




 本文详细介绍如何在三台Linux机器上部署Elasticsearch集群,包括集群配置、JDK环境准备、es安装与配置、head插件安装及ik分词器的使用。适合初学者快速上手。
本文详细介绍如何在三台Linux机器上部署Elasticsearch集群,包括集群配置、JDK环境准备、es安装与配置、head插件安装及ik分词器的使用。适合初学者快速上手。
准备工作:
1、 三台Linux系统搭建的集群:Master、Slave1、Slave2。三台机器上防火墙已关闭,ssh免密码相互通信。
2、 JDK版本:1.8。
1.集群安装es
1.1.下载解压
下载地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
解压:tar –zxvf elasticsearch-6.2.4
将解压后的es文件夹放到你喜欢的位置,并将该文件夹的所有权限赋予当前用户。
例如:
我的当前用户是hadoop,我es放置的位置在/usr/local/elasticsearch-6.2.4。
su root
chown –R hadoop:hadoop /usr/local/elasticsearch-6.2.4
1.2.核心配置文件
第一台机器上:
打开你es文件下的config/elasticsearch.yml文件
例如:vim /usr/local/ elasticsearch-6.2.4/config/elasticsearch.yml
添加以下数据:
#集群名字,三台机器必须一致
cluster.name: my_es
#各个节点名称,三台机器必须不一致
node.name: node_1
#端口号,可一致可不一致,建议一致
http.port: 9200
#是否有资格成为主节点
node.master: true
#是否有资格成为子节点
node.data: true
#节点绑定地址,三台一致
network.host: 0.0.0.0
#告诉集群有几个可以成为maste的节点
discovery.zen.minimum_master_nodes: 2
#集群的各个ip,三台一致
discovery.zen.ping.unicast.hosts: [“Master的ip”,“Slave1的ip”,“Slave2的ip”]
#这两行是为了haad插件配置,三台一致
http.cors.enabled: true
http.cors.allow-origin: “*”
#这两行设置es数据和日志存储地址,默认在es文件下的data和logs下
#path.data: /home/es /data/
#path.logs: /home/es /logs/
第二台机器上:
cluster.name: my_es
node.name: node_2
http.port: 9200
node.master: true
node.data: true
network.host: 0.0.0.0
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts: [“Master的ip”,“Slave1的ip”,“Slave2的ip”]
http.cors.enabled: true
http.cors.allow-origin: “*”
第三台机器上:
cluster.name: my_es
node.name: node_3
node.master: true
node.data: true
http.port: 9200
network.host: 0.0.0.0
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts: [“Master的ip”,“Slave1的ip”,“Slave2的ip”]
http.cors.enabled: true
http.cors.allow-origin: “*”
1.3.其他配置文件
三台机器全都修改:
1> 打开/etc/sysctl.conf文件,增加配置vm.max_map_count=262144,然后执行sudo sysctl –p命令使其生效。
2> 打开/etc/security/limits.conf文件,增加配置:(符号“*”也要粘贴)
* soft nofile 65536
* hard nofile 65536
用户退出后重新登录生效。
3> 其他优化设置可自行根据电脑配置设置,建议修改配置后重启机器。
1.4.启动
三台机器都需启动:
首先进入es文件夹下的bin目录,然后执行./elasticsearch,

(测试启动成功后,下次可使用./elasticsearch –d在后台启动)
三台机器启动完毕后,在任意一台机器上输入curl localhost:9200进行验证。
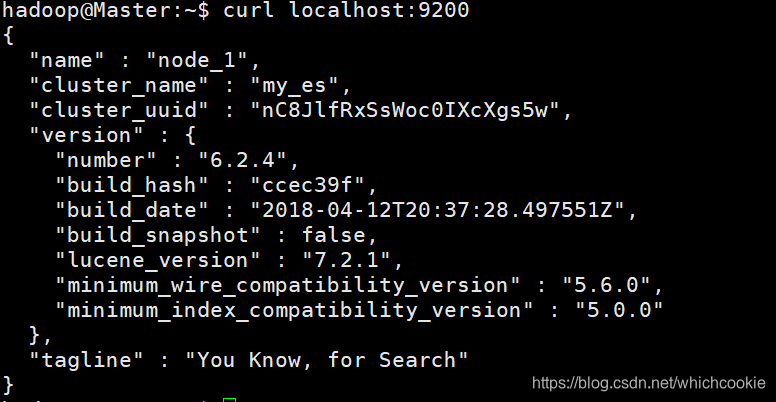
1.5.选举问题
1> discovery.zen.minimum_master_nodes:3参数代表的是集群中有资格成为主节点的最少个数。设置为3,表示当集群个数存活数目大于或等于3个节点时,主节点挂掉后集群才可以通过选举来产生新的主节点,而当集群节点存活个数少于3个并且没有主节点时,集群则没资格进行选举。
官方给出的建议是设置为(n/2)+1,n为有资格成为主节点的节点数也就是配置文件中设置node.master=true的节点个数。
2> 如果网络延迟较大,从节点访问主节点后如果3秒之内没有回复则默认主节点挂了,从而重新选择。可以在配置文件中设置discovery.zen.ping_timeout:5,即将这个时间设置为5秒。
2. elasticsearch-head安装和使用
百度云链接:https://pan.baidu.com/s/1DhGGIld_Dgv4tQ0x9oQpnA
密码:kmdp
打开谷歌浏览器=>更多工具=>扩展程序=>加载已解压的扩展工具=>选择下载好的文件。
加载成功后将开发者按钮和启用按钮打开。

此时浏览器右上角出现插件图标,点击即可打开。
打开后在插件地址栏输入集群的任意节点地址和端口号即可连接。

3. analysis-ik的安装和使用
下载链接:https://github.com/medcl/elasticsearch-analysis-ik/releases
下载与es版本对应ik插件,将其解压放入es目录下的plugins(没有则新建)文件下
文件名改为analysis-ik。
重启即可使用。
ik带有两个分词器:
ik_max_word :会将文本做最细粒度的拆分,尽可能多的拆分出词语。
ik_smart:会做最粗粒度的拆分,已被分出的词语将不会再次被其它词语占有。

















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









