




 本文介绍了在5G网络中,如何通过提出一种基于深度强化学习的MAP-DRL算法来改进学习型自适应视频流的鲁棒性。该算法利用双PPO和网络结构优化,以应对网络波动带来的挑战,有效提高视频质量和减少重缓冲。实验结果表明,MAP-DRL在各种网络条件和QoE指标下表现优于传统方法。
本文介绍了在5G网络中,如何通过提出一种基于深度强化学习的MAP-DRL算法来改进学习型自适应视频流的鲁棒性。该算法利用双PPO和网络结构优化,以应对网络波动带来的挑战,有效提高视频质量和减少重缓冲。实验结果表明,MAP-DRL在各种网络条件和QoE指标下表现优于传统方法。
1题目、作者与会议信息
2023 IEEE International Conference on Multimedia and Expo (ICME)
Improving robustness of learning-based adaptive video streaming in wildly fluctuating networks

2 背景
1.基于HTTP的动态自适应流(DASH)被认为是在异构网络条件下传输视频的一种有前途的技术。
2.5G尤其是商用毫米波5G确实可以提供超高带宽,但由于信号的阻塞等环境因素,尤其是在设备移动时,通常会出现较大的波动
3挑战
5G网络通常会出现较大的波动使基于学习的ABR无法保持高性能
4贡献
1提出了一种鲁棒的ABR算法MAP-DRL,可以处理不同的网络条件;采用DualPPO和几种强化学习设计,如优势函数归一化和奖励缩放,使ABR能够从各种移动网络中学习
2提出了不同的网络结构来处理演员和评论家网络的多种类型数据以进一步利用有限的环境反馈
5系统建模
5.1 概述
如图1所示,服务器中的一个源视频被分成I块,每个块包含L秒的视频内容。每个块被编码成具有不同比特率的多个副本,以便客户端ABR算法可以选择块的适当版本。为了表示简单,我们将比特率级别的有限集合表示为R = {R1, R2,…R|R’|}。在不失一般性的前提下,我们假设R1 > R2 >…> R|R’|, ri∈R’为块i = 1的比特率级别。
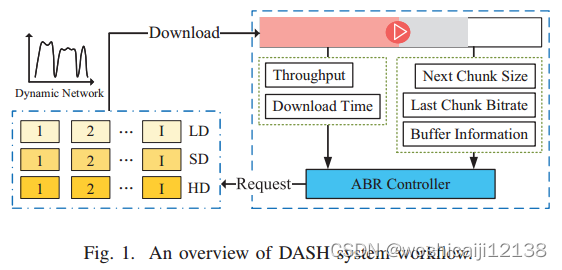
在视频流中,下载一个块的时间计算如下:
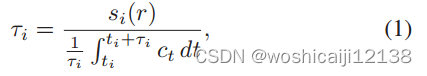
其中si®为比特率为r的副本的块大小,ti为下载第i个块的开始时间,ct为时刻t的下行带宽。
缓冲区占用bi描述了当玩家开始下载数据块i时缓冲的视频时间。当用户观看视频时,缓冲区被耗尽,每当下载数据块时,缓冲区将被L秒填充。缓冲区占用率的演变过程如下:
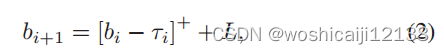
式中bi∈[L, B], B为缓冲容量。请注意,如果bi+1 < τi,则缓冲区在下载期间耗尽,播放器将继续重新缓冲,直到新块到达。
5.2问题表述
ABR算法的目标是生成一个策略π,以最大化整个视频会话的QoE。为了与基本ABR算法直接比较,我们定义了[7]使用的累积QoE目标函数:
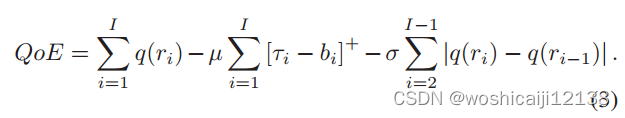
第一项是比特率级别,其中q(ri)表示块i的第ri个比特率副本的视频质量函数。基本上,更高的比特率有助于改善QoE。第二项表示重新缓冲时间。从第三项开始计算视频质量的变化。符号μ和σ分别是重缓冲和变异惩罚的权重。
综上所述,总体目标的优化问题可描述为:
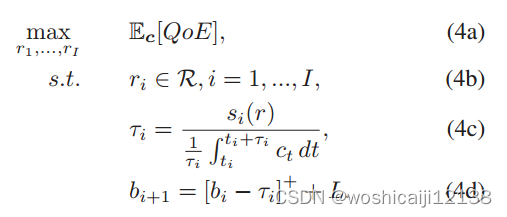
5.3马尔可夫决策过程(MDP)
基于来自环境的信息(例如,最后一个块比特率,重新缓冲时间),ABR算法确定下一个块的比特率,以最大化整个视频会话的QoE。因此,比特率问题可以很自然地表述为MDP问题。在这一过程中,涉及到环境状态、行动、奖励函数和折扣因素四个要素。
1)状态:具体来说,agent根据以下观察来确定每个块i的比特率决策,即状态si:

2)动作:对于自适应视频流任务,动作定义如下:

3)奖励:当客户端根据状态选择比特率作为操作时,环境提供奖励作为反馈,以指示当前操作的值。我们将第i块的奖励函数表示为:
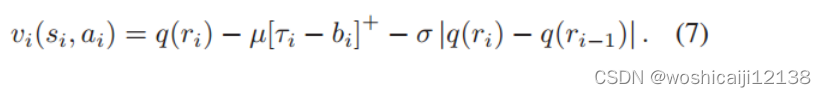
最终,ABR代理agent的目标是通过解决以下MDP问题来找到最优策略π:

5.4DRL算法
采用深度强化学习算法来求解(P1)。
特别是,我们利用基于行动者批评家的近端策略优化(PPO)来训练神经网络(NN)。
以θ为参数的演员网络负责学习策略πθ,在视频会话中选择合适的每个块的比特率,而以Φ为参数的评论家网络负责学习值函数VΦ,对策略πθ产生的动作进行评价。具体来说,ai可以根据行动者网络生成的概率中采样:

毫米波5G表现出剧烈和频繁的性能波动,这意味着使用更新的策略πθ收集的轨迹可能与使用最后一个策略πθold收集的轨迹有很大不同。这使得很难获得一个鲁棒和有效的ABR策略。为了解决这个问题,我们采用了带有多类型数据处理NN模块的双Dual-clip夹PPO[17]来学习一种鲁棒ABR算法。
其中,ρi(θ)为πθ的概率比,可由[10]计算,

请注意,由于网络的剧烈波动,每次迭代中从环境中收集的转换变化很大。因此,在Dual-clip PPO中,actor将以 的下界和上界来剪辑概率,以限制策略迭代的步长,使策略更新顺利。其中,A为估算的优势函数:
的下界和上界来剪辑概率,以限制策略迭代的步长,使策略更新顺利。其中,A为估算的优势函数:
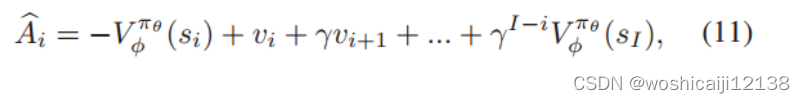
此外,对批判网络参数Φ进行训练,使以下损失函数最小化:
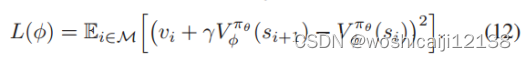
综上,actor网络的损失函数表示为:
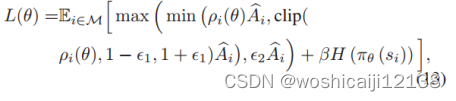

5.5 NN结构
为了充分利用有限的环境信息,我们综合分析了状态的特征,并设计了行动者和评论家网络相应的特征处理结构。网络结构如图2所示。
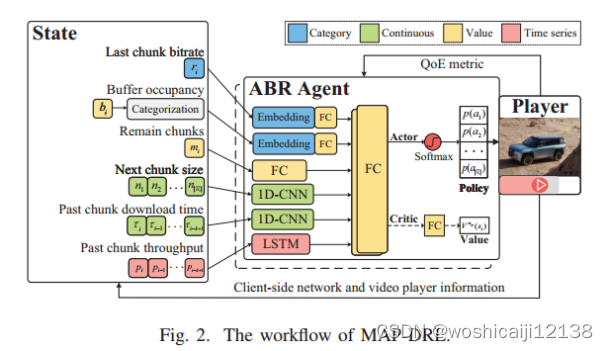
1)类别:对分类数据使用嵌入embedding层。在神经网络中,嵌入可以降低类别的维数,并在变换后的空间中学习连续表示。最后一个块比特率的输入从显然是一种分类数据类型。而对于缓冲区占用,我们首先将它们划分为z个不同的类别,并使用嵌入层来表示缓冲区的情况。每个嵌入层的所有输出将分别馈送到完全连接层中。
2)值:剩余块的数量是整型数据,我们直接使用全连接的网络来处理这种整数值。
3)连续:或者,下一个块大小和过去块的下载时间是连续尺度。利用1D-CNN层提取有益信息。
4)时间序列:长短期记忆(LSTM)被认为是递归处理顺序元素的有效结构。客户端测量的历史吞吐量是一个时间序列数据,该数据被馈送到MAP-DRL中的LSTM中。
6 实验结果
6.1实验数据集
网络轨迹和视频数据集:为了评估MAP-DRL在真实网络环境中的性能,我们使用了Lumos5G数据集[18],其中毫米波5G可以提供超高带宽(高达2Gbps),但有时会迅速下降到4G以下或几乎为零。为了进一步说明MAP-DRL的鲁棒性,我们还使用了两个广泛使用的数据集,HSDPA[19]和FCC16[20]。
此外,在每个网络中,考虑两种QoE偏好:
1)线性QoE度量,其中q(ri) = ri,表示为QoElin;
2)对数形式的QoE度量,其中q(ri) = log(ri)/ log(min(R’)),表示为QoElog。
视频数据集的详细情况及QoE参数如表1所示。

6.2比较方法
我们将MAP-DRL与六种代表性的ABR方法进行了比较:
(1)BB[3]:一种基于启发式的ABR方法,仅根据缓冲区占用率做出比特率决策。
(2) BOLA[4]:利用Lyapunov优化理论,基于缓冲区占用率进行比特率决策。
(3) RB:选择受预测吞吐量约束的最大比特率版本。
(4) RobustMPC[5]:通过观察缓冲区占用和吞吐量的动态,使用MPC框架最大化QoE指标。
(5) BayesMPC[6]:一种基于贝叶斯神经网络和MPC的不确定性鲁棒ABR算法。
(6) Pensieve[7]:一种基于rl的算法,根据对系统状态的观察选择下一个最优比特率。在这项工作中,我们用视频、数据集和QoE指标对Pensieve进行了再训练。
6.3 实现
MAP-DRL由两个神经网络组成,包括演员网络和评论家网络。我们配置了两个具有相同结构和超参数的网络。在不损失通用性的情况下,LSTM被设置为128个单元的层。1D-CNN层被设置为128个过滤器,每个过滤器的大小为4,步幅为1,完全连接的层使用128个神经元。我们使用relu作为激活函数,Adam[21]作为优化器。比特率级别的个数对应于嵌入层的输入维数,输出维数设置为3。而对于缓冲区占用,我们将它们分为z = 10个不同的类别作为相应嵌入层的输入维数,输出维数设为4。使用softmax函数生成行动者的动作概率,使用线性神经元生成评论家的值。在训练过程中,我们设置γ = 0.99,熵因子β将从5衰减到0.001。演员和评论家的学习率分别从10−4衰减到10−5和10−3衰减到10−4。根据[17],将clip interval参数(pes1, pes2)设为(0.2,3),值得注意的是,优势函数归一化1和奖励缩放2对算法的性能有直接影响,特别是在超高但波动很大的网络中。与[7]类似,将最大缓冲区占用设置为60秒,并将最后k = 8的状态馈入网络。所有实验结果均为随机5粒种子下的平均结果。
6.4结果
1)在Lumos5G数据集上的性能比较:我们评估了MAP-DRL在Lumos5G数据集上的性能。平均QoE及其组成部分的对比结果如图3所示。
对QoElin和QoElog进行平均,MAP-DRL的平均QoE分别比BB、BOLA、RB、RobustMPC、BayesMPC和Pensieve高13.3%、11.82%、12.90%、55.73%、59.48%和17.82%。
我们看到MAP-DRL可以在高视频比特率和低视频比特率变化下提供出色的性能。结合优势函数归一化和奖励标度的双夹PPO能够处理波动网络中的梯度爆炸问题。
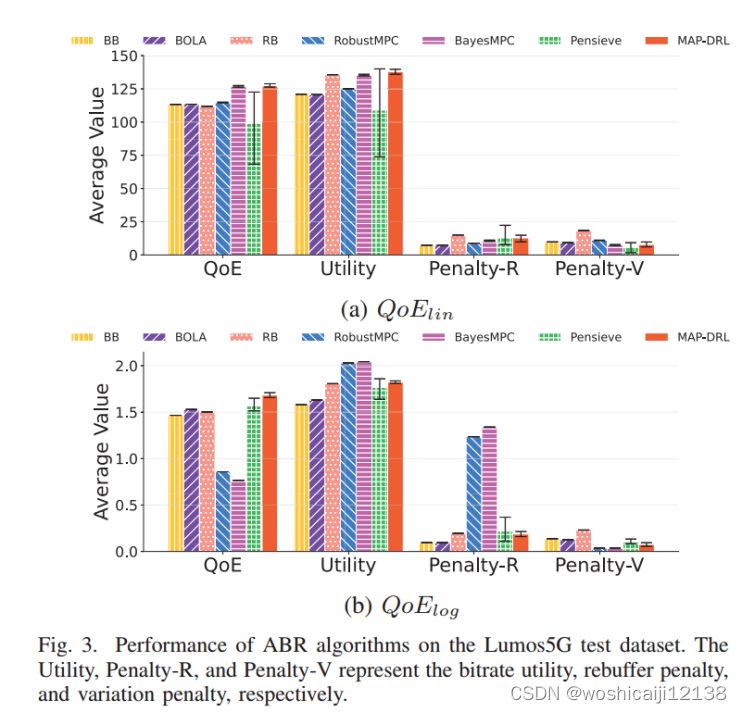
实验也验证了启发式算法在平衡视频流中各种QoE因素方面的局限性。虽然BB和BOLA策略通过关注缓冲区大小来最小化重缓冲惩罚,但它们通常会在比特率效用上妥协。相比之下,RB算法优先考虑吞吐量,导致更高的比特率效用,但不能考虑干扰。这将导致更高的变化和再缓冲。RobustMPC和BayesMPC在QoElog中的较差性能反映了基于MPC的算法的缺点,即它们需要针对不同的场景手动调整参数。传统的基于mpc的方法在不同网络上的性能不一致突出了MAP-DRL的重要性。而基于学习的Pensieve算法在QoElin中表现出保守性,因为该算法不能稳定地处理超高而剧烈波动的网络条件。
与各种网络的性能比较:然后我们将MAP-DRL与其他ABR算法在各种网络条件和QoE指标下进行比较。图4为QoElin和QoElog在Lumos5G和HSDPA数据集上的归一化QoE值结果。MAP-DRL在所有考虑的场景中都取得了出色而稳健的结果,与最具竞争力的BayesMPC方法相比,平均提高了29%。与Pensieve相比,当网络从3G切换到5G时,性能提升明显增加。这是因为MAP-DRL通过使用DualPPO结合优势函数归一化和奖励缩放,将算法中的所有值缩放到合适的区间,有效地减少了大带宽值的梯度爆炸。此外,采用不同的网络结构来处理多类型数据,提高了算法的性能。总之,通过结合上述设计,MAP-DRL可以跨异构网络和偏好实现健壮和高性能的视频流服务。
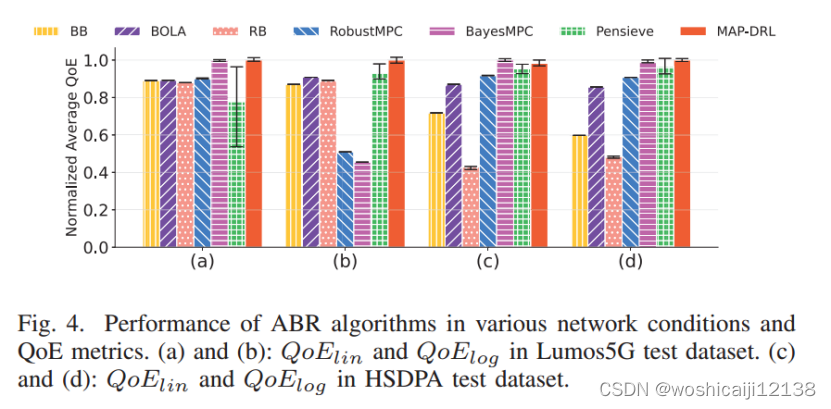
ABR算法在各种网络条件和QoE指标下的性能。(a)和(b): Lumos5G测试数据集中的QoElin和QoElog。©和(d): HSDPA测试数据集中的QoElin和QoElog。
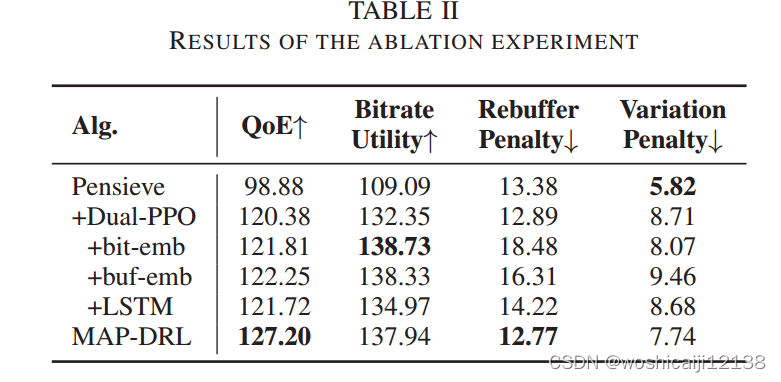
3)消融实验:我们进行烧蚀实验来验证网络结构的有效性,结果报告于表2。
首先,“+DualPPO”是指结合了优势函数归一化、奖励尺度和Pensieve神经网络的双ppo。结果表明,梯度剪辑、优势归一化和奖励尺度对算法的鲁棒性起着重要作用。在此基础上,我们增加了三种不同于Pensieve的NN设计,即比特率级嵌入,类别-大小缓冲区嵌入和LSTM。具体来说,比特率级嵌入层更能意识到比特率之间的差异,使得策略更加关注比特率效用和变异惩罚。分类缓冲区嵌入层更好地描述了缓冲区大小的变化,从而充分利用缓冲区,提高比特率利用率。而LSTM层对网络波动更为敏感,策略相对保守。
总之,上述所有设计与Dual-PPO的结合形成了一个强大的高性能MAP-DRL算法,在提供高比特率块的同时限制了重缓冲和变化。
7评价
7.1优点
数据视频环境指标经嵌入embedding层、全连接的网络、1D-CNN、LSTM处理似乎有别样的效果
采用Dual-clip PPO对鲁棒性的效果
7.2缺点
算法只考虑了QoE指标,对于重缓存时延应该需要特别的约束
参考
[3] T.-Y. Huang, R. Johari, N. McKeown, M. Trunnell, and M. Watson, “A buffer-based approach to rate adaptation: Evidence from a large video streaming service,” in Proceedings of the 2014 ACM SIGCOMM Conference, 2014, pp. 187–198.
[4] K. Spiteri, R. Urgaonkar, and R. K. Sitaraman, “Bola: Near-optimal bitrate adaptation for online videos,” IEEE/ACM Transactions on Networking, vol. 28, no. 4, pp. 1698–1711, 2020.
[5] X. Yin, A. Jindal, V. Sekar, and B. Sinopoli, “A control-theoretic approach for dynamic adaptive video streaming over http,” in Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication, 2015, pp. 325–338.
[6] N. Kan, C. Li, C. Yang, W. Dai, J. Zou, and H. Xiong, “Uncertainty-aware robust adaptive video streaming with bayesian neural network and model predictive control,” in Proceedings of the 31st ACM Workshop on Network and Operating Systems Support for Digital Audio and Video, 2021, pp. 17–24.
[7] H. Mao, R. Netravali, and M. Alizadeh, “Neural adaptive video streaming with pensieve,” in Proceedings of the Conference of the ACM Special Interest Group on Data Communication, 2017, pp. 197–210.
[10] S. Wang, S. Bi, and Y.-J. A. Zhang, “Adaptive wireless video streaming:
Joint transcoding and transmission resource allocation,” IEEE Transactions on Wireless Communications, vol. 21, no. 5, pp. 3208–3221, 2022.
[17] D. Ye, Z. Liu, M. Sun, B. Shi, P. Zhao, H. Wu, H. Yu, S. Yang, X. Wu, Q. Guo et al., “Mastering complex control in moba games with deep reinforcement learning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 6672–6679.
[21] D. P. Kingma and J. L. Ba, “Adam: A method for stochastic gradient descent,” in ICLR: International Conference on Learning Representations, 2015, pp. 1–15.

















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









