



 本文介绍了在《机器学习预测全家桶-Python》系列中,作者更新了使用CEEMDAN结合不同深度学习模型(如CNN、BiGRU、BiLSTM等)的代码,以提升电力负荷预测的精度。通过分解数据并针对每个模态构建独立预测模型,结果显示CEEMDAN方法有效改善了预测效果。文中还提供了所需Python包的版本信息。
本文介绍了在《机器学习预测全家桶-Python》系列中,作者更新了使用CEEMDAN结合不同深度学习模型(如CNN、BiGRU、BiLSTM等)的代码,以提升电力负荷预测的精度。通过分解数据并针对每个模态构建独立预测模型,结果显示CEEMDAN方法有效改善了预测效果。文中还提供了所需Python包的版本信息。
截止目前,机器学习预测全家桶
本期继续更新《机器学习预测全家桶-Python》,截止目前,全家桶包含代码目录如下:
本期新增CEEMDAN相结合的代码,包含如下:
CEEMDAN-CNN-BiGRU、CEEMDAN-CNN-BiLSTM、CEEMDAN-CNN-BiLSTM-Attention、CEEMDAN-CNN-LSTM、CEEMDAN-LSTM
所谓CEEMDAN相结合的原理与VMD相结合原理是一致的,都是将原始数据分解为数个有限带宽的模态分量,以降低原始数据的复杂度,确保不会发生模态混叠现象,提高数据清晰度,然后每个模态分别构建一个预测模型进行预测,最后把每个分量的结果相加得到最终的预测值。步骤如下:
1)首先对原始数据进行预处理;
2)对处理完的数据进行CEEMDAN分解,分解为K个模态分量和1个残差分量;
3)将各个模态分量输入模型,建立模型进行预测;
4)将各个预测结果相加得到最终的结果。
结果展示如下:
数据依旧采用《电力负荷预测数据2.xlsx》,采用前5个时刻数据,预测未来一个时刻数据。更多关于数如何处理,请看前三期文章:
1.机器学习预测全家桶-Python,一次性搞定多/单特征输入,多/单步预测!
3.机器学习预测全家桶-Python,新增VMD结合代码,大大提升预测精度!
结果展示:
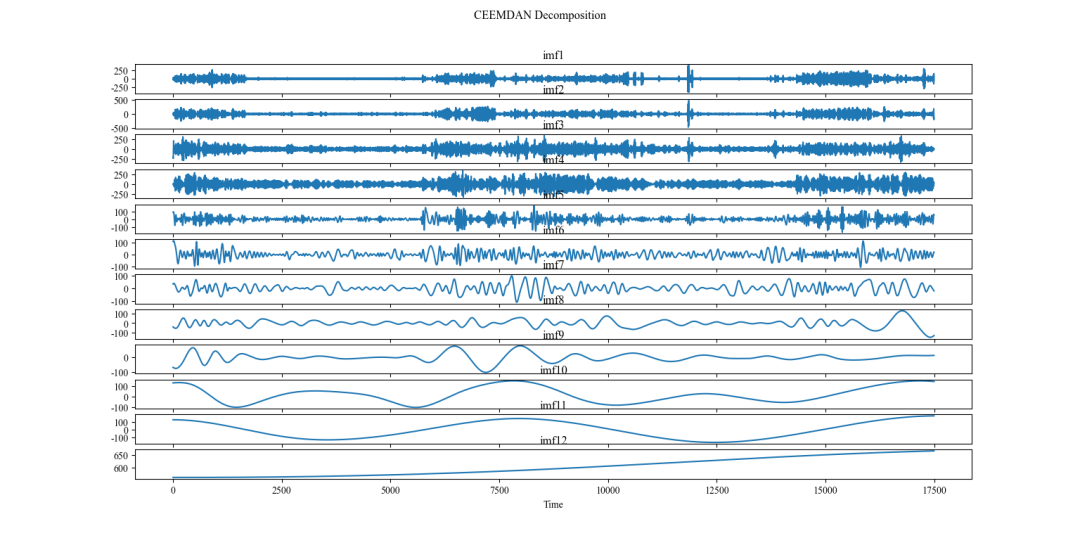
CEEMDAN分解图,对负荷数据那一列进行分解。
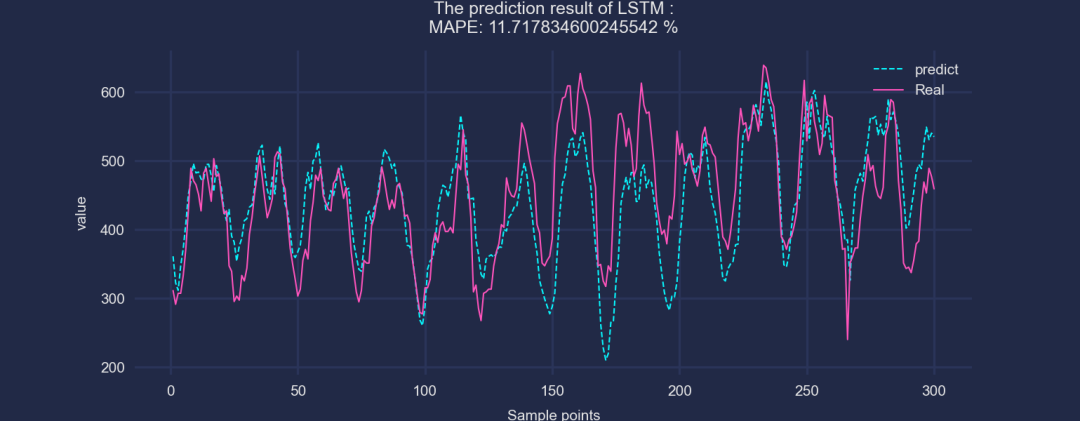
①基本的LSTM预测结果:

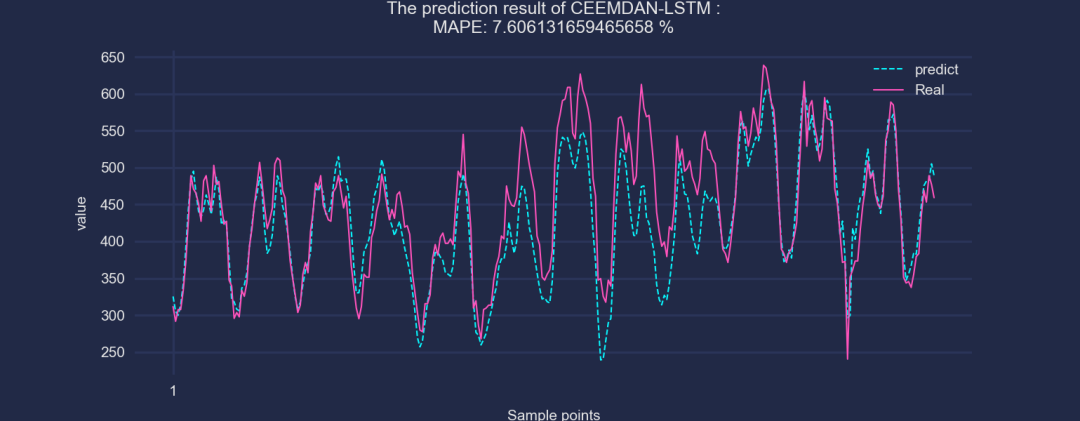
②CEEMDAN-LSTM

③CEEMDAN-CNN-LSTM

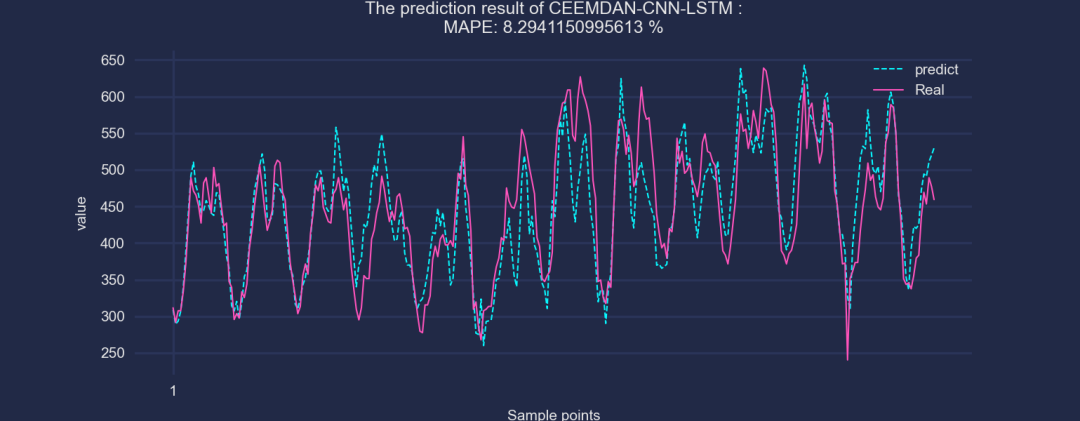
④CEEMDAN-CNN-BiGRU

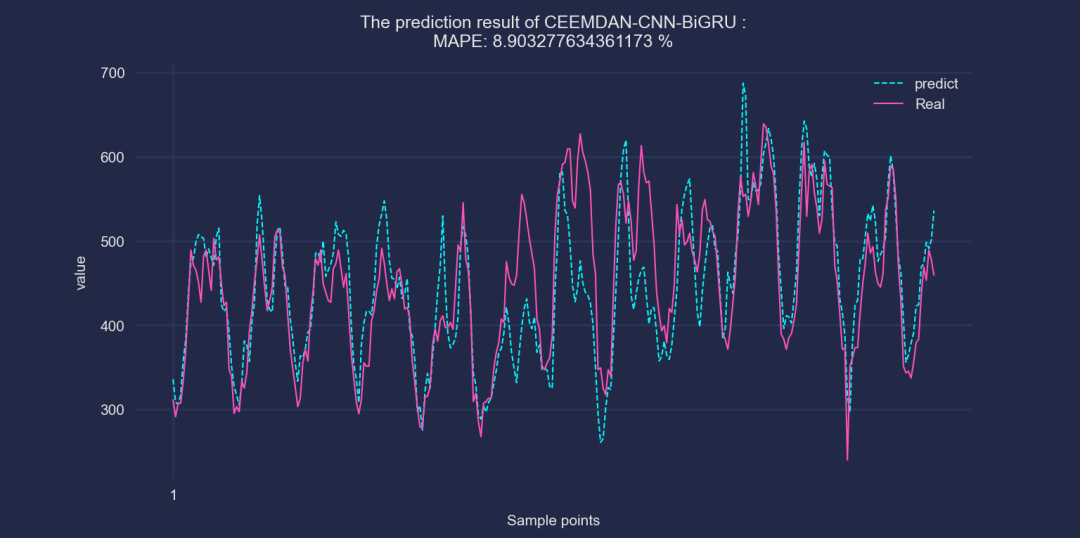
⑤CEEMDAN-CNN-BiLSTM

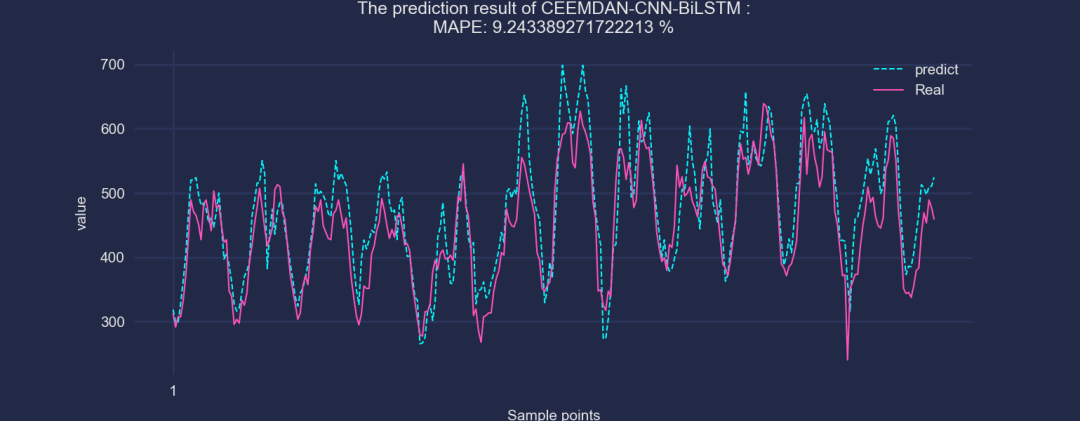
⑥CEEMDAN-CNN-BiLSTM-Attention

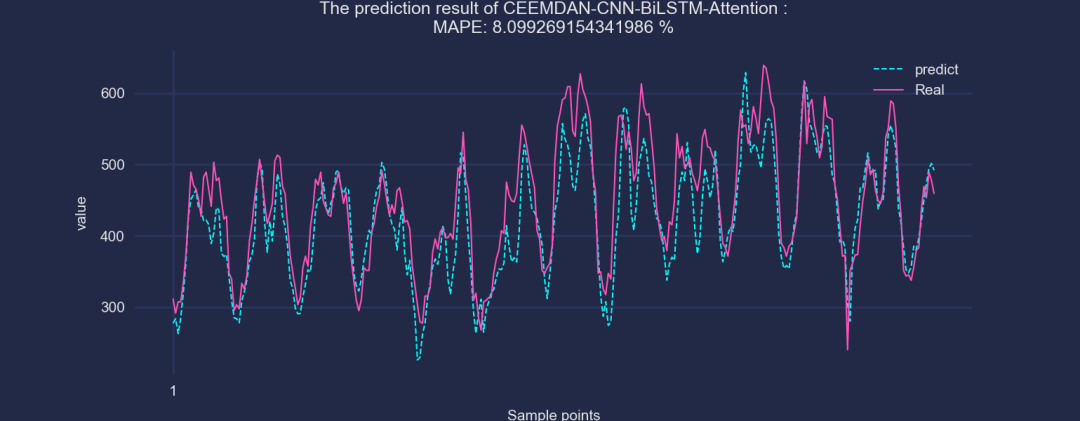
可以看到,加了CEEMDAN之后,效果是有显著提升的!
模型亲测python3.9版本可用。用到的包版本推荐如下:
pandas~=2.2.0
matplotlib~=3.8.2
numpy~=1.26.3
tensorflow~=2.15.0
scipy~=1.12.0
scikit-learn~=1.4.0
keras~=2.15.0
seaborn~=0.13.1
openpyxl~=3.1.2
mplcyberpunk~=0.7.1
qbstyles~=0.1.4
xgboost~=2.0.3
pip~=23.3.2
wheel~=0.42.0
setuptools~=49.2.1
vmdpy~=0.2
prettytable~=3.9.0或点击下方阅读原文获取此全家桶。
后续有更新直接进入此链接,即可下载最新的!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











