



 本文介绍了医疗行业中的文档整理工作,包括“表”、“单”、“书”和“卷”的概念。重点讲述了如何将病人的各类医疗文档,如病历、保险单等,整理成结构化的PDF文件,该文件包含可点击的目录、统计信息和专业摘要。内容涉及文档的多样性和复杂性,以及自动化和人工整理的结合。此外,还提到了相关项目的规模,每月处理大量页面,并强调了摘要部分的价值。
本文介绍了医疗行业中的文档整理工作,包括“表”、“单”、“书”和“卷”的概念。重点讲述了如何将病人的各类医疗文档,如病历、保险单等,整理成结构化的PDF文件,该文件包含可点击的目录、统计信息和专业摘要。内容涉及文档的多样性和复杂性,以及自动化和人工整理的结合。此外,还提到了相关项目的规模,每月处理大量页面,并强调了摘要部分的价值。
在开发的工程中,总会遇到一些“打印、报表和文档”的需求。俺就整理了一下:。
从输出的内容来看,常见的有“表”,“单”,“书”,“卷”等:
- “表”: “表”指各种表格,复杂的有“表中有表”。就是格子里又是个子表格。不同的字段数据,套的子表格也不一样。设计上一般是用一个或者多个子报表实现的。
- “单”: “单”的特点是数据项比较多,这么多的数据项都关联到一个人或者一件事上。例如:保险单,体检结果,病案首页,学籍档案。有些“单”虽然叫做“单”其实和“表”比较类似,例如:“入库单”,“报销单”。另外,有些“单”会要求“套打”。
- “书”: “书”和“单”的不同点在于,“书”在内容上更多,像是一个文档。有些有几十页。例如:手术报告,体检报告。
- “卷”: “卷”往往是把各种的内容综合在一起,有些前面还有目录,往往非常多的页。前段时间,俺处理过一个病人的一个文档(打官司用的),7万8千页。前面的目录就是30多页。里面啥都有,车祸现场的图就有几十张。不可理解的是里面还有一个洗发水的说明。俺也不知道为啥有。还有病历,医嘱等等。
这里聊一下“书”和“卷”,这两个其实差别不大,就是大小不同。俺以前做过《笔迹鉴定书》,前面一部分是 案情、检材,然后是笔迹比对表,然后是结论。主要就是这几部分。每部分有若干页。另外对格式要求比较细,例如封面的布局,不同内容文字的字体,编号、版本号、页眉页脚的内容都有标准。
下面俺讲一下俺做过的一个医疗行业的项目。项目的背景是这样的:每个病人在医院里会有很多很多文档,例如:病历、保险单、注意事项、营养计划、付费记录、影像资料、护理记录等等,啥内容都有。当病人需要打官司或者有其他的用途时,就需要把这些内容整理好,形成一个PDF文件。这个PDF的文件前面是个目录:

这个目录的每个章节是可以点击的,点击后会跳转到相应的页。
这个PDF的内容由三部分组成
一、相关的文件。有docx,有pdf,有拍照图片,有文本,有传真,有邮件等等,然后把这些文件中的内容,梳理到不同的目录中去,按照不同的Case,排好顺序。这是个费力的活。有时一个病人的数据,需要人工整理一个星期或更多的时间,缺少内容时需要在再补充。然后一页一页的分目录,有些内容可能关联到多个目录。(俺们有个 1200人团队,就是干这个活的,俺写的程序就是为了方便他们更快捷的处理这个事情的。因为这个服务是按照页数收取客户的服务费的)。这里面包含的可能是一个“说明彩页”:

也可能是一个“车子的后屁股”

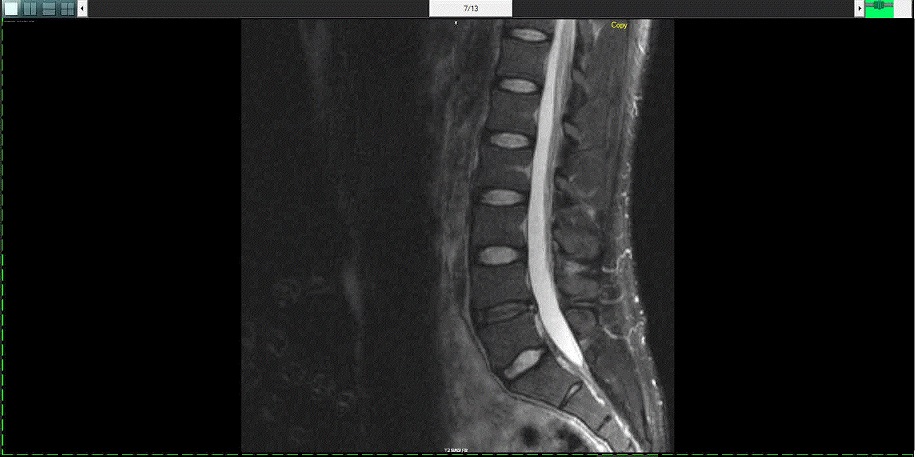
也可能是个“医疗影像”
反正啥内容都有。
二、统计信息。这个是程序自动生成的,例如下面这个就是统计这个病人那些天到过医院。

三、摘要。这部分最值钱(也是按照页数收费的,但是每页比较贵),是由专业人士看了上面的内容编写的。
然后就是把这些内容和目录一起生成PDF。一般每个病人也就是几百页,个别的过万页。现在每个月大约处理2000多万页。


















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











