



驾驶员视线跟踪和眼睛离开道路检测系统
摘要
分心驾驶是美国车辆碰撞事故的主要原因之一。通过被动监控驾驶员活动,构成了汽车安全系统的基础,该系统可通过估计驾驶员的注意力焦点来潜在减少事故数量。本文提出了一种低成本的基于视觉的系统,用于准确检测视线离开道路(EOR)。该系统包含三个主要组成部分:1)鲁棒的面部特征跟踪;2)头部姿态和视线估计;3)基于三维几何推理的EOR检测。从安装在转向柱上的摄像头获取的视频流中,本系统对驾驶员面部的面部特征进行跟踪。利用被跟踪的特征点和三维人脸模型,系统计算出头部姿态和视线方向。所采用的头部姿态估计算法对因表情变化引起的非刚性面部形变具有良好的鲁棒性。最后,通过三维几何分析,系统能够可靠地检测视线离开道路(EOR)。
所提出的系统无需任何依赖驾驶员的校准或手动初始化,可在白天和夜间实时(25帧每秒)运行。为了验证该系统在实际汽车环境中的性能,我们在广泛的光照条件、面部表情和不同个体下进行了全面的实验评估。我们的系统在所有测试场景中均实现了高于90%的EOR准确率。
索引词
驾驶员监控系统,眼睛离开道路检测,视线估计,头部姿态估计。
一、引言
DRIVER分心是大多数车辆碰撞和险些碰撞事故的主要原因。根据美国国家公路交通安全管理局(NHTSA)和弗吉尼亚理工大学交通研究所(VTTI)发布的一项研究,[16], 80%的碰撞事故和65%的险些碰撞事故涉及某种形式的驾驶员分心。此外,分心通常发生在车辆碰撞前的三秒内。最近的报告显示,从2011年到2012年,因驾驶员分心驾驶导致的车祸受伤人数增加了9%[1]。仅在2012年,就有3328人因此丧生。
分心驾驶被定义为任何可能分散驾驶员注意力、使其偏离主要驾驶任务的活动。分心行为包括发短信、使用智能手机、饮食、调节CD播放器、操作GPS系统或与乘客说话。
如今这一问题尤为突出,因为大量技术已被引入汽车环境。因此,驾驶员需要处理的次要任务所带来的认知负荷逐年增加,从而加剧了分心驾驶。根据一项综述[14], ,驾驶时执行高认知负荷任务会影响驾驶员的视觉行为和驾驶表现。文献[22] 和[36] 报告称,在高认知负荷下的驾驶员检查后视镜、仪表、交通信号以及交叉路口周围区域的时间明显减少。
尤其令人担忧的是驾驶时使用手持电话和其他类似设备的行为。美国国家公路交通安全管理局(NSTHA)[16] 报告称,发短信、浏览和拨号会导致驾驶员视线离开道路(EOR)的时间最长,并使碰撞风险增加三倍。最近的一项研究[41] 表明,这些危险行为在驾驶员中十分普遍,54%的美国机动车驾驶员通常在车辆中放置手机或在驾驶时携带手机。
监测驾驶员行为是安全系统的基础,该系统通过检测异常情况,有可能减少事故数量。在[29],中,作者指出,一个成功的基于视觉的分心驾驶检测系统建立在可靠的EOR估计之上,见图1。然而,为实际驾驶场景构建实时EOR检测系统面临诸多挑战:(1)系统必须能够在白天和夜间以及真实世界光照条件下运行;(2)驾驶员头部姿态和眼动的变化会导致被跟踪的面部特征(如瞳孔和眼角)发生剧烈变化;(3)系统必须对不同种族、性别和年龄范围的多种人群保持高精度。此外,系统还必须对佩戴不同类型眼镜的人具有鲁棒性。为解决这些问题,本文提出了一种低成本、高精度且实时的EOR检测系统。需要注意的是,EOR检测仅仅是用于检测和提醒分心驾驶员的系统的一个组成部分。
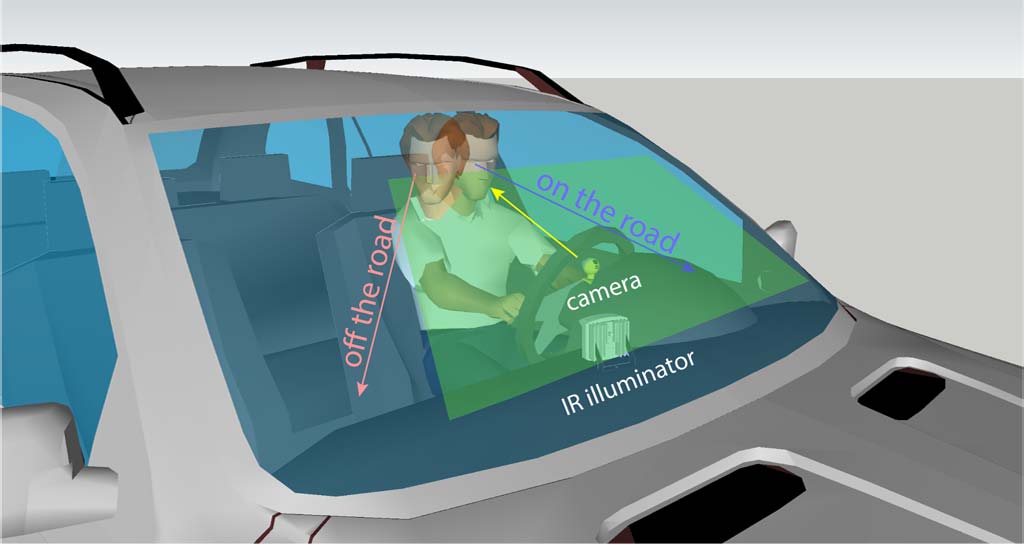
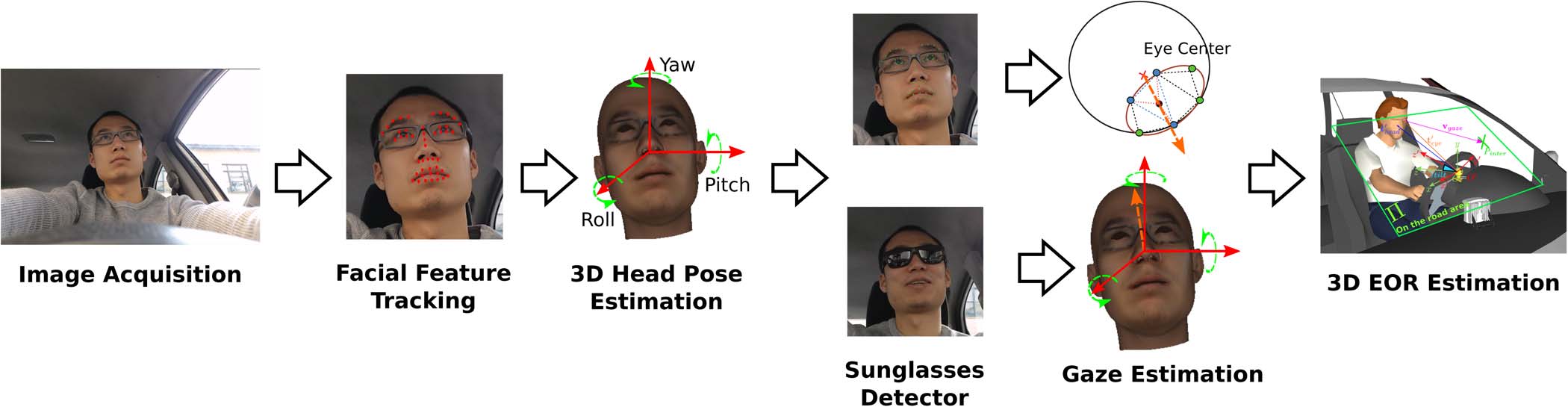
图2展示了我们系统的主要组件。该系统通过安装在转向柱上的摄像头采集视频,并跟踪面部特征,参见图1。利用三维头部模型,系统估计头部姿态和视线方向。通过三维几何分析,我们的系统提出了一种可靠的EOR估计方法。我们的系统在MATLAB中以25帧每秒的速度运行,且无需任何驾驶员依赖性校准或手动初始化。系统支持佩戴眼镜(包括太阳镜),并可在白天和夜间正常工作。此外,头部姿态估计算法采用了一种三维可变形头部模型,能够处理驾驶员面部表情(如打哈欠和说话),通过分离刚性和非刚性面部运动实现可靠的头部姿态估计。在实际汽车环境中的实验表明了我们系统的有效性。
II. 先前工作
驾驶员监控一直是计算机视觉领域的一个长期研究问题。本文无法回顾所有现有系统,但我们提供了学术界和工业界中最相关工作的描述。有关现有系统的完整概述,我们建议读者参考[14]。
一般来说,估计视线方向有两种方法:仅使用头部姿态的方法和同时使用驾驶员头部姿态与视线的方法。对于仅依赖头部姿态估计的系统,相关主题的详细报告见[34]。Lee et al.[30]提出了一种基于水平和垂直边缘投影归一化直方图并结合椭球面人脸模型和支持向量机(SVM)分类器进行视线估计的偏航角和俯仰角估计算法。
Chutorian et al.[33]提出了一种基于局部梯度方向(LGO)直方图并结合支持向量回归器(SVR)的驾驶员头部姿态估计算法。该算法在[35]中通过引入基于三维运动估计和驾驶员头部网格模型的头部跟踪模块得到了进一步发展。
最近,雷扎伊和克莱特[37]提出了一种用于分心驾驶检测的新算法,该算法采用改进的三维头部姿态估计和费马点变换。所有上述方法均被报告可在实时运行。
使用头部姿态和视线估计的系统被分为基于硬件和基于软件的方法。Ishikawa et al.[25]提出了一种被动式驾驶员视线跟踪系统,该系统采用主动外观模型(AAMs)进行面部特征跟踪和头部姿态估计。同时对驾驶员瞳孔进行跟踪,并利用三维眼模型通过单目相机实现精确的视线估计。Smith etal.[39]则依赖运动和颜色统计方法,以稳健地跟踪驾驶员头部和面部特征。该系统假设驾驶员头部到摄像头的距离固定,利用简化头部模型恢复三维视线,且无需任何校准过程。
基于硬件的方法用于驾驶员头部姿态和视线估计,依赖于近红外(IR)照明器来产生亮瞳效应 [7],[26],[27],[32]。亮瞳效应可实现低成本瞳孔检测,仅通过计算机视觉技术即可简化驾驶员瞳孔的定位。纪和杨 [26],[27]描述了一种基于亮瞳效应的驾驶员监控系统,该系统利用眼睛、视线和头部姿态跟踪进行监测。系统采用卡尔曼滤波器跟踪瞳孔,并结合瞳孔周围的图像特征与最近邻分类器进行头部姿态估计。视线方向通过提取瞳孔中心到反光点的位移和方向,并使用线性回归映射到九个视线方向来估计。该系统与人员无关性差,必须针对每种系统配置和每位驾驶员进行校准。Batista[7]使用了类似的系统,但通过椭圆拟合方法提高了面部朝向估计精度,从而实现了更准确的视线估计。这些近红外照明系统在夜间表现尤为良好,但由于外部光源和眼镜引入的干扰,性能可能显著下降[8],[21]。虽然人工光源造成的干扰可通过窄带通滤波器轻易滤除,但阳光干扰仍会存在。此外,生成亮眼效应所需的硬件将不利于系统集成到汽车仪表板中。
在工业界,基于近红外的系统最为常见。萨博驾驶员注意力警示系统[6]可检测视觉分心和疲劳驾驶。该系统采用两个集成了SmartEye技术的微型红外摄像头,以精确地估计驾驶员头部姿态、视线和眼睑状态。当驾驶员的视线在预定义的时间内未处于主要注意区域(覆盖前挡风玻璃中央部分)时,系统将触发警报。然而,尚未报告该系统在实际驾驶场景中的性能详细信息。丰田已在高端雷克萨斯车型上配备了其驾驶员监控系统[24]。该系统利用安装在转向柱顶部的近红外摄像头,持续监测驾驶员左右转动头部的动作。该系统已集成到丰田的预碰撞系统中,在可能发生碰撞时向驾驶员发出警告。
另一款商业系统是FaceLAB[2],,这是一种基于立体视觉的眼动仪,可检测眼球运动、头部位置和旋转、眼睑开度以及瞳孔大小。FaceLAB采用安装在汽车仪表板上的被动式立体摄像头对。该系统已应用于多种驾驶员辅助和注意力分散监测系统中,例如[17]–[19]。然而,基于立体视觉的系统成本过高,难以在量产汽车中安装,并且由于振动会导致系统校准随时间漂移,因此需要定期重新校准。
类似地,SmartEye[3]采用多摄像头系统,生成驾驶员头部的三维模型,从而计算其视线方向、头部姿态和眼睑状态。该系统已在[5]中进行了评估。遗憾的是,该系统成本过高,无法在商用汽车中大规模推广,并且对所需安装的硬件有严格限制。因此,在普通汽车中安装该系统是不可行的。其他商业系统还包括德尔福电子[15]和 SensoMotoric仪器有限公司[4]开发的系统。
III. 系统描述
本节介绍了我们系统的主要组成部分。系统包含六个主要模块:图像采集、面部特征检测与跟踪、头部姿态估计、视线估计、EOR检测和太阳镜检测。图2展示了系统框图和算法流程。
A. 图像采集
图像采集模块基于一个低成本CCD摄像头(在本例中为罗技c920网络摄像头),安装于顶部

位于转向柱上,见图3。将CCD相机放置在转向柱上方出于两个原因:(1)便于估计视线角度,例如俯仰角,这对于检测驾驶员是否正在发短信(对安全的主要威胁)具有重要意义。(2)从生产角度来看,将CCD相机集成到仪表板中非常方便。缺点是,当方向盘转动时,会有一些帧中驾驶员面部被转向轮遮挡。
对于夜间操作,系统需要一个照明光源来提供驾驶员面部的清晰图像。此外,照明系统不能影响驾驶员的视线。为此,在汽车仪表板上安装了一个红外照明器,参见图3。需要注意的是,所提出的系统不存在基于近红外的系统的常见缺点[7],[26],[27], ,因为它不依赖于亮瞳效应。为了使我们的CCD相机适应红外照明,必须从CCD相机中移除红外滤光片,从而使CCD对红外照明(即阳光、人工照明)更加敏感。如图5所示,这种效应在实际驾驶场景中并不明显。
B. 面部特征检测与跟踪
参数化外观模型(PAMs),例如主动外观模型(如 [12],[13])和可变形模型[9],,是面部跟踪中流行的技术。它们通过对一组手动标注数据进行主成分分析(PCA)来构建对象的外观和形状表示。图4(a)展示了一幅用 p个特征点(本例中为p= 51)标注的图像。我们的模型额外增加了两个特征点,用于瞳孔中心。然而,PAMs存在若干局限性,使其难以在我们的系统中用于检测和跟踪。首先,PAMs通常需要优化大量参数(约50–60个),这使得它们极易陷入局部极小值。其次,PAMs对特定个体对象效果良好,但由于其使用了形状和外观的线性模型[13],难以泛化到未训练过的其他受试者。第三,形状模型通常无法建模非对称表情(例如一只眼睛睁开另一只闭上,或不对称微笑),这是因为在大多数训练数据集中,这些表情并未出现。
为了解决PAMs的局限性,熊雄和德拉萨托re提出了监督下降方法(SDM)[44],,这是一种用于拟合PAMs的判别方法。该方法与传统PAMs有两个主要区别。首先,它采用了一种能够更好地泛化到未训练情况(例如非对称面部表情)的非参数形状模型。其次,SDM使用了更复杂的表示方法(在特征点周围使用SIFT描述符[31]),这种表示方法对光照具有更强的鲁棒性,对于在驾驶场景中检测和跟踪人脸至关重要。
给定一个大小为 m像素的图像d ∈ Rm×1,d(x) ∈ Rp×1(参见脚注中的符号说明)1表示图像中的 p特征点。h是一个非线性特征提取函数(在本例中为SIFT特征),且h(d(x)) ∈ R128p×1,因为SIFT特征具有128维。在训练过程中,我们假设正确的 p特征点是已知的,并将其记为 x∗[,如图4(b)所示]。此外,为了模拟测试场景,我们在训练图像上运行了人脸检测器,以提供特征点的初始配置(x0),该配置对应于平均形状[,如图4(a)所示]。然后,人脸对齐可以表述为在Δx上最小化以下函数
$$ f(x0+Δx)= ‖h(d(x0+Δx))−φ∗‖ 2 2 $$ (1)
其中φ∗= h(d(x∗))表示在手动标注的特征点处的SIFT值。在训练图像中,φ∗和Δx是已知的。
可以使用牛顿法来最小化公式(1)。牛顿法假设在最小值附近,光滑函数f(x)能够被二次函数很好地近似。如果海森矩阵是正定的,则可以通过求解线性方程组找到最小值。用于最小化公式(1)的牛顿更新为:
$$ xk= xk−1 −2H−1Jh(φk−1 −φ∗) $$ (2)
其中,φk−1 = h(d(xk−1))是在先前一组标志点位置提取的特征向量xk−1,H 和Jh 是在xk−1处计算的海森矩阵和雅可比矩阵。需要注意的是,SIFT算子不可微,因此使用一阶或二阶方法最小化方程(1)需要对雅可比矩阵和海森矩阵进行数值近似(例如有限差分)。然而,数值近似计算代价高。此外, φ ∗ 在训练阶段已知,但在测试阶段未知。SDM通过学习一系列下降方向和重缩放因子(在牛顿法中由海森矩阵完成)来解决这些问题,从而生成从x0 开始并收敛到训练数据中x∗ 的更新序列(xk+1= xk+Δxk)。也就是说,SDM从训练数据中学习一系列通用下降方向{Rk} 和偏置项{bk}
$$ x k = x k − 1 + Rk − 1 φ k − 1 + b k − 1 $$ (3) 使得在训练集的所有图像上,x k 的序列收敛到x ∗。有关 SDM的更多细节,请参见[44]。
 平均特征点,x0,通过人脸检测器初始化。黑色轮廓表示人脸检测器。b)带有51个特征点的人工标注图像。)
平均特征点,x0,通过人脸检测器初始化。黑色轮廓表示人脸检测器。b)带有51个特征点的人工标注图像。)
图5展示了跟踪器在实际驾驶场景中的若干工作示例。面部跟踪代码可在 http://www.humansensing.cs.cmu.edu/intraface/获取。

C. 头部姿态估计
在实际驾驶场景中,驾驶员在驾驶过程中会改变其头部姿态和面部表情。在复杂情况下准确估计驾驶员头部姿态是一个具有挑战性的问题。本节提出了一种3D头部姿态估计系统,用于解耦刚性和非刚性头部运动。
头部模型使用形状向量q ∈ R(3·49×1) x z 表示, 该向量拼接了所有顶点的, y,坐标。可变形面部模型是通过对 Caoet al.[10],提供的训练数据集进行主成分分析[9]构建的, 该数据集包含具有身份和表情变化的对齐的3D面部形状。新的 3D形状可以重构为特征向量vi和平均形状 ¯q的线性组合。
$$ q= q¯+∑ i βivi= q¯+ Vβ. $$ (4)
给定来自SDM跟踪器的49个被跟踪的2D面部关键点(pk ∈ R 2×1, k=1,…,49,不包括瞳孔点),我们通过最小化2D特征点与模型中对应3D点的投影之间的差异,同时拟合头部形状和头部姿态。本文中,我们假设采用弱透视相机模型 [43],,也称为缩放正交投影。拟合误差定义为
$$ E= 1 2 K=49 ∑ k=1 ∥ ∥ ∥ sP(RLkq + t′ head p) − pk ∥ ∥ ∥ 2 2 $$ (5)
其中 k是第 k个面部特征点的索引,P ∈ R 2×3是投影矩阵,L k ∈ R 3×( 3·49)是选择与第 k个面部特征点对应的顶点的选择矩阵,R ∈ R 3×3是由头部姿态角定义的旋转矩阵,t′ head p ∈ R 3×1是驾驶员头部相对于相机光心的3D平移向量, s是用于近似透视成像的尺度因子。整体拟合误差 E为所有关键点的总拟合误差。

通过交替优化方法,对姿态参数(R, t′ headp , s)和形状系数 β进行最小化。我们在估计刚性参数R和 s与非刚性参数 β之间交替进行。这些步骤单调地减少拟合误差 E,并且由于该函数有下界,因此我们收敛到一个临界点,见 [45]。图6展示了头部姿态估计和3D头部重建的四个示例。
坐标映射 :在上述方法中,头部平移向量t′ head p 是以像素为单位计算的。为了利用场景几何进行EOR估计,我们需要将像素映射到厘米,从而得到向量t′ head。该映射通过数据驱动方法实现。对于固定焦距,我们收集了一组以像素为单位的平移向量及其对应的实际长度(以厘米为单位)。通过求解线性系统来获得单位映射
$$ t′ head= At′ head p + b $$ (6)
其中A∈ R 3×3和b ∈ R 3×1是待求解的线性系数。值得注意的是,该仿射变换在汽车环境之外完成,并且对于同一型号(罗技c920)的多个摄像头具有良好的泛化能力。为了计算此映射,我们使用了三位未包含在实验部分所述测试集中的不同个体。
角度补偿 :如上所述,头部姿态估计算法基于弱透视假设,因此我们使用缩放正交投影。当驾驶员头部靠近摄像头的视轴时,该假设是准确的。然而,在车内场景中,由于驾驶员身高、坐姿位置以及相机固定倾斜角度等多种因素,驾驶员头部可能并不总是靠近摄像头的视轴。
图7显示了驾驶员头部的三个不同位置,以及通过摄像头、透视投影和缩放正交投影分别生成的对应图像。我们可以看到,在位置b处,相机视角与缩放正交投影图像中的位置相匹配,此时驾驶员头部与摄像头的视线轴对齐。对于位置 a和 c,由于相对于摄像头视线轴发生了平移,摄像头图像与弱透视图像存在差异。因此,头部姿态估计算法会因驾驶员头部位置而引入偏移。为了校正该偏移,有必要引入一种启发式方法。
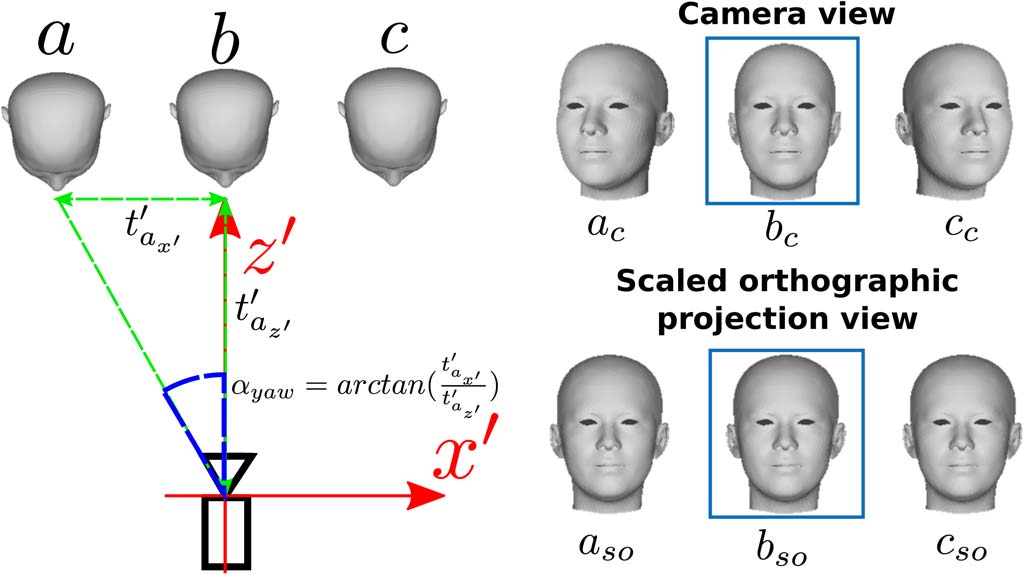
对头部旋转的补偿。图7显示了针对影响偏航角估计的横向平移所计算出的启发式补偿。对于垂直平移,也针对俯仰角计算了类似的补偿。因此,在汽车环境中,我们的头部姿态算法估计出的偏航角和俯仰角由以下给出
$$ φ′head yaw = γyaw − αyaw $$ (7)
$$ φ′head pitch= γpitch − αpitch $$ (8)
其中γyaw和 γpitch是我们的算法计算出的原始偏航角和俯仰角, αyaw和 αpitch是相应的补偿角。需要注意的是,翻滚角未引入补偿,我们的测试表明,翻滚角相对于相机虚拟轴的平移变化较不敏感。
D. 视线估计
驾驶员的凝视方向提供了关于驾驶员是否分心的关键信息。视线估计在计算机视觉领域一直是一个长期存在的问题[23],[25]。大多数现有研究采用基于模型的方法进行视线估计,该方法假设一个3D眼球模型,其中眼球中心是视线射线的原点。本文使用了类似的模型(见图8)。我们做出三个主要假设:第一,眼球为球形,因此眼球中心相对于头部模型位于一个固定点(刚性点);第二,所有眼部特征点(包括瞳孔)都通过前一节中描述的SDM跟踪器检测得到。需要注意的是,使用其他技术(如霍夫变换)可以实现更精确的瞳孔中心估计;第三,眼睛睁开,因此所有眼轮廓点均可视为刚性的。我们的算法主要包括两个部分:(1)根据刚性的眼轮廓点估计瞳孔的3D位置;(2)根据瞳孔位置和眼球中心估计3D视线方向。
瞳孔的3D位置按如下方式计算: 1)对二维的眼轮廓点进行三角化,并确定哪个三角网格包含瞳孔。参见图8。
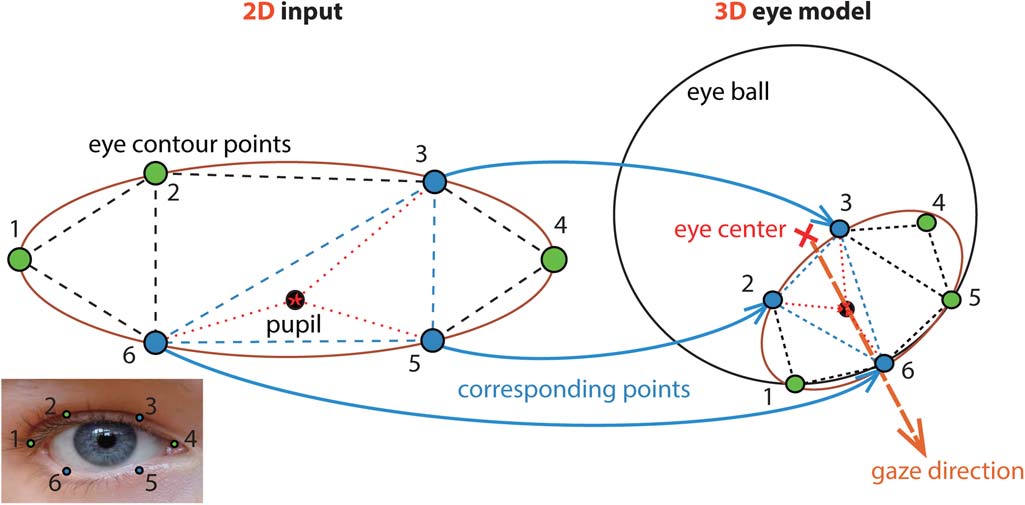
2)计算瞳孔在包含它的三角网格内的重心坐标。3)将重心坐标应用于对应的三维眼轮廓点,以获得瞳孔的三维位置。
在获得瞳孔的3D位置后,视线方向可以简单地估计为通过眼球中心和瞳孔的射线。因此,我们可以得到视线角度。
最后,为了计算相对于相机坐标系的视线角度Φ′gaze=(φ′gaze yaw , φ′gaze pitch),需要使用补偿后的头部姿态旋转矩阵对估计的视线角度进行旋转。
E. 眼睛离开道路检测
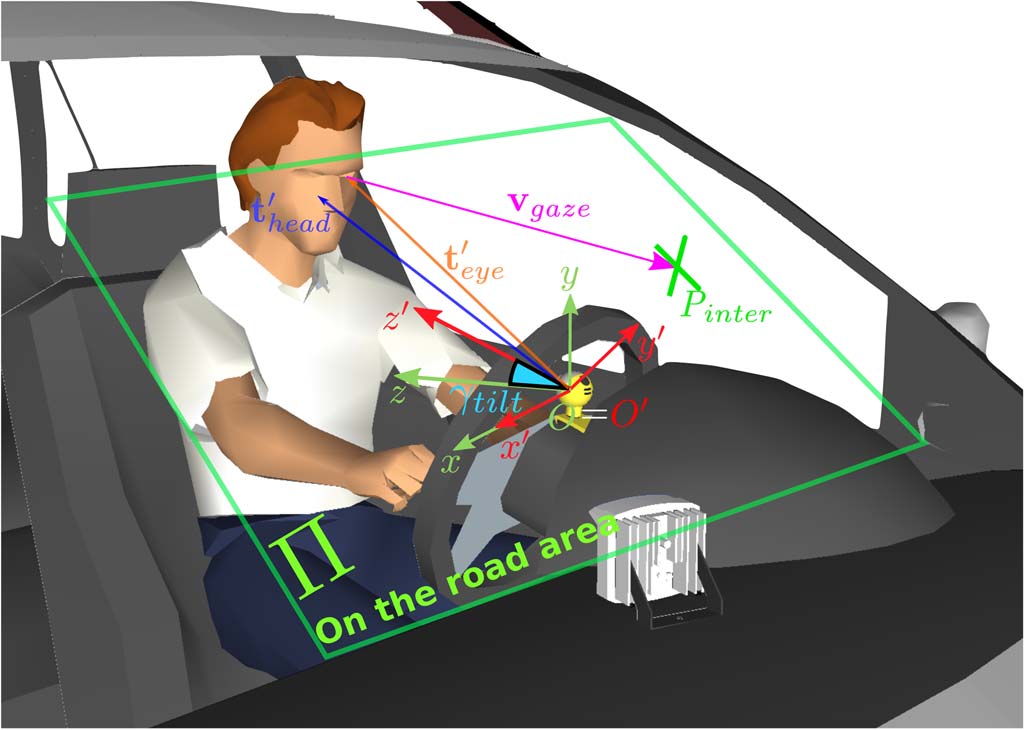
EOR估计基于一种3D光线追踪方法,该方法利用了如图9所示的场景几何。我们的EOR估计算法计算驾驶员3D视线线(图9中的vgaze)与汽车挡风玻璃平面Π的交点。如果该交点位于定义的道路区域内之外,则触发警报。在我们的方法中,仅使用了驾驶员左眼的视线,因为相比右眼,左眼受到的遮挡更少(仅有短暂的头部动作用于查看驾驶员侧后视镜)。
为了计算三维视线向量,我们需要眼睛的三维位置以及视线方向(视线偏航角和俯仰角)。设 O′和 O分别为相机坐标系的原点(x′, y ′, z′)和世界坐标系的原点(x, y, z),两个坐标系的单位均为厘米。世界坐标系是相机坐标系绕相机倾斜角 γ tilt旋转得到的,因此有 O= O ′。世界坐标系中的点 P与相机坐标系中的点 P ′之间的关系由 P= R c/w P ′表示,其中Rc/w是从相机坐标系到世界坐标系的旋转矩阵。该旋转矩阵由相机倾斜角 γ tilt 定义,参见图9。
第三节-D中描述的视线方向算法提供了驾驶员凝视方向, Φ ′ g aze =(φ′ g aze y aw , φ′ g aze p itch )相对于相机坐标系。我们可以构建三维视线向量,u′ gaze, 作为
$$ u′ gaze= \begin{bmatrix} \cos(\varphi′ {gaze_pitch}) \cdot \sin(\varphi′ {gaze_yaw}) \ \sin(\varphi′ {gaze_pitch}) \ -\cos(\varphi′ {gaze_pitch}) \cdot \cos(\varphi′_{gaze_yaw}) \end{bmatrix} $$ (9)
利用三维头部坐标,公式(4)中的q,我们的头部姿态算法估计驾驶员头部和眼睛相对于相机坐标系的三维位置,分别用向量t′ head和t′ eye表示。因此,三维视线线可以使用参数化三维直线形式表示为
$$ v_{gaze} = R_{c/w}(t′ {eye} + \lambda u′ {gaze}) $$ (10)
最后,交点Pinter由视线向量vgaze与挡风玻璃平面Π的相交得出。挡风玻璃平面Π在世界坐标系中的方程通过最小二乘平面拟合进行估计。
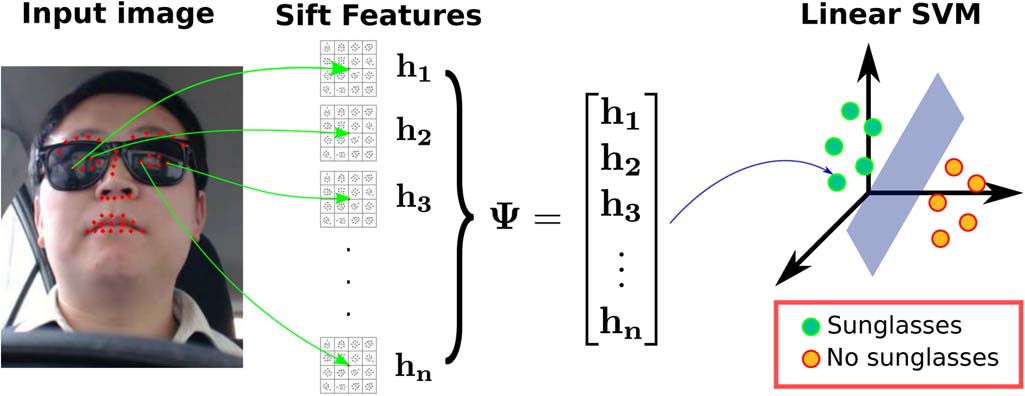
F. 太阳镜检测器
我们的系统在不同种族的驾驶员佩戴不同类型的眼镜时均能可靠工作。然而,如果驾驶员佩戴太阳镜,则无法稳健地检测瞳孔。因此,在这种情况下,为了获得可靠的EOR估计,将使用头部姿态角来计算向量vgaze。
太阳镜检测流程如图10所示。首先,我们的系统从眼睛和眉毛区域提取SIFT描述符h1,…,hn,并将它们连接起来构建特征向量 Ψ。其次,使用线性支持向量机(SVM)分类器来估计驾驶员是否佩戴了太阳镜。该SVM分类器使用了来自CMU Multi‐PIE人脸数据库[20]和PubFig数据库 [28]的7500张图像进行训练。该分类器在由600张图像组成的测试集中获得了98%准确率,这些图像在正类和负类之间均匀分布。
IV. 实验
本节评估了我们的系统在不同任务中的准确性。首先,我们将我们的头部姿态估计与其它最先进的方法进行比较。其次,我们报告了我们的EOR检测系统在汽车环境中录制的视频中的表现。最后,我们评估了头部姿态估计算法对极端面部形变的鲁棒性。
A. 头部姿态估计
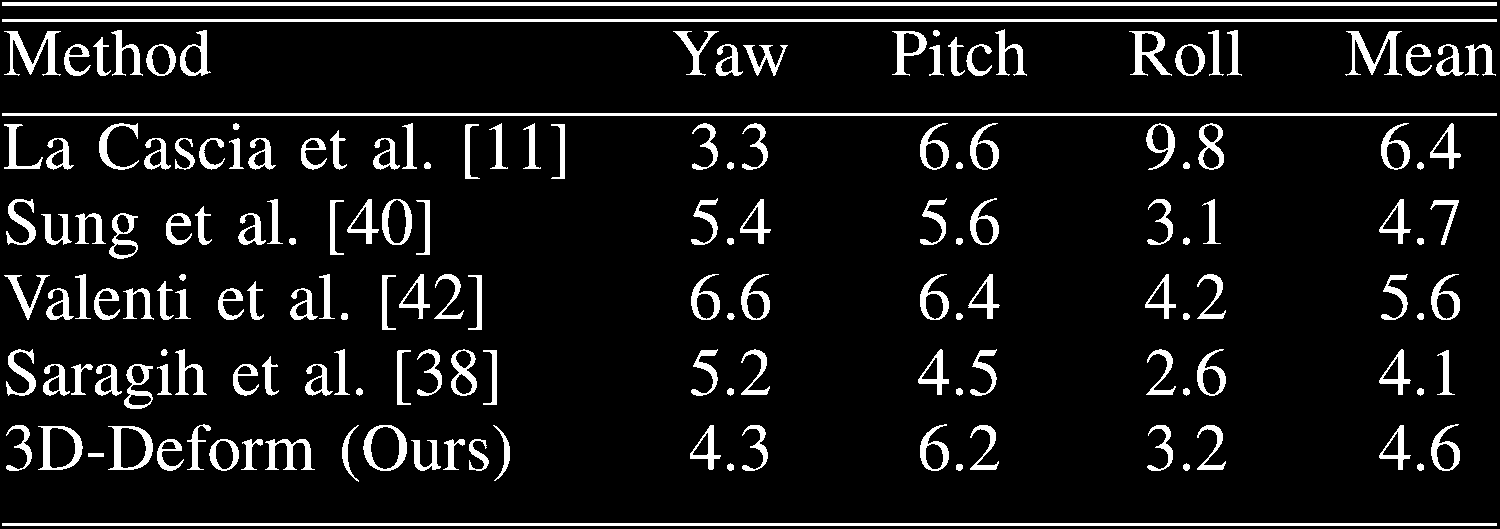
为了评估我们基于三维的头部姿态估计算法,我们使用了La Cascia etal.[11]提供的波士顿大学(BU)数据集。该数据集包含来自5个不同个体的45个视频序列,每个视频包含200帧。如前几节所述,在每一输入帧中执行面部特征检测。利用二维跟踪到的关键点,我们估计了三维头部方向和位移。距离单位已预先归一化,以确保平移度量处于同一尺度。
我们将基于可变形三维头部模型(3D‐Deform)的头部姿态估计系统与文献中的其他四种方法进行了比较。表 I显示了不同算法在头部姿态角上的平均绝对误差( MAE)。La Cascia etal.[11]提出了一种使用手动初始化的圆柱形模型和递归最小二乘优化的方法。Sung et al.[40]提出了一种基于主动外观模型[12]和圆柱形头部模型的方法。Valenti et al. [42]使用圆柱形模型和模板更新方案来实时估计模型参数。如表I所示,我们基于可变形三维面部模型的方法比这三种方法更精确。最后,Saragih et al.[38]提出了一种基于三维约束局部模型(CLM)的算法,该算法通过带逻辑回归器的线性支持向量机最大化局部块响应来估计姿态参数。该方法获得的MAE优于我们的方法,但该算法在发生较大漂移时需要使用真实值进行重新校准,这在实际汽车环境中是不可行的。
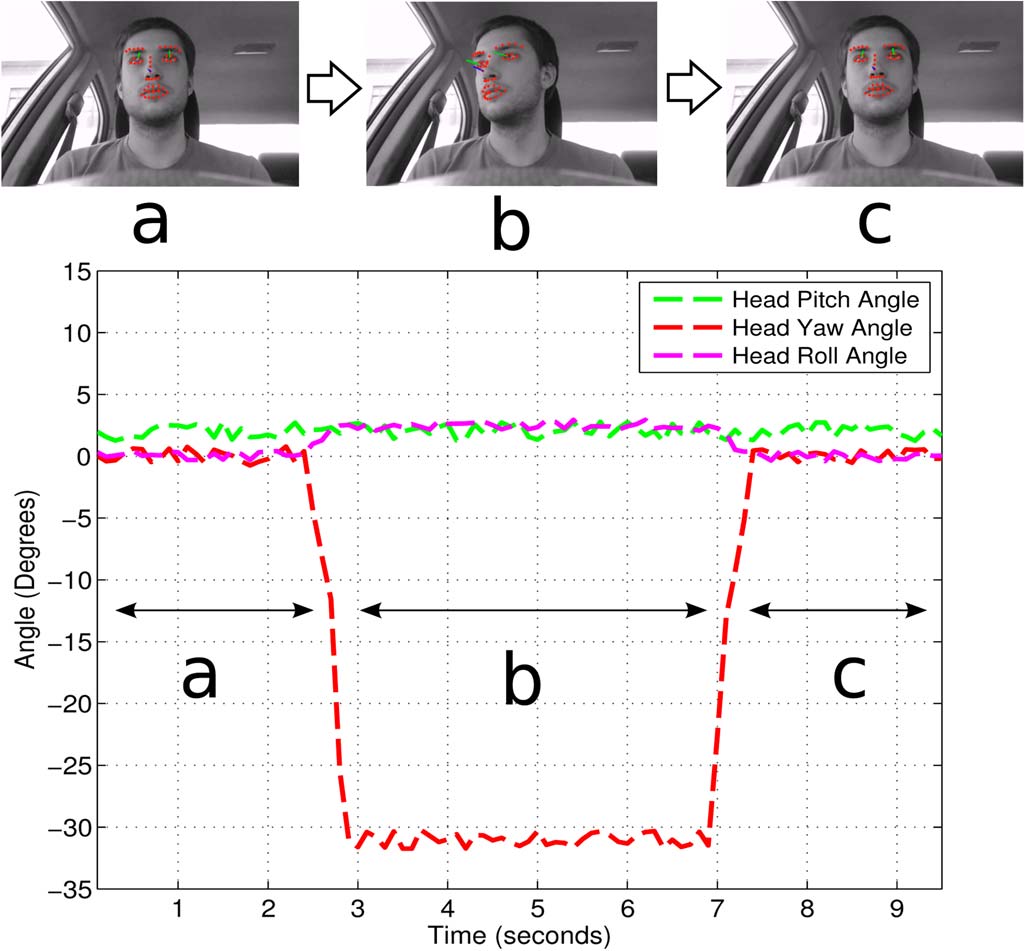
为了证明我们的头部姿态估计算法在汽车环境中对表情变化的鲁棒性,我们在不同表情设置下进行了实验。详见第四节-C。图11展示了我们的头部姿态估计算法在汽车环境中的工作情况。我们可以看到,随着驾驶员移动头部,其头部姿态的偏航角如何变化。
| 表I 在BU数据集上的头部姿态估计结果,以平均绝对误差( MAE)衡量 |
|---|
| 此处应为原文中的表格内容,因未提供具体数据,故省略 |
B. 眼睛离开/注视道路估计
本节报告了我们的EOR系统在真实汽车场景中的实验结果。首先,我们提供了用于评估系统性能的评估协议和数据集的详细信息。然后,我们进行了性能分析。
1) 评估协议和数据集
为了评估我们系统的离道路表现,我们在车内和挡风玻璃上选择了四个在道路上和十四个离道路的位置。图13显示了在道路上区域的大小以及选定的位置。红点被视为车外视线位置用绿点表示,在道路上的视线位置也用绿点表示。我们在不同条件下录制了驾驶员注视这些位置的多个视频,并计算系统正确预测在道路上和离道路视线位置的百分比。
驾驶员被要求按照指定动作序列进行操作,以规定其视线方向。最初,驾驶员直视前方挡风玻璃。在听到音频信号后,驾驶员需自然地看向图13中所示的目标位置之一,并持续十秒。对于佩戴太阳镜的驾驶员,鼓励他们将头部朝向目标位置。该过程如图12所示。实验共招募了十二名不同受试者,涵盖了广泛的面部特征和光照条件。受试者群体包括八名亚洲人和四名高加索人。白天实验中,四名受试者未戴眼镜,六名戴眼镜,四名戴太阳镜;夜间实验中,六名受试者戴眼镜,五名未戴眼镜。作为性能指标,我们采用在受试者注视特定位置的十秒期间,正确预测眼睛在道路上/离道路状态的帧百分比。总共使用了 ∼135 000帧白天和夜间的实验数据来评估在道路/离道路准确率估计 (25次实验× × 18个位置×10秒× ×FPS)。需要注意的是,五秒初始化阶段生成的帧不用于计算EOR准确率。对于位于车外区域内的位置,我们报告被预测为EOR的帧百分比;相反,对于位于道路上区域的位置,我们报告被预测为在道路上的帧百分比。
EOR系统在MATLAB中运行(∼25 FPS),图像分辨率为 1280 × 720像素,平均耗时38.4毫秒在配备2.6吉赫兹的Intel i5处理器上,使用350兆字节内存处理每一帧。
2) 实验结果
表II显示了系统在不同场景下的整体性能。系统在道路上区域的准确率高于95%,因此在所有场景下均表现出较低的误报率(低于5%)。这对于EOR检测系统而言是一个非常理想的特性,因为驾驶员不会受到系统发出的不必要声音警报的干扰。同样,系统在车外区域的准确率在所有场景下均高于90%。此外,夜间与白天结果之间没有显著差异。红外照明器有效地照亮了驾驶员面部,使系统能够准确跟踪驾驶员面部特征点,见图16。此外,SIFT特征对光照变化具有鲁棒性,使系统能够在光照减弱的场景中跟踪驾驶员面部。
| 表II 不同场景下系统EOR整体准确率 |
|---|
| 此处应为原文中的表格内容,因未提供具体数据,故省略 |
表III显示了在不戴眼镜、戴眼镜和戴太阳镜的情况下,针对18个目标区域的白天准确率结果。总体而言,系统在图13所示的18个评估目标区域中的15个实现了高准确率。系统在以下位置的准确率低于90%:驾驶员遮阳板为80.68%,乘客遮阳板为87.20%,挡风玻璃右下角为86.16%。这些位置的系统性能下降是由于极端驾驶员头部姿态导致的面部特征跟踪问题所致。此外,对于戴眼镜的驾驶员,由于眼镜框引入的遮挡,这一问题进一步加剧。
| 表III 18个目标位置的白天系统EOR准确率 |
|---|
| 此处应为原文中的表格内容,因未提供具体数据,故省略 |
对于驾驶员遮阳板位置,系统在未戴眼镜的驾驶员情况下取得了满分。另一方面,对于戴眼镜的驾驶员,由于眼镜框导致的面部关键点跟踪错误,系统性能下降至80.34%。面部关键点跟踪错误导致头部姿态和视线估计不可靠。图14展示了一个由眼镜框引起的跟踪失败情况,
驾驶员移动头部以极端的头部姿态看向驾驶员遮阳板。注意,在图14(b)中,眼部特征点位于眼镜框上,因此瞳孔跟踪效果较差。对于佩戴太阳镜的驾驶员,该系统实现了由于严重的跟踪错误,准确率仅为61.87%。因此,仅基于头部姿态的EOR估计对于驾驶员遮阳板位置而言不够可靠,无法实现高准确率。与驾驶员遮阳板位置类似,由于佩戴眼镜和太阳镜的受试者面部特征跟踪不可靠,挡风玻璃右下角位置的EOR准确率受到影响,获得的准确率值为86.16%。
在乘客遮阳板位置的情况下,系统在白天的整体准确率达到87.20%。对于不戴眼镜和戴眼镜的驾驶员,我们的EOR估计系统分别取得了84.88%和80.23%的相似性能。与驾驶员遮阳板和挡风玻璃右下角位置类似,面部特征点的误差导致了驾驶员头部姿态和视线方向的误判,见图15。然而,对于佩戴太阳镜的驾驶员,系统未出现面部特征跟踪问题[见图16(a)],,获得了完美的EOR估计准确率。
| 表IV 夜间系统在18个目标位置的EOR准确率 |
|---|
| 此处应为原文中的表格内容,因未提供具体数据,故省略 |
表IV显示了夜间系统性能。同样,我们的系统在18个评估位置中的15个达到了高于90%的准确率。准确率低于90%的三个位置分别是:乘客遮阳板、挡风玻璃左上角和挡风玻璃右下角,其准确率分别为86.25%、89.87%和89.70%。需要注意的是,在白天实验中,乘客遮阳板和挡风玻璃右下角这两个位置的系统准确率也低于90%。在夜间实验中,佩戴眼镜和未佩戴眼镜的驾驶员均出现了类似的跟踪问题,这与白天情况相似。因此,由于红外照明提供了高效的光照,夜间系统表现与白天结果保持一致。然而,根据表II,系统在夜间对在道路上和车外区域的准确率略高于白天(白天和夜间的准确率相差∼1%)。
 显示驾驶员佩戴太阳镜时EOR系统的工作情况。请注意,此种情况下EOR估计是基于头部姿态角(蓝色线条)计算的;b)显示白天工作情况,驾驶员未佩戴眼镜;c)和 d)显示夜间佩戴眼镜的驾驶员情况下系统的运行状态。)
显示驾驶员佩戴太阳镜时EOR系统的工作情况。请注意,此种情况下EOR估计是基于头部姿态角(蓝色线条)计算的;b)显示白天工作情况,驾驶员未佩戴眼镜;c)和 d)显示夜间佩戴眼镜的驾驶员情况下系统的运行状态。)
C. 表情变化下的头部姿态鲁棒性
本节描述了一项实验,用于评估头部姿态估计在极端面部表情下的鲁棒性。
1) 评估协议和数据集
我们在三种不同的夸张面部表情下评估了头部姿态估计算法:张嘴、微笑以及动态面部表情变形。在张嘴和微笑两种情况下,受试者在整个十秒录制过程中保持该表情。而在动态面部表情中,受试者会随机且持续地移动嘴部(例如说话、张嘴、微笑)。图17展示了这些形变的示例。
受试者被要求在初始化步骤中注视挡风玻璃5秒钟。随后,受试者被指示看向车内若干特定位置。我们选用了图13中所示目标位置的一个子集,具体为九个位置: S={2, 6, 8, 10, 11, 12, 14,16, 18}。其余位置在本次实验中是冗余的。受试者首先以中性表情注视某一特定位置10秒钟,然后执行三种表情之一,我们再记录10秒钟。在这20秒内,受试者的头部姿态保持不变。总计,每位受试者在注视每个位置时,我们获得了一段25秒视频(包括初始化阶段)。图18展示了该数据采集过程。与之前的实验一样,我们在计算性能指标时未使用初始化阶段的帧。
对于每种表情,我们记录了五名不同的受试者。人群种族分布包括六名亚洲人和四名高加索人。此外,十名受试者中有七人佩戴眼镜。总共我们有∼81 000帧(3种表情 ×5名受试者 × 20秒 × 30 FPS × 9位置)。我们评估了表情发生时头部姿态角的偏差。即,我们计算中性表情阶段十秒钟与表情阶段十秒钟之间的平均头部姿态角的差异。我们计算了平均绝对误差(MAE),以及中性(σ NoEx p )和表情(σ Ex p )阶段的标准差。
2) 实验结果
表V–VII总结了本次实验的结果。
表V显示了头部姿态估计对大张嘴表情的鲁棒性。根据平均绝对误差指标,滚动角估计受影响最小,而偏航角和俯仰角则更为敏感。这是在评估的三种面部表情中普遍存在的现象。偏航角估计在右上方和挡风玻璃顶部中央位置的平均绝对误差最高,偏差分别为5.51度和4.96度。在俯仰角方面,最大偏差出现在驾驶员侧后视镜和挡风玻璃左上位置,平均绝对误差分别为4.30和4.22。偏航角和俯仰角估计的误差是由面部特征点跟踪问题引起的。错误的特征点估计导致驾驶员头部的三维模型失真,从而造成头部姿态估计的误差。然而,在无表情(σNoExp)和表情( σExp )阶段期间,头部姿态估计的方差没有表现出显著差异。需要注意的是,张嘴是一种静态表情,即驾驶员在表情阶段的十秒内保持这一面部表情。
表六显示了微笑表情下的实验结果。与张大嘴表情的情况类似,估计的头部姿态角的方差没有显著差异。在这种情况下,微笑表情更容易跟踪,跟踪器丢失的频率更低。这导致平均绝对误差的估计值误差和方差更小,但在导航系统位置的偏航角估计中出现了较高的平均绝对误差。
表七显示了驾驶员进行动态表情时获得的结果。我们可以看到,在表情阶段(σ Ex p ),所有目标位置的头部姿态估计变化量显著增加。这是因为在测试期间,个体的面部表情发生了较大变化。然而,我们可以观察到,偏航角、俯仰角和翻滚角的最大绝对误差与之前研究的面部表情的最大绝对误差相似。头部姿态角估计中较大的方差是由于用户从一种表情突然切换到另一种表情时出现跟踪不稳定所致。
| 表V 张嘴表情对头部姿态估计的影响 |
|---|
| 此处应为原文中的表格内容,因未提供具体数据,故省略 |
| 表六 微笑表情对头部姿态估计的影响 |
|---|
| 此处应为原文中的表格内容,因未提供具体数据,故省略 |
| 表七 动态表情对头部姿态估计的影响 |
|---|
| 此处应为原文中的表格内容,因未提供具体数据,故省略 |
V. 结论
本文介绍了一种使用安装在转向柱上的单目相机视频的实时EOR系统。所提出系统的三个主要创新点为:(1)基于监督下降方法的鲁棒面部关键点跟踪器;(2)对三维驾驶员姿态、位置和视线方向进行精确估计,且对非刚性面部形变具有鲁棒性;(3)利用车辆/驾驶员几何结构的三维分析进行EOR预测。该系统能够在白天和夜间检测EOR,并适用于广泛的驾驶员特征(例如,戴眼镜/戴太阳镜/不戴眼镜、不同种族、年龄等,…)。该系统无需特定校准或手动初始化。更重要的是,即使摄像头位置发生变化或重新定义道路上区域,也无需进行重大重新校准。这得益于显式的三维几何推理。因此,在不同车型上安装该系统无需额外的理论开发。
该系统在所有评估场景中的准确率均超过90%,包括夜间操作。此外,在道路上区域的误报率低于5%。我们的实验表明,我们提出的头部姿态估算法对极端面部变形具有较强的鲁棒性。尽管我们的系统已取得令人鼓舞的结果,但我们认为,在具有挑战性的情况下(例如侧脸、带粗框眼镜的面部)提升面部特征检测性能,将进一步提高系统的整体表现。目前,我们还在利用基于霍夫变换的技术改进瞳孔检测,以进一步提升视线估计的精度。


















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









