




原文:
annas-archive.org/md5/9b92075f71de367fabcae691ae8a60bd译者:飞龙
前言
自动驾驶汽车很快就会出现在我们身边。这个领域的进步可以说是非凡的。我第一次听说自动驾驶汽车是在 2010 年,当时我在东京的丰田展销厅试驾了一辆。这次行程的费用大约是一美元。汽车行驶得非常慢,显然依赖于道路中嵌入的传感器。
快进几年,激光雷达和计算机视觉以及深度学习的发展使这项技术看起来原始且不必要地侵入和昂贵。
在本书的进程中,我们将使用 OpenCV 来完成各种任务,包括行人检测和车道检测;你将发现深度学习,并学习如何利用它进行图像分类、目标检测和语义分割,使用它来识别行人、汽车、道路、人行道和红绿灯,同时了解一些最有影响力的神经网络。
你将熟悉使用 CARLA 模拟器,你将使用它通过行为克隆和 PID 控制器来控制汽车;你将了解网络协议、传感器、摄像头,以及如何使用激光雷达来绘制你周围的世界并找到你的位置。
在深入探讨这些令人惊叹的技术之前,请花一点时间,尝试想象 20 年后的未来。汽车会是什么样子?它们可以自动驾驶。但它们也能飞行吗?是否还有红绿灯?这些汽车的速度、重量和价格如何?我们如何使用它们,使用频率如何?自动驾驶的公交车和卡车又如何?
我们无法预知未来,但可以想象自动驾驶汽车以及一般意义上的自动驾驶事物将以新的和令人兴奋的方式塑造我们的日常生活和城市。
你想在这个未来中扮演一个积极的角色吗?如果是这样,请继续阅读。这本书可能是你旅程的第一步。
这本书面向的对象
本书涵盖了构建自动驾驶汽车所需的多方面内容,旨在为任何编程语言(最好是 Python)有基本知识的程序员编写。不需要深度学习方面的先前经验;然而,为了完全理解最先进的章节,查看一些推荐的阅读材料可能会有所帮助。与第十一章,绘制我们的环境相关的可选源代码是用 C++编写的。
这本书涵盖的内容
第一章,OpenCV 基础和相机标定,是 OpenCV 和 NumPy 的介绍;你将学习如何操作图像和视频,以及如何使用 OpenCV 检测行人;此外,它还解释了相机的工作原理以及如何使用 OpenCV 对其进行标定。
第二章,理解和处理信号,描述了不同类型的信号:串行、并行、数字、模拟、单端和差分,并解释了一些非常重要的协议:CAN、以太网、TCP 和 UDP。
第三章,车道检测,教你如何使用 OpenCV 检测道路上的车道。它涵盖了颜色空间、透视校正、边缘检测、直方图、滑动窗口技术和获取最佳检测所需的过滤。
第四章,使用神经网络的深度学习,是神经网络的实用介绍,旨在快速教授如何编写神经网络。它描述了神经网络的一般原理,特别是卷积神经网络。它介绍了 Keras,一个深度学习模块,并展示了如何使用它来检测手写数字和分类一些图像。
第五章,深度学习工作流程,理想情况下与第四章,使用神经网络的深度学习相辅相成,因为它描述了神经网络的原理以及在典型工作流程中所需的步骤:获取或创建数据集,将其分为训练集、验证集和测试集,数据增强,分类器中使用的主体层,以及如何训练、推理和重新训练。本章还涵盖了欠拟合和过拟合,并解释了如何可视化卷积层的激活。
第六章,改进你的神经网络,解释了如何优化神经网络,减少其参数,以及如何使用批量归一化、早停、数据增强和 dropout 来提高其准确性。
第七章,检测行人和交通灯,向您介绍 CARLA,一个自动驾驶汽车模拟器,我们将用它来创建交通灯数据集。使用名为 SSD 的预训练神经网络,我们将检测行人、汽车和交通灯,并使用称为迁移学习的高级技术来训练神经网络,以根据颜色对交通灯进行分类。
第八章,行为克隆,解释了如何训练一个神经网络来驾驶 CARLA。它解释了什么是行为克隆,如何使用 CARLA 构建驾驶数据集,如何创建适合此任务的网络,以及如何训练它。我们将使用显著性图来了解网络正在学习的内容,并将其与 CARLA 集成以帮助它实现自动驾驶!
第九章,“语义分割”,是关于深度学习的最后一章,也是最高级的一章,它解释了什么是语义分割。它详细介绍了一个非常有趣的架构 DenseNet,并展示了如何将其应用于语义分割。
第十章,“转向、油门和制动控制”,是关于控制自动驾驶汽车的内容。它解释了控制器是什么,重点介绍了 PID 控制器,并涵盖了 MPC 控制器的基础知识。最后,我们将在 CARLA 中实现 PID 控制器。
第十一章,“映射我们的环境”,是最后一章。它讨论了地图、定位和激光雷达,并描述了一些开源的地图工具。您将了解什么是同时定位与地图构建(SLAM),以及如何使用 Ouster 激光雷达和 Google Cartographer 来实现它。
为了充分利用这本书
我们假设您具备基本的 Python 知识,并且熟悉您操作系统的 shell。您应该安装 Python,并可能使用虚拟环境来匹配书中使用的软件版本。建议使用 GPU,因为没有 GPU 时训练可能会非常耗时。Docker 将有助于第十一章,“映射我们的环境”。
请参考以下表格了解书中使用的软件:
如果您使用的是这本书的数字版,我们建议您亲自输入代码或通过 GitHub 仓库(下一节中提供链接)访问代码。这样做将帮助您避免与代码复制粘贴相关的任何潜在错误。
下载示例代码文件
您可以从 GitHub(github.com/PacktPublishing/Hands-On-Vision-and-Behavior-for-Self-Driving-Cars)下载本书的示例代码文件。如果代码有更新,它将在现有的 GitHub 仓库中更新。
我们还有其他来自我们丰富的图书和视频目录的代码包,可在github.com/PacktPublishing/找到。查看它们吧!
代码实战
本书的相关代码实战视频可在bit.ly/2FeZ5dQ查看。
下载彩色图片
我们还提供了一份包含书中使用的截图/图表的彩色图片 PDF 文件。您可以从这里下载:
static.packt-cdn.com/downloads/9781800203587_ColorImages.pdf
使用的约定
本书使用了多种文本约定。
文本中的代码: 表示文本中的代码单词、数据库表名、文件夹名、文件名、文件扩展名、路径名、虚拟 URL、用户输入和 Twitter 昵称。以下是一个示例:“Keras 在模型中提供了一个获取概率的方法,predict(),以及一个获取标签的方法,predict_classes()。”
代码块设置如下:
img_threshold = np.zeros_like(channel)
img_threshold [(channel >= 180)] = 255
当我们希望您注意代码块中的特定部分时,相关的行或项目将被设置为粗体:
[default]
exten => s,1,Dial(Zap/1|30)
exten => s,2,Voicemail(u100)
exten => s,102,Voicemail(b100)
exten => i,1,Voicemail(s0)
任何命令行输入或输出都应如下编写:
/opt/carla-simulator/
粗体: 表示新术语、重要单词或您在屏幕上看到的单词。例如,菜单或对话框中的单词在文本中显示如下。以下是一个示例:“参考轨迹是受控变量的期望轨迹;例如,车辆在车道中的横向位置。”
小贴士或重要注意事项
看起来像这样。
联系我们
我们欢迎读者的反馈。
一般反馈: 如果您对这本书的任何方面有疑问,请在邮件主题中提及书名,并将邮件发送至 customercare@packtpub.com。
勘误: 尽管我们已经尽最大努力确保内容的准确性,但错误仍然可能发生。如果您在这本书中发现了错误,如果您能向我们报告,我们将不胜感激。请访问 www.packtpub.com/support/errata,选择您的书籍,点击勘误提交表单链接,并输入详细信息。
盗版: 如果您在互联网上以任何形式发现我们作品的非法副本,如果您能提供位置地址或网站名称,我们将不胜感激。请通过版权@packtpub.com 与我们联系,并提供材料的链接。
如果您有兴趣成为作者: 如果您在某个领域有专业知识,并且您有兴趣撰写或为书籍做出贡献,请访问 authors.packtpub.com。
评论
请留下评论。一旦您阅读并使用了这本书,为何不在您购买它的网站上留下评论呢?潜在读者可以查看并使用您的客观意见来做出购买决定,Packt 公司可以了解您对我们产品的看法,我们的作者也可以看到他们对书籍的反馈。谢谢!
有关 Packt 的更多信息,请访问 packt.com。
第一部分:OpenCV、传感器和信号
本节将重点介绍使用 OpenCV 可以实现什么,以及它在自动驾驶汽车环境中的实用性。
本节包括以下章节:
-
第一章*,OpenCV 基础和相机标定*
-
第二章*,理解和处理信号*
-
第三章*,车道检测*
第一章:第一章:OpenCV 基础和相机标定
本章是关于 OpenCV 的介绍,以及如何在自动驾驶汽车管道的初期阶段使用它,以摄取视频流并为其下一阶段做准备。我们将从自动驾驶汽车的角度讨论摄像头的特性,以及如何提高我们从中获得的质量。我们还将研究如何操作视频,并尝试 OpenCV 最著名的功能之一,即目标检测,我们将用它来检测行人。
通过本章,您将建立如何使用 OpenCV 和 NumPy 的坚实基础,这在以后将非常有用。
在本章中,我们将涵盖以下主题:
-
OpenCV 和 NumPy 基础知识
-
读取、操作和保存图像
-
读取、操作和保存视频
-
操作图像
-
如何使用 HOG 检测行人
-
摄像头的特性
-
如何进行相机标定
技术要求
对于本章中的说明和代码,您需要以下内容:
-
Python 3.7
-
opencv-Python 模块
-
NumPy 模块
本章的代码可以在以下位置找到:
github.com/PacktPublishing/Hands-On-Vision-and-Behavior-for-Self-Driving-Cars/tree/master/Chapter1
本章的“代码在行动”视频可以在以下位置找到:
OpenCV 和 NumPy 简介
OpenCV 是一个计算机视觉和机器学习库,它已经发展了 20 多年,提供了令人印象深刻的众多功能。尽管 API 中存在一些不一致,但其简单性和实现的算法数量惊人,使其成为极其流行的库,并且在许多情况下都是最佳选择。
OpenCV 是用 C++编写的,但提供了 Python、Java 和 Android 的绑定。
在这本书中,我们将专注于 Python 的 OpenCV,所有代码都使用 OpenCV 4.2 进行测试。
Python 中的 OpenCV 由opencv-python提供,可以使用以下命令安装:
pip install opencv-python
OpenCV 可以利用硬件加速,但要获得最佳性能,您可能需要从源代码构建它,使用与默认值不同的标志,以针对您的目标硬件进行优化。
OpenCV 和 NumPy
Python 绑定使用 NumPy,这增加了灵活性,并使其与许多其他库兼容。由于 OpenCV 图像是 NumPy 数组,您可以使用正常的 NumPy 操作来获取有关图像的信息。对 NumPy 的良好理解可以提高性能并缩短您的代码长度。
让我们直接通过一些 NumPy 在 OpenCV 中的快速示例来深入了解。
图像大小
可以使用shape属性检索图像的大小:
print("Image size: ", image.shape)
对于 50x50 的灰度图像,image.shape()会返回元组(50, 50),而对于 RGB 图像,结果将是(50, 50, 3)。
拼音错误
在 NumPy 中,size属性是数组的字节数;对于一个 50x50 的灰度图像,它将是 2,500,而对于相同的 RGB 图像,它将是 7,500。shape属性包含图像的大小——分别是(50, 50)和(50, 50, 3)。
灰度图像
灰度图像由一个二维 NumPy 数组表示。第一个索引影响行(y坐标)和第二个索引影响列(x坐标)。y坐标的起点在图像的顶部角落,而x坐标的起点在图像的左上角。
使用np.zeros()可以创建一个黑色图像,它将所有像素初始化为 0:
black = np.zeros([100,100],dtype=np.uint8) # Creates a black image
之前的代码创建了一个大小为(100, 100)的灰度图像,由 10,000 个无符号字节组成(dtype=np.uint8)。
要创建一个像素值不为 0 的图像,你可以使用full()方法:
white = np.full([50, 50], 255, dtype=np.uint8)
要一次性改变所有像素的颜色,可以使用[:]表示法:
img[:] = 64 # Change the pixels color to dark gray
要只影响某些行,只需要在第一个索引中提供一个行范围:
img[10:20] = 192 # Paints 10 rows with light gray
之前的代码改变了第 10-20 行的颜色,包括第 10 行,但不包括第 20 行。
同样的机制也适用于列;你只需要在第二个索引中指定范围。要指示 NumPy 包含一个完整的索引,我们使用之前遇到的[:]表示法:
img[:, 10:20] = 64 # Paints 10 columns with dark gray
你也可以组合行和列的操作,选择一个矩形区域:
img[90:100, 90:100] = 0 # Paints a 10x10 area with black
当然,可以操作单个像素,就像在普通数组中做的那样:
img[50, 50] = 0 # Paints one pixel with black
使用 NumPy 选择图像的一部分,也称为感兴趣区域(ROI)是可能的。例如,以下代码从位置(90, 90)复制一个 10x10 的ROI到位置(80, 80):
roi = img[90:100, 90:100]
img[80:90, 80:90] = roi
以下为之前操作的结果:
图 1.1 – 使用 NumPy 切片对图像进行的一些操作
要复制一张图片,你可以简单地使用copy()方法:
image2 = image.copy()
RGB 图像
RGB 图像与灰度图像不同,因为它们是三维的,第三个索引代表三个通道。请注意,OpenCV 以 BGR 格式存储图像,而不是 RGB,所以通道 0 是蓝色,通道 1 是绿色,通道 2 是红色。
重要提示
OpenCV 将图像存储为 BGR,而不是 RGB。在本书的其余部分,当谈到 RGB 图像时,它仅意味着它是一个 24 位彩色图像,但内部表示通常是 BGR。
要创建一个 RGB 图像,我们需要提供三个尺寸:
rgb = np.zeros([100, 100, 3],dtype=np.uint8)
如果你打算用之前在灰度图像上运行的相同代码来运行新的 RGB 图像(跳过第三个索引),你会得到相同的结果。这是因为 NumPy 会将相同的颜色应用到所有三个通道上,这会导致灰色。
要选择一个颜色,只需要提供第三个索引:
rgb[:, :, 2] = 255 # Makes the image red
在 NumPy 中,也可以选择非连续的行、列或通道。您可以通过提供一个包含所需索引的元组来完成此操作。要将图像设置为洋红色,需要将蓝色和红色通道设置为255,这可以通过以下代码实现:
rgb[:, :, (0, 2)] = 255 # Makes the image magenta
您可以使用cvtColor()将 RGB 图像转换为灰度图像:
gray = cv2.cvtColor(original, cv2.COLOR_BGR2GRAY)
处理图像文件
OpenCV 提供了一个非常简单的方式来加载图像,使用imread():
import cv2
image = cv2.imread('test.jpg')
要显示图像,可以使用imshow(),它接受两个参数:
-
要写在显示图像的窗口标题上的名称
-
要显示的图像
不幸的是,它的行为不符合直觉,因为它不会显示图像,除非后面跟着对waitKey()的调用:
cv2.imshow("Image", image)cv2.waitKey(0)
在imshow()之后调用waitKey()将有两个效果:
-
它实际上允许 OpenCV 显示
imshow()提供的图像。 -
它将等待指定的毫秒数,或者如果经过的毫秒数
<=0,则等待直到按键。它将无限期等待。
可以使用imwrite()方法将图像保存到磁盘上,该方法接受三个参数:
-
文件名
-
该图像
-
一个可选的格式相关参数:
cv2.imwrite("out.jpg", image)
有时,将多张图片并排放置非常有用。本书中的一些示例将广泛使用此功能来比较图像。
OpenCV 为此提供了两种方法:hconcat()用于水平拼接图片,vconcat()用于垂直拼接图片,两者都接受一个图像列表作为参数。以下是一个示例:
black = np.zeros([50, 50], dtype=np.uint8)white = np.full([50, 50], 255, dtype=np.uint8)cv2.imwrite("horizontal.jpg", cv2.hconcat([white, black]))cv2.imwrite("vertical.jpg", cv2.vconcat([white, black]))
这里是结果:
图 1.2 – 使用 hconcat()进行水平拼接和 vconcat()进行垂直拼接
我们可以使用这两个方法来创建棋盘图案:
row1 = cv2.hconcat([white, black])row2 = cv2.hconcat([black, white])cv2.imwrite("chess.jpg", cv2.vconcat([row1, row2]))
您将看到以下棋盘图案:
图 1.3 – 使用 hconcat()结合 vconcat()创建的棋盘图案
在处理完图像后,我们就可以开始处理视频了。
处理视频文件
在 OpenCV 中使用视频非常简单;实际上,每一帧都是一个图像,可以使用我们已分析的方法进行操作。
要在 OpenCV 中打开视频,需要调用VideoCapture()方法:
cap = cv2.VideoCapture("video.mp4")
之后,您可以通过调用read()(通常在一个循环中),来检索单个帧。该方法返回一个包含两个值的元组:
-
当视频结束时为 false 的布尔值
-
下一帧:
ret, frame = cap.read()
要保存视频,有VideoWriter对象;其构造函数接受四个参数:
-
文件名
-
视频编码的四字符代码(FOURCC)
-
每秒帧数
-
分辨率
以下是一个示例:
mp4 = cv2.VideoWriter_fourcc(*'MP4V')writer = cv2.VideoWriter('video-out.mp4', mp4, 15, (640, 480))
一旦创建了VideoWriter对象,就可以使用write()方法将一帧添加到视频文件中:
writer.write(image)
当你完成使用 VideoCapture 和 VideoWriter 对象后,你应该调用它们的释放方法:
cap.release()
writer.release()
使用网络摄像头
在 OpenCV 中,网络摄像头被处理得类似于视频;你只需要为 VideoCapture 提供一个不同的参数,即表示网络摄像头的 0 基索引:
cap = cv2.VideoCapture(0)
之前的代码打开了第一个网络摄像头;如果你需要使用不同的一个,你可以指定一个不同的索引。
现在,让我们尝试操作一些图像。
操作图像
作为自动驾驶汽车计算机视觉管道的一部分,无论是否使用深度学习,你可能需要处理视频流,以便其他算法作为预处理步骤更好地工作。
本节将为你提供一个坚实的基础,以预处理任何视频流。
翻转图像
OpenCV 提供了 flip() 方法来翻转图像,它接受两个参数:
-
图像
-
一个可以是 1(水平翻转)、0(垂直翻转)或 -1(水平和垂直翻转)的数字
让我们看看一个示例代码:
flipH = cv2.flip(img, 1)flipV = cv2.flip(img, 0)flip = cv2.flip(img, -1)
这将产生以下结果:
图 1.4 – 原始图像,水平翻转,垂直翻转,以及两者都翻转
正如你所见,第一幅图像是我们的原始图像,它被水平翻转和垂直翻转,然后两者同时翻转。
模糊图像
有时,图像可能太嘈杂,可能是因为你执行的一些处理步骤。OpenCV 提供了多种模糊图像的方法,这有助于这些情况。你很可能不仅要考虑模糊的质量,还要考虑执行的速率。
最简单的方法是 blur(),它对图像应用低通滤波器,并且至少需要两个参数:
-
图像
-
核心大小(更大的核心意味着更多的模糊):
blurred = cv2.blur(image, (15, 15))
另一个选项是使用 GaussianBlur(),它提供了更多的控制,并且至少需要三个参数:
-
图像
-
核心大小
-
sigmaX,它是 X 轴上的标准差
建议指定 sigmaX 和 sigmaY(Y 轴上的标准差,第四个参数):
gaussian = cv2.GaussianBlur(image, (15, 15), sigmaX=15, sigmaY=15)
一个有趣的模糊方法是 medianBlur(),它计算中值,因此具有只发出图像中存在的颜色像素(这不一定发生在前一种方法中)的特征。它有效地减少了“盐和胡椒”噪声,并且有两个强制参数:
-
图像
-
核心大小(一个大于 1 的奇数整数):
median = cv2.medianBlur(image, 15)
此外,还有一个更复杂的过滤器 bilateralFilter(),它在去除噪声的同时保持边缘清晰。这是最慢的过滤器,并且至少需要四个参数:
-
图像
-
每个像素邻域的直径
-
sigmaColor:在颜色空间中过滤 sigma,影响像素邻域内不同颜色混合的程度 -
sigmaSpace:在坐标空间中过滤 sigma,影响颜色比sigmaColor更接近的像素如何相互影响:
bilateral = cv2.bilateralFilter(image, 15, 50, 50)
选择最佳过滤器可能需要一些实验。你可能还需要考虑速度。以下是基于我的测试结果和一些基于参数的性能依赖性的大致估计,请注意:
-
blur()是最快的。 -
GaussianBlur()类似,但它可能比 blur() 慢 2 倍。 -
medianBlur()可能会比blur()慢 20 倍。 -
BilateralFilter()是最慢的,可能比blur()慢 45 倍。
下面是结果图像:
图 1.5 – 原图、blur()、GaussianBlur()、medianBlur() 和 BilateralFilter(),以及代码示例中使用的参数
改变对比度、亮度和伽玛
一个非常有用的函数是 convertScaleAbs(),它会对数组的所有值执行多个操作:
-
它们乘以缩放参数,
alpha。 -
它们加上增量参数,
beta。 -
如果结果是 255 以上,则将其设置为 255。
-
结果被转换为无符号 8 位整型。
该函数接受四个参数:
-
源图像
-
目标(可选)
-
用于缩放的
alpha参数 -
beta增量参数
convertScaleAbs() 可以用来影响对比度,因为大于 1 的 alpha 缩放因子会增加对比度(放大像素之间的颜色差异),而小于 1 的缩放因子会减少对比度(减少像素之间的颜色差异):
cv2.convertScaleAbs(image, more_contrast, 2, 0)cv2.convertScaleAbs(image, less_contrast, 0.5, 0)
它也可以用来影响亮度,因为 beta 增量因子可以用来增加所有像素的值(增加亮度)或减少它们(减少亮度):
cv2.convertScaleAbs(image, more_brightness, 1, 64)
cv2.convertScaleAbs(image, less_brightness, 1, -64)
让我们看看结果图像:
图 1.6 – 原图、更高对比度(2x)、更低对比度(0.5x)、更高亮度(+64)和更低亮度(-64)
改变亮度的一种更复杂的方法是应用伽玛校正。这可以通过使用 NumPy 进行简单计算来完成。伽玛值大于 1 会增加亮度,而伽玛值小于 1 会减少亮度:
Gamma = 1.5
g_1_5 = np.array(255 * (image / 255) ** (1 / Gamma), dtype='uint8')
Gamma = 0.7
g_0_7 = np.array(255 * (image / 255) ** (1 / Gamma), dtype='uint8')
将产生以下图像:
图 1.7 – 原图、更高伽玛(1.5)和更低伽玛(0.7)
你可以在中间和右边的图像中看到不同伽玛值的效果。
绘制矩形和文本
在处理目标检测任务时,突出显示一个区域以查看检测到的内容是一个常见需求。OpenCV 提供了 rectangle() 函数,它至少接受以下参数:
-
图像
-
矩形的左上角
-
矩形的右下角
-
应用的颜色
-
(可选)线条粗细:
cv2.rectangle(image, (x, y), (x + w, y + h), (255, 255, 255), 2)
要在图像中写入一些文本,你可以使用putText()方法,至少需要接受六个参数:
-
图像
-
要打印的文本
-
左下角的坐标
-
字体样式
-
缩放因子,用于改变大小
-
颜色:
cv2.putText(image, 'Text', (x, y), cv2.FONT_HERSHEY_PLAIN, 2, clr)
使用 HOG 进行行人检测
方向梯度直方图(HOG)是 OpenCV 实现的一种目标检测技术。在简单情况下,它可以用来判断图像中是否存在某个特定对象,它在哪里,有多大。
OpenCV 包含一个针对行人训练的检测器,你将使用它。它可能不足以应对现实生活中的情况,但学习如何使用它是很有用的。你也可以用更多图像训练另一个检测器,看看它的表现是否更好。在本书的后面部分,你将看到如何使用深度学习来检测不仅行人,还有汽车和交通灯。
滑动窗口
OpenCV 中的 HOG 行人检测器使用的是 48x96 像素的模型,因此它无法检测比这更小的对象(或者,更好的说法是,它可以,但检测框将是 48x96)。
HOG 检测器的核心有一个机制,可以判断给定的 48x96 像素图像是否为行人。由于这并不特别有用,OpenCV 实现了一个滑动窗口机制,其中检测器被多次应用于略微不同的位置;考虑的“图像窗口”稍微滑动一下。一旦分析完整个图像,图像窗口就会增加大小(缩放),然后再次应用检测器,以便能够检测更大的对象。因此,检测器对每个图像应用数百次甚至数千次,这可能会很慢。
使用 OpenCV 的 HOG
首先,你需要初始化检测器并指定你想要使用该检测器进行行人检测:
hog = cv2.HOGDescriptor()det = cv2.HOGDescriptor_getDefaultPeopleDetector()
hog.setSVMDetector(det)
然后,只需调用detectMultiScale()函数:
(boxes, weights) = hog.detectMultiScale(image, winStride=(1, 1), padding=(0, 0), scale=1.05)
我们使用的参数需要一些解释,如下所示:
-
图像
-
winStride,窗口步长,指定每次滑动窗口移动的距离 -
填充,可以在图像边界的周围添加一些填充像素(对于检测靠近边界的行人很有用)
-
缩放,指定每次增加窗口图像的大小
你应该考虑winSize可以提升准确性(因为考虑了更多位置),但它对性能有较大影响。例如,步长为(4,4)可以比步长为(1,1)快 16 倍,尽管在实际应用中,性能差异要小一些,可能只有 10 倍。
通常,减小缩放可以提高精度并降低性能,尽管影响并不显著。
提高精度意味着检测到更多行人,但这也可能增加误报。detectMultiScale()有几个高级参数可以用于此:
-
hitThreshold,它改变了从支持向量机(SVM)平面所需距离。阈值越高,意味着检测器对结果越有信心。 -
finalThreshold,它与同一区域内的检测数量相关。
调整这些参数需要一些实验,但一般来说,较高的hitThreshold值(通常在 0–1.0 的范围内)应该会减少误报。
较高的finalThreshold值(例如 10)也会减少误报。
我们将在由 Carla 生成的行人图像上使用detectMultiScale()。
图 1.8 – HOG 检测,winStride=(1, 2),scale=1.05,padding=(0, 0) 左:hitThreshold = 0,finalThreshold = 1;中:hitThreshold = 0,inalThreshold = 3;右:hitThreshold = 0.2,finalThreshold = 1
如你所见,我们在图像中检测到了行人。使用较低的 hit 阈值和 final 阈值可能导致误报,如左图所示。你的目标是找到正确的平衡点,检测行人,同时避免有太多的误报。
相机简介
相机可能是我们现代世界中最普遍的传感器之一。它们在我们的手机、笔记本电脑、监控系统以及当然,摄影中都被广泛应用。它们提供了丰富的、高分辨率的图像,包含关于环境的广泛信息,包括空间、颜色和时间信息。
没有什么奇怪的,它们在自动驾驶技术中被广泛使用。相机之所以如此受欢迎,其中一个原因就是它反映了人眼的功能。正因为如此,我们非常习惯于使用它们,因为我们与它们的功能、局限性和优点在深层次上建立了联系。
在本节中,你将学习以下内容:
-
相机术语
-
相机的组成部分
-
优缺点
-
选择适合自动驾驶的相机
让我们逐一详细讨论。
相机术语
在学习相机的组成部分及其优缺点之前,你需要了解一些基本术语。这些术语在评估和最终选择你的自动驾驶应用中的相机时将非常重要。
视场(FoV)
这是环境(场景)中传感器可见的垂直和水平角部分。在自动驾驶汽车中,你通常希望平衡视场与传感器的分辨率,以确保我们尽可能多地看到环境,同时使用最少的相机。视场存在一个权衡空间。较大的视场通常意味着更多的镜头畸变,你需要在相机校准中进行补偿(参见相机校准部分):
图 1.9 – 视场,来源:www.researchgate.net/figure/Illustration-of-camera-lenss-field-of-view-FOV_fig4_335011596
分辨率
这是传感器在水平和垂直方向上的像素总数。这个参数通常使用百万像素(MP)这个术语来讨论。例如,一个 5 MP 的相机,如 FLIR Blackfly,其传感器有 2448 × 2048 像素,相当于 5,013,504 像素。
更高的分辨率允许你使用具有更宽视场角(FoV)的镜头,同时仍然提供运行你的计算机视觉算法所需的细节。这意味着你可以使用更少的相机来覆盖环境,从而降低成本。
Blackfly,以其各种不同的版本,由于成本、小型化、可靠性、鲁棒性和易于集成,是自动驾驶汽车中常用的相机:
图 1.10 – 像素分辨率
焦距
这是从镜头光学中心到传感器的长度。焦距最好理解为相机的变焦。较长的焦距意味着你将更靠近环境中的物体进行放大。在你的自动驾驶汽车中,你可能需要根据你在环境中的需求选择不同的焦距。例如,你可能选择一个相对较长的 100 毫米焦距,以确保你的分类器算法能够检测到足够远的交通信号,以便汽车能够平稳、安全地停车:
图 1.11 – 焦距,来源:photographylife.com/what-is-focal-length-in-photography
光圈和光圈值
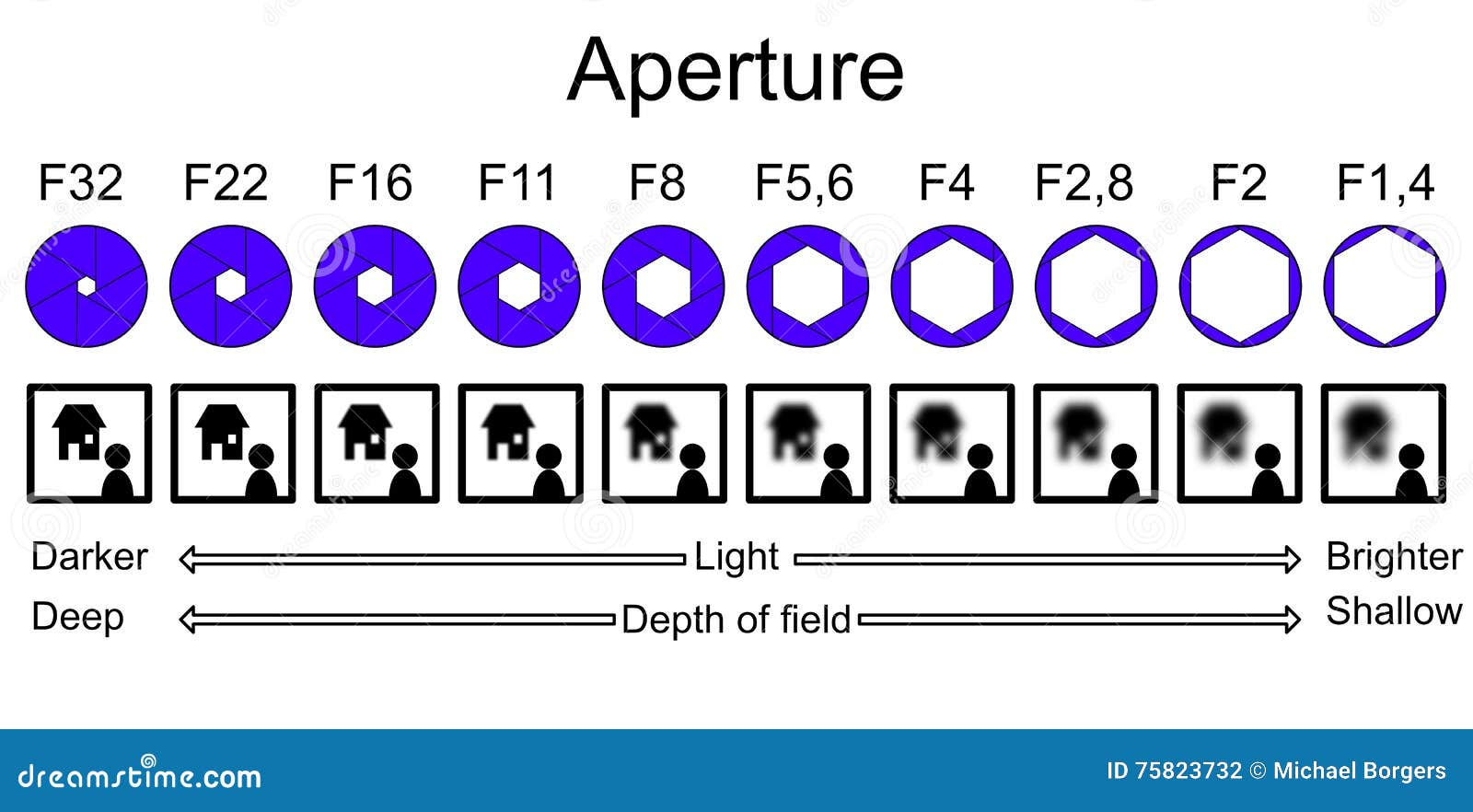
这是光线通过以照亮传感器的开口。通常用来描述开口大小的单位是光圈,它指的是焦距与开口大小的比率。例如,一个焦距为 50 毫米、光圈直径为 35 毫米的镜头将等于 f/1.4 的光圈。以下图示展示了不同光圈直径及其在 50 毫米焦距镜头上的光圈值。光圈大小对你的自动驾驶汽车非常重要,因为它与景深(DoF)直接相关。大光圈还允许相机对镜头上的遮挡物(例如,虫子)具有容忍性:更大的光圈允许光线绕过虫子并仍然到达传感器:
图 1.12 – 光圈,来源:en.wikipedia.org/wiki/Aperture#/media/File:Lenses_with_different_apertures.jpg
景深(DoF)
这是环境中将要聚焦的距离范围。这直接关联到光圈的大小。通常情况下,在自动驾驶汽车中,你希望有较深的景深,以便你的计算机视觉算法能够聚焦视野中的所有物体。问题是,深景深是通过小光圈实现的,这意味着传感器接收到的光线较少。因此,你需要平衡景深、动态范围和 ISO,以确保你能看到环境中所需看到的一切。
以下图示展示了景深与光圈之间的关系:
图 1.13 – 景深与光圈对比,来源:thumbs.dreamstime.com/z/aperture-infographic-explaining-depth-field-corresponding-values-their-effect-blur-light-75823732.jpg
动态范围
这是传感器的一个属性,表示其对比度或它能解析的最亮与最暗主题之间的比率。这可能会用 dB(例如,78 dB)或对比度(例如,2,000,000/1)来表示。
自动驾驶汽车需要在白天和夜晚运行。这意味着传感器需要在黑暗条件下提供有用的细节,同时不会在明亮阳光下过度饱和。高动态范围(HDR)的另一个原因是当太阳在地平线较低时驾驶的情况。我相信你在早上开车上班时一定有过这样的经历,太阳正对着你的脸,你几乎看不到前面的环境,因为它已经让你的眼睛饱和了。HDR 意味着即使在直射阳光下,传感器也能看到环境。以下图示说明了这些条件:
图 1.14 – HDR 示例,来源:petapixel.com/2011/05/02/use-iso-numbers-that-are-multiples-of-160-when-shooting-dslr-video/
你的梦想动态范围
如果你可以许愿,并且在你的传感器中拥有你想要的任何动态范围,那会是什么?
国际标准化组织(ISO)灵敏度
这是像素对入射光子的敏感度。
等一下,你说,你的缩写搞混了吗?看起来是这样,但国际标准化组织决定连它们的缩写也要标准化,因为否则每种语言都会不同。谢谢,ISO!
标准化的 ISO 值可以从 100 到超过 10,000。较低的 ISO 值对应于传感器较低的灵敏度。现在你可能要问,“为什么我不想要最高的灵敏度?”好吧,灵敏度是有代价的……噪声。ISO 值越高,你会在图像中看到更多的噪声。这种额外的噪声可能会在尝试对物体进行分类时给你的计算机视觉算法带来麻烦。在下面的图中,你可以看到较高 ISO 值对图像噪声的影响。这些图像都是在镜头盖盖上(完全黑暗)的情况下拍摄的。随着 ISO 值的增加,随机噪声开始渗入:
图 1.15 – 暗室中的 ISO 值示例和噪声
帧率(FPS)
这是传感器获取连续图像的速率,通常以 Hz 或每秒帧数(FPS)表示。一般来说,你希望有最快的帧率,这样快速移动的物体在你的场景中就不会模糊。这里的主要权衡是延迟:从真实事件发生到你的计算机视觉算法检测到它的时间。必须处理的帧率越高,延迟就越高。在下面的图中,你可以看到帧率对运动模糊的影响。
模糊并不是选择更高帧率的唯一原因。根据你的车辆速度,你需要一个帧率,以便车辆能够在物体突然出现在其视场(FoV)中时做出反应。如果你的帧率太慢,当车辆看到某物时,可能已经太晚做出反应了:
图 1.16 – 120 Hz 与 60 Hz 帧率对比,来源:gadgetstouse.com/blog/2020/03/18/difference-between-60hz-90hz-120hz-displays/
镜头眩光
这些是来自物体的光线在传感器上产生的伪影,这些伪影与物体在环境中的位置不相关。你可能在夜间驾驶时遇到过这种情况,当时你会看到迎面而来的车灯。那种星光效果是由于你的眼睛(或相机)的镜头中散射的光线,由于不完美,导致一些光子撞击了“像素”,而这些像素与光子来自的地方不相关——也就是说,是车灯。以下图示显示了这种效果。你可以看到星光效果使得实际物体,即汽车,非常难以看清!
图 1.17 – 迎面车灯产生的镜头眩光,来源:s.blogcdn.com/cars.aol.co.uk/media/2011/02/headlights-450-a-g.jpg
镜头畸变
这是直线或真实场景与你的相机图像所看到场景之间的区别。如果你曾经看过动作相机的视频,你可能已经注意到了“鱼眼”镜头效果。以下图示显示了广角镜头的极端畸变示例。你将学会如何使用 OpenCV 来纠正这种畸变:
图 1.18 – 镜头畸变,来源:www.slacker.xyz/post/what-lens-should-i-get
相机的组成部分
就像眼睛一样,相机由光敏感阵列、光圈和镜头组成。
光敏感阵列 – CMOS 传感器(相机的视网膜)
在大多数消费级相机中,光敏感阵列被称为 CMOS 有源像素传感器(或简称传感器)。其基本功能是将入射光子转换为电信号,该信号可以根据光子的颜色波长进行数字化。
光圈(相机的光圈)
相机的光圈或瞳孔是光线通往传感器的通道。这可以是可变的或固定的,具体取决于你使用的相机类型。光圈用于控制诸如景深和到达传感器的光线量等参数。
镜头(相机的镜头)
镜头或光学元件是相机将环境中的光线聚焦到传感器上的组成部分。镜头主要通过其焦距决定相机的视场角(FoV)。在自动驾驶应用中,视场角非常重要,因为它决定了汽车单次使用一个摄像头可以看到多少环境。相机的光学元件通常是成本最高的部分之一,并对图像质量和镜头眩光有重大影响。
选择相机的考虑因素
现在你已经了解了摄像头的基本知识和相关术语,是时候学习如何为自动驾驶应用选择摄像头了。以下是在选择摄像头时你需要权衡的主要因素列表:
-
分辨率
-
视场角(FoV)
-
动态范围
-
成本
-
尺寸
-
防护等级(IP 等级)
完美的摄像头
如果你能设计出理想的摄像头,那会是什么样子?
我理想的自动驾驶摄像头将能够从所有方向(球形视场角,360º HFoV x 360º VFoV)看到。它将具有无限的分辨率和动态范围,因此你可以在任何距离和任何光照条件下以数字方式解析物体。它的大小将和一粒米一样,完全防水防尘,并且只需 5 美元!显然,这是不可能的。因此,我们必须对我们所需的东西做出一些谨慎的权衡。
从你的摄像头预算开始是最好的起点。这将给你一个关于要寻找哪些型号和规格的想法。
接下来,考虑你的应用需要看到什么:
-
当你以 100 km/h 的速度行驶时,你是否需要从 200 米外看到孩子?
-
你需要覆盖车辆周围多大的范围,你能否容忍车辆侧面的盲点?
-
你需要在夜间和白天都能看到吗?
最后,考虑你有多少空间来集成这些摄像头。你可能不希望你的车辆看起来像这样:
图 1.19 – 摄像头艺术,来源:www.flickr.com/photos/laughingsquid/1645856255/
这可能非常令人不知所措,但在思考如何设计你的计算机视觉系统时,这一点非常重要。一个很好的起点是 FLIR Blackfly S 系列,它非常受欢迎,在分辨率、帧率(FPS)和成本之间取得了极佳的平衡。接下来,搭配一个满足你视场角(FoV)需求的镜头。互联网上有一些有用的视场角计算器,例如来自www.bobatkins.com/photography/technical/field_of_view.html的计算器。
摄像头的优缺点
现在,没有任何传感器是完美的,即使是你的心头好摄像头也会有它的优点和缺点。让我们现在就来看看它们。
让我们先看看它的优势:
-
高分辨率:与其他传感器类型(如雷达、激光雷达和声纳)相比,摄像头在场景中识别物体时具有出色的分辨率。你很容易就能以相当低的价格找到具有 500 万像素分辨率的摄像头。
-
纹理、颜色和对比度信息:摄像头提供了其他传感器类型无法比拟的关于环境的丰富信息。这是因为摄像头能够感知多种波长的光。
-
成本:摄像头是你能找到的性价比最高的传感器之一,尤其是考虑到它们提供的数据质量。
-
尺寸:CMOS 技术和现代 ASIC 技术使得相机变得非常小,许多小于 30 立方毫米。
-
范围:这主要归功于高分辨率和传感器的被动性质。
接下来,这里有一些弱点:
-
大量数据处理用于物体检测:随着分辨率的提高,数据量也随之增加。这就是我们为了如此精确和详细的图像所付出的代价。
-
被动:相机需要一个外部照明源,如太阳、车头灯等。
-
遮蔽物(如昆虫、雨滴、浓雾、灰尘或雪):相机在穿透大雨、雾、灰尘或雪方面并不特别擅长。雷达通常更适合这项任务。
-
缺乏原生深度/速度信息:仅凭相机图像本身无法提供关于物体速度或距离的任何信息。
测绘学正在帮助弥补这一弱点,但代价是宝贵的处理资源(GPU、CPU、延迟等)。它也比雷达或激光雷达传感器产生的信息准确性低。
现在您已经很好地理解了相机的工作原理,以及其基本部分和术语,是时候动手使用 OpenCV 校准相机了。
使用 OpenCV 进行相机校准
在本节中,您将学习如何使用已知模式的物体,并使用 OpenCV 来纠正镜头扭曲。
记得我们在上一节中提到的镜头扭曲吗?您需要纠正这一点,以确保您能够准确地定位物体相对于车辆的位置。如果您不知道物体是在您前面还是旁边,那么看到物体对您没有任何好处。即使是好的镜头也可能扭曲图像,这尤其适用于广角镜头。幸运的是,OpenCV 提供了一个检测这种扭曲并纠正它的机制!
策略是拍摄棋盘的图片,这样 OpenCV 就可以使用这种高对比度图案来检测点的位置,并根据预期图像与记录图像之间的差异来计算扭曲。
您需要提供几张不同方向的图片。可能需要一些实验来找到一组好的图片,但 10 到 20 张图片应该足够了。如果您使用的是打印的棋盘,请确保纸张尽可能平整,以免影响测量:
图 1.20 – 一些可用于校准的图片示例
如您所见,中心图像清楚地显示了某些桶形扭曲。
扭曲检测
OpenCV 试图将一系列三维点映射到相机的二维坐标。然后,OpenCV 将使用这些信息来纠正扭曲。
首件事是初始化一些结构:
image_points = [] # 2D points object_points = [] # 3D points coords = np.zeros((1, nX * nY, 3), np.float32)coords[0,:,:2] = np.mgrid[0:nY, 0:nX].T.reshape(-1, 2)
请注意nX和nY,它们分别是x和y轴上棋盘上要找到的点数。在实践中,这是方格数减 1。
然后,我们需要调用findChessboardCorners():
found, corners = cv2.findChessboardCorners(image, (nY, nX), None)
如果 OpenCV 找到了点,则found为真,corners将包含找到的点。
在我们的代码中,我们将假设图像已经被转换为灰度图,但您也可以使用 RGB 图片进行校准。
OpenCV 提供了一个很好的图像,展示了找到的角点,确保算法正在正常工作:
out = cv2.drawChessboardCorners(image, (nY, nX), corners, True)object_points.append(coords) # Save 3d points image_points.append(corners) # Save corresponding 2d points
让我们看看结果图像:
图 1.21 – OpenCV 找到的校准图像的角点
校准
在几幅图像中找到角点后,我们最终可以使用calibrateCamera()生成校准数据。
ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(object_points, image_points, shape[::-1], None, None)
现在,我们准备使用undistort()校正我们的图像:
dst = cv2.undistort(image, mtx, dist, None, mtx)
让我们看看结果:
图 1.22 – 原始图像和校准图像
我们可以看到,第二张图像的桶形畸变较少,但并不理想。我们可能需要更多和更好的校准样本。
但我们也可以通过在findChessboardCorners()之后寻找cornerSubPix()来尝试从相同的校准图像中获得更高的精度:
corners = cv2.cornerSubPix(image, corners, (11, 11), (-1, -1), (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001))
以下是为结果图像:
图 1.23 – 使用亚像素精度校准的图像
由于完整的代码有点长,我建议您在 GitHub 上查看完整的源代码。
摘要
嗯,你在通往制作真正自动驾驶汽车的计算机视觉之旅中已经取得了很好的开端。
你了解了一个非常有用的工具集,称为 OpenCV,它为 Python 和 NumPy 提供了绑定。有了这些工具,你现在可以使用imread()、imshow()、hconcat()和vconcat()等方法创建和导入图像。你学会了如何导入和创建视频文件,以及使用VideoCapture()和VideoWriter()方法从摄像头捕获视频。小心,斯皮尔伯格,镇上来了一个新的电影制作人!
能够导入图像是件好事,但如何开始操作它们以帮助你的计算机视觉算法学习哪些特征很重要呢?你通过flip()、blur()、GaussianBlur()、medianBlur()、bilateralFilter()和convertScaleAbs()等方法学会了如何这样做。然后,你学会了如何使用rectangle()和putText()等方法为人类消费标注图像。
然后,真正的魔法出现了,你学会了如何使用 HOG 检测行人来处理图像并完成你的第一个真正的计算机视觉项目。你学会了如何使用detectMultiScale()方法在图像上以不同大小的窗口滑动窗口来扫描检测器,使用参数如winStride、padding、scale、hitThreshold和finalThreshold。
你在使用图像处理的新工具时玩得很开心。但似乎还缺少了什么。我该如何将这些图像应用到我的自动驾驶汽车上?为了回答这个问题,你学习了关于相机及其基本术语,例如分辨率、视场角、焦距、光圈、景深、动态范围、ISO、帧率、镜头眩光,以及最后的镜头畸变。然后,你学习了组成相机的基本组件,即镜头、光圈和光敏阵列。有了这些基础知识,你继续学习如何根据相机的优缺点来选择适合你应用的相机。
带着这些知识,你勇敢地开始使用在 OpenCV 中学习的畸变校正工具来消除这些弱点之一,即镜头畸变。你使用了findChessboardCorners()、calibrateCamera()、undistort()和cornerSubPix()等方法来完成这项工作。
哇,你真的在朝着能够在自动驾驶应用中感知世界的方向前进。你应该花点时间为自己到目前为止所学到的感到自豪。也许你可以通过自拍来庆祝,并应用一些你所学的知识!
在下一章中,你将学习一些基本信号类型和协议,这些类型和协议在你尝试将传感器集成到自动驾驶应用中时可能会遇到。
问题
-
OpenCV 能否利用硬件加速?
-
如果 CPU 性能不是问题,最好的模糊方法是什么?
-
哪个检测器可以用来在图像中找到行人?
-
你该如何从网络摄像头中读取视频流?
-
光圈和景深之间的权衡是什么?
-
在什么情况下你需要高 ISO?
-
为相机校准计算亚像素精度值得吗?
第二章:第二章:理解和处理信号
本章,你将了解你可能在集成你为项目选择的各种传感器时遇到的不同信号类型。你还将了解各种信号架构,本章将帮助你选择最适合你应用的一个。每个都有其陷阱、协议和规定。
本章我们将涵盖以下主题:
-
信号类型
-
模拟与数字
-
串行数据
-
CAN
-
UDP
-
TCP
到本章结束时,你将能够应用你对每个协议的理解。你将能够手动解码各种协议的串行数据以帮助调试信号。最重要的是,你将拥有应用开源工具为你做繁重工作的知识。
技术要求
要执行本章中的指令,你需要以下条件:
-
基本电气电路知识(关于电压、电流和电阻)
-
二进制、十六进制和 ASCII 编程知识
-
使用示波器探测传感器信号的经验
本章的代码可以在以下位置找到:
github.com/PacktPublishing/Hands-On-Vision-and-Behavior-for-Self-Driving-Cars/tree/master/Chapter2
本章的“代码实战”视频可以在以下位置找到:
理解信号类型
当你集成自动驾驶汽车的传感器、执行器和控制器时,你会遇到许多不同的信号类型。你需要了解每种类型的优缺点,以帮助你选择正确的设备进行集成。接下来的几节将涵盖每种信号类型的所有细节,并为你提供做出正确选择的知识。
这里是你在机器人和自动驾驶汽车中会遇到的基本信号类型:
-
串行
-
并行
-
模拟
-
数字
-
单端
-
差分
在下一节中,你将学习模拟信号和数字信号之间的区别。
模拟与数字
首先要记住的是,我们生活在一个模拟的世界。没有什么是一瞬间发生的,一切都是连续的。这也是我们无法瞬间移动的原因,遗憾的是!
同样,模拟信号是连续且不断变化的;它们不会瞬间跳跃,而是平滑地从一种状态过渡到另一种状态。一个典型的模拟信号例子是古老的调幅(AM)收音机。你可以在下面的图中看到,平滑的数据信号是如何调制到平滑的载波上以创建平滑的 AM 信号。在这里,音调由振幅变化的快慢表示,音量由振幅的大小表示:
图 2.1 – 模拟信号示例
相比之下,数字信号是在已知的时间点采样的。当信号被采样时,它会检查是否高于或低于某个阈值,这将决定它是逻辑0还是1。你可以在下面的图中看到这个例子:
图 2.2 – 数字信号示例
模拟隐藏在数字中
尽管我们谈论数字是从一种状态跳到另一种状态,但实际上并不是。它只是非常快速地变化,但以模拟的方式。我们只是选择在脉冲中间采样它。世界总是模拟的,但有时我们以数字的方式解释它。
如果你仔细观察下面的图,你会看到隐藏在角落中的模拟特性!
图 2.3 – 数字信号示波器 – 信号运行前后
你看到了吗?尽管这应该是电压之间的尖锐过渡,但你可以看到本应是方形角落的圆润。这是因为自然界中没有什么是瞬间的,一切都是从一种状态平滑过渡到另一种状态。
在下一节中,你将学习串行和并行数据传输之间的区别。
串行与并行
串行数据可能是最普遍的数据传输类型。这是我们人类习惯于沟通的方式。你现在就在这样做,当你阅读这段文字时。串行通信简单来说就是数据一次传输和接收一个单元(与并行传输多个数据单元相对)。
在阅读这本书的情况下,你的眼睛通过从左到右扫描每一行文本来逐字处理,然后回到下一行的开头并继续。你正在处理一个用于传达某些思想和观点的单词序列流。相反,想象一下如果你一次能读几行。这将被认为是并行数据传输,那将是非常棒的!
计算机中使用的单位是位,它是对开或关的二进制表示,更常见的是 1 或 0。
并行数据传输在计算机的早期年份很受欢迎,因为它允许通过多个(通常是 8 个)电线同时传输位,这大大提高了数据传输速度。这种速度是以几个代价为代价的。更多的电线意味着更多的重量、成本和噪音。由于这些多根电线通常相邻,你会在相邻的电线中产生大量的噪声,这被称为串扰。这种噪声导致传输距离缩短。以下图示了 8 位是串行传输还是并行传输:
图 2.4 – 串行与并行
现在,你可以看到每根线都专门用于每个位。在早期计算中,当发送 8 位时,这没问题,但你可以想象,当考虑 32 位和 64 位数据时,这会变得多么难以管理。幸运的是,随着协议速度的提高,很明显串行传输要便宜得多,也更容易集成。这并不是说并行数据传输不存在;它确实存在于速度至关重要的应用中。
有几种类型的串行数据协议,如 UART、I2C、SPI、以太网和 CAN。在接下来的几节中,你将了解它们的介绍。
通用异步接收和发送(UART)
UART 是一个非常常见的协议,得益于其简单性和成本效益。许多低数据速率的应用程序会使用它来传输和接收数据。在自动驾驶应用中,你将看到 UART 的一个常见应用是时间同步到 GPS。一个包含所有位置和时间信息的 GPS 接收器消息将被发送到激光雷达、摄像头、雷达或其他传感器,以将它们同步到协调世界时(UTC)。
抱歉,我想你的缩写搞混了。
法国人英语人无法就缩写达成一致,所以与其在英语中使用 CUT 或法语中使用TUC(Temps Universel Coordonné),他们决定两者都混用,以不偏袒任何一种语言。如果我不能按照我的方式来,你也不能!就这样,UTC 诞生了!
好吧,那么 UART 看起来是什么样子?首先你需要理解的是,该协议是异步的,这意味着不需要时钟信号(线)。相反,两个设备各自必须拥有相当好的内部时钟来为自己计时。对,所以不需要时钟线;但你需要什么线?你只需要两根线:一根用于传输,一根用于接收。因此,在开始游戏之前,两个设备需要就一些基本规则达成一致:
-
波特率:这设置了设备之间每秒交换的位数。换句话说,它是位计数的时间长度。常见的波特率有 9,600、19,200、38,400、57,600、115,200、128,000 和 256,000。
-
数据位:这设置了数据帧中用于有效载荷(数据)的位数。
-
奇偶校验位:这决定了数据包中是否会有奇偶校验位。这可以用来验证接收到的消息的完整性。这是通过计算数据帧中 1 的数量来完成的,如果 1 的数量是偶数,则将奇偶校验位设置为 0,如果是奇数,则设置为 1。
-
停止位:这设置了表示数据包结束的停止位数。
-
流量控制:这设置了你是否会使用硬件流量控制。这并不常见,因为它需要额外的两根线用于准备发送(RTS)和清除发送(CTS)。
很好,我们已经有了基本规则。现在让我们看看数据包的样子,然后再解码一个。
以下图示说明了 UART 消息数据包的结构。你可以看到我们从一个精确的起始比特(低电平)开始,然后是 5 到 9 个数据比特,如果规则中有奇偶校验位,则跟随奇偶校验位,最后是停止比特(1 到 2 个,高电平)。空闲状态通常是高电压状态,表示一个 1,而活动状态通常是低电平,表示一个 0。这是一个正常极性。如果需要,你可以反转极性,只要事先设定好规则:
图 2.5 – UART 数据包结构
以下是一个示例信号波形,展示了如何使用八个数据比特、无奇偶校验和一个停止比特来解码比特。我们从空闲(高电平)状态开始,然后数据包以低电压位开始。这意味着接下来的八个比特是数据。接下来,我们看到五个高电压计数,表示五个 1 比特,然后是三个低电压计数,表示三个 0 比特。你应该知道 UART 消息是以最低有效位首先发送的,意味着最低的二进制值或 20 位,然后是 21 位,然后是 22 位,依此类推。所以,如果你将它们重新排列成人类可读的格式,你的数据消息是 0 0 0 1 1 1 1 1;转换成十进制,那将是 31 或十六进制的 1F。有关不同基数系统(如二进制、十进制和十六进制)的丰富资源,请参阅 www.mathsisfun.com/binary-decimal-hexadecimal.html。还有另一个方便的资源,用于从二进制解码 ASCII 字符 www.asciitable.com/:
图 2.6 – UART 示例比特
蛋白质
拿出你的解码环。现在是学习生命、宇宙和万物意义的时候了…
太棒了,现在你知道如何解码 UART 串行消息了。
好吧,所以你可能想知道,UART 如此简单,我为什么要使用其他任何东西呢? 让我们来看看 UART 的优缺点。
优点如下:
-
便宜
-
全双工(同时发送和接收)
-
异步(没有时钟线)
-
简单,每个设备之间只有两根线
-
奇偶校验用于错误检查
-
广泛使用
缺点如下:
-
每个数据包的最大比特数为九比特。
-
设备时钟必须在彼此的 10% 以内。
-
按照现代标准,它的速度较慢,标准波特率从每秒 9,600 到 230,400 比特不等。
-
需要在每个设备之间建立直接连接,而不是总线架构。
-
起始和停止比特有一些开销,需要复杂的硬件来发送和接收。
如果你想通过 Python 获得 UART 的经验,你可以测试 UART 通信的最简单设备是 Arduino。如果你有,太好了!然后你可以直接跳转到 PySerial 的文档,开始与你的 Arduino 进行通信。如果你没有 Arduino,你可以在本书的仓库中找到一个示例模拟器代码,在第二章文件夹中:
github.com/PacktPublishing/Hands-On-Vision-and-Behavior-for-Self-Driving-Cars/tree/master/Chapter2
接下来,你将了解使用 UART 消息的两种不同标准。
差分与单端
UART 信号可以通过几种不同的方式传输。最常见的是推荐标准 232(RS-232)和推荐标准 422(RS-422)。
RS-232 是一种单端信号,意味着它的电压直接与系统的电气地(0 V)比较。以下图显示了单端信号:
图 2.7 – 单端线
相比之下,RS-422 是一种差分信号,意味着电压是在系统电气地(地线)独立比较的:
图 2.8 – 差分线
现在是故事时间…
从前,信号诞生了,它有一个使命:将发送者的信息传递到接收者居住的遥远之地。世界上充满了鬼怪,它们正在密谋对付我们的英雄信号。这些鬼怪和幽灵绊倒并扭曲了我们可怜的朋友信号。信号在旅途中行进得越远,这些坏蛋就越能偷偷潜入并造成破坏。一般来说,在短途旅行中,信号不受影响,相对无干扰地穿过魔法森林。然而,旅程越长,信号就越需要找到技巧、朋友和守护者,才能安全地到达接收器。
那么,这些鬼怪和幽灵是谁呢?它们是电磁场和感应电流。你看,每当一个幽灵电磁场靠近信号的路径(电线)时,它就会在路径上产生一个鬼怪(电流)。这个鬼怪随后使用它的魔法力量拉伸和收缩信号的臂,直到它到达目的地,接收器看到的信号的臂比它们应有的要短或长。
但不必害怕——技巧、朋友和守护者都在这里!信号有一个很好的小技巧来挫败鬼怪,但首先它必须产生一个双胞胎:我们可以称之为 langis(这是信号的倒写)。langis 和信号在前往接收器的路上相互缠绕。这使鬼怪困惑,导致它们产生两个相等但相反的鬼怪,它们无意中撞在一起并消失,在它们能够使用魔法力量之前。
另一个技巧是 langis 和信号都承诺无论遇到什么小妖精,他们都会始终手牵手一起旅行。所以,当他们到达目的地时,接收器只需测量 langis 和信号之间的距离来获取信息!
好吧,那么这个童话在现实生活中是什么样子呢?你不会只有一个传输线,而是使用两条线。然后你将一条线设置为高电压(V+),另一条线设置为低电压(V-)。现在当比较接收端的信号时,你测量 V+和 V-之间的电压差以确定你是否有高或低信号。以下图显示了单端信号(1a)和差分信号(1b):
图 2.9 – 单端信号与差分信号
这有一个美妙的效果,即任何感应噪声都会以相同的方式影响 V+和 V-,所以当你测量 V+和 V-之间的差异时,它不会改变它发送时的状态。以下图展示了这种情况:
图 2.10 – 差分线的噪声
另一个技巧是将差分对的两个线绕在一起。这会抵消线中任何感应电流。以下插图显示了直通电缆和绞合对电缆电流之间的差异。你可以看到,在每次绞合时,线会交换位置,因此噪声电流在每次绞合时交替,从而有效地相互抵消:
图 2.11 – 差分绞合对电缆的噪声消除
那么,当你选择单端和差分时,这一切对你意味着什么呢?
这里有一个比较表以供参考:
表 2.1
在下一节中,你将了解另一种形式的串行通信,它可以使事情加快一些,还有一些非常实用的好处。
I2C
I2C,或称 I2C,代表互集成电路,是另一种具有一些酷炫新特性的串行数据传输协议。更多关于这些内容稍后介绍。I2C 通常用于在单个印刷电路板(PCB)上的组件之间进行通信。它声称数据传输速率为 100-400 kHz,这通常得到支持,规范甚至为高达 5 MHz 的通信留有空间,尽管这在许多设备上并不常见得到支持。
你可能会问,“为什么使用 I2C?UART 已经非常简单和容易了。” 好吧,I2C 添加了一些非常酷的特性,这些特性在 UART 中是没有的。回想一下,UART 需要在每个设备之间连接两根线,这意味着你需要为每个你想与之通信的设备准备一个连接器。当你想要连接多个设备时,这会迅速变成一个难以管理的线网。此外,在 UART 中,也没有主从设备的概念,因为设备直接在各自的 Tx 和 Rx 线上相互交谈。以下图示将展示一个完全连接的 UART 架构的例子:
图 2.12 – 完全连接的 UART 网络
I2C 来拯救!I2C 也只使用两根线:一根串行时钟线(SCL)和一根串行数据线(SDA)——稍后我们将详细介绍这些是如何工作的。它使用这两根线来在设备之间设置一个新的架构,即总线。总线简单地说是一组共享的线,将信号传输到所有连接到它们的设备。以下插图将帮助我们更好地理解这一点:
图 2.13 – I2C 总线架构
这允许多个设备之间相互交谈,而不需要每个设备到它需要与之交谈的每个其他设备的专用线路。
你可能正在想,大家怎么能都在同一条线上说话并且理解任何东西呢? I2C 协议实现了主从设备的概念。主设备通过向所有人宣布来控制通信流程,嘿,大家注意了,我在和 RasPi1 说话,请确认你在那里,然后发送数据给我! 然后,主设备将控制权交给 RasPi1,它迅速喊道,我在这里,已经理解了请求!这是你请求的数据;请确认你已收到。然后主设备说,收到了! 然后这个过程重新开始。以下是一个 I2C 交换的时序图:
图 2.14 – I2C 时序图
让我们通过一个通信序列来了解一下。这个序列从主设备将 SDA 线拉低,然后是 SCL 线拉低开始。这标志着开始条件。接下来的 7-10 位(取决于你的设置)是正在交谈的从设备的地址。下一个位,R/W 位,指示从设备要么写入(逻辑 0)要么从(逻辑 1)其内存寄存器读取。R/W 位之后的位是确认(ACK)位。如果被寻址的从设备听到了、理解了、确认了,并且将响应请求,那么它就会设置这个位。然后主设备将在 SCL 线上继续生成脉冲,同时从设备或主设备开始将数据放置在 SDA 上的八个数据位上。
大位在前
与 UART 相反,I2C 中的位是先传输 MSB(最高有效位)。
例如,如果 R/W 位被设置为 0,从设备将接收放置在 SDA 上的数据并将其写入内存。紧随八位数据之后,从设备将 SDA 线拉低一个时钟周期以确认它已接收数据、存储数据并准备好将 SDA 线的控制权交还给主设备。此时,主设备将 SDA 线拉低。最后,为了停止序列,主设备将释放 SCL,然后是 SDA。
当这么多设备可以同时通过总线进行通信时,有一些规则来确保不会发生冲突是很重要的。I2C 通过使用开漏系统来实现这一点,这仅仅意味着任何主设备或从设备都只能将线路拉到地。SCL 和 SDA 的空闲状态通过上拉电阻保持在高电压状态。这可以在图 2.13中看到,电阻连接到 VDD。当主设备或从设备想要发送数据时,它们将线路拉到地(或打开漏极)。这确保了你永远不会有一个设备驱动线路高电平,而另一个设备驱动低电平。
I2C 协议的另一个有趣特性是,总线不仅可以有多个从设备,还可以有多个主设备。在这里,你会问,“等等,你说主设备控制流量。我们将如何知道谁在控制?”这个架构的精髓在于每个设备都连接到相同的线路(总线),因此它们都可以在任何给定时间看到正在发生的事情。所以,如果有两个主设备几乎同时尝试控制总线,第一个将 SDA 线拉低的设备获胜!另一个主设备退让并成为临时从设备。有一种情况是两个主设备同时将 SDA 线拉低,此时不清楚谁有控制权。在这种情况下,将开始仲裁。第一个释放 SDA 线到高电平的主设备将失去仲裁权并成为从设备。
复活节彩蛋
如果一只半的母鸡在一天半的时间里下了一只半的蛋,那么半打母鸡在半打天里会下多少蛋?解码以下信号以获取答案!
这里是 I2C 的优缺点总结。
这些是优点:
-
多主多从架构,最多支持 1,024 个设备在 10 位地址模式下。
-
基于总线的,只需要两条线(SCL 和 SDA)
-
速度高达 5 MHz
-
价格低廉
-
消息确认
这些是缺点:
-
半双工,不能同时发送和接收。
-
开始、停止和确认条件的开销降低了吞吐量。
-
拉上电阻限制了时钟速度,消耗了 PCB 空间,并增加了功耗。
-
短的最大线缆长度(1 cm–2 m)取决于电容、电阻和速度。
你已经学到了很多关于 I2C 的知识,这使你拥有了更多关于处理串行数据的知识。在下一节中,你将学习另一种带有更多活力的串行通信协议,但为此牺牲了其他一些东西。
SPI
串行外设接口(SPI)是一种主要用于微控制器的串行传输链路,用于连接外围设备,如 USB、内存和板载传感器。它的主要优势是速度和实现的简单性。SPI 不常用于你在自动驾驶汽车应用中使用的传感器,但如果你遇到它,了解一些相关信息是有价值的。它是一个全双工链路,使用四根线:SCLK、MOSI、MISO 和 SS。以下插图将有助于我们讨论它们的功能:
图 2.15 – SPI 连接图
SPI 是一个同步串行链路,使用主时钟信号(SCLK),这与你在 I2C 中学到的类似。时钟速率通常在 6-12.5 MHz 之间,这也是它的比特率。数据在 主设备输出从设备输入(MOSI)和 主设备输入从设备输出(MISO)线上传递。MOSI、MISO 和 SCLK 可以用作总线架构,就像 I2C 一样。最后一根线是 从机选择(SS)线。这条线被拉低以通知连接到它的从机,它应该监听即将到来的消息。
这与 I2C 相比,I2C 会发送从机地址以及要监听哪个从机的信息。正如你在 图 2.15 中可以看到的,必须为系统添加的每个从机分配一条单独的线和引脚(图中用 SS1、SS2 和 SS3 表示)。用于实现 SPI 的硬件相当简单,通常依赖于移位寄存器。你可能会问:“什么是移位寄存器?” 好吧,这是一个简单的内存寄存器,可以存储一定数量的位,比如八位。每次从一侧引入一个新位时,另一侧就会推出一个位。以下图示说明了这在 SPI 中的工作原理:
图 2.16 – SPI 移位寄存器
由于总线上只允许有一个主设备,SPI 数据传输非常简单。以下图示有助于说明如何使用 SCK、MOSI、MISO 和 SS 来进行全双工数据传输:
图 2.17 – SPI 时序图
主设备将 SS 线拉低,这样目标从机就会知道:“嘿,SS1,这条消息是给你的,请准备好接收。” 然后,主设备在 SCK 线上发送时钟脉冲,告诉从机何时应该采样 MOSI 上传来的数据。如果已经预定从机需要发送一些信息,主设备随后会跟随 SCK 脉冲,告诉从机何时应该在 MISO 线上发送数据。由于有两条线,MISO 和 MOSI,这两个事务可以使用移位寄存器格式同时发生。
SPI 在协议方面不像 UART 或 I2C 那样标准化。因此,你需要查阅你想要连接的设备的接口控制文档,以确定操作该设备所需的特定命令、寄存器大小、时钟模式等。
你可以看到,与 UART 和 I2C 相比,SPI 中没有开销。没有起始位、地址、停止位、确认位或其他开销。它是纯粹、甜美、高速的数据。另一方面,在两个设备之间进行通信需要更多的编程和预先安排的设置。SPI 还可以在数据线上驱动高低电平,允许更快地从 0 到 1 的转换,这导致了之前讨论的更快传输速率。
因此,让我们总结一下优缺点。
这些是优点:
-
6-12.5 MHz 的快速数据速率
-
全双工通信
-
可以使用简单的移位寄存器硬件
-
多个从设备
-
总线架构
这些是缺点:
-
单个主设备
-
需要 4 根线,每增加一个从设备还需要一个从设备选择线。
-
传输长度短,取决于速度、阻抗和电容,最大估计为 3 米
在下一节中,我们将讨论一种在几乎所有道路上行驶的车辆中都使用的非常常见的协议!发动引擎吧!
基于帧的串行协议
到目前为止,我们一直在讨论那些在 8-10 位范围内的消息大小相对较小的协议。如果你想要发送更多的消息呢?在接下来的几节中,你将了解到支持更大消息大小并将它们打包成帧或数据包的协议。
你将了解到以下协议:
-
CAN
-
以太网:UDP 和 TCP
理解 CAN
控制器局域网络 (CAN) 是一种基于消息的协议,由博世公司开发,旨在减少连接车辆中不断增长的微控制器和 电子控制单元 (ECUs) 所需的线缆数量。
这是一个基于总线的协议,由两根作为差分对的线组成,即 CAN-HI 和 CAN-LO。你在 单端与差分 部分学习了差分对。
幽灵和鬼怪
你还记得我们用来为 langis 和信号提供安全通道的那个技巧吗?这个故事中有一个真正的 转折。
CAN 是一个功能丰富的协议,非常健壮、可靠且快速。以下是该协议的一些特性:
-
分散式多主通信
-
优先级消息
-
总线仲裁
-
远程终端请求
-
使用循环冗余校验的数据完整性
-
灵活可扩展的网络
-
集中式诊断和配置
-
通过扭绞差分对抑制电磁干扰噪声
CAN 总线架构非常简单,如下图所示:
图 2.18 – CAN 总线架构
你可以看到节点可以添加在总线内部的任何位置,包括在总线终端 Rterm 内部。连接节点时需要考虑的是未终止的引线长度,标准建议将其保持在 0.3 米以下。
现在我们来看看位是如何在 CAN HI 和 CAN LO 差分双绞线上传输的。以下图说明了 CAN 协议的主导和隐含电压:
从零到英雄
0 以其主导的差分电压上升至最小阈值以上来统治总线。
一劳永逸
1 以其隐含的差分电压在总线上休眠,该电压低于最小阈值。
图 2.19 – CAN 主导和隐含电压
通过 EE JRW – own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=55237229
现在你已经看到了位是如何放置在总线上的,让我们来看看 CAN 帧结构。如果你发现自己正在调试或读取 CAN 总线流量,这将很有用。以下图显示了 CAN 帧的各个部分:
图 2.20 – CAN 消息格式
CAN 帧以0开始,这是主导的差分电压。这听起来可能有点类似于你在 UART 通信中学到的,UART 也是以逻辑0开始的。与 UART 类似,CAN 中的 SOF 位是从空闲状态到活动状态的转换。然而,与 UART 不同的是,活动状态和主导状态是高电压状态。
在 SOF 位之后是仲裁字段。这可以被认为是 ECU 的功能地址(例如,转向模块、氧传感器、激光雷达传感器等)。
少即是多
在仲裁字段中地址较小的 ECU 在 CAN 协议中被认为是优先级较高的。当两个或多个设备同时开始传输时,较小的地址将赢得仲裁。
下一个位是1,隐含状态。
接下来的六位是帧的数据长度码(DLC)部分,它说明了即将到来的数据字段将有多长。CAN 消息的数据长度可以是 0 到 8 字节。
紧接着 DLC 的是数据,其长度可以是 0-64 位(0-8 字节)。
位顺序
CAN 以 MSB(最高有效位)优先发送其信息。
接下来是循环冗余校验(CRC)字段,长度为 15 位,用于检查消息中的错误。发送 ECU 对数据字段进行校验和计算,并将其放置在 CRC 字段中。一旦接收 ECU 接收到帧,它将在数据字段上运行相同的校验和计算,并验证它是否与接收帧中的 CRC 字段匹配。CRC 字段紧随其后的是 CRC 定界符字段,以将其与 ACK 位分开。
1位是隐性的,这样任何接收 ECU 都可以在位间隔期间确认接收到无错误的数据。ACK 位后面跟着 ACK 定界符,以允许任何超出 ACK 位的时序差异。
最后,1位,表示 – 您猜对了 – 帧的结束。
好吧,还有一件事:存在一个帧间空间(IFS),它由系统的 CAN 控制器定义。
好吧,这已经很长了。不过不用担心;CAN 是一个非常受支持的协议,您可以找到大量的软件和硬件模块来为您做繁重的工作。您可能只有在事情不正常时才需要翻出老式的示波器来探测 CAN 总线并验证消息是否正确传输。
让我们回顾一下 CAN 总线协议的优缺点。
这些是优点:
-
去中心化多主通信
-
优先级消息
-
总线仲裁
-
RTR
-
使用 CRC 进行数据完整性
-
灵活、可扩展的网络
-
集中式诊断和配置
-
通过双绞差分对抑制 EMI 噪声
-
最大电缆长度为 40 米
这实际上只有一个缺点:
- 需要仔细注意布线总线端子和跳线长度。
在下一节中,您将了解现代汽车和家庭中使用的最普遍的网络协议。
以太网和互联网协议
以太网是一个由协议和层组成的框架,在现代网络中被用于几乎与您互动的每个应用中。以太网存在于您的家中,您乘坐的火车上,您乘坐的飞机上,当然也包括您的自动驾驶汽车中。它包括基于网络的通信的物理和协议标准。一切始于不同层的开放系统互连(OSI)模型。以下图示说明了 OSI 模型的七层及其每一层的任务:
图 2.21 – OSI 模型的七层
每一层都有自己的协议来处理数据。一切始于应用层的原始数据或比特。数据在每一层被处理,以便传递到下一层。每一层将前一层的帧包装成一个新的帧,这就是为什么模型显示了帧越来越大。以下图示说明了每一层的协议:
图 2.22 – OSI 模型的协议
我们可以花整整一本书的时间来讨论每一层和协议的细节。相反,我们将专注于您在自动驾驶汽车中与传感器和执行器一起工作时将遇到的两种协议(UDP 和 TCP)。
理解 UDP
用户数据报协议(UDP)是激光雷达、摄像头和雷达等传感器非常流行的协议。它是一个无连接协议。等等——如果它是无连接的,它是如何发送数据的? 在这个意义上,无连接只是意味着在发送数据之前,该协议不会验证它是否能够到达目的地。UDP 存在于 OSI 模型的传输层。你可以在以下图中看到,传输层是第一个添加头部的一层:
图 2.23 – 传输层上的 UDP
如果你要给某人送礼物,你希望他们知道关于礼物的哪些信息,以便他们可以确信礼物是给他们的,而不是被换成别人的礼物?你可能会说些像,“Tenretni Olleh,我正在给你发送一套大号奢华彩虹睡衣,希望它们合身。请试穿一下。”这正是 UDP 头部的作用。它存储源端口、目的端口、包括头部在内的数据长度,最后是一个校验和。校验和只是一个在发送数据之前用算法创建的数字,以确保当它被接收时,数据是完整的且未被损坏。这是通过在接收数据上运行相同的算法,并将生成的数字与校验和值进行比较来完成的。这就像给 Tenretni 发送所发送睡衣的图片,这样他们就知道他们收到了正确的礼物。
以下图示展示了 UDP 头部内的字段以及实际的消息本身:
图 2.24 – UDP 头部字段
端口、插头和插座
在以太网协议中,一个端口可以类比为墙上的电源插座。你将不同的设备插入插座,例如灯具和电视。每个插座一旦连接,就为特定的设备提供电源。同样,端口是创建用于特定设备或协议发送和/或接收数据的一个数字插座。
UDP 头部始终是 8 字节(64 位),而数据(消息)的长度可以达到 65,507 字节。以下图示是一个相关示例,展示了来自一个流行的超高分辨率激光雷达传感器系列的 UDP 数据包的数据(消息)字段大小:
图 2.25 – Ouster 激光雷达 UDP 数据结构
从这里你可以看到,如果你仔细地将所有字节相乘,你会得到 389 个单词 * 4 字节/单词 * 16 个方位/数据包 = 24,896 字节/数据包。这完全在 UDP 数据包的数据限制大小范围内,65,507 字节。为了通过 UDP 发送这些数据,激光雷达传感器需要附加什么数据?你已经猜到了——需要有一个包含源、目的、数据长度和校验和信息的 UDP 头部。
UDP 通常用于流式设备,如激光雷达传感器、摄像头和雷达,因为如果数据没有收到,重新发送数据是没有意义的。想象一下,在激光雷达传感器示例中,你没有收到几个方位角。你会希望重新发送那些数据给你吗?可能不会,因为激光反射的任何东西现在都过去了,并且可能处于不同的位置。使用 UDP 的另一个原因是,由于数据速率高,如果需要重新发送丢失或损坏的数据,这将极大地减慢速度。
在下一节中,我们将讨论一个协议,该协议将解决你可能想要确保每个数据包都进行三次握手的情况。
理解 TCP
如果你打算发送一个命令来转动自动驾驶汽车的转向盘,你会不会对命令从未到达、错误或损坏的情况感到满意?你会对不知道转向执行器是否收到命令的情况感到满意吗?可能不会!
这就是传输控制协议(TCP)能为你服务的地方!TCP 的操作方式类似于 UDP…实际上,它完全不同。与 UDP 不同,TCP 是一种基于连接的协议。这意味着每次你想发送数据时,你都需要进行三次握手。这是通过一个称为 SYN-SYN/ACK-ACK 的过程来完成的。让我们将其分解以更好地理解:
-
SYN – 客户端发送一个带有随机选择的初始序列号(
x)的 SYN(同步)数据包,该序列号用于计算发送的字节数。它还将 SYN 位标志设置为1(稍后会有更多介绍)。 -
SYN/ACK – 服务器接收到 SYN 数据包:
-
它将
x增加 1。这成为确认(ACK)编号(x+1),这是它期望接收的下一个字节的编号。 -
然后它向客户端发送一个带有 ACK 编号以及服务器自己随机选择的序列号(
y)的 SYN/ACK 数据包。- ACK – 客户端接收到带有 ACK 编号(
x+1)和服务器序列号(y)的 SYN/ACK 数据包:
-
它将服务器的初始序列号增加到
y+1。 -
它向服务器发送一个带有 ACK 编号(
y+1)和 ACK 位标志设置为1的 ACK 数据包以建立连接。
- ACK – 客户端接收到带有 ACK 编号(
以下图表说明了连接序列:
图 2.26 – TCP 连接序列图
现在连接已经建立,数据可以开始流动。每个发送的数据包都将跟随一个 ACK 数据包,其中包含接收到的字节数加 1,表示数据包已完整接收,并指出它期望接收的下一个字节编号。对于 SYN 和 SYN/ACK 数据包,序列号增加 1,对于 ACK 数据包,增加接收到的有效载荷字节数。
你已经可以看到,为了完成所有这些,头部将需要比 UDP 更多的字段。以下图表说明了 TCP 头部的字段:
图 2.27 – TCP 头字段
让我们逐个字段及其用途进行解析:
-
源端口:这是数据包发送的端口。这通常是一个随机分配的端口号。
-
22。可以在以下链接找到知名端口的列表:www.iana.org/assignments/service-names-port-numbers/service-names-port-numbers.xhtml. -
序列号:这是有效载荷中第一个发送的字节的编号;对于 SYN 和 SYN/ACK 数据包,它是随机选择的初始序列号。
-
确认号:这是已接收的字节数加一,表示预期的下一个字节编号。
-
数据偏移:这是 TCP 头的长度,即有效载荷之前的偏移量。
-
保留:这些是未使用但为未来协议改进预留的位。
-
(
0或1)。这用于标记数据包为紧急。 -
ACK位标志,当发送有效的确认号时设置为1。 -
当数据应立即推送到应用程序时设置为
1。 -
当连接需要重置时设置为
1。 -
当初始化 SYN-SYN/ACK 连接建立过程时设置为
1。它表示序列号字段中有一个有效的序列号。 -
当所有数据发送后应关闭连接时设置为
1。 -
窗口:这是接收端在丢失数据之前可以接受的缓冲区大小。
-
payload+header用于验证接收到的数据是否有效且未更改。 -
URG位标志设置为1。
TCP 使用所有这些头部信息来确保所有数据都被接收、验证和确认。如果数据丢失,可以使用最后一个有效的序列号重新发送数据。现在您可以自信地通过以太网发送转向命令,知道您不会冲下悬崖!
汽车主要使用 CAN…
虽然我们在这里以转向为例说明了 TCP,但您通常会发现在工厂中,车辆控制命令是通过以太网总线从 CAN 总线发送的。然而,越来越多的自动驾驶汽车创造者正依赖以太网,因为它具有更高的数据吞吐量和安全性。未来,人们讨论将工厂车辆迁移到以太网总线。军用飞机已经开始了这样的行动!
好吧——天哪,这有很多东西要理解。不过,不用担心:现在您已经看了一次并理解了,您就可以依赖开源工具在将来解析这些信息了。您会发现这很有用,当事情开始出错并且您需要调试数据流时。
说到这个,Wireshark 是一款用于在您的网络上嗅探以太网数据包并查看信息流以进行调试和测试的出色工具。您可以在 www.wireshark.org/ 找到有关安装和使用的所有信息。
如你所见,TCP 是一种强大的基于连接的、高度可靠且安全的协议。现在,出去开始使用本章末尾列出的开源工具使用以太网协议吧!
摘要
恭喜你,你已经和你的新朋友——langis 和信号一起完成了你的任务!你经历了一段相当刺激的冒险!你与以电磁波和感应电流形式出现的鬼怪战斗。在旅途中,你学到了很多关于串行与并行数据传输;数字与模拟信号;以及 UART、I2C、SPI、CAN、UDP 和 TCP 等协议及其秘密解码环的知识!你现在拥有了将传感器和执行器集成到你的真实自动驾驶汽车中所需的知识。
在下一章中,你将学习如何使用 OpenCV 检测道路上的车道,这是确保你的自动驾驶汽车安全合法运行的重要技能!
问题
在阅读本章后,你应该能够回答以下问题:
-
每个协议需要多少根线,它们的名称是什么?
-
有哪些方法可以减少信号中的噪声?
-
串行和并行数据传输有什么区别?
-
哪些协议使用总线架构?
-
哪些协议包含时钟信号?
-
哪个协议被广泛用于将 GPS 信息发送到其他传感器?
进一步阅读
-
德州仪器公司控制器局域网物理层要求(
www.ti.com/lit/an/slla270/slla270.pdf?HQS=slla270-aaj&ts=1589256007656) -
德州仪器公司关于控制器局域网(CAN)的介绍(
www.ti.com/lit/an/sloa101b/sloa101b.pdf) -
通用异步接收器/发送器(UART)(
ieeexplore.ieee.org/document/7586376) -
理解 I2C 总线(
www.ti.com/lit/an/slva704/slva704.pdf?&ts=1589265769229)
开源协议工具
你还可以参考以下资源,了解更多关于使用这些协议进行编程的工具:
-
PySerial(pypi.org/project/pyserial/) 用于 UART(RS-232、RS-422、RS-485) -
python-periphery(python-periphery.readthedocs.io/en/latest/index.html) 用于 UART、I2C、SPI 等 -
smbus2(pypi.org/project/smbus2/) 用于 I2C -
spidev(pypi.org/project/spidev/) 用于 SPI -
python-can(pypi.org/project/python-can/) 用于 CAN -
socket(docs.python.org/3/library/socket.html) 用于以太网 TCP、UDP 等
第三章:第三章:车道检测
本章将展示使用计算机视觉(特别是 OpenCV)可以实现的一些令人难以置信的事情:车道检测。你将学习如何分析图像并逐步构建更多的视觉知识,应用多种过滤技术,用对图像的更好理解来替换噪声和近似,直到你能够检测到直道上或转弯处的车道位置,然后我们将把这个流程应用到视频中,以突出道路。
你会看到这种方法依赖于几个可能在实际世界中不成立的假设,尽管它可以进行调整以纠正这一点。希望你会觉得这一章很有趣。
我们将涵盖以下主题:
-
在道路上检测车道
-
颜色空间
-
透视校正
-
边缘检测
-
阈值
-
直方图
-
滑动窗口算法
-
多项式拟合
-
视频滤波
到本章结束时,你将能够设计一个流程,使用 OpenCV 检测道路上的车道线。
技术要求
我们的车道检测流程需要相当多的代码。我们将解释主要概念,并且你可以在 GitHub 上找到完整的代码,链接为github.com/PacktPublishing/Hands-On-Vision-and-Behavior-for-Self-Driving-Cars/tree/master/Chapter3。
对于本章中的说明和代码,你需要以下内容:
-
Python 3.7
-
OpenCV-Python 模块
-
NumPy 模块
-
Matplotlib 模块
为了识别车道,我们需要一些图像和一段视频。虽然很容易找到一些开源数据库来使用,但它们通常仅供非商业用途。因此,在这本书中,我们将使用两个开源项目生成的图像和视频:CARLA,一个用于自动驾驶任务的模拟器,以及 Speed Dreams,一个开源视频游戏。所有技术也适用于现实世界的视频,我们鼓励你尝试在 CULane 或 KITTI 等公共数据集上使用它们。
本章的“代码在行动”视频可以在以下位置找到:
如何执行阈值操作
对于人类来说,跟随车道线很容易,但对于计算机来说,这并不是那么简单。一个问题是一个道路图像包含太多的信息。我们需要简化它,只选择我们感兴趣的部分。我们将只分析图像中车道线部分,但我们也需要将车道线从图像的其余部分分离出来,例如,使用颜色选择。毕竟,道路通常是黑色或深色的,而车道通常是白色或黄色的。
在接下来的几节中,我们将分析不同的颜色空间,以查看哪一个对阈值化最有用。
阈值在不同颜色空间上的工作原理
从实际角度来看,颜色空间是分解图像颜色的一种方式。您可能最熟悉 RGB,但还有其他颜色空间。
OpenCV 支持多种颜色空间,作为此流程的一部分,我们需要从各种颜色空间中选择两个最佳通道。我们为什么要使用两个不同的通道?有两个原因:
-
对于白色车道来说,一个好的颜色空间可能不适合黄色车道。
-
当存在困难的帧(例如,道路上存在阴影或车道变色时),一个通道可能比另一个通道受影响较小。
对于我们的示例来说,这可能不是严格必要的,因为车道总是白色的,但在现实生活中这绝对是有用的。
我们现在将看到我们的测试图像在不同颜色空间中的外观,但请记住,您的情况可能不同。
RGB/BGR
起始点将是以下图像:
图 3.1 – 参考图像,来自 Speed Dreams
图像当然可以分解为三个通道:红色、绿色和蓝色。正如我们所知,OpenCV 以 BGR(意味着,第一个字节是蓝色通道,而不是红色通道)存储图像,但从概念上讲,没有区别。
这就是分离后的三个通道:
图 3.2 – BGR 通道:蓝色、绿色和红色通道
它们看起来都很好。我们可以尝试通过选择白色像素来分离车道。由于白色颜色是(255, 255, 255),我们可以留出一些余地并选择高于 180 的颜色的像素。为了执行此操作,我们需要创建一个与所选通道相同大小的黑色图像,然后在原始通道中所有高于 180 的像素上涂成白色:
img_threshold = np.zeros_like(channel)
img_threshold [(channel >= 180)] = 255
这就是输出看起来像这样:
图 3.3 – BGR 通道:蓝色、绿色和红色通道,阈值为 180 以上
它们看起来都很好。红色通道也显示了汽车的一部分,但由于我们不会分析图像的这一部分,所以这不是问题。由于白色在红色、绿色和蓝色通道中具有相同的值,所以在所有三个通道上都能看到车道是预料之中的。然而,对于黄色车道来说,情况并非如此。
我们选择的阈值非常重要,不幸的是,它取决于车道使用的颜色和道路情况;光线条件和阴影也会影响它。
下图显示了完全不同的阈值,20-120:
图 3.4 – BGR 通道:蓝色、绿色和红色通道,阈值为 20-120
您可以使用以下代码选择 20-120 范围内的像素:
img_threshold[(channel >= 20) & (channel <= 120)] = 255
只要考虑车道是黑色的,图像可能仍然可用,但这并不推荐。
HLS
HLS 颜色空间将颜色分为色调、亮度和饱和度。结果有时会令人惊讶:
图 3.5 – HLS 通道:色调、亮度和饱和度
色调通道相当糟糕,噪声大,分辨率低,而亮度似乎表现良好。饱和度似乎无法检测到我们的车道。
让我们尝试一些阈值:
图 3.6 – HLS 通道:色调、亮度和饱和度,阈值高于 160
阈值显示,亮度仍然是一个好的候选者。
HSV
HSV 颜色空间将颜色分为色调、饱和度和值,它与 HLS 相关。因此,结果是类似于 HLS 的:
图 3.7 – HSV 通道:色调、饱和度和值
色调和不饱和度对我们来说没有用,但应用阈值后的亮度看起来不错:
图 3.8 – HSV 通道:色调、饱和度和值,阈值高于 160
如预期,值的阈值看起来不错。
LAB
LAB(CIELAB 或 CIE Lab*)颜色空间将颜色分为 L*(亮度,从黑色到白色)、a*(从绿色到红色)和 b*(从蓝色到黄色):
图 3.9 – LAB 通道:L*、a和 b
L看起来不错,而 a和 b*对我们来说没有用:
图 3.10 – LAB 通道:L*、a和 b,阈值高于 160
YCbCr
YCbCr 是我们将要分析的最后一个颜色空间。它将图像分为亮度(Y)和两个色度分量(Cb 和 Cr):
图 3.11 – YCbCr 通道:Y、Cb 和 Cr
这是应用阈值后的结果:
图 3.12 – YCbCr 通道:Y、Cb 和 Cr,阈值高于 160
阈值证实了亮度通道的有效性。
我们的选择
经过一些实验,似乎绿色通道可以用于边缘检测,而 HLS 空间中的 L 通道可以用作额外的阈值,因此我们将坚持这些设置。这些设置对于黄色线条也应该适用,而不同的颜色可能需要不同的阈值。
透视校正
让我们退一步,从简单开始。我们可以拥有的最简单的情况是直线车道。让我们看看它看起来如何:
图 3.13 – 直线车道,来自 Speed Dreams
如果我们飞越道路,并从鸟瞰的角度观察,车道线将是平行的,但在图片中,由于透视,它们并不是平行的。
透视取决于镜头的焦距(焦距较短的镜头显示的透视更强)和摄像机的位置。一旦摄像机安装在汽车上,透视就固定了,因此我们可以考虑这一点并校正图像。
OpenCV 有一个计算透视变换的方法:getPerspectiveTransform()。
它需要两个参数,都是四个点的数组,用于标识透视的梯形。一个数组是源,一个数组是目标。这意味着可以使用相同的方法通过交换参数来计算逆变换:
perspective_correction = cv2.getPerspectiveTransform(src, dst)
perspective_correction_inv = cv2.getPerspectiveTransform(dst, src)
我们需要选择车道线周围的区域,以及一个小边距:
图 3.14 – 带有车道线周围感兴趣区域的梯形
在我们的情况下,目标是一个矩形(因为我们希望它变得笔直)。图 3.14显示了带有原始视角的绿色梯形(前一段代码中的src变量)和白色矩形(前一段代码中的dst变量),这是期望的视角。请注意,为了清晰起见,它们被绘制为重叠的,但矩形的坐标作为参数传递时发生了偏移,就像它从X坐标 0 开始一样。
现在我们可以应用透视校正并获取我们的鸟瞰视图:
cv2.warpPerspective(img, perspective_correction, warp_size, flags=cv2.INTER_LANCZOS4)
warpPerspective()方法接受四个参数:
-
源图像。
-
从
getPerspectiveTransform()获得的变换矩阵。 -
输出图像的大小。在我们的情况下,宽度与原始图像相同,但高度只是梯形/矩形的宽度。
-
一些标志,用于指定插值。
INTER_LINEAR是一个常见的选项,但我建议进行实验,并尝试使用INTER_LANCZOS4。
这就是使用INTER_LINEAR进行扭曲的结果:
图 3.15 – 使用 INTER_LINEAR 扭曲
这是使用INTER_LANCZOS4的结果:
图 3.16 – 使用 INTER_LANCZOS4 扭曲
它们非常相似,但仔细观察会发现,使用LANCZOS4重采样进行的插值更清晰。我们将在后面看到,在管道的末端,差异是显著的。
在两张图片中都很清楚的是,我们的线条现在是垂直的,这直观上可能有助于我们。
我们将在下一节中看到如何利用这张图像。
边缘检测
下一步是检测边缘,我们将使用绿色通道来完成这项工作,因为在我们的实验中,它给出了良好的结果。请注意,您需要根据您计划运行软件的国家/地区以及许多不同的光照条件对图像和视频进行实验。很可能会根据线条的颜色和图像中的颜色,您可能需要选择不同的通道,可能是来自另一个颜色空间;您可以使用cvtColor()等函数将图像转换为不同的颜色空间:
img_hls = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2HLS).astype(np.float)
我们将坚持使用绿色。
OpenCV 有几种计算边缘检测的方法,我们将使用 Scharr,因为它表现相当不错。Scharr 计算导数,因此它检测图像中的颜色差异。我们对 X 轴感兴趣,并且希望结果是一个 64 位的浮点数,所以我们的调用将如下所示:
edge_x = cv2.Scharr(channel, cv2.CV_64F, 1, 0)
由于 Scharr 计算导数,值可以是正的也可以是负的。我们感兴趣的并不是符号,而只是存在边缘的事实。因此,我们将取绝对值:
edge_x = np.absolute(edge_x)
另一个问题是我们期望的单通道图像上的 0-255 值范围内的值没有界限,而值是浮点数,而我们需要一个 8 位的整数。我们可以通过以下行解决这两个问题:
edge_x = np.uint8(255 * edge_x / np.max(edge_x))
这是结果:
图 3.17 – 使用 Scharr 进行边缘检测,缩放并取绝对值
图 3.17 – 使用 Scharr 进行边缘检测,缩放并取绝对值
在这一点上,我们可以应用阈值将图像转换为黑白,以便更好地隔离车道像素。我们需要选择要选择的像素强度,在这种情况下,我们可以选择 20-120;我们只选择至少具有 20 的强度值且不超过 120 的像素:
binary = np.zeros_like(img_edge)
binary[img_edge >= 20] = 255
zeros_like()方法创建一个全零数组,其形状与图像相同,第二行将强度在 20 到 120 之间的所有像素设置为 255。
这是结果:
图 3.18 – 应用 20 阈值后的结果
现在,车道非常明显,但有一些噪声。我们可以通过提高阈值来减少噪声:
binary[img_edge >= 50] = 255
这就是输出显示的样子:
图 3.19 – 应用 50 阈值后的结果
现在,噪声更少,但我们失去了顶部的线条。
现在,噪声更少,但我们失去了顶部的线条。
插值阈值
在实践中,我们不必在用很多噪声选择整条线与在检测到部分线的同时减少噪声之间做出选择。我们可以对底部(那里我们分辨率更高,图像更清晰,噪声更多)应用更高的阈值,而在顶部(那里我们得到的对比度更低,检测更弱,噪声更少,因为像素被透视校正拉伸,自然地模糊了)应用较低的阈值。我们可以在阈值之间进行插值:
threshold_up = 15 threshold_down = 60 threshold_delta = threshold_down-threshold_up for y in range(height): binary_line = binary[y,:] edge_line = channel_edge[y,:] threshold_line = threshold_up + threshold_delta * y/height binary_line[edge_line >= threshold_line] = 255
让我们看看结果:
图 3.20 – 应用插值阈值后的结果,从 15 到 60
现在,我们可以在底部有更少的噪声,并在顶部检测到更弱的信号。然而,虽然人类可以直观地识别车道,但对于计算机来说,它们仍然只是图像中的像素,所以还有工作要做。但我们极大地简化了图像,并且我们正在取得良好的进展。
组合阈值
如我们之前提到的,我们也想在另一个通道上使用阈值,而不进行边缘检测。我们选择了 HLS 的 L 通道。
这是超过 140 的阈值的结果:
图 3.21 – L 通道,阈值超过 140
还不错。现在,我们可以将其与边缘结合起来:
图 3.22 – 两个阈值的组合
结果更嘈杂,但也更稳健。
在继续前进之前,让我们引入一个带有转弯的图片:
图 3.23 – 转弯车道,来自 Speed Dreams
这是阈值:
图 3.24 – 转弯车道,阈值之后
它仍然看起来不错,但我们可以看到,由于转弯,我们不再有垂直线。事实上,在图像的顶部,线条基本上是水平的。
使用直方图查找车道
我们如何或多或少地理解车道在哪里?对于人类来说,答案是简单的:车道是一条长线。但对于计算机来说呢?
如果我们谈论垂直线,一种方法可以是计算某一列中白色的像素。但是,如果我们检查转弯的图像,那可能不起作用。然而,如果我们把注意力减少到图像的底部,线条就有点更垂直了:
图 3.25 – 转弯车道,阈值之后,底部部分
我们现在可以按列计数像素:
partial_img = img[img.shape[0] // 2:, :] # Select the bottom part
hist = np.sum(partial_img, axis=0) # axis 0: columns direction
要将直方图保存为文件中的图形,我们可以使用 Matplotlib:
import matplotlib.pyplot as plt
plt.plot(hist)plt.savefig(filename)plt.clf()
我们得到了以下结果:
图 3.26 – 左:直线车道的直方图,右:转弯车道的直方图
直方图上的 X 坐标代表像素;由于我们的图像分辨率为 1024x600,直方图显示了 1,024 个数据点,峰值集中在车道所在像素周围。
如我们所见,在直线车道的情况下,直方图清楚地识别了两条线;在转弯的情况下,直方图不太清晰(因为线条转弯,因此白色像素在周围稍微分散),但它仍然可用。我们还可以看到,在虚线线的情况下,直方图中的峰值不太明显,但它仍然存在。
这看起来很有希望!
现在,我们需要一种方法来检测两个峰值。我们可以使用 NumPy 的argmax()函数,它返回数组中最大元素的索引,这是我们其中一个峰值。然而,我们需要两个。为此,我们可以将数组分成两半,并在每一半中选择一个峰值:
size = len(histogram)
max_index_left = np.argmax(histogram[0:size//2])
max_index_right = np.argmax(histogram[size//2:]) + size//2
现在我们有了索引,它们代表峰值的 X 坐标。这个值本身(例如,histogram[index])可以被认为是识别车道线的置信度,因为更多的像素意味着更高的置信度。
滑动窗口算法
当我们在取得进展时,图像仍然有一些噪声,这意味着有一些像素可以降低精度。此外,我们只知道线条的起始位置。
解决方案是专注于线条周围的区域——毕竟,没有必要在整个扭曲的图像上工作;我们可以从线条的底部开始,然后“跟随”它。这可能是图像胜过千言万语的例子,所以这是我们想要达到的:
图 3.27 – 顶部:滑动窗口,底部:直方图
在图 3.27 的上部,每个矩形代表一个感兴趣窗口。每个通道底部的第一个窗口位于直方图相应峰值的中心。然后,我们需要一种“跟随线条”的方法。每个窗口的宽度取决于我们想要的边距,而高度取决于我们想要的窗口数量。这两个数字可以改变以达到更好的检测(减少不需要的点以及因此的噪声)和检测更困难转弯的可能性,半径更小(这将要求窗口更快地重新定位)。
由于此算法需要相当多的代码,我们将专注于左侧车道以保持清晰,但相同的计算也需要对右侧车道进行。
初始化
我们只对被阈值选择的像素感兴趣。我们可以使用 NumPy 的nonzero()函数:
non_zero = binary_warped.nonzero()
non_zero_y = np.array(non_zero[0])
non_zero_x = np.array(non_zero[1])
non_zero变量将包含白色像素的坐标,然后non_zero_x将包含 X 坐标,而non_zero_y将包含 Y 坐标。
我们还需要设置 margin,即允许车道移动的距离(例如,滑动窗口窗口宽度的一半),以及 min_pixels,这是我们想要检测以接受滑动窗口新位置的最小像素数。低于此阈值,我们不会更新它:
margin = 80 min_pixels = 50
滑动窗口的坐标
left_x 变量将包含左侧车道的位置,我们需要用从直方图获得的价值初始化它。
在设置好场景后,我们现在可以遍历所有窗口,我们将使用的索引变量是 idx_window。X 范围是从最后的位置计算的,加上 margin:
win_x_left_min = left_x - margin
win_x_left_max = left_x + margin
Y 范围由我们正在分析的窗口的索引确定:
win_y_top = img_height - idx_window * window_height win_y_bottom = win_y_top + window_height
现在,我们需要选择白色像素(来自 non_zero_x 和 non_zero_y)并且被我们正在分析的窗口所约束的像素。
NumPy 数组可以使用重载运算符进行过滤。为了计算所有在 win_y_bottom 之上的 Y 坐标,我们可以简单地使用以下表达式:
non_zero_y >= win_y_bottom
结果是一个数组,选中的像素为 True,其他像素为 False。
但我们需要的是 win_y_top 和 win_y_bottom 之间的像素:
(non_zero_y >= win_y_bottom) & (non_zero_y < win_y_top)
我们还需要 X 坐标,它必须在 win_x_left_min 和 win_x_left_max 之间。由于我们只需要计数,我们可以添加一个 nonzero() 调用:
non_zero_left = ((non_zero_y >= win_y_bottom) & (non_zero_y < win_y_top) & (non_zero_x >= win_x_left_min) &
(non_zero_x < win_x_left_max)).nonzero()[0]
我们需要选择第一个元素,因为我们的数组位于另一个只有一个元素的数组内部。
我们还将把这些值保存在一个变量中,以便稍后绘制车道线:
left_lane_indexes.append(non_zero_left)
现在,我们只需要更新左侧车道的位置,取位置的平均值,但前提是有足够多的点:
if len(non_zero_left) > min_pixels:
left_x = np.int(np.mean(non_zero_x[non_zero_left]))
多项式拟合
现在,我们可能已经选择了成千上万的点,但我们需要理解它们并得到一条线。为此,我们可以使用 polyfit() 方法,该方法可以用指定次数的多项式来近似一系列点;对于二次多项式对我们来说就足够了:
x_coords = non_zero_x[left_lane_indexes]
y_coords = non_zero_y[left_lane_indexes]
left_fit = np.polynomial.polynomial.polyfit(y_coords, x_coords, 2)
注意
请注意,polyfit() 函数接受参数的顺序为 (X, Y),而我们所提供的顺序为 (Y, X)。我们这样做是因为按照数学惯例,在多项式中,X 是已知的,而 Y 是基于 X 计算得出的(例如,Y = X² + 3X + 5*)。然而,我们知道 Y 并需要计算 X,因此我们需要以相反的顺序提供它们。
我们几乎完成了。
Y 坐标只是一个范围:
ploty = np.array([float(x) for x in range(binary_warped.shape[0])])
然后,我们需要从 Y 计算出 X,使用二次多项式的通用公式(在 X 和 Y 上反转):
x = Ay² + By + C;
这是代码:
Left_fitx = left_fit[2] * ploty ** 2 + left_fit[1] * ploty + left_fit[0]
这是我们现在的位置:
图 3.28 – 在扭曲图像上绘制的车道
我们现在可以使用逆透视变换调用 perspectiveTransform() 来移动像素到图像中的相应位置。这是最终结果:
图 3.29 – 图像上检测到的车道
恭喜!这并不特别容易,但现在你可以在正确的条件下检测到帧上的车道。不幸的是,并不是所有的帧都足够好来进行这项检测。让我们在下一节中看看我们如何可以使用视频流的时序演变来过滤数据并提高精度。
增强视频
从计算角度来看,实时分析视频流可能是一个挑战,但通常,它提供了提高精度的可能性,因为我们可以在前一帧的知识基础上构建并过滤结果。
现在我们将看到两种技术,当处理视频流时,可以使用这些技术以更高的精度检测车道。
部分直方图
如果我们假设在前几帧中正确检测到了车道,那么当前帧上的车道应该处于相似的位置。这个假设受汽车速度和相机帧率的影响:汽车越快,车道变化就越大。相反,相机越快,车道在两帧之间移动就越少。在现实中的自动驾驶汽车中,这两个值都是已知的,因此如果需要,可以将其考虑在内。
从实际的角度来看,这意味着我们可以限制我们分析直方图的区域,以避免错误检测,只分析一些之前帧平均值的周围的一些直方图像素(例如,30)。
滚动平均
我们检测的主要结果是每个车道的多项式拟合的三个值。遵循上一节相同的原理,我们可以推断出它们在帧之间不会变化太多,因此我们可以考虑一些之前帧的平均值,以减少噪声。
有一种称为指数加权移动平均(或滚动平均)的技术,可以用来轻松计算值流中最后一些值的近似平均值。
给定 beta,一个大于零且通常接近一的参数,移动平均可以按以下方式计算:
moving_average = beta * prev_average + (1-beta)*new_value
作为一个指示,影响平均值的帧数如下:
1 / (1 - beta)
因此,beta = 0.9 会平均 10 帧,而 beta = 0.95 会平均 20 帧。
这就结束了本章。我邀请您在 GitHub 上查看完整的代码,并尝试对其进行操作。您可以在那里找到一些真实的视频片段并尝试识别车道。
并且不要忘记应用相机标定,如果可能的话。
摘要
在本章中,我们构建了一个很好的车道检测流程。首先,我们分析了不同的颜色空间,如 RGB、HLS 和 HSV,以查看哪些通道对检测车道更有用。然后,我们使用getPerspectiveTransform()进行透视校正,以获得鸟瞰图并使道路上的平行线在分析的图像上也看起来平行。
我们使用Scharr()进行边缘检测,以检测边缘并使我们的分析比仅使用颜色阈值更稳健,并将两者结合起来。然后我们计算直方图以检测车道开始的位置,并使用“滑动窗口”技术来“跟随”图像中的车道。
然后,我们使用polyfit()在检测到的像素上拟合一个二次多项式,使它们有意义,并使用函数返回的系数来生成我们的曲线,在它们上应用反向透视校正后。最后,我们讨论了两种可以应用于视频流以提高精度的技术:部分直方图和滚动平均值。
使用所有这些技术一起,你现在可以构建一个能够检测道路上车道线的管道。
在下一章中,我们将介绍深度学习和神经网络,这些是强大的工具,我们可以使用它们来完成更复杂的计算机视觉任务。
问题
-
你能列举一些除了 RGB 之外的颜色空间吗?
-
为什么我们要应用透视校正?
-
我们如何检测车道开始的位置?
-
你可以使用哪种技术来跟随图像中的车道?
-
如果你有很多点大致形成一个车道,你如何将它们转换成一条线?
-
你可以使用哪个函数进行边缘检测?
-
你可以使用什么来计算最后N个位置的平均值?
第二部分:使用深度学习和神经网络改进自动驾驶汽车的工作方式
本节将引导你进入深度学习的世界,希望用相对简单和简短的代码所能实现的事情给你带来惊喜。
本节包含以下章节:
-
第四章*,使用神经网络进行深度学习*
-
第五章*,深度学习工作流程*
-
第六章*,改进你的神经网络*
-
第七章*,检测行人和交通信号灯*
-
第八章*,行为克隆*
-
第九章*,语义分割*
第四章:第四章:使用神经网络的深度学习
本章是使用 Keras 介绍神经网络。如果你已经使用过 MNIST 或 CIFAR-10 图像分类数据集,可以自由跳过。但如果你从未训练过神经网络,本章可能对你来说有一些惊喜。
本章非常实用,旨在让你很快就能玩起来,我们将尽可能跳过理论,学习如何以高精度识别由单个数字组成的手写数字。我们在这里所做以及更多内容的理论将在下一章中介绍。
我们将涵盖以下主题:
-
机器学习
-
神经网络及其参数
-
卷积神经网络
-
Keras,一个深度学习框架
-
MNIST 数据集
-
如何构建和训练神经网络
-
CIFAR-10 数据集
技术要求
对于本章中的说明和代码,你需要以下内容:
-
Python 3.7
-
NumPy
-
Matplotlib
-
TensorFlow
-
Keras
-
OpenCV-Python 模块
-
一个 GPU(推荐)
本书代码可以在以下位置找到:
github.com/PacktPublishing/Hands-On-Vision-and-Behavior-for-Self-Driving-Cars/tree/master/Chapter4
本章的“代码实战”视频可以在以下位置找到:
理解机器学习和神经网络
根据维基百科,机器学习是“通过经验自动改进的计算机算法的研究。”
实际上,至少对我们来说,这意味着算法本身的重要性只是适度的,而关键的是我们提供给这个算法的数据,以便它能够学习:我们需要训练我们的算法。换一种说法,只要我们为当前任务提供适当的数据,我们就可以在许多不同的情况下使用相同的算法。
例如,在本章中,我们将开发一个能够识别 0 到 9 之间手写数字的神经网络;很可能,完全相同的神经网络可以用来识别 10 个字母,并且通过微小的修改,它可以识别所有字母或甚至不同的对象。实际上,我们将基本上以原样重用它来识别 10 个对象。
这与常规编程完全不同,在常规编程中,不同的任务通常需要不同的代码;为了改进结果,我们需要改进代码,而且我们可能根本不需要数据来使算法可用(使用真实数据)。
话虽如此,这并不意味着只要输入好的数据,神经网络的结果就总是好的:困难的任务需要更高级的神经网络才能表现良好。
为了明确起见,虽然算法(即神经网络模型)在传统编程中不如代码重要,但如果想要获得非常好的结果,它仍然很重要。事实上,如果架构错误,你的神经网络可能根本无法学习。
神经网络只是你可以用来开发机器学习模型的各种工具之一,但这是我们将会关注的。深度学习的准确性通常相当高,你可能会发现,在那些使用不太精确的机器学习技术的应用中,数据量和处理成本有很大的限制。
深度学习可以被认为是机器学习的一个子集,其中的计算由多个计算层执行,这是名称中的“深度”部分。从实际的角度来看,深度学习是通过神经网络实现的。
这引出了一个问题:神经网络究竟是什么?
神经网络
神经网络在一定程度上受到我们大脑的启发:我们大脑中的神经元是一个“计算节点”,它连接到其他神经元。在执行计算时,我们大脑中的每个神经元“感知”它所连接的神经元的兴奋状态,并使用这些外部状态来计算它自己的状态。神经网络中的神经元(感知器)基本上做的是同样的,但这里的相似之处到此为止。为了明确起见,感知器不是神经元的模拟,但它只是受到了启发。
以下是一个小型神经网络,其中包含其神经元:
图 4.1 – 一个神经网络
第一层是输入(例如,图像的像素)和输出层是结果(例如,分类)。隐藏层是计算发生的地方。通常,你会有更多的隐藏层,而不仅仅是单个。每个输入也可以称为特征,在 RGB 图像的情况下,特征通常是像素的单个通道。
在前馈神经网络中,一个层的神经元只与前一层的神经元和下一层的神经元连接:
图 4.2 – 一个神经网络
但神经元究竟是什么?
神经元
神经元是一个计算节点,它根据某些输入产生输出。至于这些输入和输出是什么——嗯,这取决于。我们稍后会回到这个点。
以下是一个神经网络中典型神经元的表示:
图 4.3 – 神经网络中单个神经元的示意图。©2016 Wikimedia Commons
这需要一些解释。神经元执行的计算可以分为两部分:
- 转换函数计算每个输入乘以其权重的总和(只是一个数字);这意味着神经元的状况取决于其输入神经元的状况,但不同的神经元提供不同的贡献。这仅仅是一个线性操作:
- 激活函数应用于转换函数的结果,并且它应该是一个非线性操作,通常有一个阈值。由于性能出色,我们将经常使用的一个函数被称为修正线性单元(ReLU)。
图 4.4 – 两种激活函数:Softplus 和 ReLU
通常还有一个偏差,这是一个用于移动激活函数的值。
线性函数与非线性函数的组合是非线性的,而两个线性函数的组合仍然是线性的。这一点非常重要,因为它意味着如果激活是线性的,那么神经元的输出将是线性的,不同层的组合也将是线性的。因此,整个神经网络将是线性的,因此等同于单层。
在激活函数中引入非线性操作,使得网络能够计算越来越复杂的非线性函数,随着层数的增加,这些函数变得越来越复杂。这是最复杂的神经网络实际上可以有数百层的原因之一。
参数
偏差和权重被称为参数,因为它们不是固定的,需要根据任务进行调整。我们在训练阶段进行这一操作。为了明确起见,训练阶段的整个目的就是为我们的任务找到这些参数的最佳可能值。
这具有深远的影响,因为它意味着同一个神经网络,具有不同的参数,可以解决不同的问题——非常不同的问题。当然,技巧是找到这些参数的最佳值(或一个近似值)。如果你想知道一个典型的神经网络可以有多少参数,答案是数百万。幸运的是,这个过程,即训练,可以自动化。
想象神经网络的一个替代方法是将其视为一个庞大的方程组系统,而训练阶段则是一个尝试找到其近似解的过程。
深度学习的成功
你可能已经注意到,深度学习在过去几年中经历了爆炸性的增长,但神经网络实际上并不是什么新鲜事物。我记得在阅读了一本关于神经网络的书之后,我尝试编写一个神经网络(并且失败得很惨!)那是在 20 多年前。事实上,它们可以追溯到 1965 年,有些理论甚至比那还要早 20 年。
多年前,它们基本上被当作一种好奇心,因为它们计算量太大,不实用。
然而,快进几十年,深度学习成为了新的热门领域,这得益于一些关键性的进步:
-
计算机运行得更快,并且有更多的 RAM 可用。
-
可以使用 GPU 来使计算更快。
-
现在互联网上有许多数据集可以轻松用于训练神经网络。
-
现在互联网上有许多教程和在线课程专门介绍深度学习。
-
现在有多个优秀的开源库用于神经网络。
-
架构已经变得更加优秀和高效。
这正是使神经网络更具吸引力的完美风暴,而且有许多应用似乎都在等待深度学习,例如语音助手和当然,自动驾驶汽车。
有一种特殊的神经网络特别擅长理解图像内容,我们将特别关注它们:卷积神经网络。
学习卷积神经网络
如果你观察一个经典的神经网络,你可以看到第一层由输入组成,它们排列成一行。这不仅是一个图形表示:对于一个经典神经网络来说,输入是输入,它应该独立于其他输入。如果你试图根据大小、ZIP 代码和楼层号预测公寓的价格,这可能没问题,但对于图像来说,像素有邻居,保持这种邻近信息似乎很直观。
卷积神经网络(CNNs)正好解决了这个问题,结果发现它们不仅能够高效地处理图像,而且还可以成功应用于自然语言处理。
CNN 是一种至少包含一个卷积层的神经网络,它受到动物视觉皮层的启发,其中单个神经元只对视野中一个小区域内的刺激做出反应。让我们看看卷积究竟是什么。
卷积
卷积基于核的概念,这是一个应用于某些像素以得到单个新像素的矩阵。核可以用于边缘检测或对图像应用过滤器,并且如果你愿意,你通常可以在图像处理程序中定义你的核。以下是一个 3x3 的单位核,它以原样复制图像,并且我们正在将其应用于一个小图像:
图 4.5 – 图像的一部分、一个 3x3 的单位核以及结果
想象一下,在每个核的元素后面放置一个像素,并将它们相乘,然后将结果相加以得到新像素的值;显然,除了中央像素外,其他所有像素都会得到零,中央像素保持不变。这个核保留了中间像素的值,丢弃了所有其他像素。如果你将这个卷积核在整个图片上滑动,你会得到原始图像:
图 4.6 – 单位卷积 – 只复制图像
你可以看到,当卷积核在图像上滑动时,像素保持不变地复制。你还可以看到分辨率降低了,因为我们使用了 valid 填充。
这是另一个例子:
图 4.7 – 图像的一部分、3x3 的核和结果
其他核可能比恒等核更有趣。下面的核(在左侧)可以检测边缘,如右侧所示:
图 4.8 – 核检测边缘
如果你对核感兴趣,请继续使用 OpenCV 并享受乐趣:
img = cv2.imread("test.jpg")kernel = np.array(([-1, -1, -1], [-1, 8, -1], [-1, -1, -1]))dst = cv2.filter2D(img,-1,kernel)cv2.imshow("Kernel", cv2.hconcat([img, dst]))cv2.waitKey(0)
核不需要是 3x3 的;它们可以更大。
如果你想象从图像的第一个像素开始,你可能会问那时会发生什么,因为上面或左边没有像素。如果你将核的左上角放在图像的左上像素上,图像的每一边都会丢失一个像素,因为你可以将它想象成核从中心发射出一个像素。这并不总是一个问题,因为在设计神经网络时,你可能希望图像在每一层之后都变得越来越小。
另一个选择是使用填充 – 例如,假装图像周围有黑色像素。
好消息是,你不需要找到核的值;CNN 会在训练阶段为你找到它们。
为什么卷积如此出色?
卷积有一些显著的优势。正如我们之前所说,它们保留了像素的邻近性:
图 4.9 – 黄色的卷积层与绿色的密集层
如前图所示,卷积知道图像的拓扑结构,例如,它可以知道像素 43 正好位于像素 42 的旁边,位于像素 33 的下方,位于像素 53 的上方。同一图中的密集层没有这个信息,可能会认为像素 43 和像素 51 相近。不仅如此,它甚至不知道分辨率是 3x3、9x1 还是 1x9。直观地了解像素的拓扑结构是一个优势。
另一个重要的优势是它们在计算上效率很高。
卷积的另一个显著特点是它们非常擅长识别模式,例如对角线或圆形。你可能会说它们只能在较小的尺度上做到这一点,这是真的,但你可以组合多个卷积来检测不同尺度的模式,并且它们在这方面可以出奇地好。
它们也能够检测图像不同部分的模式。
所有这些特性使它们非常适合处理图像,并且它们在目标检测中被广泛使用并不令人惊讶。
现在理论部分就到这里。让我们动手写我们的第一个神经网络。
开始使用 Keras 和 TensorFlow
有许多库专门用于深度学习,我们将使用 Keras,这是一个使用多个后端的 Python 库;我们将使用 TensorFlow 作为后端。虽然代码是针对 Keras 的,但原则可以应用于任何其他库。
要求
在开始之前,你需要至少安装 TensorFlow 和 Keras,使用pip:
pip install tensorflow
pip install keras
我们正在使用 TensorFlow 2.2,它集成了 GPU 支持,但如果你使用的是 TensorFlow 版本 1.15 或更早版本,你需要安装一个单独的包来利用 GPU:
pip install tensorflow-gpu
我建议使用 TensorFlow 和 Keras 的最新版本。
在开始之前,让我们确保一切就绪。你可能想使用 GPU 来加速训练。不幸的是,让 TensorFlow 使用你的 GPU 并不一定简单;例如,它对 CUDA 的版本非常挑剔:如果它说 CUDA 10.1,那么它确实意味着它——它不会与 10.0 或 10.2 兼容。希望这不会对你的游戏造成太大影响。
要打印 TensorFlow 的版本,可以使用以下代码:
import tensorflow as tf
print("TensorFlow:", tf.__version__)
print("TensorFlow Git:", tf.version.GIT_VERSION)
在我的电脑上,它会打印出以下内容:
TensorFlow: 2.1.0
TensorFlow Git: v2.1.0-rc2-17-ge5bf8de410
要检查 GPU 支持,可以使用以下代码:
print("CUDA ON" if tf.test.is_built_with_cuda() else "CUDA OFF")print("GPU ON" if tf.test.is_gpu_available() else "GPU OFF")
如果一切正常,你应该看到CUDA ON,这意味着你的 TensorFlow 版本已经集成了 CUDA 支持,以及GPU ON,这意味着 TensorFlow 能够使用你的 GPU。
如果你的 GPU 不是 NVIDIA,可能需要更多的工作,但应该可以配置 TensorFlow 在 AMD 显卡上运行,使用 ROCm。
现在你已经正确安装了所有软件,是时候在我们的第一个神经网络上使用了。我们的第一个任务将是使用名为 MNIST 的数据集来识别手写数字。
检测 MNIST 手写数字
当你设计神经网络时,你通常从一个你想要解决的问题开始,你可能从一个已知在类似任务上表现良好的设计开始。你需要一个数据集,基本上是你能得到的尽可能大的数据集。在这方面没有真正的规则,但我们可以这样说,训练你自己的神经网络可能至少需要大约 3000 张图片,但如今,世界级的 CNNs 是使用数百万张图片进行训练的。
我们的首要任务是检测手写数字,这是 CNNs 的经典任务。为此有一个数据集,即 MNIST 数据集(版权属于 Yann LeCun 和 Corinna Cortes),并且它方便地存在于 Keras 中。MNIST 检测是一个简单的任务,因此我们将取得良好的结果。
加载数据集很容易:
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = np.reshape(x_train, np.append(x_train.shape, (1)))
x_test = np.reshape(x_test, np.append(x_test.shape, (1)))
reshape只是将形状从(60000, 28, 28)重新解释为(60000, 28, 28, 1),因为 Keras 需要四个维度。
我们刚刚加载了什么?
load_data()方法返回四个东西:
-
x_train:用于训练的图像 -
y_train:用于训练的标签(即每个手写数字的正确数字) -
x_test:用于测试的图像 -
y_test:用于测试的标签(即每个手写数字的正确数字)
训练样本和标签
让我们打印训练样本(x)和标签(y)的维度:
print('X Train', x_train.shape, ' - X Test', x_test.shape)print('Y Train', y_train.shape, ' - Y Test', y_test.shape)
应该打印出类似以下内容:
X Train (60000, 28, 28, 1) - X Test (10000, 28, 28, 1)Y Train (60000,) - Y Test (10000,)
x 变量代表 CNN 的输入,这意味着 x 包含所有我们的图像,分为两个集合,一个用于训练,一个用于测试:
-
x_train包含 60,000 张用于训练的图像,每张图像有 28x28 像素,为灰度图(一个通道)。 -
x_test包含 10,000 张用于测试的图像,每张图像有 28x28 像素,为灰度图(一个通道)。
如你所见,训练和测试图像具有相同的分辨率和相同数量的通道。
y 变量代表 CNN 的预期输出,也称为标签。对于许多数据集,有人手动标记所有图像以说明它们是什么。如果数据集是人工的,标记可能是自动化的:
-
y_train由 60,000 个属于 10 个类别的数字组成,从 0 到 9。 -
y_test由 10,000 个属于 10 个类别的数字组成,从 0 到 9。
对于每张图像,我们都有一个标签。
通常来说,一个神经网络可以有多个输出,每个输出都是一个数字。在分类任务的情况下,例如 MNIST,输出是一个单独的整数。在这种情况下,我们特别幸运,因为输出值实际上是我们感兴趣的数字(例如,0 表示数字 0,1 表示数字 1)。通常,你需要将数字转换为标签(例如,0 -> 猫,1 -> 狗,2 -> 鸭)。
严格来说,我们的 CNN 不会输出一个从 0 到 9 的整数结果,而是 10 个浮点数,最高值的位置将是标签(例如,如果位置 3 的输出是最高值,则输出将是 3)。我们将在下一章中进一步讨论这个问题。
为了更好地理解 MNIST,让我们看看训练数据集和测试数据集的五个样本:
图 4.10 – MNIST 训练和测试数据集样本。版权属于 Yann LeCun 和 Corinna Cortes
如你所料,这些图像的对应标签如下:
-
训练样本(
y_train)包括 5、0、4、1 和 9。 -
测试样本(
y_test)包括 7、2、1、0 和 4。
我们还应该调整样本的大小,使其范围从 0-255 变为 0-1,因为这有助于神经网络获得更好的结果:
x_train = x_train.astype('float32')x_test = x_test.astype('float32')x_train /= 255 x_test /= 255
一维编码
标签不能直接使用,需要使用one-hot encoding将其转换为向量。正如其名所示,你得到一个向量,其中只有一个元素是热的(例如,其值为1),而所有其他元素都是冷的(例如,它们的值为0)。热的元素代表标签的位置,在一个包含所有可能位置的向量中。一个例子应该会使理解更容易。
在 MINST 的情况下,你有 10 个标签:0、1、2、3、4、5、6、7、8 和 9。因此,one-hot encoding 将使用 10 个项目。这是前三个项目的编码:
-
0 ==> 1 0 0 0 0 0 0 0 0 0 -
1 ==> 0 1 0 0 0 0 0 0 0 0 -
2 ==> 0 0 1 0 0 0 0 0 0 0
如果你有三个标签,狗、猫和鱼,你的 one-hot encoding 将如下所示:
-
Dog ==> 1 0 0 -
Cat ==> 0 1 0 -
Fish ==> 0 0 1
Keras 提供了一个方便的函数来处理这个问题,to_categorical(),它接受要转换的标签列表和标签总数:
print("One hot encoding: ", keras.utils.to_categorical([0, 1, 2], 10))
如果你的标签不是数字,你可以使用index()来获取指定标签的索引,并使用它来调用to_categorical():
labels = ['Dog', 'Cat', 'Fish']
print("One hot encoding 'Cat': ", keras.utils.to_categorical(labels.index('Cat'), 10))
训练和测试数据集
x变量包含图像,但为什么我们既有x_train又有x_test?
我们将在下一章中详细解释一切,但到目前为止,我们只能说 Keras 需要两个数据集:一个用于训练神经网络,另一个用于调整超参数以及评估神经网络的性能。
这有点像有一个老师先向你解释事情,然后质问你,分析你的答案来更好地解释你没有理解的部分。
定义神经网络模型
现在我们想编写我们的神经网络,我们可以称之为我们的模型,并对其进行训练。我们知道它应该使用卷积,但我们对此了解不多。让我们从一位古老但非常有影响力的 CNN:LeNet中汲取灵感。
LeNet
LeNet 是第一个 CNN 之一。追溯到 1998 年,对于今天的标准来说,它相当小且简单。但对于这个任务来说已经足够了。
这是它的架构:
图 4.11 – LeNet
LeNet 接受 32x32 像素的图像,并具有以下层:
-
第一层由六个 5x5 卷积组成,输出 28x28 像素的图像。
-
第二层对图像进行子采样(例如,计算四个像素的平均值),输出 14x14 像素的图像。
-
第三层由 16 个 5x5 卷积组成,输出 10x10 像素的图像。
-
第四层对图像进行子采样(例如,计算四个像素的平均值),输出 5x5 像素的图像。
-
第五层是一个包含 120 个神经元的全连接密集层(即,前一层中的所有神经元都连接到这一层的所有神经元)。
-
第六层是一个包含 84 个神经元的全连接密集层。
-
第七个也是最后一个层是输出,一个包含 10 个神经元的完全连接的密集层,因为我们需要将图像分类为 10 个类别,对应于 10 个数字。
我们并不是试图精确地重现 LeNet,我们的输入图像略小一些,但我们会将其作为参考。
代码
第一步是定义我们正在创建哪种类型的神经网络,在 Keras 中通常是Sequential:
model = Sequential()
现在我们可以添加第一个卷积层:
model.add(Conv2D(filters=6, kernel_size=(5, 5),
activation='relu', padding='same',
input_shape=x_train.shape[1:]))
它接受以下参数:
-
六个过滤器,因此我们将得到六个核,这意味着六个卷积。
-
核大小 5x5。
-
ReLU 激活。
-
使用
same填充(例如,在图像周围使用黑色像素),以避免过早地大幅度减小图像大小,并更接近 LeNet。 -
input_shape包含图像的形状。
然后,我们添加了使用最大池化(默认大小=2x2)的子采样,它输出具有最大激活(例如,最大值)的像素值:
model.add(MaxPooling2D())
然后,我们可以添加下一个卷积层和下一个最大池化层:
model.add(Conv2D(filters=16, kernel_size=(5,5), activation='relu'))
model.add(MaxPooling2D())
然后我们可以添加密集层:
model.add(Flatten())model.add(Dense(units=120, activation='relu'))model.add(Dense(units=84, activation='relu'))model.add(Dense(units=num_classes, activation='softmax'))
Flatten()用于将卷积层的 2D 输出展平为单行输出(1D),这是密集层所需的。为了清楚起见,对于我们的用例,卷积滤波器的输入是一个灰度图像,输出也是另一个灰度图像。
最后的激活,softmax,将预测转换为概率,以便方便起见,并且具有最高概率的输出将代表神经网络与图像关联的标签。
就这样:仅仅几行代码就能构建一个能够识别手写数字的 CNN。我挑战你不用机器学习来做同样的事情!
架构
即使我们的模型定义非常直接,可视化它并查看例如维度是否符合预期也是有用的。
Keras 有一个非常有用的函数用于此目的——summary():
model.summary()
这是结果:
_______________________________________________________________
Layer (type) Output Shape Param #
===============================================================
conv2d_1 (Conv2D) (None, 28, 28, 6) 156
_______________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 6) 0
_______________________________________________________________
conv2d_2 (Conv2D) (None, 10, 10, 16) 2416
_______________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 5, 5, 16) 0
_______________________________________________________________
flatten_1 (Flatten) (None, 400) 0
_______________________________________________________________
dense_1 (Dense) (None, 120) 48120
_______________________________________________________________
dense_2 (Dense) (None, 84) 10164
_______________________________________________________________
dense_3 (Dense) (None, 10) 850
===============================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0
这非常有趣。首先,我们可以看到卷积层的输出维度与 LeNet 相同:28x28 和 10x10。这并不一定很重要;它只是意味着网络的设计符合我们的预期。
我们还可以看到层的顺序是正确的。有趣的是每行的第三个值:参数数量。参数是神经网络需要确定以实际学习某些东西的变量。它们是我们庞大方程系统中的变量。
在全连接密集层的情况下,参数的数量是通过将前一层神经元的数量乘以一,再加上当前层神经元的数量来获得的。如果您还记得神经元的图像,每个神经元都有一个与之相连的权重,所以对于每个神经元都是一个可训练的参数来说,这是很直观的。此外,还有一个用于激活阈值(偏置)的参数。因此,在最后一层,我们有以下内容:
-
84 个输入 ==> 84 个权重 + 1 个偏置 ==> 85 个参数
-
10 个输出
-
85 x 10 ==> 850 个参数
在卷积层的情况下,参数的数量由核的面积加一以及激活的偏置给出。在第一层,我们有以下内容:
-
5x5 核 ==> 25 + 1 个偏置 ==> 26 个参数
-
6 个过滤器
-
26 x 6 ==> 156 个参数
如您所见,我们的网络有 61,706 个参数。虽然这看起来可能很多,但对于神经网络来说,拥有数百万个参数并不罕见。它们如何影响训练?作为一个初步的近似,我们可以这样说,拥有更多的参数使我们的网络能够学习更多的事物,但同时也减慢了它的速度,增加了模型的大小以及它使用的内存量。不要对参数的数量过于着迷,因为并非所有参数都是相同的,但要注意它们,以防某些层使用了过多的参数。您可以看到,密集层倾向于使用许多参数,在我们的例子中,它们占据了超过 95%的参数。
训练神经网络
现在我们已经拥有了我们的神经网络,我们需要对其进行训练。我们将在下一章中更多地讨论训练,但正如其名所示,训练是神经网络学习训练数据集并真正学习它的阶段。至于它学习得有多好——这取决于。
为了快速解释概念,我们将与学生试图为了考试学习一本书的不当比较:
-
这本书是学生需要学习的学习数据集。
-
每次学生阅读整本书都称为一个 epoch。学生可能想要多次阅读这本书,对于神经网络来说,做同样的事情并训练超过一个 epoch 是非常常见的。
-
优化器就像一个人从练习册(验证数据集;尽管在我们的例子中,我们将使用测试数据集进行验证)中提问学生,以查看学生学习得有多好。一个关键的区别是,神经网络不会从验证数据集中学习。我们将在下一章中看到为什么这是非常好的。
-
为了跟踪他们的进度并在更短的时间内学习,学生可以要求优化器在阅读一定数量的页面后提问;这个页数就是批大小。
首件事是配置模型,使用compile():
model.compile(loss=categorical_crossentropy, optimizer=Adam(), metrics=['accuracy'])
Keras 有多种损失函数可供使用。loss基本上是衡量你的模型结果与理想输出之间距离的度量。对于分类任务,我们可以使用categorical_crossentropy作为损失函数。optimizer是用于训练神经网络的算法。如果你把神经网络想象成一个巨大的方程组系统,那么优化器就是那个找出如何改变参数以改进结果的人。我们将使用metrics,这只是训练期间计算的一些值,但它们不是由优化器使用的;它们只是作为参考提供给你。
我们现在可以开始训练,这可能需要几分钟,并且会打印出正在进行的进度:
history = model.fit(x_train, y_train, batch_size=16, epochs=5, validation_data=(x_test, y_test), shuffle=True)
我们需要提供几个参数:
-
x_train:训练图像。 -
y_train:训练标签。 -
batch_size:默认值是 32,通常尝试从 16 到 256 的 2 的幂次方是值得的;批处理大小会影响速度和准确性。 -
epochs:CNN 将遍历数据集的次数。 -
validation_data:正如我们之前所说的,我们正在使用测试数据集进行验证。 -
shuffle:如果我们想在每个 epoch 之前打乱训练数据,这通常是我们想要的。
训练的结果是history,它包含了很多有用的信息:
print("Min Loss:", min(history.history['loss']))
print("Min Val. Loss:", min(history.history['val_loss']))
print("Max Accuracy:", max(history.history['accuracy']))
print("Max Val. Accuracy:", max(history.history['val_accuracy']))
我们在讨论最小值和最大值,因为这些值是在每个 epoch 期间测量的,并不一定总是朝着改进的方向前进。
让我们来看看我们这里有什么:
-
最小损失是衡量我们接近训练数据集中理想输出的程度,或者神经网络学习训练数据集的好坏的度量。一般来说,我们希望这个值尽可能小。
-
最小验证损失是我们接近验证数据集中理想输出的程度,或者神经网络在训练后使用验证数据集所能做到的多好。这可能是最重要的值,因为这是我们试图最小化的,所以我们希望这个值尽可能小。
-
最大准确率是我们 CNN 使用训练数据集所能给出的最大正确答案(预测)百分比。对于之前的学生示例,它将告诉他们他们记住了书本的程度。仅仅记住书本本身并不坏——实际上这是可取的——但目标不是记住书本,而是从中学习。虽然我们希望这个值尽可能高,但它可能会误导。
-
最大验证准确率是我们 CNN 使用验证数据集所能给出的最大正确答案(预测)百分比。对于之前的学生示例,它将告诉他们他们实际上学到了书本内容的程度,以便他们可以回答书中可能没有的问题。这将是我们神经网络在实际生活中表现如何的一个指标。
这是我们的 CNN 的结果:
Min Loss: 0.054635716760404344
Min Validation Loss: 0.05480437679834067
Max Accuracy: 0.9842833
Max Validation Accuracy: 0.9835000038146973
在你的电脑上,它可能略有不同,实际上每次运行时都应该有所变化。
我们可以看到损失接近零,这是好的。准确率和验证准确率几乎都是 98.5%,这在一般情况下是非常好的。
我们还可以绘制这些参数随时间演变的图表:
plt.plot(history_object.history['loss'])
plt.plot(history_object.history['val_loss'])
plt.plot(history_object.history['accuracy'])
plt.plot(history_object.history['val_accuracy'])
plt.title('model mean squared error loss')
plt.ylabel('mean squared error loss')
plt.xlabel('epoch')
plt.legend(['T loss', 'V loss', 'T acc', 'V acc'], loc='upper left')
plt.show()
这是结果:
图 4.12 – MNIST 随时间变化的验证和准确率图
在第一个 epoch 之后,准确率和损失都非常良好,并且持续改进。
到目前为止一切顺利。也许你认为这很简单。但 MNIST 是一个简单的数据集。让我们尝试 CIFAR-10。
CIFAR-10
要使用 CIFAR-10,我们只需请求 Keras 使用不同的数据集:
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
CIFAR-10 是一个更困难的数据集。它包含 32x32 的 RGB 图像,包含 10 种类型的对象:
X Train (50000, 32, 32, 3) - X Test (10000, 32, 32, 3)
Y Train (50000, 1) - Y Test (10000, 1)
它看起来与 MNIST 相似。
在 GitHub 上的代码中,要使用 CIFAR 10,你只需将use_mnist变量更改为False:
use_mnist = False
你不需要在代码中做任何其他更改,除了移除reshape()调用,因为 CIFAR-10 使用 RGB 图像,因此它已经具有三个维度:宽度、高度和通道。Keras 将适应不同的维度和通道,神经网络将学习一个新的数据集!
让我们看看新的模型:
_______________________________________________________________
Layer (type) Output Shape Param #
===============================================================
conv2d_1 (Conv2D) (None, 32, 32, 6) 456
_______________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 16, 16, 6) 0
_______________________________________________________________
conv2d_2 (Conv2D) (None, 12, 12, 16) 2416
_______________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 6, 6, 16) 0
_______________________________________________________________
flatten_1 (Flatten) (None, 576) 0
_______________________________________________________________
dense_1 (Dense) (None, 120) 69240
_______________________________________________________________
dense_2 (Dense) (None, 84) 10164
_______________________________________________________________
dense_3 (Dense) (None, 10) 850
===============================================================
Total params: 83,126
Trainable params: 83,126
Non-trainable params: 0
模型稍微大一些,因为图像稍微大一些,并且是 RGB 格式。让我们看看它的表现:
Min Loss: 1.2048443819999695
Min Validation Loss: 1.2831668125152589
Max Accuracy: 0.57608
Max Validation Accuracy: 0.5572999715805054
这不是很好:损失很高,验证准确率只有大约 55%。
下一个图表非常重要,你将多次看到它,所以请花些时间熟悉一下。下面的图表显示了我们的模型在时间上每个 epoch 的损失(我们使用均方误差)和准确率的演变。在X轴上,你可以看到 epoch 的数量,然后有四条线:
-
T loss: 训练损失 -
V loss: 验证损失 -
T acc: 训练准确率 -
V acc: 验证准确率:
图 4.13 – CIFAR-10 随时间变化的验证和准确率图
我们可以看到损失正在下降,但还没有达到最小值,所以这可能意味着更多的 epochs 会有所帮助。准确率很低,并且保持低水平,可能是因为模型参数不足。
让我们看看 12 个 epochs 的结果:
Min Loss: 1.011266466407776
Min Validation Loss: 1.3062725918769837
Max Accuracy: 0.6473
Max Validation Accuracy: 0.5583999752998352
好消息:损失下降了,准确率提高了。坏消息:验证损失和验证准确率没有提高。在实践中,我们的网络已经通过心算学习了训练数据集,但它不能泛化,因此它在验证数据集上的表现不佳。
让我们尝试显著增加网络的大小:
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu', input_shape=x_train.shape[1:]))
model.add(AveragePooling2D())
model.add(Conv2D(filters=256, kernel_size=(3, 3), activation='relu'))
model.add(AveragePooling2D())
model.add(Flatten())
model.add(Dense(units=512, activation='relu'))
model.add(Dense(units=256, activation='relu'))
model.add(Dense(units=num_classes, activation = 'softmax'))
这给我们带来了这个新的模型:
_______________________________________________________________
Layer (type) Output Shape Param #
===============================================================
conv2d_1 (Conv2D) (None, 30, 30, 64) 1792
_______________________________________________________________
average_pooling2d_1 (Average (None, 15, 15, 64) 0
_______________________________________________________________
conv2d_2 (Conv2D) (None, 13, 13, 256) 147712
_______________________________________________________________
average_pooling2d_2 (Average (None, 6, 6, 256) 0
_______________________________________________________________
flatten_1 (Flatten) (None, 9216) 0
_______________________________________________________________
dense_1 (Dense) (None, 512) 4719104
_______________________________________________________________
dense_2 (Dense) (None, 256) 131328
_______________________________________________________________
dense_3 (Dense) (None, 10) 2570
===============================================================
Total params: 5,002,506
Trainable params: 5,002,506
Non-trainable params: 0
哇:我们从 83,000 个参数跳到了 5,000,000 个参数!第一个密集层变得很大…
让我们看看是否可以看到一些改进:
Min Loss: 0.23179266978245228
Min Validation Loss: 1.0802633233070373
Max Accuracy: 0.92804
Max Validation Accuracy: 0.65829998254776
现在所有值都有所提高;然而,尽管训练准确率现在超过了 90%,但验证准确率仅为 65%:
图 4.14 – CIFAR-10 验证和准确率随时间的变化图
我们看到一些令人担忧的情况:虽然训练损失随时间下降,但验证损失上升。这种情况被称为过拟合,这意味着网络不擅长泛化。这也意味着我们使用了过多的 epoch 而没有效果。
不仅于此,如果我们最后保存了模型,我们也不会保存最佳模型。如果你想知道是否有保存最佳模型(例如,只有当验证损失降低时才保存)的方法,那么答案是肯定的——Keras 可以做到:
checkpoint = ModelCheckpoint('cifar-10.h5', monitor='val_loss', mode='min', verbose=1, save_best_only=True)
这里我们告诉 Keras 执行以下操作:
-
将模型以名称
'cifar-10.h5'保存。 -
监控验证损失。
-
根据最小损失选择模型(例如,只有当验证损失降低时才保存)。
-
只保存最佳模型。
你可以将checkpoint对象传递给model.fit():
history_object = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_test, y_test), shuffle=True, callbacks=[checkpoint])
这有所帮助,但模型还不够好。我们需要一个根本性的改进。
在下一章中,我们将学习许多有望帮助我们获得更好结果的东西。此外,在第六章,提高你的神经网络中,我们将应用这些知识,以及更多,来提高结果。现在,如果你愿意,你可以花些时间尝试调整和改进网络:你可以改变其大小,添加滤波器和层,并看看它的表现如何。
摘要
这已经是一个内容丰富的章节!我们讨论了机器学习的一般概念和深度学习的特别之处。我们谈论了神经网络以及如何利用像素邻近的知识来使用卷积来创建更快、更准确的神经网络。我们学习了权重、偏差和参数,以及训练阶段的目标是优化所有这些参数以学习当前的任务。
在验证了 Keras 和 TensorFlow 的安装后,我们介绍了 MNIST,并指导 Keras 构建一个类似于 LeNet 的网络,以在数据集上实现超过 98%的准确率,这意味着我们现在可以轻松地识别手写数字。然后,我们看到同样的模型在 CIFAR-10 上表现不佳,尽管增加了 epoch 的数量和网络的大小。
在下一章中,我们将深入研究我们在这里介绍的大多数概念,最终目标是完成第六章,提高你的神经网络,学习如何训练神经网络。
问题
在阅读本章后,你应该能够回答以下问题:
-
什么是感知器?
-
你能说出一个在许多任务中表现良好的优化器吗?
-
什么是卷积?
-
什么是 CNN?
-
什么是密集层?
-
Flatten()层做什么? -
我们一直使用哪个后端进行 Keras 开发?
-
第一批卷积神经网络(CNN)的名字是什么?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}