 ELK组成及EFK区别介绍
ELK组成及EFK区别介绍




一、ELK的组成
1、Elasticsearch (ES):
Elasticsearch 是一个基于 Apache Lucene 构建的分布式、实时搜索与分析引擎。它能够索引、搜索和分析大量数据,并且提供了水平扩展能力,允许处理 PB 级别的数据。Elasticsearch 适合用于全文搜索、日志分析、监控指标聚合等多种场景,其 RESTful API 让数据的索引和查询变得非常便捷。
2、Logstash (LS):
Logstash 是一个动态数据收集管道,用于从各种数据源接收、解析、转换并将数据发送到“es”(例如 Elasticsearch)。它可以收集来自服务器日志、数据库、应用程序、网络设备等各种源头的日志数据,并对这些数据进行清洗、标准化和丰富,以便于后续分析。
3、Kibana (KB):
Kibana 是一个开源的数据可视化工具,专为 Elasticsearch 设计,提供了一个用户友好的 Web 界面,使得用户可以轻松地搜索、查看和分析 Elasticsearch 中存储的数据。借助 Kibana,用户可以创建仪表板、图表和其他可视元素,对数据进行深度探索,同时支持实时数据分析和交互式操作。
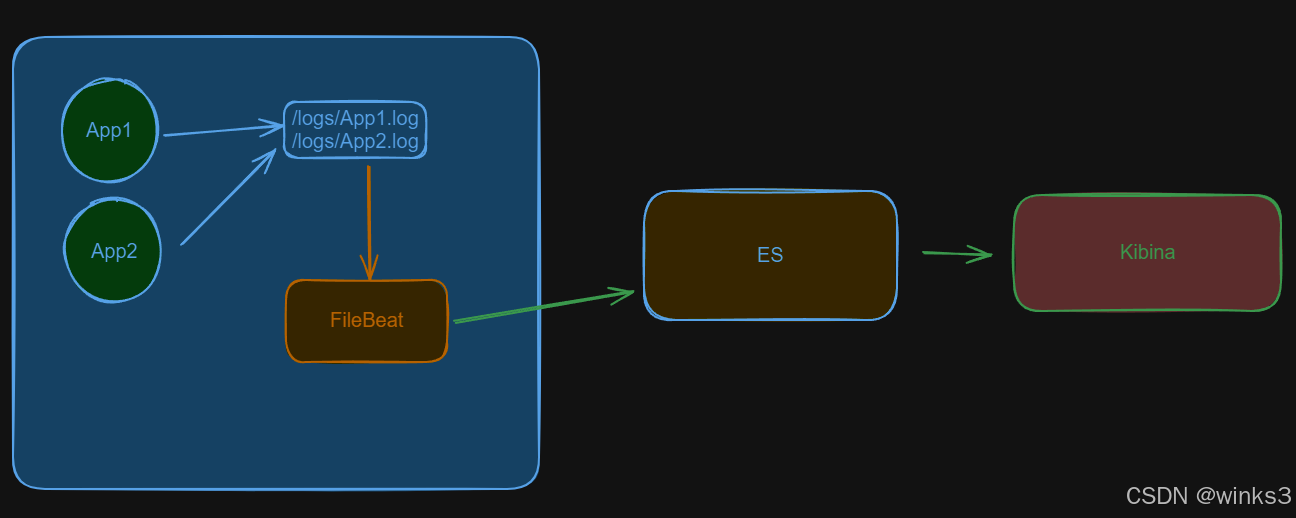
二、EFK
EFK与ELK的区别主要在于,EFK使用Filebeat来替代 Logstash 作为日志收集代理,这是因为 Filebeat 相对于 Logstash 来说更为轻量级,资源消耗较小,尤其适合于边缘节点或者资源有限的服务器上收集日志数据。
Filebeat的好处是:
轻量化、模块化、传输化

















 3916
3916

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









