






讨论“基于语音识别的智能电子病历”,就绕不开 Nuance 和 M*Modal。这2个公司长时间的占据第一和第二的位置。下面介绍一下M*Modal。
这是2019年的一个新闻“专业医疗软件提供商3M公司为自己购买了一份圣诞礼物,即M*Modal IP LLC的医疗技术业务,总价值为10亿美元。3M公司表示,此次收购旨在通过将M*Modal基于人工智能的医生会话软件添加到其产品组合中来推动其自身的医疗健康信息系统业务。”。实际的成交额没有这么高,最终的成交是 2.6亿美元 加 一些股份。但是这个收购,只是收购了 M*Modal 的研发团队和产品。客户和合同留给了Aquity Solutions,Aquity Solutions目前有1.4万员工。
M*Modal 是第一个大规模的把语音识别和结构化电子病历 结合起来的公司。当时 Nuance 的语音识别结果是SRT 和 IDX 文件。M*Modal 的识别结果已经是 CDA文件了(临床文档架构 Clinical Document Architecture)。

生成的CDA电子病历 能够直接编辑、发布、打印

AnyModal Publish Two components: Authoring tool for template creation Server side component Microsoft Word based conversion tool CDA DOC, DOCX, PDF, HTML, TXT, … Easy to configure using Microsoft Word 2007 for template generation Full support for MsWord formatting features Formatting templates can be maintained by account manager
接下来是一个具体的CDA 文件的例子

mm:conf的值是语音识别的质量。
mm:part的值是语音识别的时间信息。
有了语音信息,再浏览CDA时就可以做到语音跟随。
语音跟随的CDA 电子病历编辑器
CDA看上很简单,但是结合发布模板可以生成非常复杂的电子病历文档。而且 M*Modal 提供了发布模板的制作工具。
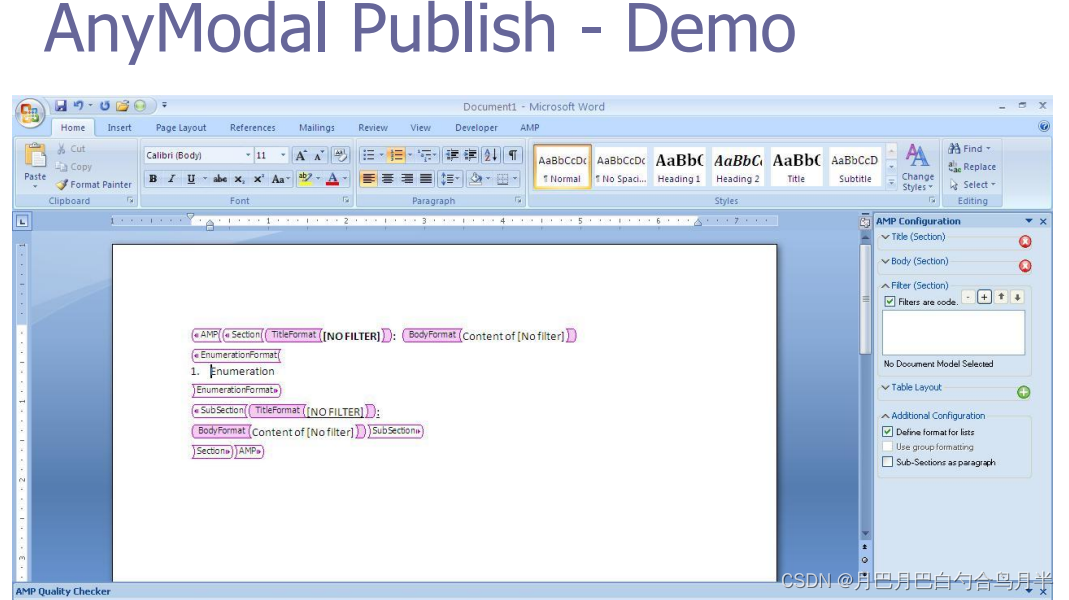
CDA文件通过发布就可以生成比较复杂的病历,例如:

另:
这是我们自研引擎的一一个文档,俺在2014-03-13写的。



















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











