



1. 缓存穿透如何解决?(有大量不存在的key访问redis)
缓存穿透,即穿透过缓存,直接访问mysql等其他关系型数据库;
比如有黑客故意用很多不存在的key来访问redis,导致mysql过载运行;
布隆过滤器或者 在查询mysql无果后,缓存null值到redis;
缓存穿透,就是穿透了redis 打到了mysql上,可以加锁,让查询不到redis的操作暂时等待,加锁后,查询到数据,放入redis,解开锁就可以了
link
2. redis如何处理缓存 雪崩?(有大量的key在同一时间)
雪崩的含义是指,在某个时间段,redis有大量的数据不可访问,
解决办法:
1 加锁,防止有大量的并发来访问数据库;当时实际运用中,考虑到用户体验,一般不会这样做;
2 我们的做法是在原有的设计的失效时间基础上,随机加上一个1 - 5 分钟的随机时间,让失效时间更加的散列;降低缓存雪崩的几率;
3. redis为什么那么快?
(单线程)使用了nio 多路复用机制、基于内存的缓存、良好的数据结构(SDS、跳跃表、字典等)
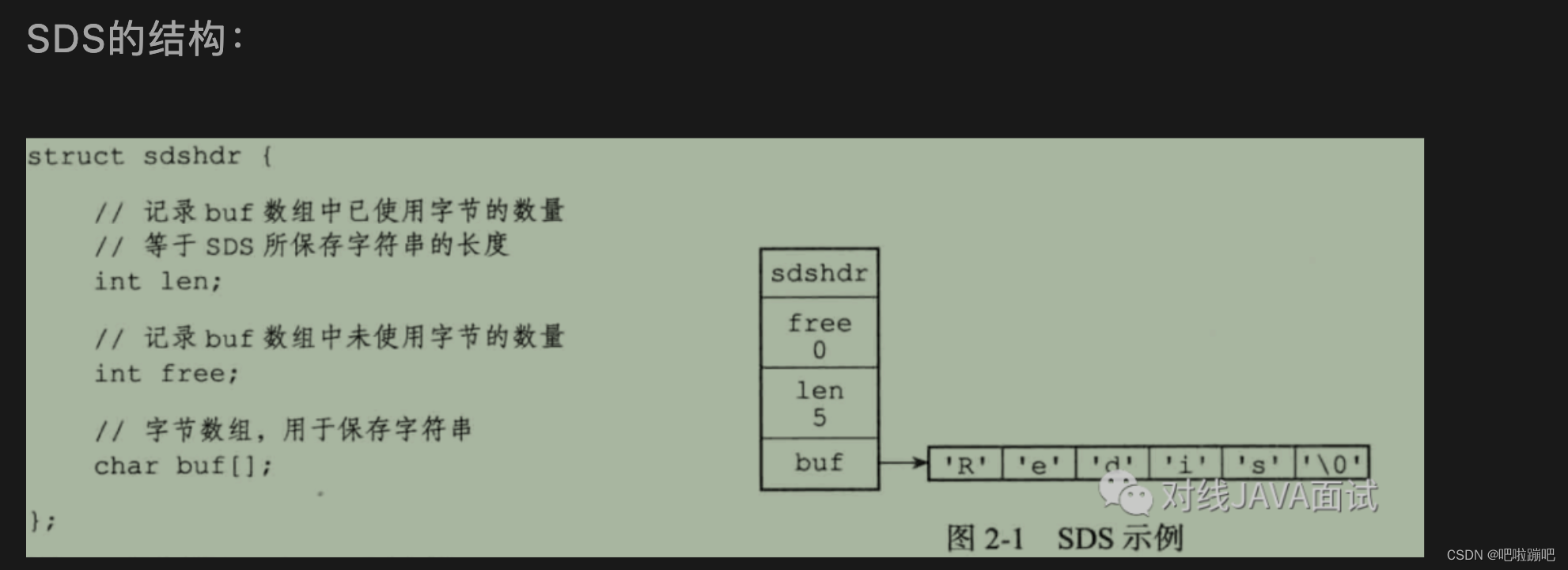
4. 几种数据结构
redis中有哪些数据结构?
使用了 SDS、 链表、字典、跳跃表、压缩表 等数据结构
| msg | 解析 | 备注 |
|---|---|---|
| list 列表对象 | 用双向链表实现;特点是有序可重复,优点:放入数据快,缺点:定位慢 | |
| set | set是redis的无序集合,是通过哈希表实现的,因此任何操作(添加、删除和测试成员的存在性等)的时间复杂度是O(1)。(无论集合中包含多少元素,时间都是常量 | |
| hash对象 | 哈希对象的编码可以使用 ziplist 或 dict 压缩表 或者字典 | |
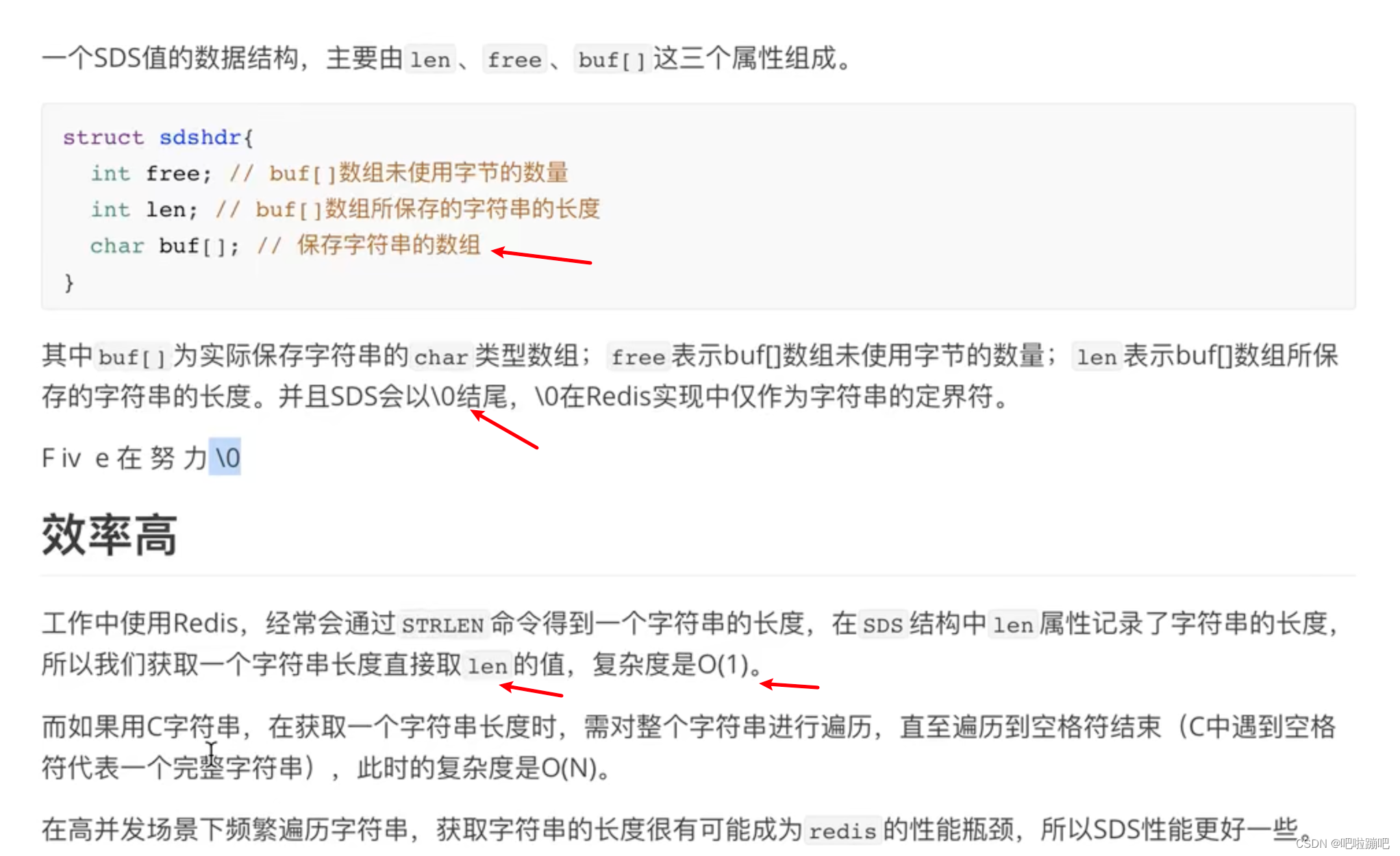
| 字符串使用 SDS | 防止buf内存溢出;二进制存储,安全;得到字符串长度的效率为O(1);空间预分配 | |
| zset数据结构 | 当数据长度小于64字节同时个数小于128个(参数可调)用的压缩编码 ziplist;否则用的数据字典 + skiplist | |
zset 如何排序?
Set的每个成员都与分数相关,分数是用来进行排序的;
hash 对象如何扩容?
渐进式扩容 rehash

5. redis如何防止数据的丢失
redis具有良好的数据备份机制,分别是AOF 和RDB;
RDB 默认开启;方式是间隔一个时间存储数据,缺点是可能导致 数据丢失;
AOF 是 记录 Redis的写入记录,不会导致数据丢失,缺点是磁盘占用空间大;
如果数据非常重要,建议两种同步方式都开启;
如果AOF将要把磁盘写满怎么办?
AOF会开启一个新的线程,同步最新的Redis快照,然后删除旧的AOF文件;
6. Redis的内存不足怎么办?(先讲原理(带上优缺点),再讲现实)
link
首先 Reids内存,它会使用定期淘汰机制 + 惰性淘汰机制来管理内存;
具体而言;redis默认是100ms 随机抓取一批设置了过期时间的数据来检测,发现有过期的,delete;但是缺点是有的数据过期了不能被及时清理;
所以惰性淘汰机制就起作用了,当访问redis的key到来,redis查询到数据,先检查是否已经过期,如果过期delete数据;返回null;
同时,redis在内存不足的情况下,会有多种淘汰机制可以选择,比如Random 、LRU、LFU;现实使用大多使用LRU,根据最近使用的时间戳和现在的时间的间隔大小作为热度依据;其实Redis 4.0出现的LFU 是使用频次作为
热度依据;显得更加合适;
然后,如果在redis以上机制上,想继续优化内存不足问题,可以考虑:
1 加大内存空间,2 在业务允许的前提下,将一些大对象的失效时间调小些;
7. Redis 如何实现高可用?
部署的时候进行集群部署,开启主从同步;
数据恢复上同时开启 RDB 和 AOF 两种数据写入磁盘的模式;
8. 主从模式,leader挂了怎么办?
哨兵进程会使用raft算法进行选择;
具体的说,有两步一是过滤,二是排序; 先过滤掉down机的salve节点,然后对可用节点进行一定的优先级排序,
选出最靠前的节点作为leader节点;
9. Redis 慢查询 了解吗
慢查询就是指规定某个时间的查询没有返回数据的查询为慢查询,可以使用 slowlog- 设置 多长时间为慢查询,
慢查询的容量长度;
底层存储慢查询数据结构是链表
slowlog get 查询 数据
link
10. Redis 如何架构
3.2 版本 使用去中心化集群架构,数据散落在各个节点上,同步数据使用Gassip 病毒传播协议;
11. 你们用的那个版本
3.2
12. 使用redis的场景
缓存数据、分布式锁、排行榜(zset)、计数(incrby)、消息队列(stream)、地理位置(geo)、访客统计(hyperloglog)等
13. redis 是单线程还是多线程?
虽然在后面的高版本引入了多线程,但是这个多线程运用在数据IO上,而查询数据的过程依旧使用了NIO 多路复用模型下的单线程;
14. redis 查询慢怎么办?
先用 slow log get 查询 到那些操作慢;
一般是因为使用了过于复杂的命令导致的,比如在内存中遍历大量数据 排序 等导致的;
优化代码
15. 主从同步原理
link
核心点在于RDB的同步;
流程上,先发送命名建立TCP连接;
master发送RDB文件给从节点,从节点吃进去;
因为这段时间可能master有新数据来了,所以master等从节点告诉自己,RDB我吃完了,master还要发送一个缓存刚才那段时间的新数据的buffer给从节点;
之后两者数据就完全一样了;
之后master就一直发指令给从节点,我干什么,你照着做就可以;
另外,主从同步原理是开启哨兵机制的前提,也是做集群高可用的基础;
16 Redis可以用来干什么
list 存储很火热的文章,我使用list作为队列使用,因为取得队列两端的数据是非常快速的,时间复杂度为O(1)
volatile
AtomicInteger 等原子类都是使用的 volatile 加 unsafe类实现的;
高并发
| msg | 解析 | 备注 |
|---|---|---|
| 原子性 | 加锁实现的 | |
| 可见性 | jvm中的happen-before模型 实现的 | |
| 有序性 | 内存屏障 防止指令重排序 | |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









