



用python 写了一个输入框对话的机器人,效果如下:
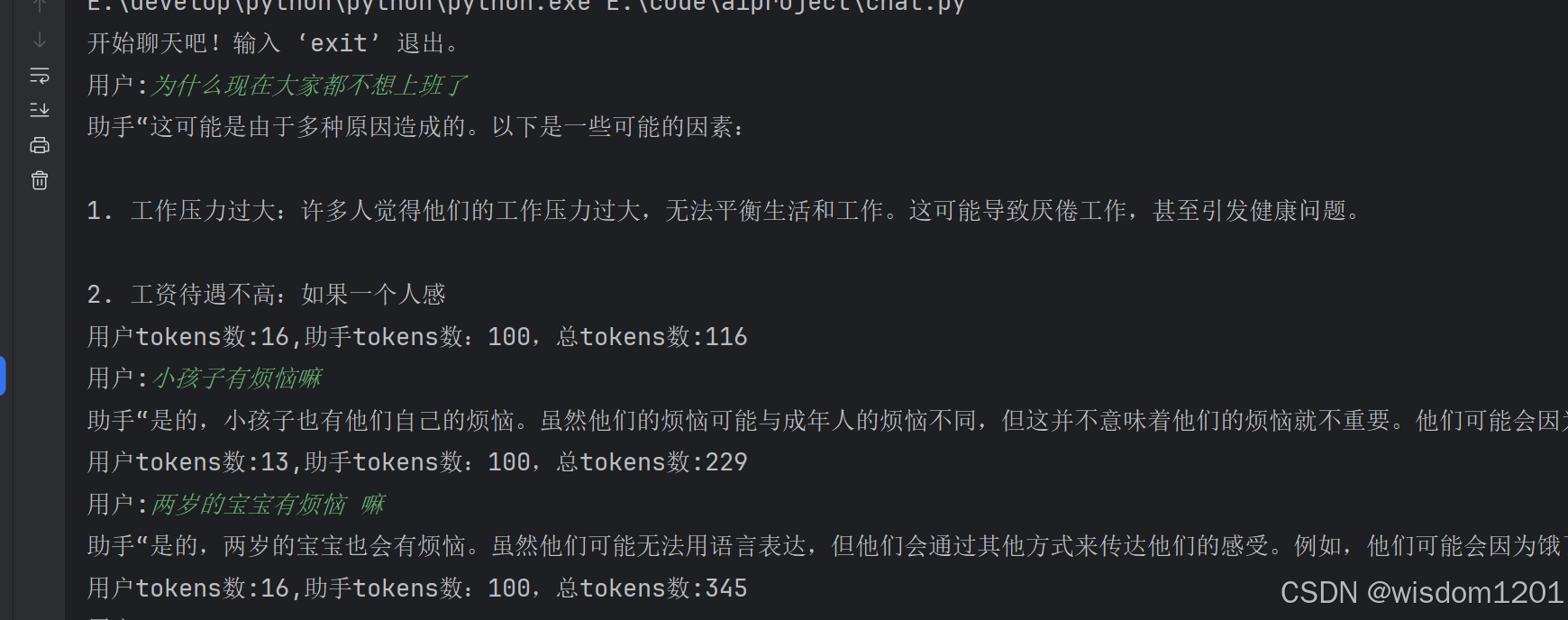
我问的问题是不是很搞笑 哈哈
记录下代码吧
from openai import OpenAI
import tiktoken
from pyexpat.errors import messages
client = OpenAI()
encoder = tiktoken.encoding_for_model("gpt-4")
def count_token(text):
encoder.encode(text)
#将输入的文本text 转换为对应的token列表。具体来说,它使用tiktoken库中的编码器将文本进行编码,方便以后进行处理
tokens = encoder.encode(text)
# 统计文本中的token 数量
return len(tokens)
def main():
# 初始化聊天记录
messages = [{"role":"system","content":"You are a helpful assistant"}]
print("开始聊天吧!输入 ‘exit’ 退出。")
total_tokens = 0
while True:
# 获取用户输入
user_input = input("用户:")
if user_input.lower() == "exit":
break
messages.append({"role":"system","content":user_input})
user_tokens = count_token(user_input)
total_tokens += user_tokens
# 调用GPT-4 模型
response = client.chat.completions.create(
model="gpt-4",
messages=messages,
max_tokens=1000,
temperature=0.7,
top_p=1,
n=1
)
# 获取助手的回复
assistant_message = response.choices[0].message.content.strip()
# 添加助手的回复到聊天记录
messages.append({"role":"system","content":assistant_message})
# 统计助手回复的token 数量并累加
messages.append({"role":"system","content":assistant_message})
assistant_tokens = count_token(assistant_message)
total_tokens += assistant_tokens
# 输出用户输入和助手的回复
print(f"助手“{assistant_message}")
# 输出当前聊天记录的总 token 数量
print(f"用户tokens数:{user_tokens},助手tokens数:{assistant_tokens},总tokens数:{total_tokens}")
if __name__ == "__main__":
main()
很简单,直接执行python 文件即可执行

















 2554
2554

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









