






 本文详细介绍了一种利用Selenium和Scrapy爬取豆瓣读书评论的实战方法,从构造搜索URL到获取书本ID,再到集成Selenium进行JS渲染内容抓取,最终实现对大量评论的高效爬取。
本文详细介绍了一种利用Selenium和Scrapy爬取豆瓣读书评论的实战方法,从构造搜索URL到获取书本ID,再到集成Selenium进行JS渲染内容抓取,最终实现对大量评论的高效爬取。
文章目录
想做一个爬虫, 输入一个关键字, 然后爬取豆瓣读书的第一个搜索结果的所有评论.
思路
1. 根据关键字构造豆瓣搜索url, 根据结果获取书的id
如https://book.douban.com/subject_search?search_text=太空漫游, 第一个结果的链接中包含了这本书的id.
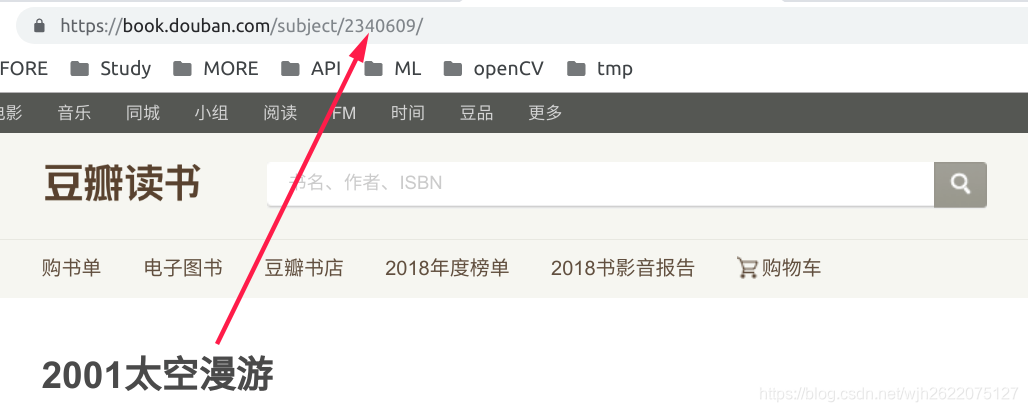
2. 根据id, 构造该书评论的url链接
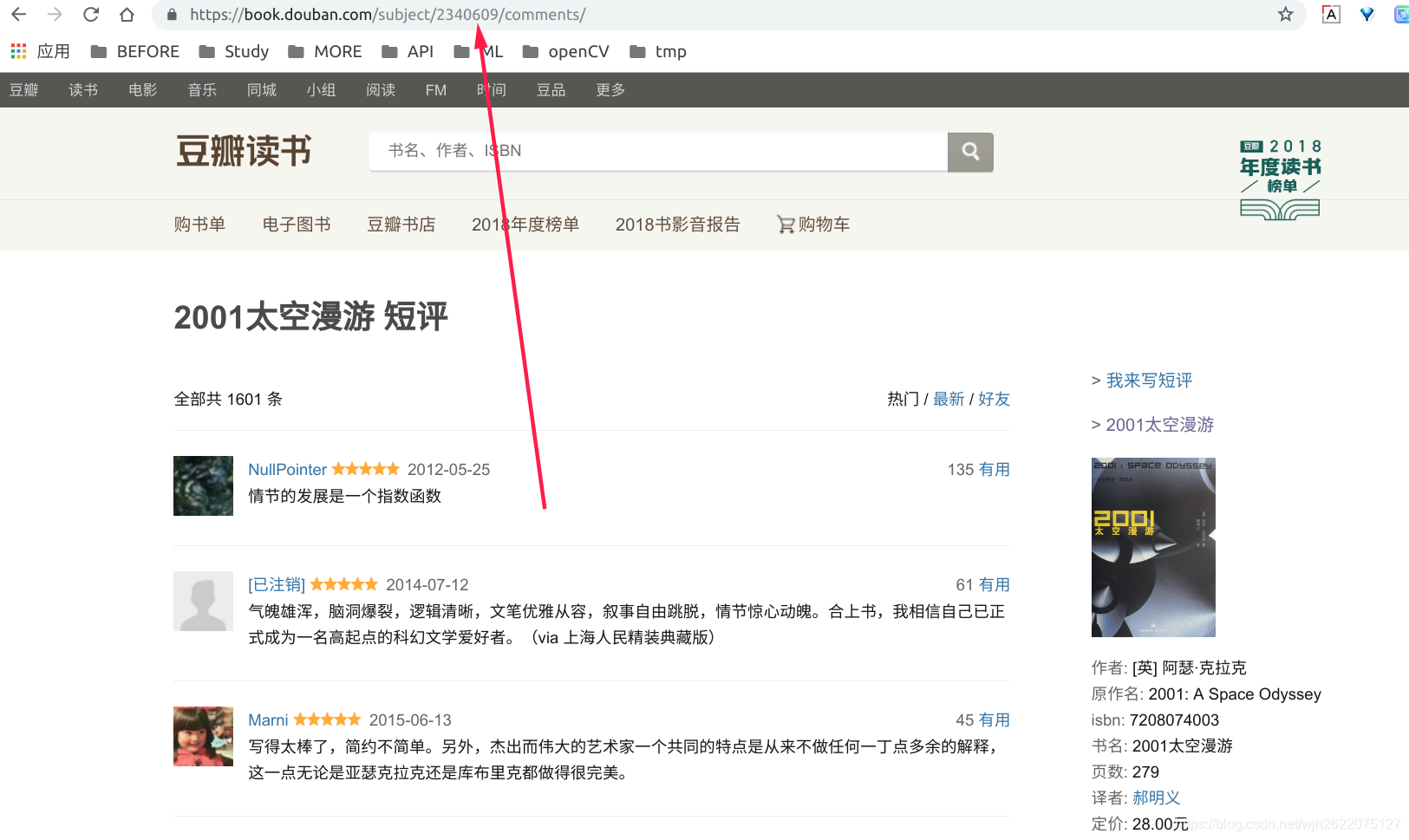
3. 爬取网页内容, 并构造下一页url
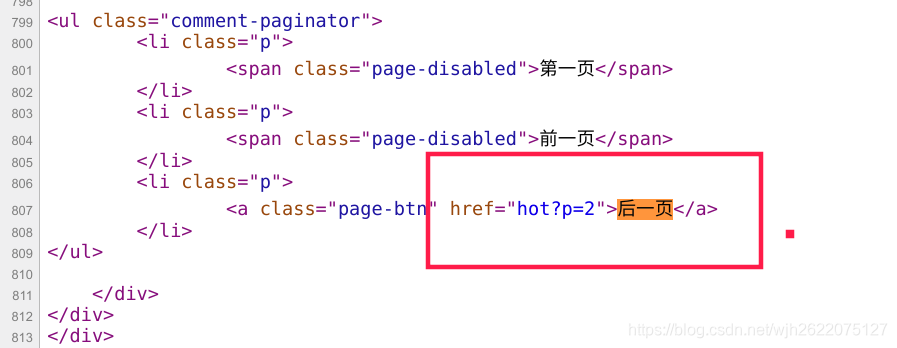
4. 重复步骤3, 反复爬取
过程
1. 页面爬取测试
使用scrapy genspider doubanComments book.douban.com生成爬取模板
基本代码爬取豆瓣读书主页book.douban.com 成功
# -*- coding: utf-8 -*-
import scrapy
class DoubancommentsSpider(scrapy.Spider):
name = 'doubanComments'
allowed_domains = ['book.douban.com']
start_urls = ['https://book.douban.com/']
def parse(self, response):
print("hello?")
with open("doubanComments.html", 'wb') as douban_comments_file:
douban_comments_file.write(response.body)
爬取太空漫游评论页也成功
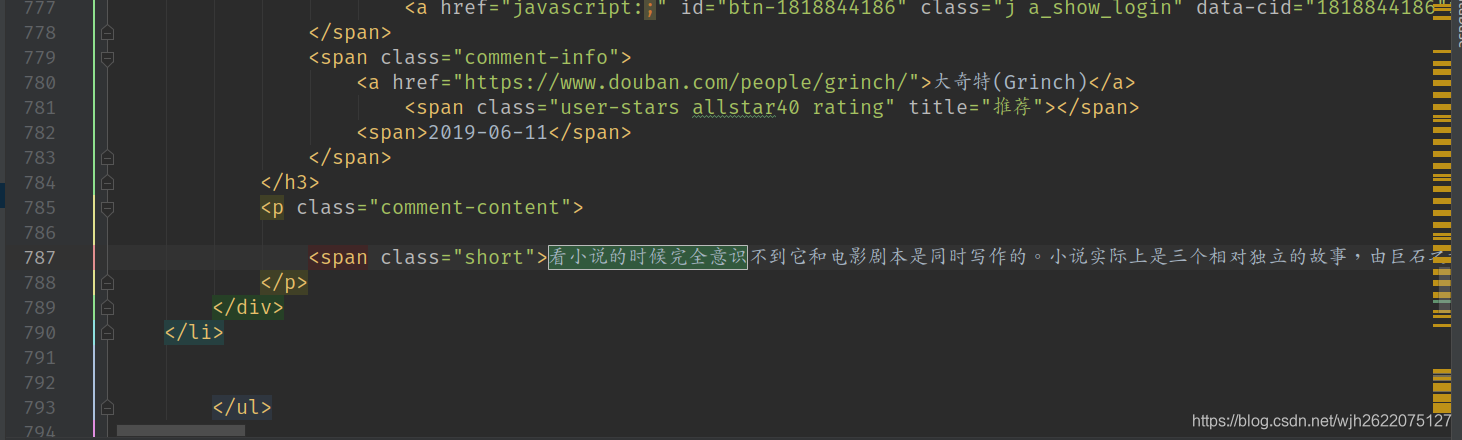
但是, 当我查看搜索页面的源码时, 发现并没有列表的信息, 关键字"太空漫游"少的可怜. 仔细查看发现, 它使用js渲染的, 直接看是看不到的.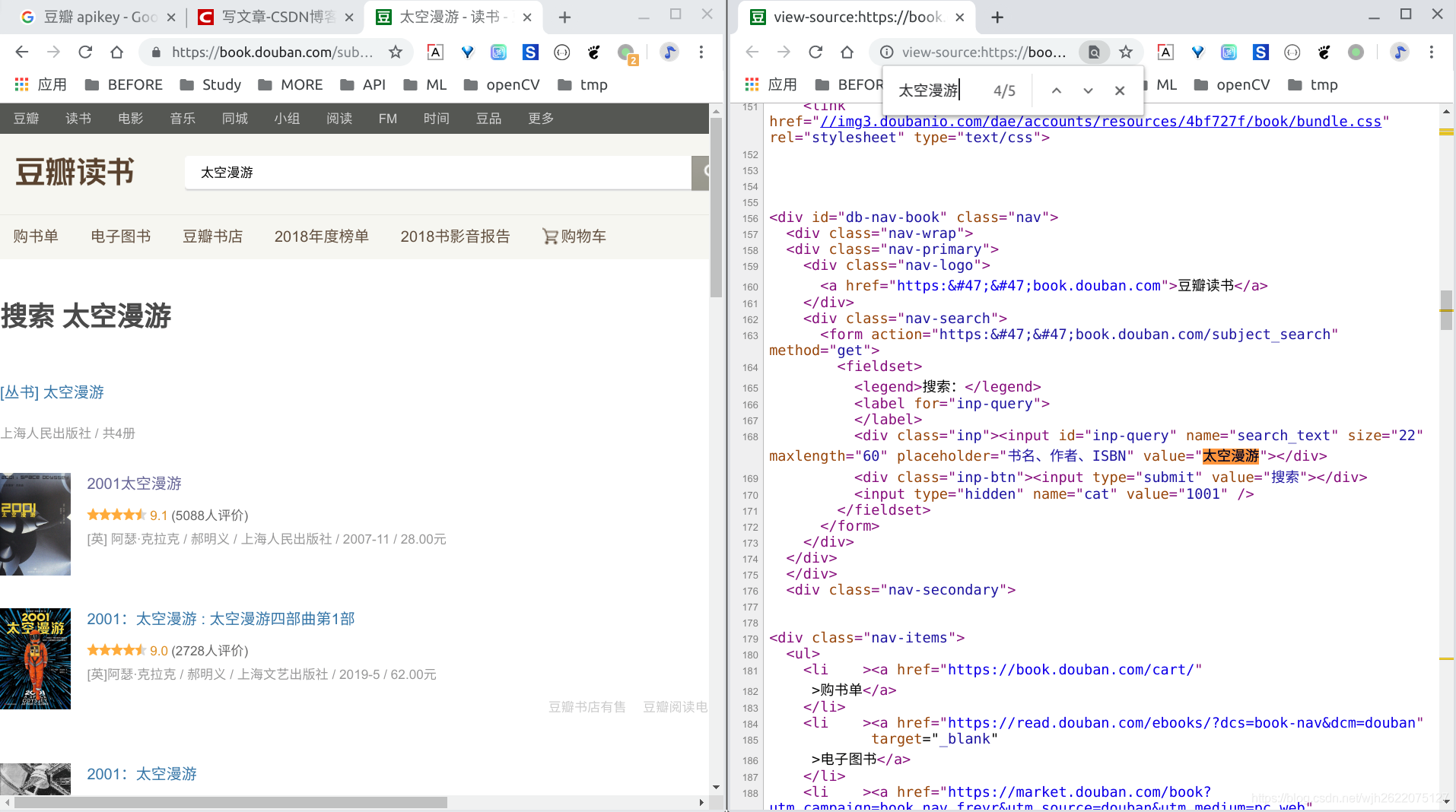
用Chrome的检查元素发现, 可以看到列表信息. 但是直接爬取是看不到的. 因此无法用这种简单的方法找到书的id.
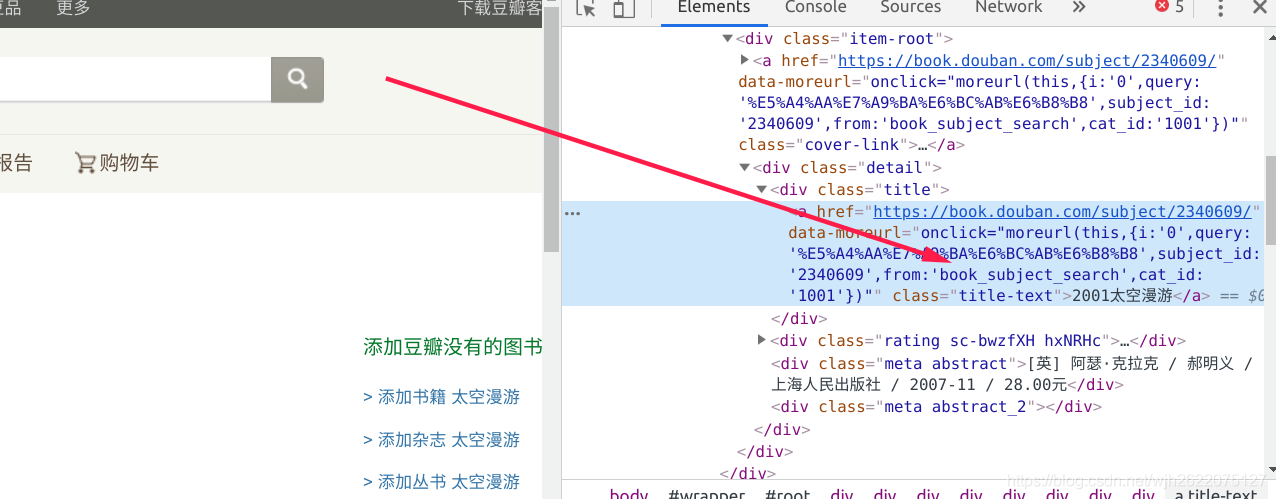
2. 使用selenium工具获取id
因此我们使用可以查看js渲染结果的工具Selenium.
首先安装Selenium
pip install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple
然后下载ChromeDriver
到官网下载对应系统和版本
写一个简单的selenium程序, 成功加载出js渲染的内容
代码
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://book.douban.com/subject_search?search_text=%E5%A4%AA%E7%A9%BA%E6%BC%AB%E6%B8%B8')
with open("douban.html", 'w+', encoding='utf-8') as file:
file.write(browser.page_source)
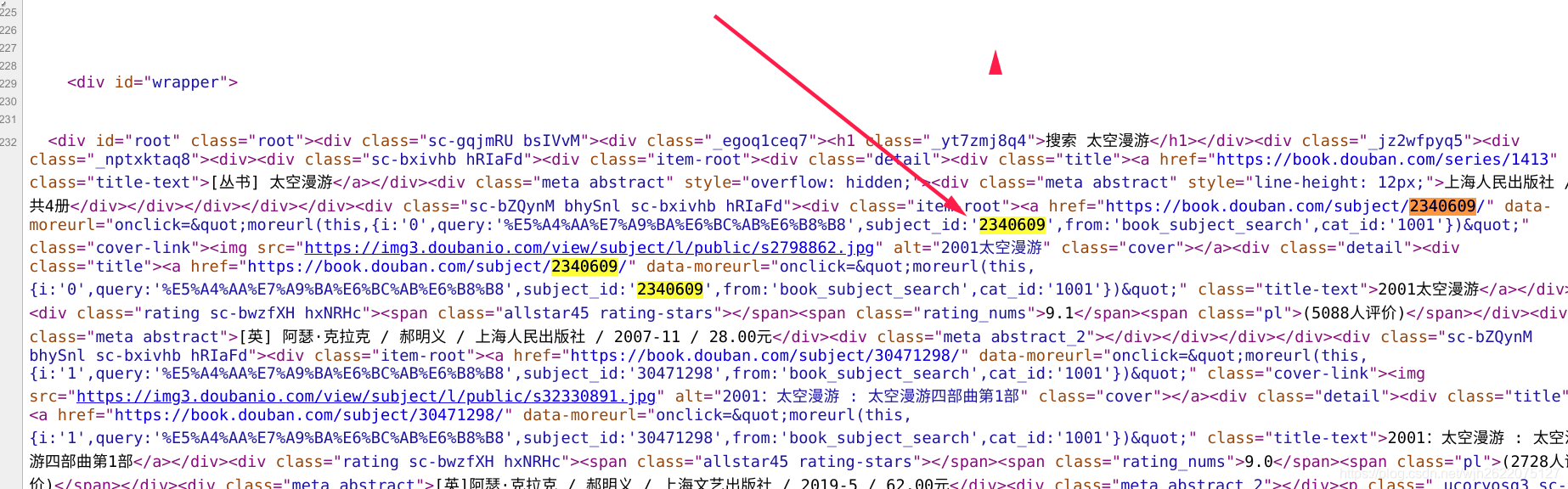
3. 将selenium集成到scrapy中
将selenium集成到scrapy中, 写他所在的getID函数用来获取一本书的id.
接下来就是普通的爬虫爬取过程了, 内容如
- 初始化csv文件, 因为后面的写入评论用的是追加模式, 每次运行都要重新
- 将评论按行写入到csv文件中
- xpath选择器找出下一页的href, 构造下一页的链接
- 使用scrapy.Request() 进行下一个页面的爬取
4. 爬取结果
爬取了太空漫游的1700+的评论
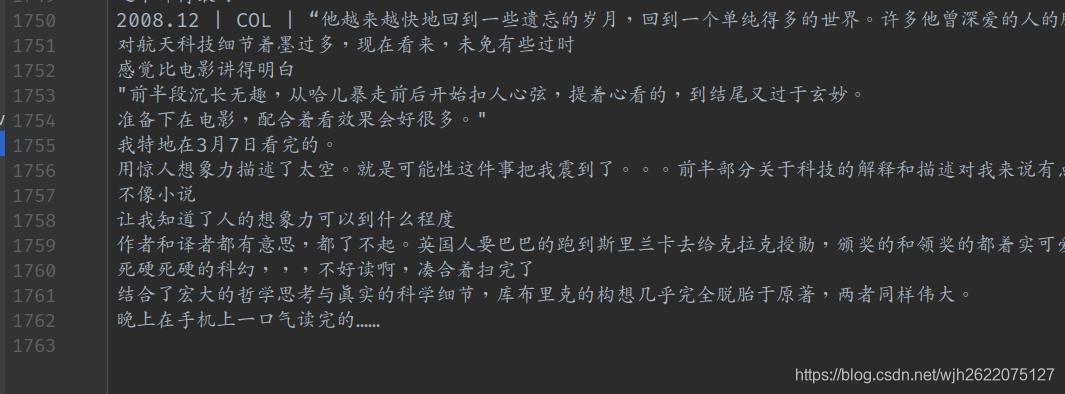
九州的5000+的评论
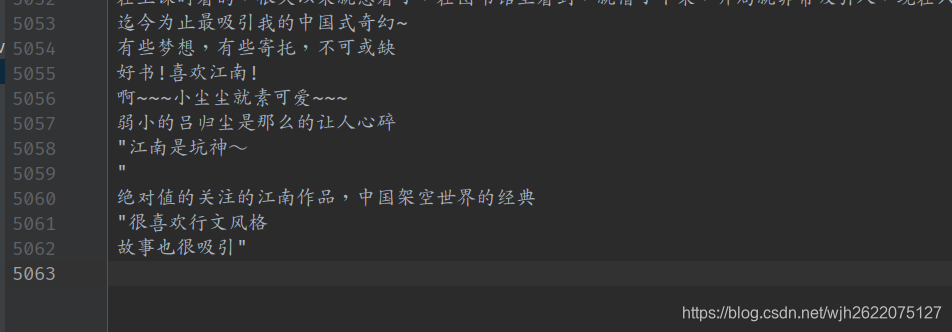
但是遇到了爬取九州的评论时候遇到了一个问题. 同一个ip在短时间内大量访问豆瓣, 被发现了, 然后禁止我爬取了.
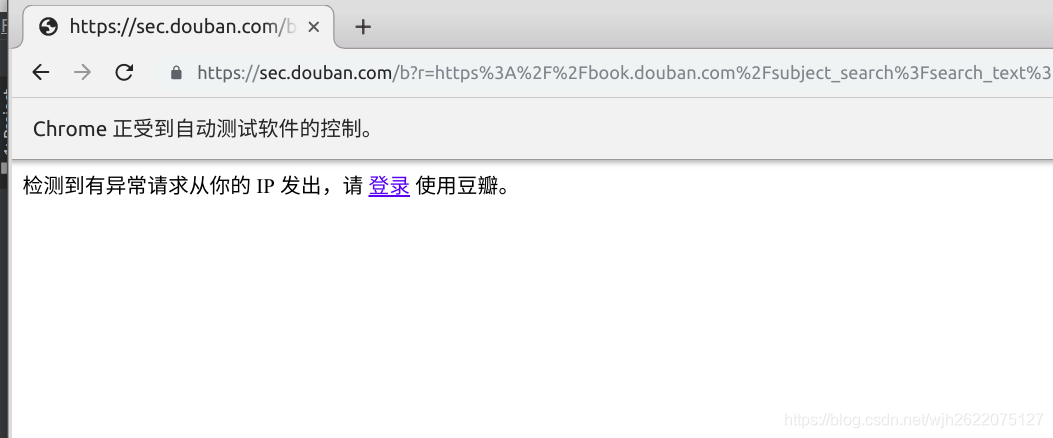
5. 阶段性spider代码
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver
import re, csv
def getID(search): # 获取书本id
browser = webdriver.Chrome()
browser.get('https://book.douban.com/subject_search?search_text={}'.format(search))
html = browser.page_source
id = re.findall(r'subject_id:\'(\d+)\'', html)[0]
return id
class DoubancommentsSpider(scrapy.Spider):
name = 'doubanComments'
search = input("请输入你要搜素的书籍: ")
id = getID(search)
with open("doubanBookComments_{}.csv".format(search), 'w', encoding='utf-8') as file:
file.write('')
start_urls = ['https://book.douban.com/subject/{}/comments/new'.format(id)]
def parse(self, response):
comments = response.xpath(r'//p[@class="comment-content"]/span/text()').extract()
# 江评论写入到csv文件
with open("doubanBookComments_{}.csv".format(self.search), 'a+', encoding='utf-8') as file:
writer = csv.writer(file)
for each in comments:
writer.writerow([each])
# 构造下一页进行爬取
next = response.xpath('//ul[@class="comment-paginator"]/li/a/@href').extract()
print("next = ", next)
next = next[-1]
url = self.start_urls[0] + next.replace("new", '')
print("url = ", url)
yield scrapy.Request(url=url, callback=self.parse)
ip异常问题
可以设置程序隔一段时间爬取一次, 也可以随机设置时间, 显得是人在操作. 不过这样爬完的时间就长了很多.
或者可以设置代理
免费的西刺代理
找一个可行的ip
需要注意的是, 免费代理ip需要测试多次找到一个可以使用的
1. 给selenium添加代理
原先browser = webdriver.Chrome() 改成下面有代理选项的代码
proxy = '61.128.208.94:3128' # 免费的代理ip
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://' + proxy)
browser = webdriver.Chrome(chrome_options=chrome_options)
2. 给scrapy添加代理
首先在middlewares.py文件的最后面, 添加下面的代理类
class ProxyMiddleware(object):
def process_request(self, request, spider):
request.meta['proxy'] = "https://61.128.208.94:3128" # 改成自己的代理
然后在settings.py后面添加下面代码
# 设置代理
DOWNLOADER_MIDDLEWARES = {
'tutorial.middlewares.ProxyMiddleware': 100, # tutorial改成自己的项目名称
}
使用selenium代理时, 可以使用browser.get('http://httpbin.org/get')来查看代理是否生效
3. 注意
上面的这个方法暂时只是权宜之计, 因为只设置了一个ip, 所以当这个新的ip对豆瓣进行访问时, 如果他在一定时间内的访问次数过多, 就也会封ip, 这这么短的时间内, 可能还来不及爬完一本书的全部评论. 所以正解应该是设置代理池(还不会).

















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









