






🚀 个人主页 极客小俊
✍🏻 作者简介:程序猿、设计师、技术分享
🐋 希望大家多多支持, 我们一起学习和进步!
🏅 欢迎评论 ❤️点赞💬评论 📂收藏 📂加关注

概述
在SQL Server 2000中有这样两种数据类型: sql_variant和uniqueidentifier, 它们是两种非常有用的数据类型,它们在不同的应用场景中发挥着重要的作用, 今天就跟大家具体介绍一下!
sql_variant数据类型
sql_variant数据类型可以让字段或变量存储不同数据类型的数据值!
通俗一点的说sql_variant数据类型就像一个万能盒子, 想象一下,你有一个万能盒子 这个盒子非常神奇,因为它可以装下很多不同种类的东西,比如: 苹果(整数)、香蕉(浮点数)、橙子(字符串)等等。
但是,每次你只能往盒子里放一样东西,而且一旦放了,你就得知道里面装的是什么类型的物品,以便正确地取出来使用 !
在SQL Server中,sql_variant数据类型就像这样一个万能盒子, 这在某些情况下非常有用,比如当我们不知道用户会输入什么类型的数据时, 那么我们可以采用这种数据类型进行暂时保存!
特点
每个sql_variant值都附带了元数据,也就是关于它里面存储了什么数据类型的额外信息, 相当于这就像你在万能盒子上贴了一个标签,标明里面装的是什么!
但是从性能上说由于sql_variant需要存储元数据,并且SQL Server在处理它时需要额外的步骤来确定数据的类型,那么使用sql_variant可能会比使用固定类型的数据列稍微慢一些, 所以说sql_variant类型通常用于需要灵活存储多种类型数据的场景,但如果我们知道字段中只会存储一种类型的数据,那么使用固定类型的数据列会更高效!
限制
虽然sql_variant很方便,但它也有一些限制, 比如,它不能存储大型文本或二进制数据, 例如:text、ntext、image等
也不能存储一些特殊的数据类型!
sql_variant的应用场景
假设我们有一个员工信息表,其中需要存储员工的多种联系信息例如: 电话号码、电子邮件地址和社交媒体账号等等… 这些联系信息可能以不同的格式出现, 比如: 字符串、整数都有可能, 并且不是每个员工都会提供所有类型的信息。
那么为了简化表结构并允许存储不同类型的数据,我们可以使用sql_variant类型来创建一个通用的联系信息字段!
如下
CREATE TABLE EmployeeContacts (
eid INT PRIMARY KEY IDENTITY, -- 员工ID,自增主键
FirstName VARCHAR(50) NOT NULL, -- 员工名
LastName VARCHAR(50) NOT NULL, -- 员工姓
ContactType VARCHAR(50) NOT NULL, -- 联系信息类型(如Phone, Email, SocialMedia)
ContactInfo sql_variant -- 联系信息内容,可以是多种类型
)
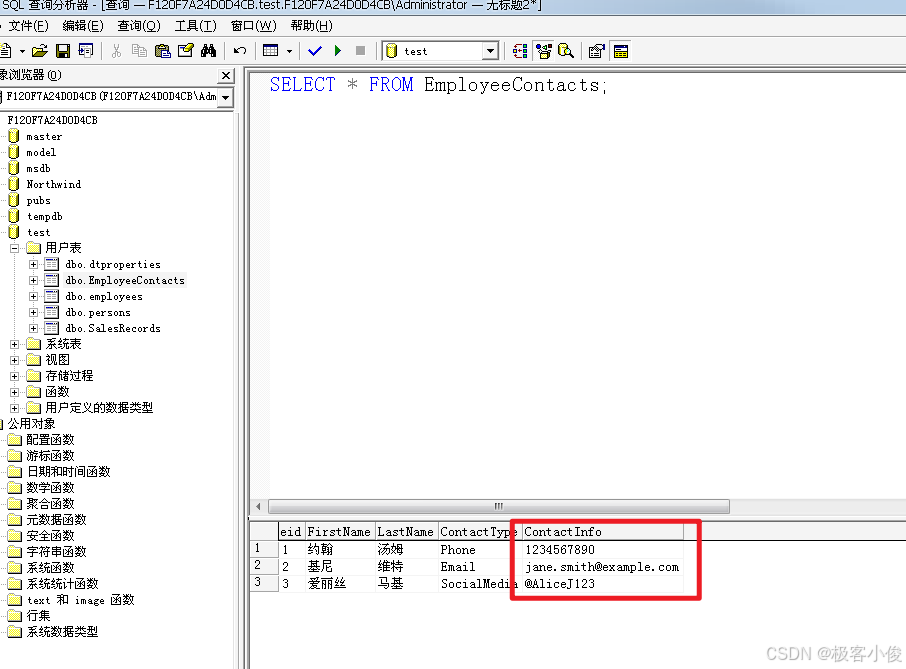
INSERT INTO EmployeeContacts (FirstName, LastName, ContactType, ContactInfo) VALUES ('约翰', '汤姆', 'Phone', 1234567890); -- 电话号码作为整数存储
INSERT INTO EmployeeContacts (FirstName, LastName, ContactType, ContactInfo) VALUES ('基尼', '维特', 'Email', 'jane.smith@example.com'); -- 电子邮件地址作为字符串存储
INSERT INTO EmployeeContacts (FirstName, LastName, ContactType, ContactInfo) VALUES ('爱丽丝', '马基', 'SocialMedia', '@AliceJ123'); -- 社交媒体账号作为字符串存储(这里假设是某种用户句柄)
如图
查询结果
但是平常我们使用这种数据类型的可能性还是很低的!
uniqueidentifier数据类型
这种uniqueidentifier类型是专门用来存储全局唯一标识符(GUID)的数据类型。
GUID前面我说过了是一个128位的数字,通常由16个字节的二进制数组表示,它可以通过算法生成,几乎是唯一的!
uniqueidentifier数据类型在数据库中就是用于表示一个表中的记录的唯一标识符,确保数据的唯一性和关系的完整性!
数据库中通常这种数据类型的值表示为带有连字符的十六进制字符串,具体格式如下:
6F9619FF-8B86-D011-B42D-00C04FC964FF, 并且平常我们也就是使用的NEWID()函数来生成一个唯一的uniqueidentifier值
uniqueidentifier数据类型的值是不可变的,一旦记录被创建,那么uniqueidentifier值就不能被更改!
应用场景
举个栗子
CREATE TABLE Customers (
--使用NEWID()为默认值填充uniqueidentifier列
CustomerID uniqueidentifier NOT NULL DEFAULT NEWID(),
CompanyName varchar(100) NOT NULL
)
--插入数据,CustomerID字段会自动填充为新的uniqueidentifier值
INSERT INTO Customers (CompanyName) VALUES ('张三');
INSERT INTO Customers (CompanyName) VALUES ('李四');
INSERT INTO Customers (CompanyName) VALUES ('王五');
如图
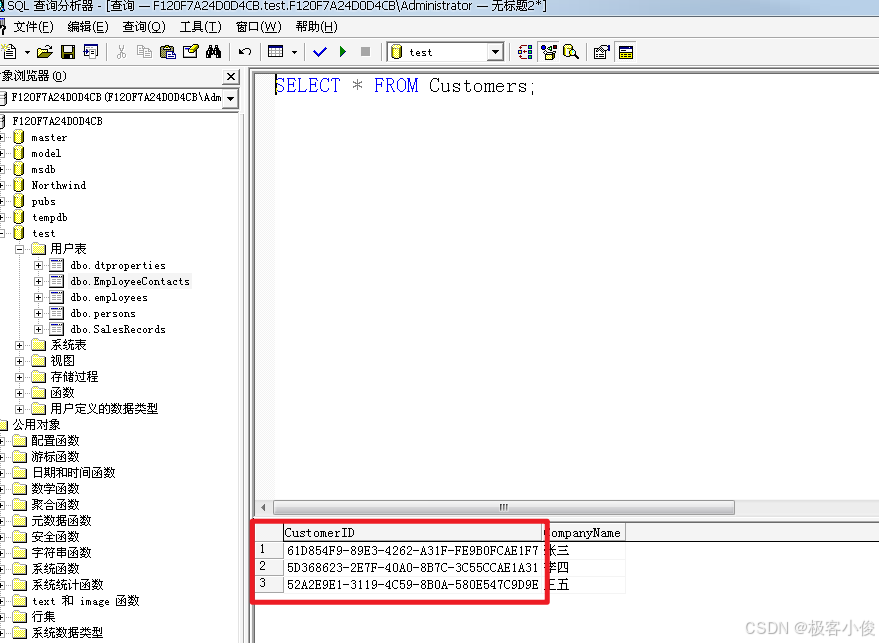
这种数据类型通常用作数据库表的主键或外键,以确保每条记录的唯一性。
比如说在一个订单管理系统中,每个订单可以有一个唯一的uniqueidentifier值作为订单ID,这样可以确保每个订单都是唯一的,并且可以通过这个ID来快速检索和跟踪订单


"👍点赞" "✍️评论" "收藏❤️"欢迎一起交流学习❤️❤️💛💛💚💚
好玩 好用 好看的干货教程可以点击下方关注❤️微信公众号❤️
说不定有意料之外的收获哦..🤗嘿嘿嘿、嘻嘻嘻🤗!
🌽🍓🍎🍍🍉🍇




















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









