



 本文详细介绍了结构体内存对齐的基本概念、规则及其原因,包括不同平台的默认对齐数,并通过具体例子展示了如何计算结构体的大小及偏移量。
本文详细介绍了结构体内存对齐的基本概念、规则及其原因,包括不同平台的默认对齐数,并通过具体例子展示了如何计算结构体的大小及偏移量。
a>结构体内存对齐的概念
我们现在使用的算机中内存空间都是按照字节(Byte)划分的,理论上说,似乎对任何类型的变量的访问可以从任意地址开 始,但实际情况则是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型的数据按照一定的规则在内存 空间上排列,而不是顺序的一个接一个地排放,这就是对齐。
b>结构体内存对齐的规则
1. 第⼀个成员在与结构体变量偏移量为0的地址处。
2. 其他成员变量要对⻬到某个数字(对⻬数)的整数倍的地址处。对⻬数 = 编译器默 的⼀个对⻬数 与 该成员⼤⼩的较⼩ 值。 VS中默认的值为8 Linux中的默认值为4
3. 结构体总⼤⼩为最⼤对⻬数(每个成员变量都有⼀个对⻬数的整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体对⻬到⾃⼰的最⼤对⻬数的整数倍处,结构体的整体大小就是所有对⻬数最大值 ( 含嵌套结构体的对⻬数的整数倍。
5.如果嵌套了联合体,将联合看成一个普通成员,这个成员的大小就是联合体的大小。这个成员的对齐数就是联合体的大小 和默认对齐数的较小值。
c>为什么要有结构体内存对齐
1、使用平台的原因:不是在所有平台上都可以访问任意内存的地址,所以需要适当的进行偏移,偏移到我们可以访问的位置 上进行数据存储。
2、内存对齐可以使访问速度提高:为了访问未对齐的内存,处理器需要两次内存访问;然而,对齐的内存访问仅需要一次访 问
d>默认对齐数
Linux 默认#pragma pack(4)
window 默认#pragma pack(8)
注:可以通过预编译命令#pragma pack(n) ,n=1,2,4,8,16来改变这一系数,其中的n就是指定的“对齐系数”。
总结:内存对齐就是通过空间换时间的做法。
举例说明
struct A
{
int a;
double d;
char c;
};
union C
{
int a;
char c;
};
struct B
{
int a;
A s;
C d;
double c;
};
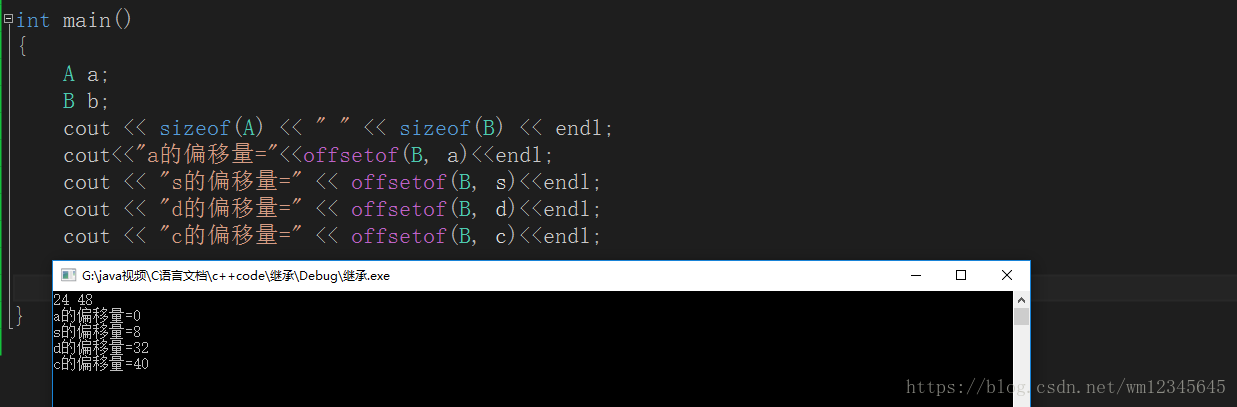
int main()
{
A a;
B b;
cout << sizeof(A) << " " << sizeof(B) << endl;
return 0;
}
Windows 上面跑 默认对齐数为8 结果为 24 48
下面画出结构体B的内存图
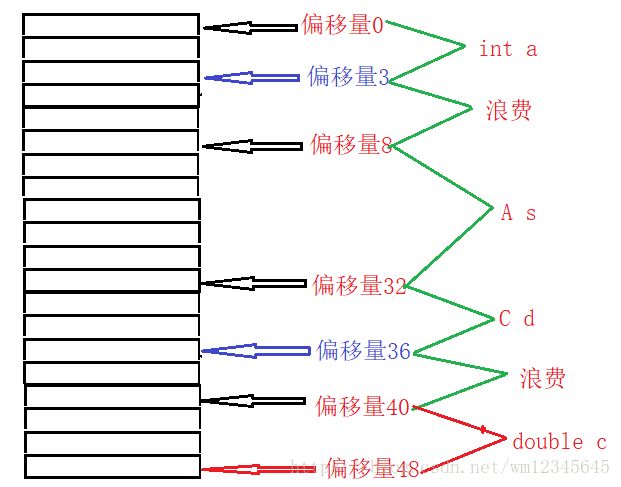
用offsetof宏来验证
e>offsetof宏解析
#define offsetof(type, member) ((size_t)(&((type *)0)->member))
type就是结构体名字,member是结构体成员变量名
((type*)0):将0强转为结构体类型的指针
((type*)0)->member : 结构体指针指向成员变量,得到成员变量
&((type*)0)>member :取结构体成员的地址
(size_t)&((type*)0)->member:将结构体成员的地址强转为size_t ,
因为结构体指针是0地址处,所以得到的成员的地址就是相对于0地址处的偏移量。

















 7097
7097

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









