



 在进行数据分析时,检查数据的分组合理性至关重要。通过使用欧氏距离的聚类图和主成分分析(PCA)图,可以评估样本之间的差异。若聚类结果未能有效区分群体,可能表明个体间的差异大于处理后的差异。PCA图则有助于理解变量间的关系及样本的分布。使用`hclust`和`PCA`函数进行聚类和降维,并通过`fviz_pca_ind`展示结果,以便于分析和解释数据。
在进行数据分析时,检查数据的分组合理性至关重要。通过使用欧氏距离的聚类图和主成分分析(PCA)图,可以评估样本之间的差异。若聚类结果未能有效区分群体,可能表明个体间的差异大于处理后的差异。PCA图则有助于理解变量间的关系及样本的分布。使用`hclust`和`PCA`函数进行聚类和降维,并通过`fviz_pca_ind`展示结果,以便于分析和解释数据。
写在前面
帮忙处理数据时,拿到数据第一件事就是看下所谓之前的分组是不是合理的有效,如果不合理有效又应该如何呢?这是一个非常重要的问题。
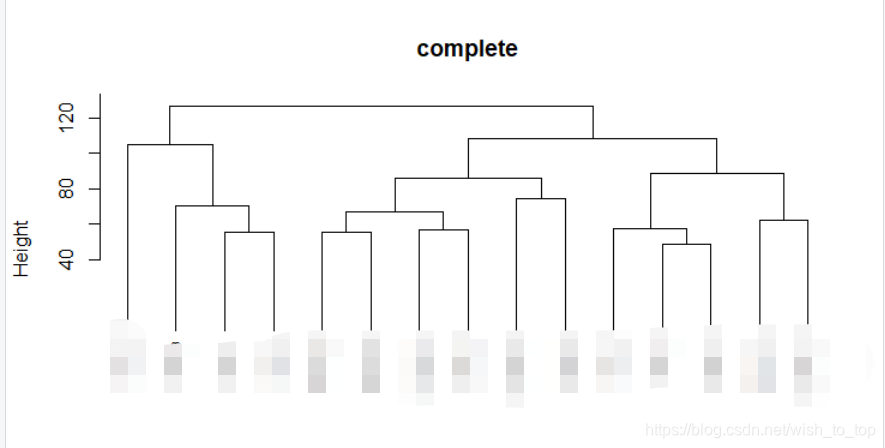
聚类图
d <- dist(t(logCPM), method = "euclidean")
# 聚类,类之间还是没有分开,这个说明了什么问题,这个说明的是个体的差异比加药后的差异大
# for 循环批量计算聚类并绘图
for (i in c("complete","average","ward.D")) {
hc1 <- hclust(d, method = i)
plot(hc1, cex = 0.6, hang = -1,main = i)
}
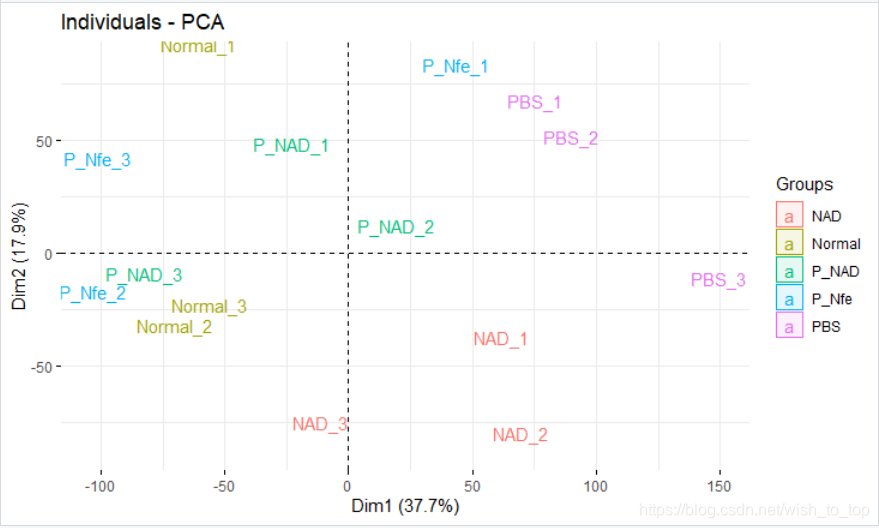
PCA图
dat=as.data.frame(t(logCPM)) # 画PCA图时要求是行名时样本名,列名时探针名,因此此时需要转换。格式要求data.frame
library("FactoMineR")# 计算PCA
library("factoextra")# 画图展示
dat.pca <- PCA(dat, graph = F)
# fviz_pca_ind按样本 fviz_pca_var按基因
fviz_pca_ind(dat.pca,
geom.ind = "text", # c("point", "text)2选1
col.ind = group_list, # color by groups
# palette = c("#00AFBB", "#E7B800"),# 自定义颜色
addEllipses = T, # 加圆圈
legend.title = "Groups"# 图例名称
)

















 8216
8216

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









