




实验内容
- 导出账单信息(半年以上.csv)
- 信息清洗与预处理
- 隐私信息请注意脱敏
- 按【要求】用R语言编程处理
- 统计与分析
- R语言图像处理
实验要求
- 要求1:半年以上分月份消费总额折线图
- 要求2:针对单次交易金额重新编码,新建一列并输出小额消费(<10)、一般消费(10~1000)、高消费(>1000)
- 要求3:利用交易分类频次数统计&交易金额重新编码生成列联表
- 要求4:交易分类频次数统计数据饼图,要求包含百分占比图例
- 要求5:针对交易时间重新编码(例如上午、下午和晚上),与交易分类频次及交易类别(收入或支出)形成复杂条图
- 要求6:对交易金额进行排序,观测最大额的十比交易,输出交易信息
- 要求7:自定义函数,利用循环及判定逻辑实现计算一般消费以上(>10元)的交易额总数、均值、标准差的计算
实验步骤
安装R语言编程工具
这个比较简单,这里不多赘述。
导出账单信息
从微信导出账单信息(因为微信比支付宝导出账单比较简单)
在微信底端“我的”-“服务”-“钱包”-“账单”
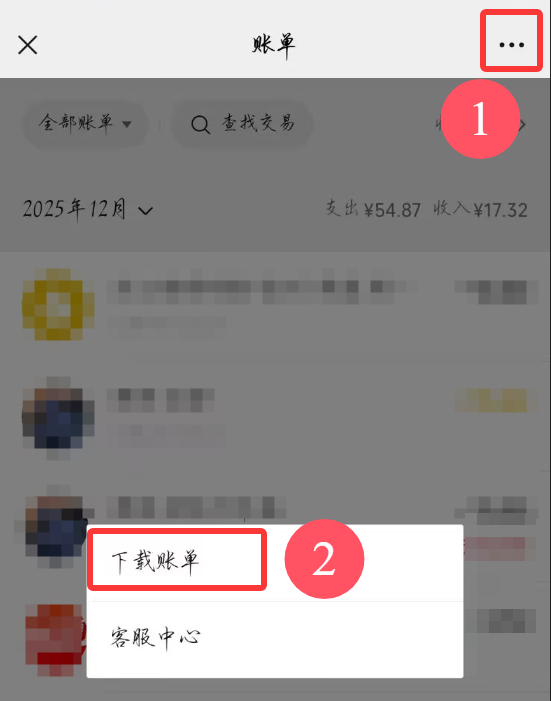
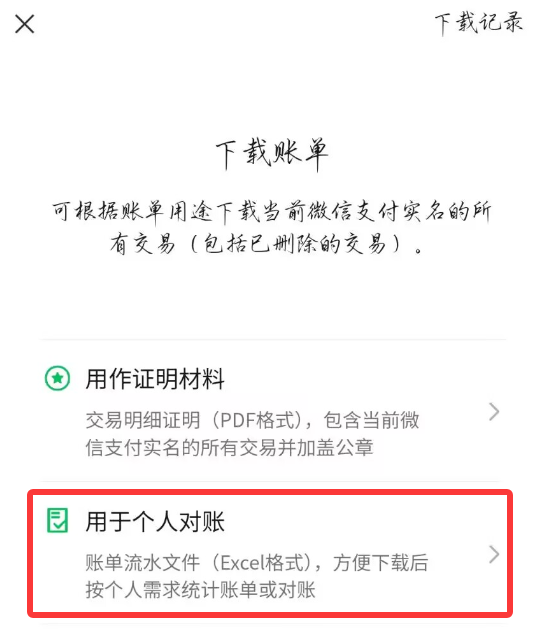
接受方式任意,看你哪个方便。
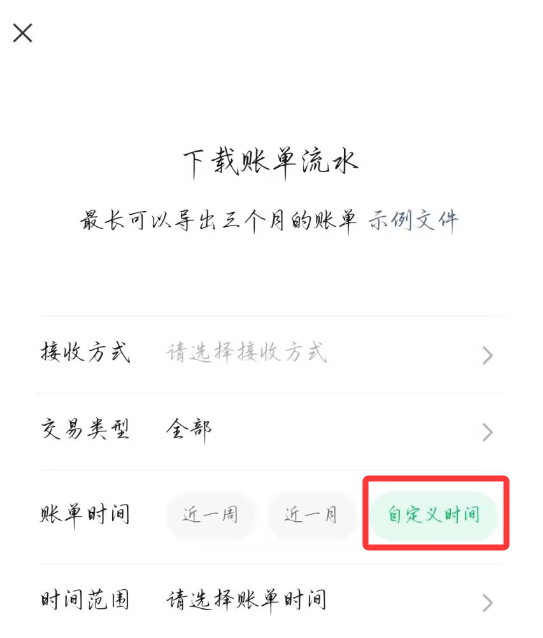
账单时间选择“自定义时间”,这里一次最多导出三个月的账单,但要求是半年的账单,所以需要导出两次,自己计算以下,如“2025.5.1-2025.7.31”和“2025.8.1-2025.10.31”。
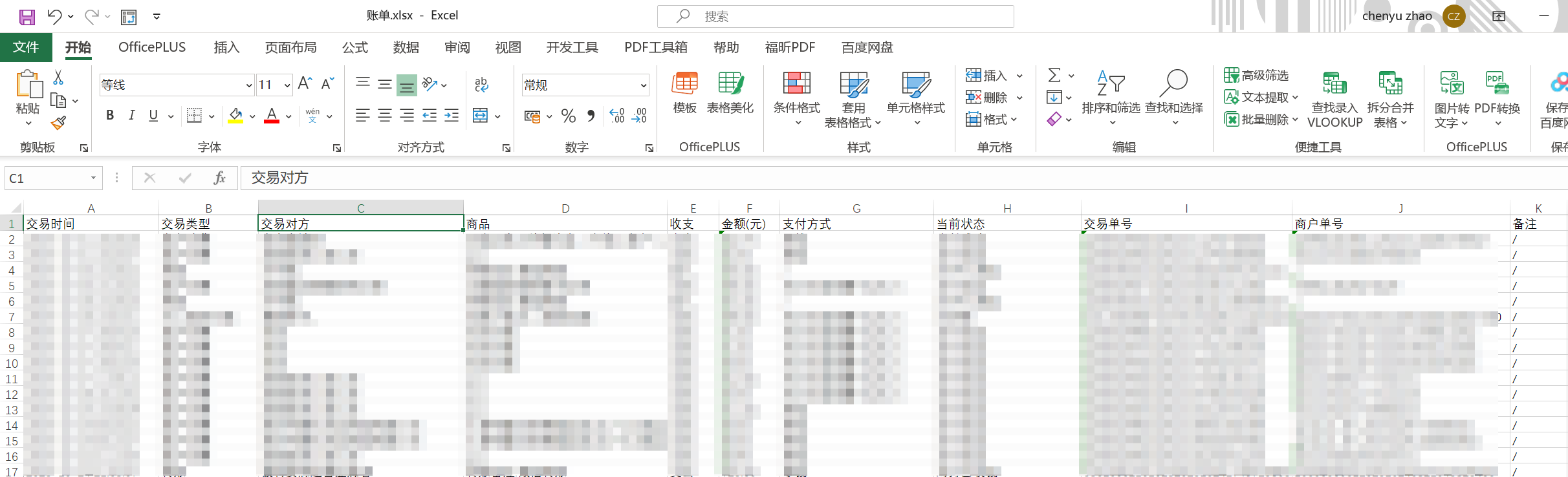
然后将两次的表格合并成一个“账单.xlsx”表格文件。如下:
要求1解 半年以上分月份消费总额折线图
# 加载必要的包
library(readxl)
library(dplyr)
library(ggplot2)
library(lubridate)
library(scales)
# 读取数据
# 请确保将文件路径修改为你的实际文件路径
bill_data <- read_excel("账单.xlsx")
bill_data <- bill_data %>%
mutate(
# 将交易时间转换为POSIXct格式,保留完整的时间信息
交易时间 = as.POSIXct(交易时间, format = "%Y-%m-%d %H:%M:%S"),
# 提取月份
月份 = format(交易时间, "%Y-%m"),
)
这里使用了%>%管道操作符,将bill_data传递给mutate函数,用于创建新列或修改现有列。
-
交易时间 = as.Date(交易时间):将原有的“交易时间”列转换为日期格式(Date),并覆盖原列。 -
月份 = format(交易时间, "%Y-%m"):使用format函数从日期中提取年份和月份(格式如“2023-01”),并创建新列“月份”。
运行后能发现导入的数据里多了一列“月份”,而原始表格没有变化。
expense_data <- bill_data %>%
filter(`收/支` == "支出")
这里因为“收/支”列字符间有“/”号,不加引号会只能读入“收”,而加双引号会被认为是字符间匹配而不是当作是列,所以正确是使用反引号。
使用filter函数筛选出“收/支”列等于“支出”的行,因为要求1只要消费的折线图。
expense_data <- expense_data %>%
mutate(金额 = as.numeric(gsub("[^0-9.-]", "", `金额(元)`)))
将字符型的金额转换为数值型。原始数据中金额列名为“金额(元)”。使用gsub函数移除所有非数字、负号和小数点的字符(正则表达式[^0-9.-]表示匹配除了数字、负号和小数点以外的任何字符),然后用as.numeric转换为数值。注意,这里使用了反引号金额(元),因为列名中包含括号,在R中引用时需要反引号。
运行后在消费账单后新加一列“金额”,这样做是因为原列“金额(元)”的数据类型中有符号“¥”,不变处理。
# 计算每月消费总额
monthly_expense <- expense_data %>%
group_by(月份) %>%
summarise(
消费总额 = sum(金额, na.rm = TRUE),
交易笔数 = n(),
平均消费 = mean(金额, na.rm = TRUE)
) %>%
arrange(月份) # 按月份排序
# 查看每月消费汇总
print(monthly_expense) #可省
使用group_by按照“月份”列进行分组,然后使用summarise计算三个统计量:
-
消费总额:对每组的“金额”求和。 -
交易笔数:使用n()计算每组的行数,即交易笔数。 -
平均消费:计算每组的平均交易金额。
最后,使用arrange(月份)将结果按月份排序。
library(ggplot2)
library(scales) # 为了使用comma_format函数
# 绘制带数值标签的折线图
ggplot(monthly_expense, aes(x = 月份, y = 消费总额, group = 1)) +
# 折线层
geom_line(color = "steelblue", size = 1.5) +
# 数据点层
geom_point(color = "steelblue", size = 3) +
# 数值标签层(核心新增)
geom_text(
aes(label = comma_format()(消费总额)), # 标签显示格式化后的消费总额(千分位)
vjust = -1, # 标签在点上方(避免重叠,可调整为1表示下方)
hjust = 0.5, # 标签水平居中
color = "black", # 标签颜色
size = 3.5, # 标签字体大小
fontface = "bold" # 标签加粗
) +
# 标题/标签配置
labs(
title = "分月份消费总额趋势图",
subtitle = paste("数据期间:",
format(min(bill_data$交易时间, na.rm = TRUE), "%Y-%m-%d"),
"至",
format(max(bill_data$交易时间, na.rm = TRUE), "%Y-%m-%d")),
x = "月份",
y = "每月消费总额 (元)"
) +
# 主题配置
theme_minimal(base_size = 12) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
plot.subtitle = element_text(hjust = 0.5, color = "gray40"),
axis.text.x = element_text(angle = 45, hjust = 1),
panel.grid.minor = element_blank(),
plot.caption = element_text(color = "gray50")
) +
# y轴千分位格式化
scale_y_continuous(labels = comma_format()) +
# 可选:调整y轴范围,避免标签超出画布(根据实际数据微调)
expand_limits(y = c(0, max(monthly_expense$消费总额) * 1.2))
画图的细节这里也不多赘述(你要画的简单也可以,画得更好也还有空间)。
ggsave("月度消费趋势图.png", width = 12, height = 8, dpi = 300)
总结(可省)
cat("===== 月度消费分析报告 =====\n")
cat("分析期间:", format(min(bill_data$交易时间), "%Y年%m月%d日"),
"至", format(max(bill_data$交易时间), "%Y年%m月%d日"), "\n")
cat("总消费笔数:", nrow(expense_data), "\n")
cat("总消费金额:", sum(expense_data$金额, na.rm = TRUE), "元\n")
cat("平均每月消费:", round(mean(monthly_expense$消费总额), 2), "元\n")
cat("消费最低的月份:",
monthly_expense$月份[which.min(monthly_expense$消费总额)], # 补充 $ 分隔符
"(", min(monthly_expense$消费总额), "元)\n") # 修正变量名+补充空格
cat("消费最高的月份:",
monthly_expense$月份[which.max(monthly_expense$消费总额)],
"(", max(monthly_expense$消费总额), "元)\n")
完整代码如下:
# 加载必要的包
library(readxl)
library(dplyr)
library(ggplot2)
library(lubridate)
library(scales)
# 读取数据
# 请确保将文件路径修改为你的实际文件路径
bill_data <- read_excel("账单.xlsx")
bill_data <- bill_data %>%
mutate(
# 将交易时间转换为POSIXct格式,保留完整的时间信息
交易时间 = as.POSIXct(交易时间, format = "%Y-%m-%d %H:%M:%S"),
# 提取月份
月份 = format(交易时间, "%Y-%m"),
)
expense_data <- bill_data %>%
filter(`收/支` == "支出")
expense_data <- expense_data %>%
mutate(金额 = as.numeric(gsub("[^0-9.-]", "", `金额(元)`)))
# 计算每月消费总额
monthly_expense <- expense_data %>%
group_by(月份) %>%
summarise(
消费总额 = sum(金额, na.rm = TRUE),
交易笔数 = n(),
平均消费 = mean(金额, na.rm = TRUE)
) %>%
arrange(月份) # 按月份排序
# 查看每月消费汇总
print(monthly_expense) #可省
library(ggplot2)
library(scales) # 为了使用comma_format函数
# 绘制带数值标签的折线图
ggplot(monthly_expense, aes(x = 月份, y = 消费总额, group = 1)) +
# 折线层
geom_line(color = "steelblue", size = 1.5) +
# 数据点层
geom_point(color = "steelblue", size = 3) +
# 数值标签层(核心新增)
geom_text(
aes(label = comma_format()(消费总额)), # 标签显示格式化后的消费总额(千分位)
vjust = -1, # 标签在点上方(避免重叠,可调整为1表示下方)
hjust = 0.5, # 标签水平居中
color = "black", # 标签颜色
size = 3.5, # 标签字体大小
fontface = "bold" # 标签加粗
) +
# 标题/标签配置
labs(
title = "分月份消费总额趋势图",
subtitle = paste("数据期间:",
format(min(bill_data$交易时间, na.rm = TRUE), "%Y-%m-%d"),
"至",
format(max(bill_data$交易时间, na.rm = TRUE), "%Y-%m-%d")),
x = "月份",
y = "每月消费总额 (元)"
) +
# 主题配置
theme_minimal(base_size = 12) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
plot.subtitle = element_text(hjust = 0.5, color = "gray40"),
axis.text.x = element_text(angle = 45, hjust = 1),
panel.grid.minor = element_blank(),
plot.caption = element_text(color = "gray50")
) +
# y轴千分位格式化
scale_y_continuous(labels = comma_format()) +
# 可选:调整y轴范围,避免标签超出画布(根据实际数据微调)
expand_limits(y = c(0, max(monthly_expense$消费总额) * 1.2))
ggsave("月度消费趋势图.png", width = 12, height = 8, dpi = 300)
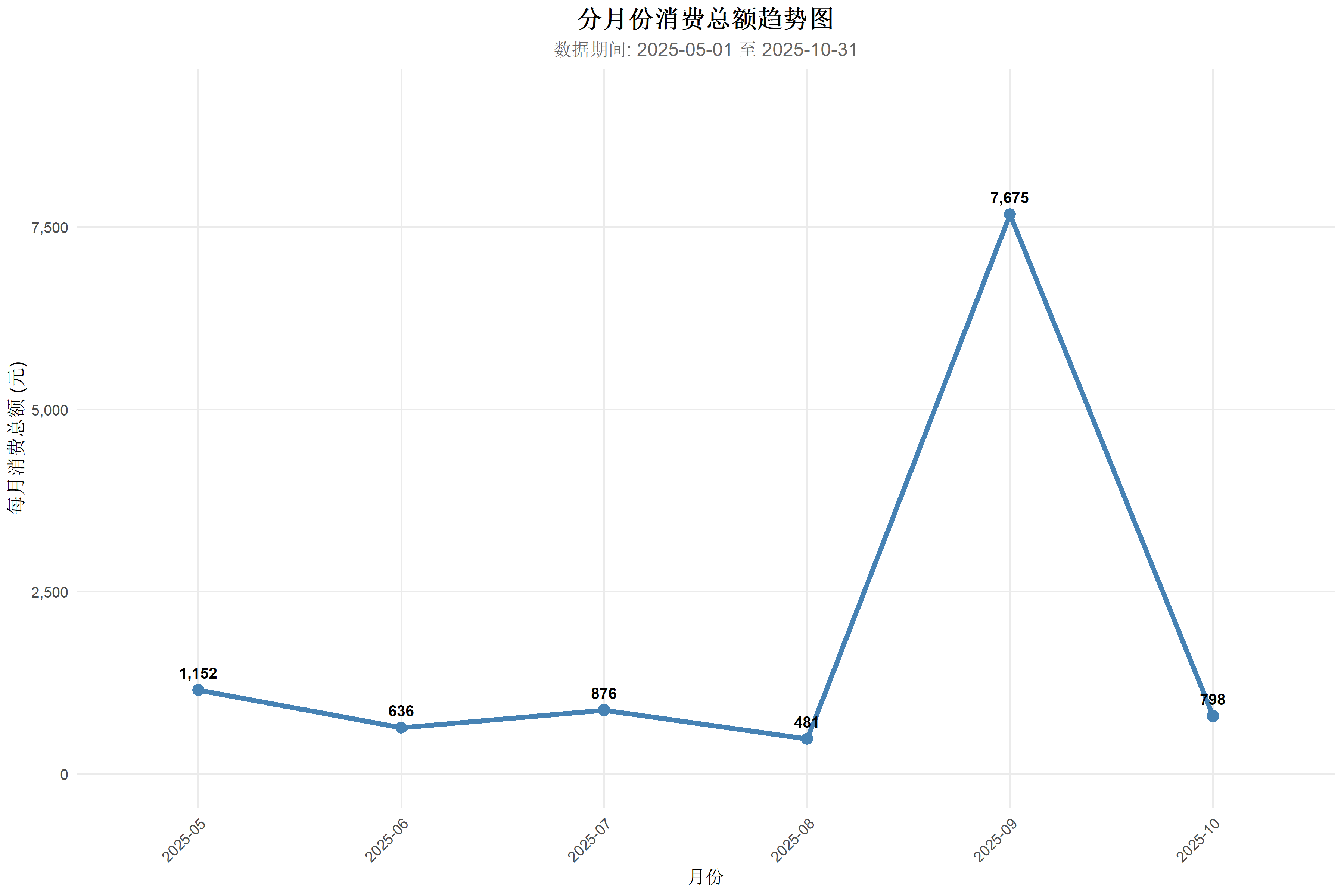
要求2解 针对单次交易金额重新编码
expense_data <- expense_data %>%
mutate(
消费类型 = case_when(
金额 < 10 ~ "小额消费",
金额 >= 10 & 金额 <= 1000 ~ "一般消费",
金额 > 1000 ~ "高消费",
TRUE ~ "其他"
)
)
write.csv(expense_data, "账单_带消费类型.csv", row.names = FALSE, fileEncoding = "UTF-8")
row.names = FALSE 含义:不将行名写入文件,如果设为TRUE,R会在第一列添加数字行号,通常保存数据时不包含行名,所以设为FALSE
总结(可省)
cat("\n✓ 要求2完成!\n")
cat("✓ 已添加新列:'消费类型'\n")
cat("✓ 已保存为新文件:账单_带消费类型.csv\n")
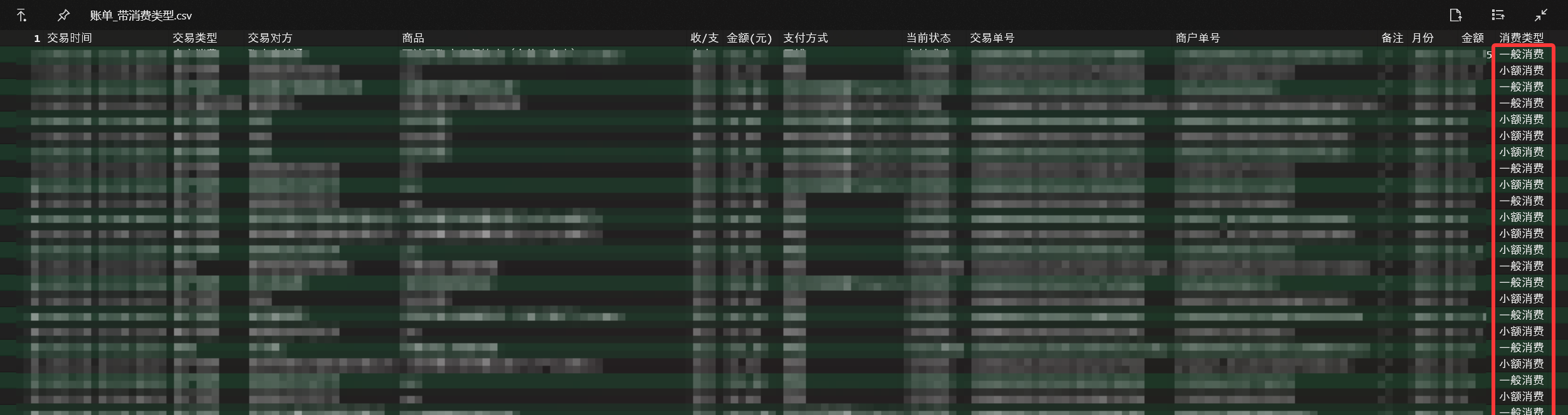
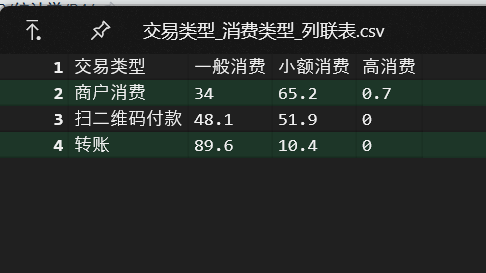
要求3解 生成交易类型与消费类型的列联表
# 1. 加载必需的包(dplyr用于数据操作,tidyr用于宽长格式转换)
library(dplyr)
library(tidyr)
# 2. 生成列联表(频数+百分比)
ctable <- expense_data %>%
# 按交易类型+消费类型分组,计算频数
group_by(交易类型, 消费类型) %>%
summarise(频数 = n(), .groups = 'drop') %>%
# 按交易类型分组,计算组内百分比(每行和为100%)
group_by(交易类型) %>%
mutate(百分比 = round(频数 / sum(频数) * 100, 1)) %>%
ungroup()
# 3. 转换为宽格式(行:交易类型,列:消费类型,值:百分比)
ctable_wide <- ctable %>%
select(交易类型, 消费类型, 百分比) %>%
pivot_wider(
names_from = 消费类型, # 列名来自“消费类型”
values_from = 百分比, # 列值来自“百分比”
values_fill = 0 # 缺失值填充为0(简化写法,等价于list(百分比=0))
)
# 4. 格式化输出列联表
cat("\n")
cat(paste(rep("=", 50), collapse = ""), "\n")
cat("要求3:交易类型与消费类型的列联表(百分比)\n")
cat("行:交易类型,列:消费类型,单位:% (每行和为100%)\n")
cat(paste(rep("=", 50), collapse = ""), "\n\n")
# 打印宽格式列联表(直观展示)
print(ctable_wide, row.names = FALSE)
write.csv(ctable_wide, "交易类型_消费类型_列联表.csv", row.names = FALSE, fileEncoding = "UTF-8")
cat("✓ 列联表已保存为:交易类型_消费类型_列联表.csv\n")
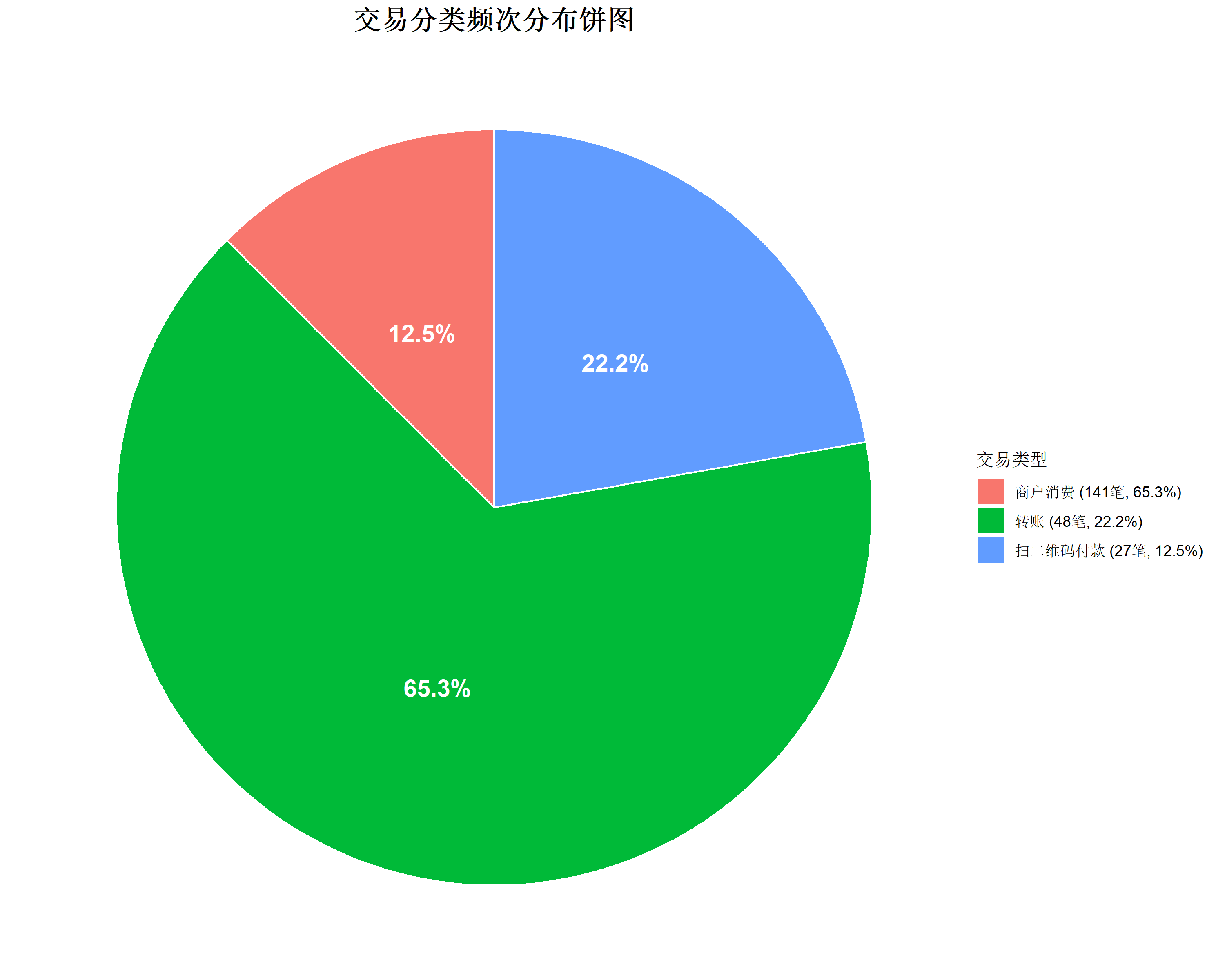
要求4解 交易分类频次数统计数据饼图,要求包含百分占比图例
# 计算交易类型的频数统计
transaction_type_counts <- expense_data %>%
count(交易类型) %>%
mutate(
百分比 = round(n / sum(n) * 100, 1)
) %>%
arrange(desc(n)) # 按频数降序排列
# 创建饼图
pie_chart <- ggplot(transaction_type_counts, aes(x = "", y = n, fill = 交易类型)) +
geom_bar(stat = "identity", width = 1, color = "white") +
coord_polar("y", start = 0) +
labs(
title = "交易分类频次分布饼图",
fill = "交易类型"
) +
theme_void() +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16)
) +
geom_text(aes(label = paste0(百分比, "%")),
position = position_stack(vjust = 0.5),
color = "white", fontface = "bold", size = 5) +
# 添加图例,显示百分比
scale_fill_discrete(
labels = paste0(transaction_type_counts$交易类型,
" (", transaction_type_counts$n, "笔, ",
transaction_type_counts$百分比, "%)")
)
# 显示饼图
print(pie_chart)
ggsave("交易分类频次饼图.png", pie_chart, width = 10, height = 8, dpi = 300)
#(可省)
cat("\n")
cat(paste(rep("=", 50), collapse = ""))
cat("\n")
cat("交易分类频次统计:\n")
print(transaction_type_counts)
cat(paste(rep("=", 50), collapse = ""))
cat("\n")
cat("✓ 交易分类频次饼图已保存为:交易分类频次饼图.png\n")
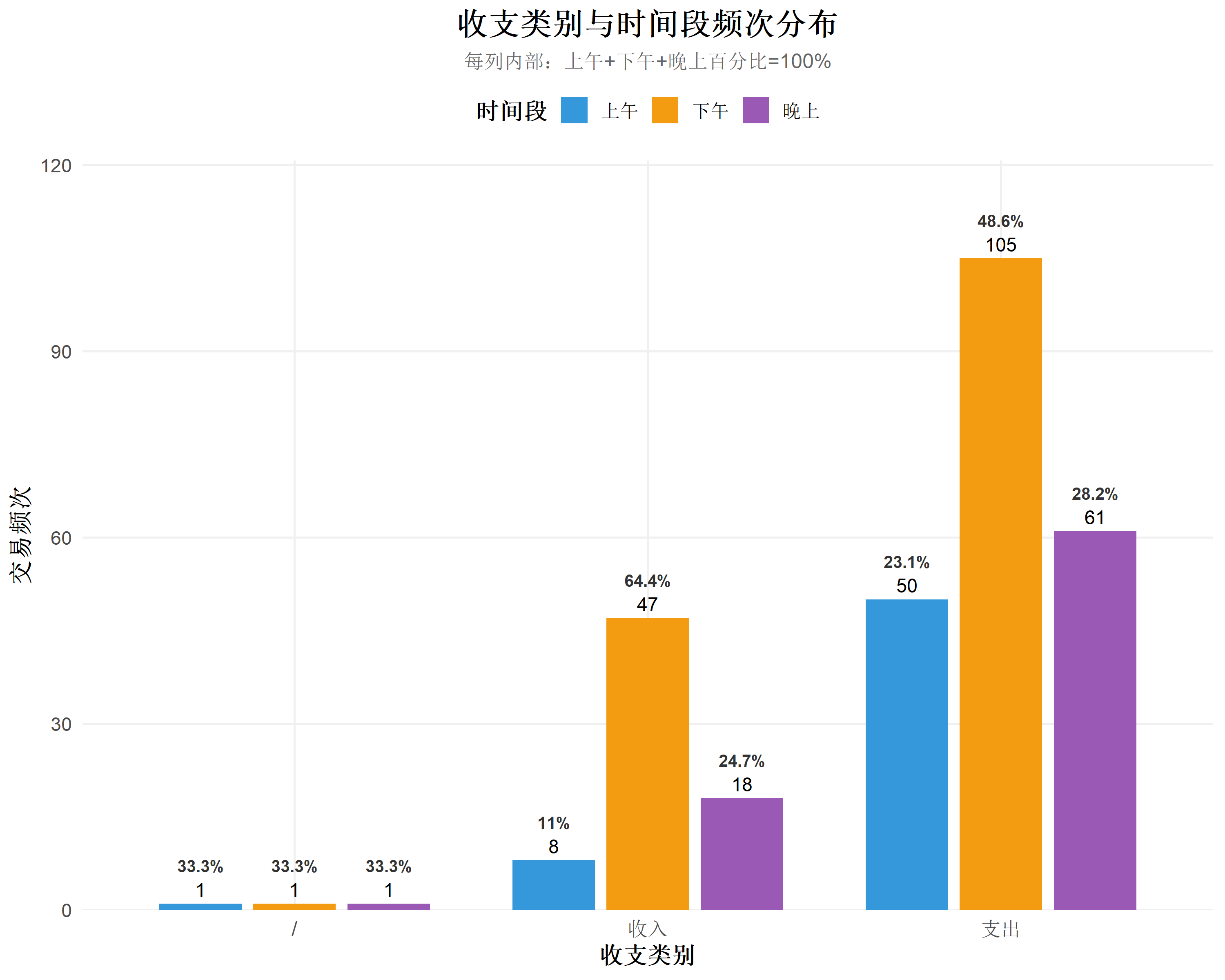
要求5解 针对交易时间重新编码(例如上午、下午和晚上),与交易分类频次及交易类别(收入或支出)形成复杂条图
这里的理解可能不同,所以所画的图不一样
bill_data <- bill_data %>%
mutate(
# 将交易时间转换为POSIXct格式,保留完整的时间信息
交易时间 = as.POSIXct(交易时间, format = "%Y-%m-%d %H:%M:%S"),
# 提取小时(依赖lubridate包)
交易小时 = hour(交易时间),
# 重新编码时间段
时间段 = case_when(
交易小时 >= 4 & 交易小时 < 12 ~ "上午",
交易小时 >= 12 & 交易小时 < 20 ~ "下午",
TRUE ~ "晚上"
),
# 转换为有序因子
时间段 = factor(时间段, levels = c("上午", "下午", "晚上"), ordered = TRUE)
)
# 检查时间段分布
cat("\n时间段分布统计:\n")
time_distribution <- bill_data %>%
count(时间段, `收/支`) %>%
arrange(时间段, `收/支`)
print(time_distribution)
# 计算每个时间段和收支的频次统计
time_income_expense_stats <- bill_data %>%
group_by(时间段, `收/支`) %>%
summarise(
频次 = n(),
.groups = 'drop'
) %>%
# 确保所有时间段和收支组合都存在
complete(时间段, `收/支`, fill = list(频次 = 0))
# 计算每个收支类别内部的时间段百分比
time_income_expense_stats <- time_income_expense_stats %>%
group_by(`收/支`) %>%
mutate(
该收支总频次 = sum(频次),
百分比 = ifelse(该收支总频次 > 0, round(频次 / 该收支总频次 * 100, 1), 0)
) %>%
ungroup()
income_expense_bar <- ggplot(time_income_expense_stats,
aes(x = `收/支`, y = 频次, fill = 时间段)) +
geom_bar(stat = "identity", position = position_dodge(0.8), width = 0.7) +
# 添加频次数值标签
geom_text(aes(label = 频次),
position = position_dodge(0.8),
vjust = -0.5, size = 4) +
# 添加百分比标签
geom_text(aes(label = ifelse(频次 > 0, paste0(百分比, "%"), "")),
position = position_dodge(0.8),
vjust = -2.5, size = 3.5, fontface = "bold", color = "#333333") + scale_fill_manual(values = c("上午" = "#3498DB", "下午" = "#F39C12", "晚上" = "#9B59B6")) +
labs(
title = "收支类别与时间段频次分布",
subtitle = "每列内部:上午+下午+晚上百分比=100%",
x = "收支类别",
y = "交易频次",
fill = "时间段"
) +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 18),
plot.subtitle = element_text(hjust = 0.5, color = "#666666", size = 12), axis.title = element_text(face = "bold"), axis.text.x = element_text(size = 12), axis.text.y = element_text(size = 11), panel.grid.major = element_line(color = "#F0F0F0"),
panel.grid.minor = element_blank(),
legend.position = "top",
legend.title = element_text(face = "bold"),
plot.background = element_rect(fill = "white", color = NA)
) +
scale_y_continuous(
expand = expansion(mult = c(0, 0.15)) # 为顶部标签留出空间
)
# 10. 显示复杂条图
print(income_expense_bar)
# 11. 保存图表
ggsave("收支_时间段_复杂条图.png", income_expense_bar, width = 10, height = 8, dpi = 300)
#总结(可省)
cat("\n" + paste(rep("=", 60), collapse = "") + "\n")
cat("✓ 要求5完成:交易时间重新编码与复杂条图\n")
cat("✓ 时间编码规则:\n")
cat(" - 上午: 4:00 - 11:59\n")
cat(" - 下午: 12:00 - 19:59\n")
cat(" - 晚上: 20:00 - 3:59\n")
cat("✓ 复杂条图已保存为:收支_时间段_复杂条图.png\n")
cat(paste(rep("=", 60), collapse = "") + "\n")
要求6解 对交易金额进行排序,观测最大额的十比交易,输出交易信息
# 确保所有交易数据(包括收入和支出)都有金额数值列
# 如果bill_data中没有金额数值列,先创建
if (!"金额" %in% colnames(bill_data)) {
bill_data <- bill_data %>%
mutate(金额 = as.numeric(gsub("[^0-9.-]", "", `金额(元)`)))
}
# 对交易金额进行排序(按绝对值排序,显示支出最高的10笔)
# 注意:这里假设支出为负数,收入为正数,但根据实际情况调整
# 如果所有金额都是正数,则按降序排列
# 方法1:按金额绝对值降序排列(显示交易额最大的10笔,无论收支)
top_10_absolute <- bill_data %>%
mutate(金额绝对值 = abs(金额)) %>%
arrange(desc(金额绝对值)) %>%
slice_head(n = 10)
# 方法2:按实际金额降序排列(显示数值最大的10笔,通常收入为正数,支出为负数)
top_10_numerical <- bill_data %>%
arrange(desc(金额)) %>%
slice_head(n = 10)
# 方法3:按支出金额降序排列(如果支出为负数,则支出金额最大的就是负数最小的)
# 先筛选支出,然后按金额降序排列(支出金额通常为负数,所以降序排列会得到最小的负数,即支出最大的)
top_10_expense <- expense_data %>%
arrange(desc(金额)) %>%
slice_head(n = 10)
# 根据你的数据结构选择合适的方法
# 这里假设你想要交易额最大的10笔(按绝对值计算)
top_10_transactions <- top_10_absolute %>%
select(交易时间, 交易类型, 交易对方, 商品, `收/支`, 金额, 支付方式, 当前状态, 交易单号, 商户单号, 备注)
# 输出最大额的十笔交易信息
cat("\n")
cat(paste(rep("=", 60), collapse = ""))
cat("\n")
cat("最大额的十笔交易信息(按金额绝对值排序):\n")
cat(paste(rep("=", 60), collapse = ""))
cat("\n")
# 以整洁的格式打印
print(top_10_transactions)
# 或者使用knitr的kable函数生成更美观的表格(如果安装了knitr包)
if (requireNamespace("knitr", quietly = TRUE)) {
library(knitr)
cat("\n")
cat("美观的表格输出:\n")
print(kable(top_10_transactions, align = c("l", "l", "l", "l", "c", "r", "l", "l", "l", "l", "l"),
col.names = c("交易时间", "交易类型", "交易对方", "商品", "`收/支`", "金额(元)", "支付方式", "当前状态", "交易单号", "商户单号", "备注")))
}
# 保存最大额交易信息到CSV文件
write.csv(top_10_transactions, "最大额十笔交易.csv", row.names = FALSE, fileEncoding = "UTF-8")
# 输出简要统计信息
cat("\n")
cat(paste(rep("-", 40), collapse = ""))
cat("\n")
cat("最大额交易统计摘要:\n")
cat(sprintf("最高交易金额: %.2f元\n", max(top_10_transactions$金额, na.rm = TRUE)))
cat(sprintf("最低交易金额(在前10名中): %.2f元\n", min(top_10_transactions$金额, na.rm = TRUE)))
cat(sprintf("平均交易金额: %.2f元\n", mean(top_10_transactions$金额, na.rm = TRUE)))
cat(sprintf("交易金额中位数: %.2f元\n", median(top_10_transactions$金额, na.rm = TRUE)))
# 按交易类型统计
cat("\n最大额交易按类型分布:\n")
type_dist <- top_10_transactions %>%
count(交易类型) %>%
mutate(占比 = round(n / sum(n) * 100, 1))
print(type_dist)
# 按收支类型统计
cat("\n最大额交易按收支分布:\n")
income_expense_dist <- top_10_transactions %>%
count(`收/支`) %>%
mutate(占比 = round(n / sum(n) * 100, 1))
print(income_expense_dist)
cat(paste(rep("=", 60), collapse = ""))
cat("\n")
cat("✓ 最大额十笔交易信息已保存为:最大额十笔交易.csv\n")

要求7解 自定义函数,利用循环及判定逻辑实现计算一般消费以上(>10元)的交易额总数、均值、标准差的计算
# 定义自定义函数
calculate_expense_stats <- function(data) {
# 初始化统计变量
total_amount <- 0
count <- 0
amount_vector <- numeric()
# 使用循环遍历数据
for(i in 1:nrow(data)) {
# 获取当前行的金额
current_amount <- data$金额[i]
# 判定逻辑:只计算金额≥10的交易
if(!is.na(current_amount) && current_amount >= 10) {
total_amount <- total_amount + current_amount
count <- count + 1
amount_vector <- c(amount_vector, current_amount)
}
}
# 计算统计指标
if(count > 0) {
mean_amount <- total_amount / count
# 计算标准差
if(count > 1) {
variance <- sum((amount_vector - mean_amount)^2) / (count - 1)
sd_amount <- sqrt(variance)
} else {
sd_amount <- 0 # 只有一个数据点时标准差为0
}
} else {
mean_amount <- 0
sd_amount <- 0
}
# 返回结果列表
return(list(
交易笔数 = count,
交易总额 = round(total_amount, 2),
平均金额 = round(mean_amount, 2),
标准差 = round(sd_amount, 2),
金额范围 = if(count > 0) {
paste0("(", round(min(amount_vector), 2), " ~ ", round(max(amount_vector), 2), ")")
} else {
"无数据"
}
))
}
# 使用自定义函数计算一般消费及以上的统计指标
stats_result <- calculate_expense_stats(expense_data)
# 输出结果
cat("\n")
cat(paste(rep("=", 50), collapse = ""))
cat("\n")
cat("要求7:一般消费及以上(金额≥10元)统计结果\n")
cat("使用自定义函数通过循环和判定逻辑计算\n")
cat(paste(rep("=", 50), collapse = ""))
cat("\n")
# 格式化输出结果
cat("统计指标:\n")
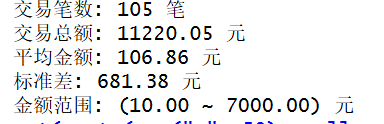
cat(sprintf(" 交易笔数: %d 笔\n", stats_result$交易笔数))
cat(sprintf(" 交易总额: %.2f 元\n", stats_result$交易总额))
cat(sprintf(" 平均金额: %.2f 元\n", stats_result$平均金额))
cat(sprintf(" 标准差: %.2f 元\n", stats_result$标准差))
cat(sprintf(" 金额范围: %s 元\n", stats_result$金额范围))
# 计算占比
total_count <- nrow(expense_data)
if(total_count > 0) {
percentage <- round(stats_result$交易笔数 / total_count * 100, 1)
cat(sprintf(" 占所有消费比例: %.1f%%\n", percentage))
}
cat(paste(rep("=", 50), collapse = ""))
cat("\n")
# 验证:使用向量化方法计算同样的指标进行验证
cat("验证(使用向量化方法):\n")
filtered_data <- expense_data %>% filter(金额 >= 10)
if(nrow(filtered_data) > 0) {
cat(sprintf(" 交易笔数: %d 笔\n", nrow(filtered_data)))
cat(sprintf(" 交易总额: %.2f 元\n", sum(filtered_data$金额)))
cat(sprintf(" 平均金额: %.2f 元\n", mean(filtered_data$金额)))
cat(sprintf(" 标准差: %.2f 元\n", sd(filtered_data$金额)))
cat(sprintf(" 金额范围: (%.2f ~ %.2f) 元\n",
min(filtered_data$金额), max(filtered_data$金额)))
}
cat(paste(rep("=", 50), collapse = ""))
cat("\n")



















 1761
1761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











