




 超级会员免费看
超级会员免费看

目录
一、问题定义与业务场景
目标:分析用户在应用内的连续行为序列(如页面浏览、功能点击),识别特定行为路径模式(如“A→B→C”)。
核心需求:
- 相邻行为验证:统计完成相邻动作的用户(如签到后立刻抽奖)。
- 非连续路径匹配:识别行为序列中存在中间步骤的路径(如A→任意页面→B→非C页面→D)。
应用场景:
- 漏斗转化分析(如购物车→支付流程)
- 用户流失点定位(如注册后未完成新手引导)
- 运营活动效果追踪(如优惠券领取→使用路径)
二、数据准备与建表语句
2.1 建表语句
CREATE TABLE user_behavior_log (
user_id BIGINT COMMENT '用户ID',
action_id VARCHAR(128) COMMENT '行为标识(如sign/lottery)',
event_time DATETIME COMMENT '行为时间'
) COMMENT '用户行为日志表'; 2.2 样例数据
INSERT INTO user_behavior_log VALUES
(1001, 'login', '2025-06-01 09:00:00'),
(1001, 'sign', '2025-06-01 09:01:00'), -- 签到
(1001, 'lottery', '2025-06-01 09:01:30'), -- 抽奖(与签到相邻)
(1001, 'view_product', '2025-06-01 09:02:00'),
(1002, 'sign', '2025-06-01 10:00:00'),
(1002, 'view_ad', '2025-06-01 10:00:30'), -- 中间行为
(1002, 'lottery', '2025-06-01 10:01:00'), -- 非相邻抽奖
(1003, 'sign', '2025-06-01 11:00:00'),
(1003, 'lottery', '2025-06-01 11:00:05'); -- 相邻抽奖2.3 数据关系说明
| 用户 | 行为序列 | 是否符合相邻路径(sign→lottery) |
| 1001 | login → sign → lottery | ✅(间隔30秒) |
| 1002 | sign → view_ad → lottery | ❌(存在中间行为) |
| 1003 | sign → lottery | ✅(间隔5秒) |
三、SQL解决方案(两种主流方法)
3.1 窗口函数法(验证相邻行为)
适用场景:检测连续两个行为是否相邻(如签到后立刻抽奖)。
核心逻辑:
- 使用
LEAD()获取下一个行为 - 筛选当前行为为
sign且下一行为lottery的用户数
SELECT
COUNT(DISTINCT user_id) AS user_count
FROM (
SELECT
user_id,
action_id,
LEAD(action_id, 1) OVER ( PARTITION BY user_id ORDER BY event_time ) AS next_action
FROM user_behavior_log
) t
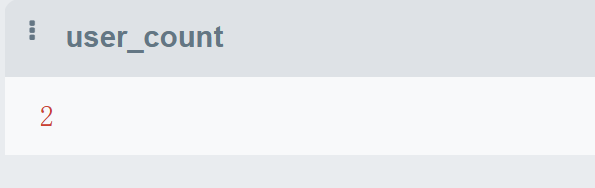
WHERE action_id = 'sign' AND next_action = 'lottery';执行结果:
3.2 行为序列拼接法(验证非连续路径)
适用场景:识别复杂路径(如A→B→D且中间不含C)的用户数。
核心逻辑:
- 按时间排序拼接行为序列
- 用正则匹配路径模式
WITH behavior_sequence AS (
SELECT
user_id,
GROUP_CONCAT(action_id ORDER BY event_time) AS action_path
FROM user_behavior_log
GROUP BY user_id
)
SELECT
COUNT(*) AS user_count
FROM behavior_sequence
WHERE
-- 匹配A-B-D路径,且B-D之间不含C
action_path REGEXP '.*sign,.*lottery.*,view_product.*'
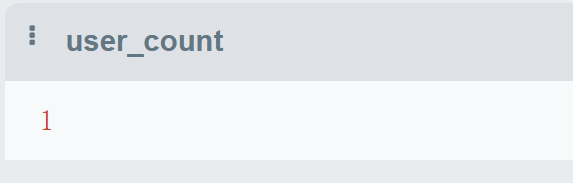
AND action_path NOT LIKE '.*sign,.*C,.*view_product.*'; 执行结果:
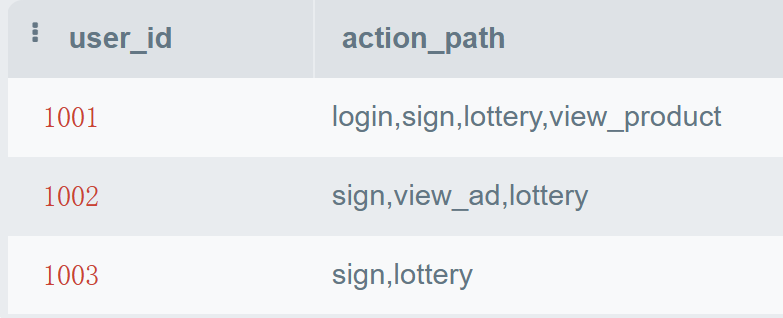
分组统计明细:
四、扩展优化与边界处理
4.1 关键边界场景
- 相同时间行为:
ORDER BY event_time, action_id -- 时间相同时按行为ID排序4.2 性能优化方案
- 数据倾斜处理(用户行为量差异大)
- 索引设计(MySQL/PostgreSQL):
CREATE INDEX idx_user_time ON user_behavior_log(user_id, event_time);4.3 高级变体问题
- 使用正则的路径匹配(如A后出现B但跳过C):
action_path RLIKE 'A((?!C).)*B' -- 匹配A到B之间无C- 循环行为检测(如A→B→A):
action_path LIKE '%A,B,A%' -- 简单循环模式五、总结与面试要点
- 核心方法对比:
| 方法 | 适用场景 | 时间复杂度 | 优势 |
| 窗口函数(LEAD) | 相邻行为验证 | O(n log n) | 代码简洁 |
| 行为序列拼接 | 复杂路径匹配 | O(n²) | 支持非连续路径 |
1.高频考点
- 时间乱序处理:
ORDER BY event_time确保序列顺序 - 去重机制:GROUP_CONCAT、
COLLECT_LIST需搭配排序避免乱序 - 分区策略:按日期分区提升查询性能
2.避坑指南
- 空值处理:
LEAD()可能返回NULL,需用COALESCE - 性能陷阱:避免对未分区的大表全扫描
3.真题参考
腾讯、拼多多等大厂高频题型,扩展题包括“用户行为漏斗转化率分析”、“关键路径流失用户定位”。


















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











