






🚀 个人主页 极客小俊
✍🏻 作者简介:程序猿、设计师、技术分享
🐋 希望大家多多支持, 我们一起学习和进步!
🏅 欢迎评论 ❤️点赞💬评论 📂收藏 📂加关注



场景需求
我在制作视频影视后期混剪的时候,经常会遇见人声分离的需求, 比如我们需要某个音频或者视频中的干净的人声,俗称干声, 这就需要我们把媒体文件中的其他杂音去掉,只剩下人的声音,又或者说是,常常我们听见一段BGM很不错,但是又背景人声,想把它去掉, 那么这个时候人声分离的需求就出现了!
Spleeter介绍
想要实现人声分离的办法其实也有很多,但是这里我推荐一个Python库也就是我们今天要说的Spleeter
Spleeter是由Deezer开源的一款高性能Python音频分离工具,它利用深度机器学习技术将音频文件中的人声与BGM分离成两个独立的音轨,让我们得到两个独立的音乐文件人声和BGM
Spleeter就像是一个音频魔术师,可以很方便的帮助我们获取到音频中的人声和背景音乐, 这个在我们制作后期剪辑和影视混剪的时候非常有用!
前期准备
安装Python
因为Spleeter是基于Python语言开发的,它依赖于Python的生态系统来运行!
所以要在我们电脑上运行Spleeter,首先需要安装Python环境,这个我在前面已经多次讲解过了,
注意
这个Spleeter目前必须要安装Python3.7.7这个版本才能支持!
如图

这一点非常重要!
所以如果后期你使用这个插件库出了什么问题,那么检查你是否使用了兼容版本的,比如 Python3.6、3.7 3.8
那安装Python的步骤如下: 这里我以Python3.7.7为例
首先进入Python官网 https://www.python.org
选择Downloads-->Windows
如图

然后在下面的历史列表中找到Python3.7.7这个版本
点击Download Windows x86-64 executable installer
如图

这样我们就能得到一个python-3.7.7的安装包文件
如图

双击开始安装!
首先我们要把Add Python3.7 to PATH勾选上,这样能自动帮我们添加到环境变量中去!
如图

然后选择自定义安装(Customize installation)
默认全部都勾选上!
如图

然后自己选择一个安装路径!
如图

然后点击Install开始安装Python
如图

安装完成!

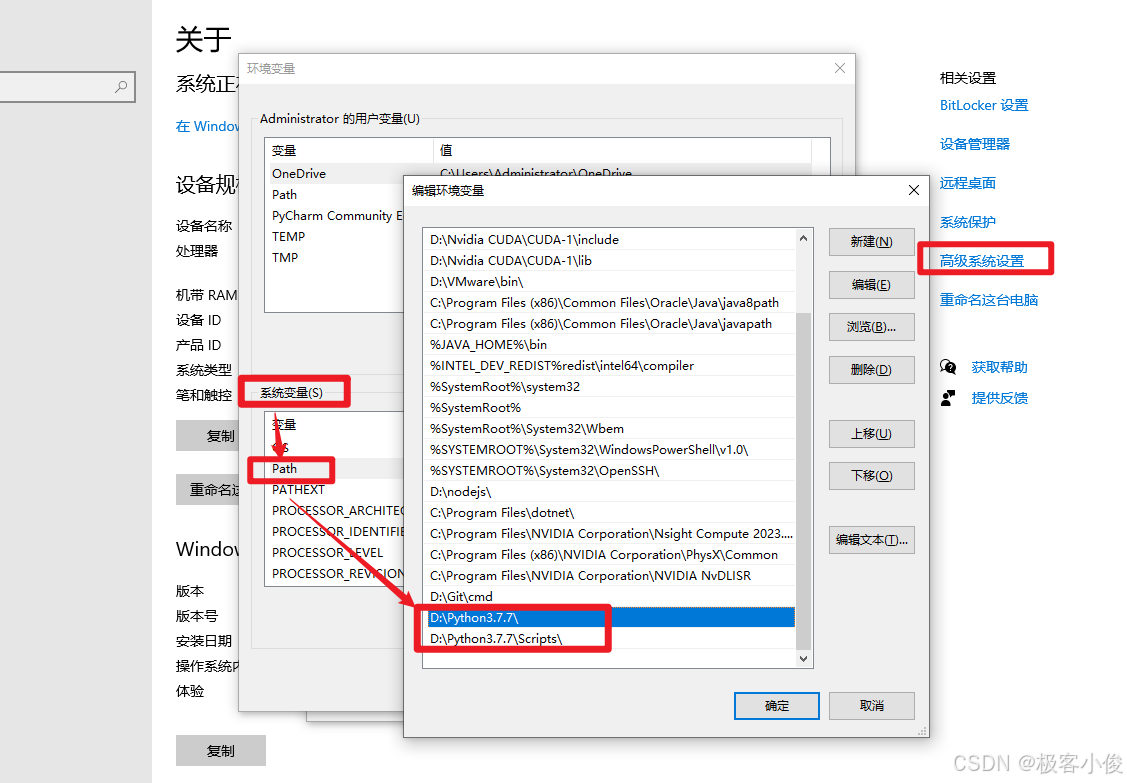
这里注意一下,我们安装好Python之后,还是需要手动检查一下,并且再次配置一下Python的安装路径到环境变量中的Path下!
如图
安装FFmpeg
FFmpeg是一套开源的跨平台视频音频处理工具及开发套件,提供了视频解码、编码、后期处理等一系列功能
我们可以从FFmpeg官方网站下载FFmpeg
https://ffmpeg.org/download.html
这里我以Windows10系统为例
如图

然后点击Windows builds by BtbN

然后进入到下载地址
https://github.com/BtbN/FFmpeg-Builds/releases
这里我们下载ffmpeg-master-latest-win64-gpl.zip这个压缩包
如图

下载好之后,我们解压一下

把ffmpeg配置到环境变量 解压之后,找到bin目录,里面有如下几个文件
如图

我们现在其实可以把,这个解压出来的ffmpeg-master-latest-win64-gpl这个目录重命名一下,免得一会配置环境变量路径太长,并且把这个目录放到一个比较合适的盘符下,路径不要有中文!
这里我就放在D盘根目录下的ffmpeg目录中
例如我的路径是这样:
D:\ffmpeg\bin
如图
把他们这样放

然后把D:\ffmpeg\bin这个路径配置到环境变量中去!
也就是将FFmpeg的bin目录添加到你的系统环境变量中, 这样,你就可以在命令行中全局访问FFmpeg了
如图

如果你还不清楚什么是环境变量,可以去看看我前面的教程!
配置好之后,我们可以打开cmd输入ffmpeg命令回车
如果看到以下提示,那么说明你已经配置成功了!
如图

Spleeter安装
https://pypi.org/project/spleeter/
如图

既然Spleeter是一个Python库,我们在安装好Python之后,可以通过pip包管理器进行安装!
我们使用快捷键win + R 打开cmd命令行, 然后输入以下命令来安装Spleeter
pip install spleeter
如图

因为Spleeter还依赖于其他Python库,例如 TensorFlow(一个开源的机器学习框架)等,来执行其复杂的音频处理任务!
所以这里我们安装Spleeter的时候,同时也会下载必要的依赖库!
我们在执行pip install spleeter时,pip包管理器会自动的安装Spleeter所需的大部分依赖库!
要确保安装了所有必要的依赖库, 然后我们才可以通过命令行或脚本方式运行Spleeter,对音频文件进行人声分离处
所以安装过程可能需要等待一段时间!
如图

如下你看到以下提示,说明安装完毕!
如图

我们可以使用以下命令在cmd命令行中执行,来看看Spleeter是否安装成功!
pip show spleeter
如图

下载预训练模型(model)
Spleeter需要预训练模型来分离人声和背景音乐,我们可以到Github上去下载
地址如下:
https://github.com/deezer/spleeter/releases
如图

建议把下载链接复制到下载工具进行下载!
如图

下载好了之后,如下所示
如图

然后我们规划一下, 这几个模型文件!
首先解压模型文件到一个你记得且没有中文的路径上
比如我在D盘根目录下新建一个Spleeter目录, 然后新建子目录pretrained_models,
然后把刚刚解压好的3个模型文件都放到这里!
如图

Spleeter分离人声
一切都准备好了之后,现在我们就可以开始进行人声分离了!
这里我就先把要处理的音频文件先放置到我刚刚在D盘创建的Spleeter目录下,跟模型同级目录!
如图

使用2stems模型
然后打开cmd命令行,把路径切换到这个Spleeter目录下,输入以下命令
spleeter separate -o audio_output test1.mp3
解释
上面这段代码的意思就是默认分离2个文件出来,(人声和伴奏) 让预训练模型直接分离音频文件!
-o这个参数用于设置输出保存路径,用于保存分离的音频文件, 这里的audio_output我们可以随便修改一个合适的名称, 我们在第一次运行时可能需要相当长的时间才能执行,因为它将下载预先训练的模型!
如图

当你看到succesfully那就恭喜你你已经成功把音频文件进行了人声分
并且保存到了当前指定的audio_output目录中!
在当前处理的音频同级目录下,会把这个audio_output目录自动进行生成!
里面包含两个文件的文件夹:accompaniment.wav和vocals.wav
accompaniment.wav 就是分离出来的背景音乐
vocals.wav 就是分离出来的人声
如图

这样我们就可以利用这个素材到PR AE中进行后期视频混剪加工处理了!
特别提醒
如下我们在分离音频的时候,遇到下面这种错误提示,
那么说明你的Python版本太高了,把版本更换到3.7.7就没问题了!
如图

使用4stems模型
这种方式比上面分离得还要细致, 它包括了分离人声、贝斯、鼓、其他
命令语法
spleeter separate -o 输出目录名称 -p spleeter:4stems 音频文件名称.mp3
语法解释
-p参数选项用于提供模型设置,我们可以在这个参数后面跟如下模型
spleeter:2stems
spleeter:4stems
spleeter:5stems
例如
spleeter separate -o audio_output_4 -p spleeter:4stems test1.mp3
如图

这次它将自动给我们生成4个文件:
vocals.wav(人声)、drums.wav(鼓打)、bass.wav(低音)、other.wav(其他)
如图

使用5stems模型
最后Spleeter还提供5stems预训练模型,可以分离出人声,贝斯,鼓,钢琴,其他 这几种音色!
命令语法
spleeter separate -o 输出目录 -p spleeter:5stems 音频文件.mp3
这将生成五个文件:
vocals.wav(人声)、drums.wav(鼓打)、bass.wav(低音)、other.wav(其他)、piano.wav(钢琴)
例如
spleeter separate -o audio_output_5 -p spleeter:5stems test1.mp3
如图


使用16kHz 的模型
我们默认的spleeter:2stems、spleeter:4stems和spleeter:5stems都可实现11kHz的分离
这些模型也可以分离出16kHz音频
模型名称写法如下:
spleeter:2stems-16kHz
spleeter:4stems-16kHz
spleeter:5stems-16kHz
11kHz和16kHz的区别如下:
11kHz的采样率获得的声音为电话音质,基本上能让人分辨出通话人的声音
16kHz的采样率能捕捉到更高频率的声音,在语音通信和语音识别方面具有重要意义,适用于一些对高频响应要求较高的场景!
使用语法
spleeter separate -o 输出目录 -p 模型名称 音频文件.mp3
例如
spleeter separate -o audio16kHz -p spleeter:2stems-16kHz test1.mp3
如图

怎么样,赶紧去试试看分离出来的音质吧~~


"👍点赞" "✍️评论" "收藏❤️"欢迎一起交流学习❤️❤️💛💛💚💚
好玩 好用 好看的干货教程可以点击下方关注❤️微信公众号❤️
说不定有意料之外的收获哦..🤗嘿嘿嘿、嘻嘻嘻🤗!
🌽🍓🍎🍍🍉🍇




















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









