




 本文详细介绍了Linux系统中用于文本处理的三个重要工具:grep用于过滤文本内容,sed是一个流编辑器,awk则是功能强大的文本分析工具。文章涵盖了它们的基本用法、选项、操作符和常见应用场景,包括内容的查找、替换、删除、增加等操作。
本文详细介绍了Linux系统中用于文本处理的三个重要工具:grep用于过滤文本内容,sed是一个流编辑器,awk则是功能强大的文本分析工具。文章涵盖了它们的基本用法、选项、操作符和常见应用场景,包括内容的查找、替换、删除、增加等操作。
目录
grep
针对文本内容进行过滤,也就是查找
常用选项
-i 忽略大小写 默认的
-n 显示匹配的行号
-c 显示匹配的行数
-v 取反,要找的不显示
-m 多个匹配时,可以限定显示的行数,可理解为匹配几次之后停止
-o 仅显示匹配到的字符串
-A 匹配所在行以及下几行
-B 匹配所在行以及上几行
-C 匹配所在行以及上下几行
-e 逻辑或,可以匹配多个条件,实现多个选项间的逻辑关系
-w 匹配整个单词
-E 使用扩展正则表达式 egrep也可以使用扩展正则表达式
-f 根据两个文件的内容进行匹配,匹配两个文件中相同的内容
-r 递归目录,不处理软连接
-R 递归目录,处理软连接
grep的作用就是过滤文本内容,是针对行来进行处理
sed
类似于vim,就是一个文本编辑器,按行来进行编辑和处理
sed的主要作用就是对文本内容进行增删改查
sed可以支持正则表达式和扩展正则表达式
sed的原理
读取、执行命令、显示三个过程
读取 读取文本内容之后,读取到的内容存放到临时的缓冲区(模式空间)
执行 在模式空间,根据读取的文本内容,按行执行,除非指定行号,否则会遍历执行,从上往下依次执行
显示 执行完之后,把执行结果打印,如果要改变生效,模式空间被修改的内容会写入到指定的文件当中,只操作但不写入文件时,只展示结果,展示完后模式空间的数据会立即删除
sed文本内容处理工具 面试题
文件过大怎么办
1.split -l
2.cat 文件名 | sed处理 中型文件,大型文件还是先分割
sed
sed -e '操作' 文件1 -e '操作' 文件2
只对一个文件操作时可以不加-e
常用选项
-e 条件操作选项
-f 指定脚本文件来处理输入的文本文件内容,把命令写在脚本里,用脚本里的命令处理第二个文件里面的内容
-i 立即生效 慎用
-n 显示script处理之后的结果
常用操作符
s 替换,替换指定的字符
d 删除,删除指定的行
a 增加,当前行的下面插入指定内容
i 增加,当前行的下面插入指定内容
c 替换,整行替换
y 替换,替换字符,替换前后的字符长度必须一致
p 打印 sed自己有一个默认输出,p打印会额外再来一行
r 表示使用扩展正则
= 值输出行号
sed的核心就是改、删、增,查没有grep强大
对包含指定字符串的内容进行打印
sed -n '/ 过滤内容/p' test.txt 所有包含过滤内容的会全部打印
应用基础正则表达式进行打印
删除
怎么不进入文件就可以删除文件当中的内容,免交互删除。面试题
sed -i 'd' test.txt
cat /dev/null > test.txt
指定行号进行删除
sed '3d;p' test.txt 删除第3行打印剩下的
取反
sed '3!d;p' test.txt删除出来第3行打印第三行
sed -n 's/root/test/p' /etc/passwd 替换第一个root
sed -n 's/root/test/2p' /etc/passwd 替换第二个root
sed -n 's/root/test/gp' /etc/passwd 替换所有root
替换
字母字符大小写替换
sed -nr 's/[a-z]/\u&/g' test.txt 小写转大写
sed -nr 's/[A-Z]/\l&/g' test.txt 大写转小写
I&:转换成小写的特殊符号,在使用时,需要转义符。
u&:转换成大写的特殊符号,在使用时,需要转义符。
g全部替换,不加默认修改首字符
整行替换
sed '/要替换的内容/c 替换的内容' test.txt
增加
sed '/test/a test1' test.txt 在下一行添加test1
sed '/test/i test1' test.txt 在上一行添加test1
sed '/test1/r test1.txt' test.tst 从test1.txt读取指定内容到test.txt中
第一个文件是要读取内容的文件,第二个文件是要指定操作的文件
位置交换
sed命令当中字符串位置进行交换
echo testroot | sed -r 's/(test)(root)/\2\1/'
中文用可以用(.)
查看安装包版本
cat num.txt | sed -r 's/(.*)-(.*)(\.jar)/\2/'
awk
文本三剑客之一,是功能最强大的文本工具
awk也是按行来进行操作,对航操作后,可以根据指定命令来对行取列
awk的默认分隔符是空格或者tab键,多个空格会自动压缩成一个
用法
awk 选项 '模式或条件 {操作}' 文件
-F 指定分隔符,如果是空格就不需要加F
-v 变量赋值
操作默认就是打印
常用内置变量
$0 打印所有内容
$n 处理行的第n列
NR 处理的行的行号
NF 处理当前行的字段个数,$NF就表示最后一个字段
FS 列分隔符,指定文本的分隔符,和F作用一致。区别 -F: FS=":"
OFS 输出文本的分隔符
RS 指定分隔符为回车
内置变量$n要加$,其他的内置变量不用加$,更不能用引号,也不能用括号,否则会被当成字符串来处理
NR==n
超找第几行
NR==m,NR==n m到n
NR==m;NR==n m和n
奇偶行打印
NR%==0 偶数行
NR%==1 奇数行
运算
awk 'BEGIN{print n+m}'
+-*/ 加减乘除
**和^都表示求幂
还支持小数运算
内置函数
getline
1、如果getline左右没有重定向符或者没有管道符时,原本awk会先读第一行,但是如果加了getline会跳过第一行去读取第二行
2、如果getline左右有重定向符或者管道符时,getline作用于定向输入文件
awk '{getline < "test1.txt"; print > "test2.txt"}' test1.txt
将test1.txt传给test2.txt
ls | awk '{getline test3; print test3;}'
getline test3 自定义变量
ls输出的结果传给test3,打印ls输出的结果。如果没有结果打印为空,不做任何操作。
文本内容过滤打印
awk '/内容/{print}'
BEGIN模式
awk 'BEGIN{..};{..};END{..}' 文件
在对文件进行操作之前会先执行BEGIN{..}模式条件或者命令操作,中间的{..}是真正的用于处理文件的命令,END{..}结束语句,一般都是打印执行结果
怎么通过awk获取文件中有多少行 面试题
awk 'BEEGIN{i=0};{i++};END{print i}' /etc/passwd
-v
变量赋值指的是改变分隔符
head -n m 前m行
条件语句
awk 条件判断语句
例
awk -F: '{if ($3=10) {print}}' /etc/passwd三元表达式
类似于JAVA
awk '(条件表达式)?(A表达式或者值):(B的表达式或者值)'
? if
: else
精确筛选
比较数值><=
$n~"字符串" 表示第n个字段包含某个字符串
$n!~"字符串" 表示第n个字段不包含某个字符串
$n=="字符串" 表示第n个字段就是某个字符串
$n!=="字符串" 表示第n个字段不是是某个字符串
$NF: 最后一个字段
awk和tr比较改变分隔符
结合数组使用
在awk中怎么来定义数组
awk 'BEGIN{a[0]=10;a[1]=20;a[2]=30; for (i in a)print i,a[i]'
awk去重
awk '{a[$1]++};END{for (i in a) {print i,a[i]}}' www.txt
实验
提取host.txt主机名
1 www.kgc.com
2 mail.kgc.com
3 ftp.kgc.com
4 linux.kgc.com
5 blog.kgc.com
cat file.txt | awk -F '[ .]+' '{print $2}'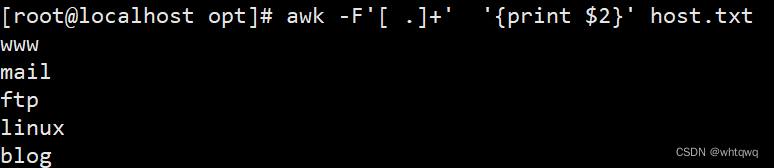


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









