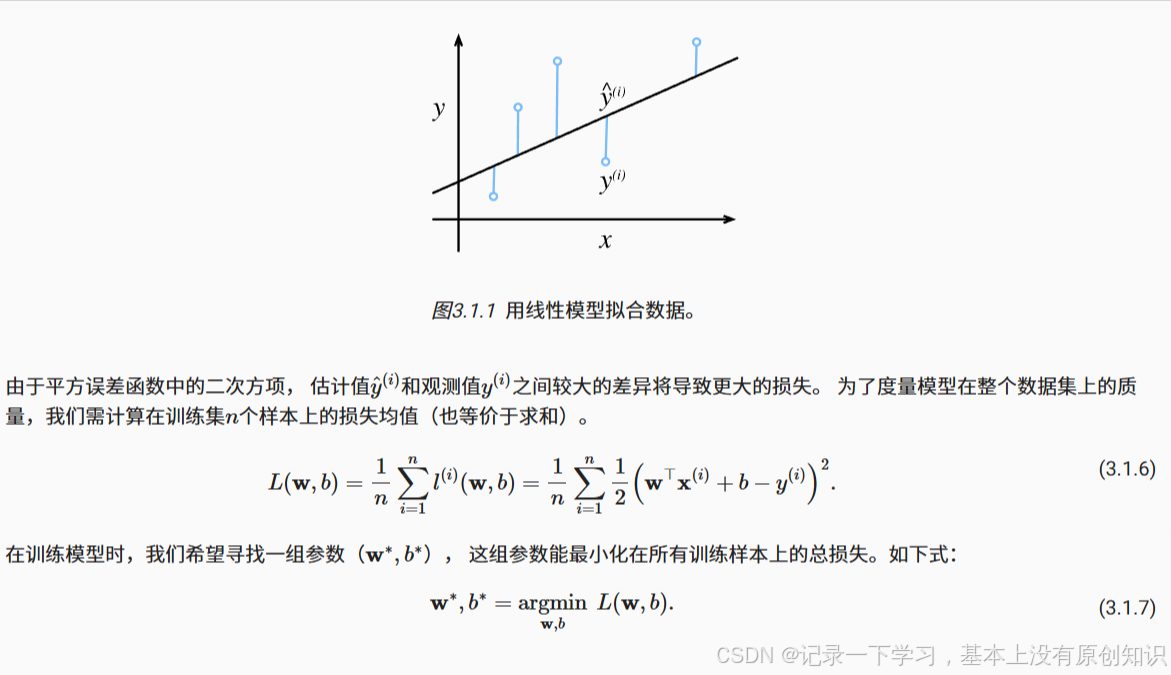
在我们开始考虑如何用模型拟合(fit)数据之前,我们需要确定一个拟合程度的度量。 损失函数(loss function)能够量化目标的实际值与预测值之间的差距。 通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。 回归问题中最常用的损失函数是平方误差函数。

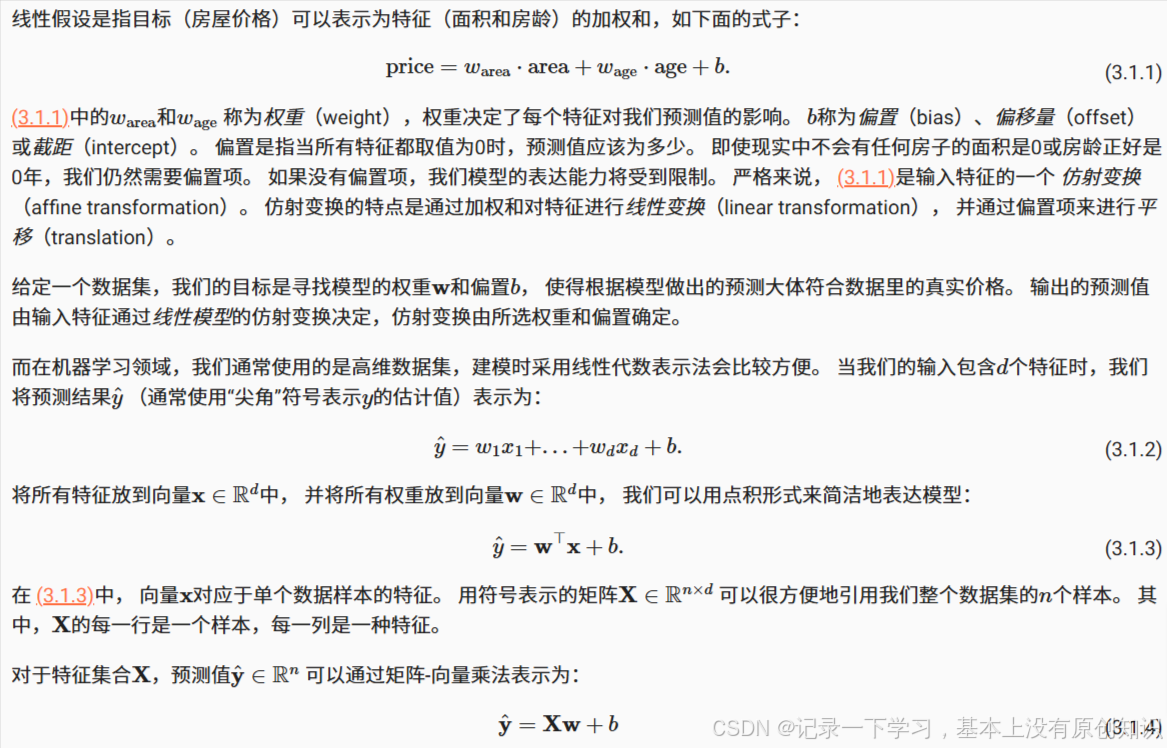
常数1/2不会带来本质的差别,但这样在形式上稍微简单一些 (因为当我们对损失函数求导后常数系数为1)。 由于训练数据集并不受我们控制,所以经验误差只是关于模型参数的函数。 为了进一步说明,来看下面的例子。 我们为一维情况下的回归问题绘制图像,如 图3.1.1所示。
解析解

随机梯度下降
即使在我们无法得到解析解的情况下,我们仍然可以有效地训练模型。 在许多任务上,那些难以优化的模型效果要更好。 因此,弄清楚如何训练这些难以优化的模型是非常重要的。
本书中我们用到一种名为梯度下降(gradient descent)的方法, 这种方法几乎可以优化所有深度学习模型。 它通过不断地在损失函数递减的方向上更新参数来降低误差。
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值) 关于模型参数的导数(在这里也可以称为梯度)。 但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。 因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本, 这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)。

线性回归恰好是一个在整个域中只有一个最小值的学习问题。 但是对像深度神经网络这样复杂的模型来说,损失平面上通常包含多个最小值。 深度学习实践者很少会去花费大力气寻找这样一组参数,使得在训练集上的损失达到最小。 事实上,更难做到的是找到一组参数,这组参数能够在我们从未见过的数据上实现较低的损失, 这一挑战被称为泛化(generalization)。
矢量化加速
在训练我们的模型时,我们经常希望能够同时处理整个小批量的样本。 为了实现这一点,需要我们对计算进行矢量化, 从而利用线性代数库,而不是在Python中编写开销高昂的for循环。
为了说明矢量化为什么如此重要,我们考虑对向量相加的两种方法。 我们实例化两个全为1的10000维向量。 在一种方法中,我们将使用Python的for循环遍历向量; 在另一种方法中,我们将依赖对+的调用。
%matplotlib inline
import math
import time
import numpy as np
import torch
from d2l import torch as d2l
n = 10000
a = torch.ones([n])
b = torch.ones([n])
由于在本书中我们将频繁地进行运行时间的基准测试,所以我们定义一个计时器:
class Timer: #@save
"""记录多次运行时间"""
def __init__(self):
self.times = []
self.start()
def start(self):
"""启动计时器"""
self.tik = time.time()
def stop(self):
"""停止计时器并将时间记录在列表中"""
self.times.append(time.time() - self.tik)
return self.times[-1]
def avg(self):
"""返回平均时间"""
return sum(self.times) / len(self.times)
def sum(self):
"""返回时间总和"""
return sum(self.times)
def cumsum(self):
"""返回累计时间"""
return np.array(self.times).cumsum().tolist()
现在我们可以对工作负载进行基准测试。
首先,我们使用for循环,每次执行一位的加法。
c = torch.zeros(n)
timer = Timer()
for i in range(n):
c[i] = a[i] + b[i]
f'{timer.stop():.5f} sec'
输出结果为
'0.16749 sec'
或者,我们使用重载的+运算符来计算按元素的和。
timer.start()
d = a + b
f'{timer.stop():.5f} sec'
输出结果为
'0.00042 sec'
结果很明显,第二种方法比第一种方法快得多。 矢量化代码通常会带来数量级的加速。 另外,我们将更多的数学运算放到库中,而无须自己编写那么多的计算,从而减少了出错的可能性。
从线性回归到深度网络
到目前为止,我们只谈论了线性模型。 尽管神经网络涵盖了更多更为丰富的模型,我们依然可以用描述神经网络的方式来描述线性模型, 从而把线性模型看作一个神经网络。 首先,我们用“层”符号来重写这个模型。
深度学习从业者喜欢绘制图表来可视化模型中正在发生的事情。 在 图3.1.2中,我们将线性回归模型描述为一个神经网络。 需要注意的是,该图只显示连接模式,即只显示每个输入如何连接到输出,隐去了权重和偏置的值。
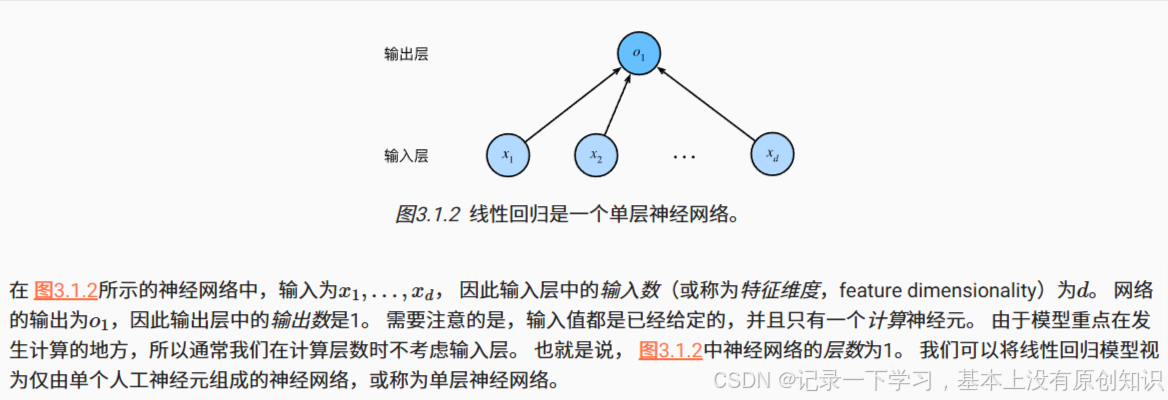
对于线性回归,每个输入都与每个输出(在本例中只有一个输出)相连, 我们将这种变换( 图3.1.2中的输出层) 称为全连接层(fully-connected layer)或称为稠密层(dense layer)。 后面将详细讨论由这些层组成的网络。

















 919
919

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









